
hollama
A minimal web-UI for talking to Ollama (and OpenAI) servers
Stars: 775
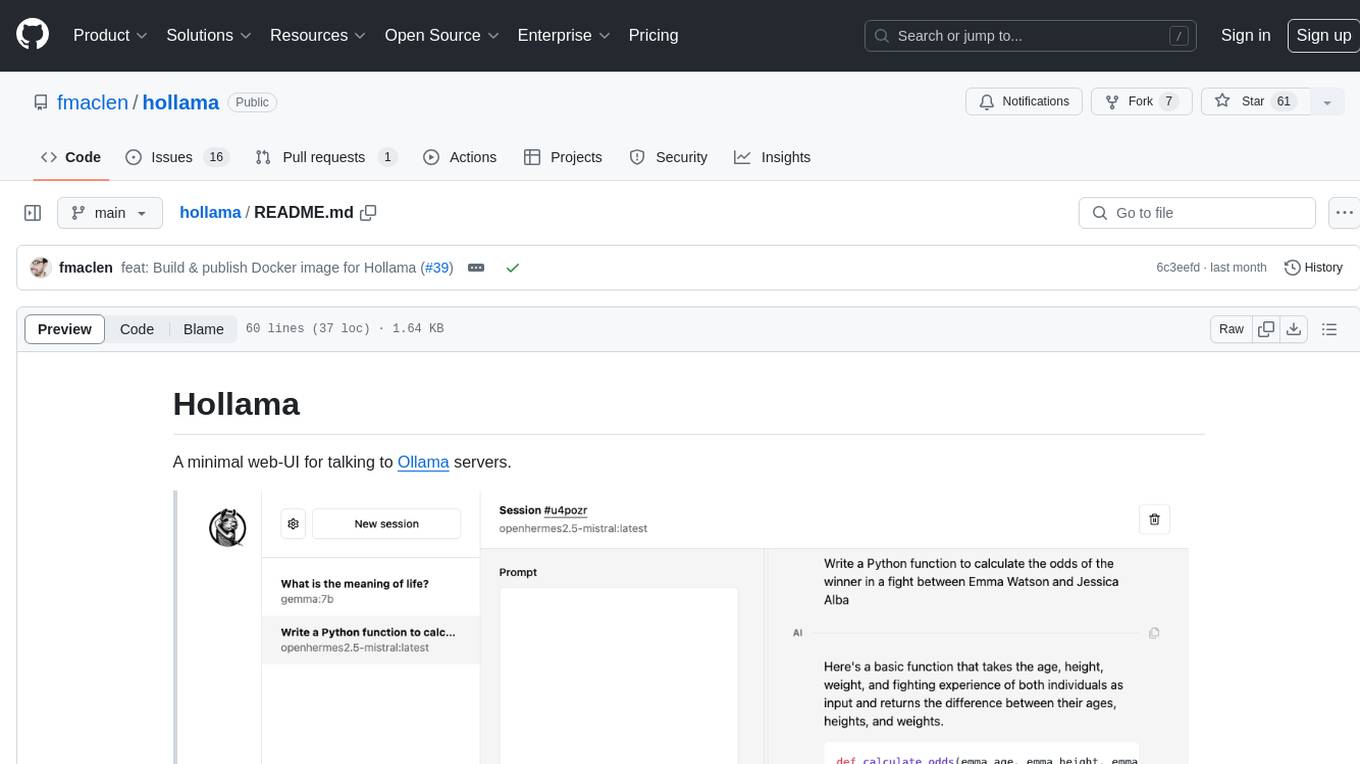
Hollama is a minimal web-UI tool designed for interacting with Ollama servers. It features large prompt fields, streams completions, ability to copy completions as raw text, Markdown parsing with syntax highlighting, and saves sessions/context in the browser's localStorage. Users can access the latest version of Hollama at https://hollama.fernando.is without sign up, and data is stored locally on the browser. The tool can also be run as a Docker image by executing a specific command. Developers can connect to an Ollama server by updating the ORIGIN settings. Hollama facilitates easy development by providing instructions to set up the environment, install dependencies, and start a development server. Building a production version of the app is straightforward with a single command, and deployment may require installing an adapter for the target environment.
README:
A minimal web-UI for talking to Ollama servers.
- Support for Ollama & OpenAI models
- Multi-server support
- Large prompt fields
- Support for reasoning models
- Markdown rendering with syntax highlighting
- KaTeX math notation
- Code editor features
- Customizable system prompts & advanced Ollama parameters
- Copy code snippets, messages or entire sessions
- Edit & retry messages
- Stores data locally on your browser
- Responsive layout
- Light & dark themes
- Multi-language interface
- Download Ollama models directly from the UI
- ⚡️ Live demo
- No sign-up required
- 🖥️ Download for macOS, Windows & Linux
- 🐳 Self-hosting with Docker
- 🐞 Contribute
 |
 |
|---|---|
 |
 |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for hollama
Similar Open Source Tools
hollama
Hollama is a minimal web-UI tool designed for interacting with Ollama servers. It features large prompt fields, streams completions, ability to copy completions as raw text, Markdown parsing with syntax highlighting, and saves sessions/context in the browser's localStorage. Users can access the latest version of Hollama at https://hollama.fernando.is without sign up, and data is stored locally on the browser. The tool can also be run as a Docker image by executing a specific command. Developers can connect to an Ollama server by updating the ORIGIN settings. Hollama facilitates easy development by providing instructions to set up the environment, install dependencies, and start a development server. Building a production version of the app is straightforward with a single command, and deployment may require installing an adapter for the target environment.
