
kubesphere
The container platform tailored for Kubernetes multi-cloud, datacenter, and edge management ⎈ 🖥 ☁️
Stars: 15078
KubeSphere is a distributed operating system for cloud-native application management, using Kubernetes as its kernel. It provides a plug-and-play architecture, allowing third-party applications to be seamlessly integrated into its ecosystem. KubeSphere is also a multi-tenant container platform with full-stack automated IT operation and streamlined DevOps workflows. It provides developer-friendly wizard web UI, helping enterprises to build out a more robust and feature-rich platform, which includes most common functionalities needed for enterprise Kubernetes strategy.
README:
![]()
The container platform tailored for Kubernetes multi-cloud, datacenter, and edge management




English | 中文
KubeSphere is a distributed operating system for cloud-native application management, using Kubernetes as its kernel. It provides a plug-and-play architecture, allowing third-party applications to be seamlessly integrated into its ecosystem. KubeSphere is also a multi-tenant container platform with full-stack automated IT operation and streamlined DevOps workflows. It provides developer-friendly wizard web UI, helping enterprises to build out a more robust and feature-rich platform, which includes most common functionalities needed for enterprise Kubernetes strategy, see Feature List for details.
The following screenshots give a close insight into KubeSphere. Please check What is KubeSphere for further information.
| Workbench | Project Resources |
 |
 |
| CI/CD Pipeline | App Store |
 |
 |
🎮 KubeSphere Lite provides you with free, stable, and out-of-the-box managed cluster service. After registration and login, you can easily create a K8s cluster with KubeSphere installed in only 5 seconds and experience feature-rich KubeSphere.
🖥 You can view the Demo Video to get started with KubeSphere.
🕸 Provisioning Kubernetes Cluster
Support deploy Kubernetes on any infrastructure, support online and air-gapped installation. Learn more.🔗 Kubernetes Multi-cluster Management
Provide a centralized control plane to manage multiple Kubernetes clusters, and support the ability to propagate an app to multiple K8s clusters across different cloud providers.🤖 Kubernetes DevOps
Provide GitOps-based CD solutions and use Argo CD to provide the underlying support, collecting CD status information in real time. With the mainstream CI engine Jenkins integrated, DevOps has never been easier. Learn more.🔎 Cloud Native Observability
Multi-dimensional monitoring, events and auditing logs are supported; multi-tenant log query and collection, alerting and notification are built-in. Learn more.🧩 Service Mesh (Istio-based)
Provide fine-grained traffic management, observability and tracing for distributed microservice applications, provides visualization for traffic topology. Learn more.💻 App Store
Provide an App Store for Helm-based applications, and offer application lifecycle management on Kubernetes platform. Learn more.💡 Edge Computing Platform
KubeSphere integrates KubeEdge to enable users to deploy applications on the edge devices and view logs and monitoring metrics of them on the console. Learn more.📊 Metering and Billing
Track resource consumption at different levels on a unified dashboard, which helps you make better-informed decisions on planning and reduce the cost. Learn more.🗃 Support Multiple Storage and Networking Solutions
🏘 Multi-tenancy
Provide unified authentication with fine-grained roles and three-tier authorization system, and support AD/LDAP authentication.🧠 GPU Workloads Scheduling and Monitoring
Create GPU workloads on the GUI, schedule GPU resources, and manage GPU resource quotas by tenant.KubeSphere uses a loosely-coupled architecture that separates the frontend from the backend. External systems can access the components of the backend through the REST APIs.

🎉 KubeSphere v3.4.0 was released! It brings enhancements and better user experience, see the Release Notes For 3.4.0 for the updates.
| Component | Version | K8s supported version |
|---|---|---|
| Alerting | N/A | 1.21,1.22,1.23,1.24,1.25,1.26 |
| Auditing | v0.2.0 | 1.21,1.22,1.23,1.24,1.25,1.26 |
| Monitoring | N/A | 1.21,1.22,1.23,1.24,1.25,1.26 |
| DevOps | v3.4.0 | 1.21,1.22,1.23,1.24,1.25,1.26 |
| EdgeRuntime | v1.13.0 | 1.21,1.22,1.23 |
| Events | N/A | 1.21,1.22,1.23,1.24,1.25,1.26 |
| Logging | opensearch:v2.6.0 fluentbit-operator: v0.14.0 fluent-bit-tag: v1.9.4 |
1.21,1.22,1.23,1.24,1.25,1.26 |
| Metrics Server | v0.4.2 | 1.21,1.22,1.23,1.24,1.25,1.26 |
| Network | N/A | 1.21,1.22,1.23,1.24,1.25,1.26 |
| Notification | v2.3.0 | 1.21,1.22,1.23,1.24,1.25,1.26 |
| AppStore | N/A | 1.21,1.22,1.23,1.24,1.25,1.26 |
| Storage | pvc-autoresizer: v0.3.0 storageclass-accessor: v0.2.2 |
1.21,1.22,1.23,1.24,1.25,1.26 |
| ServiceMesh | Istio: v1.14.6 | 1.21,1.22,1.23,1.24 |
| Gateway | Ingress NGINX Controller: v1.3.1 | 1.21,1.22,1.23,1.24 |
KubeSphere can run anywhere from on-premise datacenter to any cloud to edge. In addition, it can be deployed on any version-compatible Kubernetes cluster. The installer will start a minimal installation by default, you can enable other pluggable components before or after installation.
Ensure that your cluster has installed Kubernetes v1.21.x, v1.22.x, v1.23.x, * v1.24.x, * v1.25.x, or * v1.26.x. For Kubernetes versions with an asterisk, some features may be unavailable due to incompatibility.
Run the following commands to install KubeSphere on an existing Kubernetes cluster:
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.4.0/kubesphere-installer.yaml
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.4.0/cluster-configuration.yaml👨💻 No Kubernetes? You can use KubeKey to install both KubeSphere and Kubernetes/K3s in single-node mode on your Linux machine. Let's take K3s as an example:
# Download KubeKey
curl -sfL https://get-kk.kubesphere.io | VERSION=v3.0.10 sh -
# Make kk executable
chmod +x kk
# Create a cluster
./kk create cluster --with-kubernetes v1.24.14 --container-manager containerd --with-kubesphere v3.4.0You can run the following command to view the installation logs. After KubeSphere is successfully installed, you can
access the KubeSphere web console at http://IP:30880 and log in using the default administrator account (
admin/P@88w0rd).
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l 'app in (ks-install, ks-installer)' -o jsonpath='{.items[0].metadata.name}') -fKubeSphere is hosted on the following cloud providers, and you can try KubeSphere by one-click installation on their hosted Kubernetes services.
- KubeSphere for Amazon EKS
- KubeSphere for Azure AKS
- KubeSphere for DigitalOcean Kubernetes
- KubeSphere on QingCloud AppCenter(QKE)
You can also install KubeSphere on other hosted Kubernetes services within minutes, see the step-by-step guides to get started.
👨💻 No internet access? Refer to
the Air-gapped Installation on Kubernetes
or Air-gapped Installation on Linux
for instructions on how to use private registry to install KubeSphere.
We ❤️ your contribution. The community walks you through how to get started contributing KubeSphere. The development guide explains how to set up development environment.
🤗 Please submit any KubeSphere bugs, issues, and feature requests to KubeSphere GitHub Issue.
💟 The KubeSphere team also provides efficient official ticket support to respond in hours. For more information, click KubeSphere Online Support.
The user case studies page includes the user list of the project. You can leave a comment to let us know your use case.
KubeSphere is a member of CNCF and a Kubernetes Conformance Certified platform
, which enriches the CNCF CLOUD NATIVE Landscape.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for kubesphere
Similar Open Source Tools
kubesphere
KubeSphere is a distributed operating system for cloud-native application management, using Kubernetes as its kernel. It provides a plug-and-play architecture, allowing third-party applications to be seamlessly integrated into its ecosystem. KubeSphere is also a multi-tenant container platform with full-stack automated IT operation and streamlined DevOps workflows. It provides developer-friendly wizard web UI, helping enterprises to build out a more robust and feature-rich platform, which includes most common functionalities needed for enterprise Kubernetes strategy.
appwrite
Appwrite is a best-in-class, developer-first platform that provides everything needed to create scalable, stable, and production-ready software quickly. It is an end-to-end platform for building Web, Mobile, Native, or Backend apps, packaged as Docker microservices. Appwrite abstracts the complexity of building modern apps and allows users to build secure, full-stack applications faster. It offers features like user authentication, database management, storage, file management, image manipulation, Cloud Functions, messaging, and more services.
ToolJet
ToolJet is an open-source platform for building and deploying internal tools, workflows, and AI agents. It offers a visual builder with drag-and-drop UI, integrations with databases, APIs, SaaS apps, and object storage. The community edition includes features like a visual app builder, ToolJet database, multi-page apps, collaboration tools, extensibility with plugins, code execution, and security measures. ToolJet AI, the enterprise version, adds AI capabilities for app generation, query building, debugging, agent creation, security compliance, user management, environment management, GitSync, branding, access control, embedded apps, and enterprise support.

sealos
Sealos is a cloud operating system distribution based on the Kubernetes kernel, designed for a seamless development lifecycle. It allows users to spin up full-stack environments in seconds, effortlessly push releases, and scale production seamlessly. With core features like easy application management, quick database creation, and cloud universality, Sealos offers efficient and economical cloud management with high universality and ease of use. The platform also emphasizes agility and security through its multi-tenancy sharing model. Sealos is supported by a community offering full documentation, Discord support, and active development roadmap.
ksail
KSail is a tool that bundles common Kubernetes tooling into a single binary, providing a unified workflow for creating clusters, deploying workloads, and operating cloud-native stacks across different distributions and providers. It eliminates the need for multiple CLI tools and bespoke scripts, offering features like one binary for provisioning and deployment, support for various cluster configurations, mirror registries, GitOps integration, customizable stack selection, built-in SOPS for secrets management, AI assistant for interactive chat, and a VSCode extension for cluster management.

toolhive-studio
ToolHive Studio is an experimental project under active development and testing, providing an easy way to discover, deploy, and manage Model Context Protocol (MCP) servers securely. Users can launch any MCP server in a locked-down container with just a few clicks, eliminating manual setup, security concerns, and runtime issues. The tool ensures instant deployment, default security measures, cross-platform compatibility, and seamless integration with popular clients like GitHub Copilot, Cursor, and Claude Code.
higress
Higress is an open-source cloud-native API gateway built on the core of Istio and Envoy, based on Alibaba's internal practice of Envoy Gateway. It is designed for AI-native API gateway, serving AI businesses such as Tongyi Qianwen APP, Bailian Big Model API, and Machine Learning PAI platform. Higress provides capabilities to interface with LLM model vendors, AI observability, multi-model load balancing/fallback, AI token flow control, and AI caching. It offers features for AI gateway, Kubernetes Ingress gateway, microservices gateway, and security protection gateway, with advantages in production-level scalability, stream processing, extensibility, and ease of use.

clearml
ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.
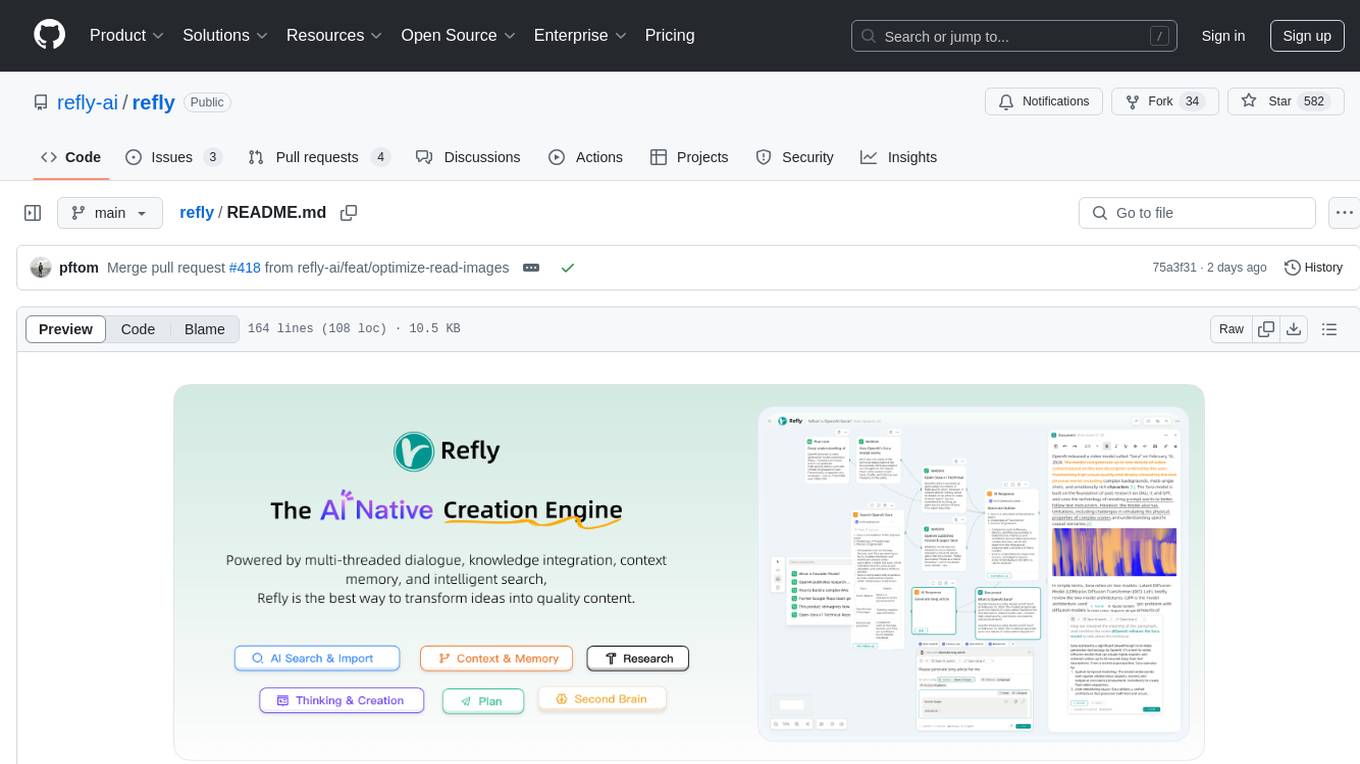
refly
Refly.AI is an open-source AI-native creation engine that empowers users to transform ideas into production-ready content. It features a free-form canvas interface with multi-threaded conversations, knowledge base integration, contextual memory, intelligent search, WYSIWYG AI editor, and more. Users can leverage AI-powered capabilities, context memory, knowledge base integration, quotes, and AI document editing to enhance their content creation process. Refly offers both cloud and self-hosting options, making it suitable for individuals, enterprises, and organizations. The tool is designed to facilitate human-AI collaboration and streamline content creation workflows.
kubewall
kubewall is an open-source, single-binary Kubernetes dashboard with multi-cluster management and AI integration. It provides a simple and rich real-time interface to manage and investigate your clusters. With features like multi-cluster management, AI-powered troubleshooting, real-time monitoring, single-binary deployment, in-depth resource views, browser-based access, search and filter capabilities, privacy by default, port forwarding, live refresh, aggregated pod logs, and clean resource management, kubewall offers a comprehensive solution for Kubernetes cluster management.

xpander.ai
xpander.ai is a Backend-as-a-Service for autonomous agents that abstracts the ops layer, allowing AI engineers to focus on behavior and outcomes. It provides managed agent hosting with version control and CI/CD, a fully managed PostgreSQL memory layer, and a library of 2,000+ functions. The platform features an AI native triggering system that processes inputs from various sources and delivers unified messages to agents. With support for any agent framework or SDK, including Agno and OpenAI, xpander.ai enables users to build intelligent, production-ready AI agents without dealing with infrastructure complexity.
docq
Docq is a private and secure GenAI tool designed to extract knowledge from business documents, enabling users to find answers independently. It allows data to stay within organizational boundaries, supports self-hosting with various cloud vendors, and offers multi-model and multi-modal capabilities. Docq is extensible, open-source (AGPLv3), and provides commercial licensing options. The tool aims to be a turnkey solution for organizations to adopt AI innovation safely, with plans for future features like more data ingestion options and model fine-tuning.
agents-towards-production
Agents Towards Production is an open-source playbook for building production-ready GenAI agents that scale from prototype to enterprise. Tutorials cover stateful workflows, vector memory, real-time web search APIs, Docker deployment, FastAPI endpoints, security guardrails, GPU scaling, browser automation, fine-tuning, multi-agent coordination, observability, evaluation, and UI development.
gobii-platform
Gobii Platform is an open-source platform designed for running durable autonomous agents in production. Each agent can run continuously, wake from schedules and events, use real browsers, call external systems, and coordinate with other agents. It is optimized for reliable, secure, always-on agent operations for teams and businesses. Gobii treats agents as operational entities with addressable communication endpoints, allowing teams to contact them directly like AI coworkers. The platform provides security-first controls, encrypted-at-rest secrets, proxy-governed egress, and Kubernetes sandbox compute support. Gobii is purpose-built for secure, governed, always-on production execution in cloud or hybrid environments.

clearml
ClearML is an auto-magical suite of tools designed to streamline AI workflows. It includes modules for experiment management, MLOps/LLMOps, data management, model serving, and more. ClearML offers features like experiment tracking, model serving, orchestration, and automation. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm for remote debugging. ClearML aims to simplify collaboration, automate processes, and enhance visibility in AI projects.
agentgateway
Agentgateway is an open source data plane optimized for agentic AI connectivity within or across any agent framework or environment. It provides drop-in security, observability, and governance for agent-to-agent and agent-to-tool communication, supporting leading interoperable protocols like Agent2Agent (A2A) and Model Context Protocol (MCP). Highly performant, security-first, multi-tenant, dynamic, and supporting legacy API transformation, agentgateway is designed to handle any scale and run anywhere with any agent framework.
For similar tasks
kubesphere
KubeSphere is a distributed operating system for cloud-native application management, using Kubernetes as its kernel. It provides a plug-and-play architecture, allowing third-party applications to be seamlessly integrated into its ecosystem. KubeSphere is also a multi-tenant container platform with full-stack automated IT operation and streamlined DevOps workflows. It provides developer-friendly wizard web UI, helping enterprises to build out a more robust and feature-rich platform, which includes most common functionalities needed for enterprise Kubernetes strategy.
For similar jobs

AirGo
AirGo is a front and rear end separation, multi user, multi protocol proxy service management system, simple and easy to use. It supports vless, vmess, shadowsocks, and hysteria2.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

llm-code-interpreter
The 'llm-code-interpreter' repository is a deprecated plugin that provides a code interpreter on steroids for ChatGPT by E2B. It gives ChatGPT access to a sandboxed cloud environment with capabilities like running any code, accessing Linux OS, installing programs, using filesystem, running processes, and accessing the internet. The plugin exposes commands to run shell commands, read files, and write files, enabling various possibilities such as running different languages, installing programs, starting servers, deploying websites, and more. It is powered by the E2B API and is designed for agents to freely experiment within a sandboxed environment.

pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

learn-generative-ai
Learn Cloud Applied Generative AI Engineering (GenEng) is a course focusing on the application of generative AI technologies in various industries. The course covers topics such as the economic impact of generative AI, the role of developers in adopting and integrating generative AI technologies, and the future trends in generative AI. Students will learn about tools like OpenAI API, LangChain, and Pinecone, and how to build and deploy Large Language Models (LLMs) for different applications. The course also explores the convergence of generative AI with Web 3.0 and its potential implications for decentralized intelligence.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

aiges
AIGES is a core component of the Athena Serving Framework, designed as a universal encapsulation tool for AI developers to deploy AI algorithm models and engines quickly. By integrating AIGES, you can deploy AI algorithm models and engines rapidly and host them on the Athena Serving Framework, utilizing supporting auxiliary systems for networking, distribution strategies, data processing, etc. The Athena Serving Framework aims to accelerate the cloud service of AI algorithm models and engines, providing multiple guarantees for cloud service stability through cloud-native architecture. You can efficiently and securely deploy, upgrade, scale, operate, and monitor models and engines without focusing on underlying infrastructure and service-related development, governance, and operations.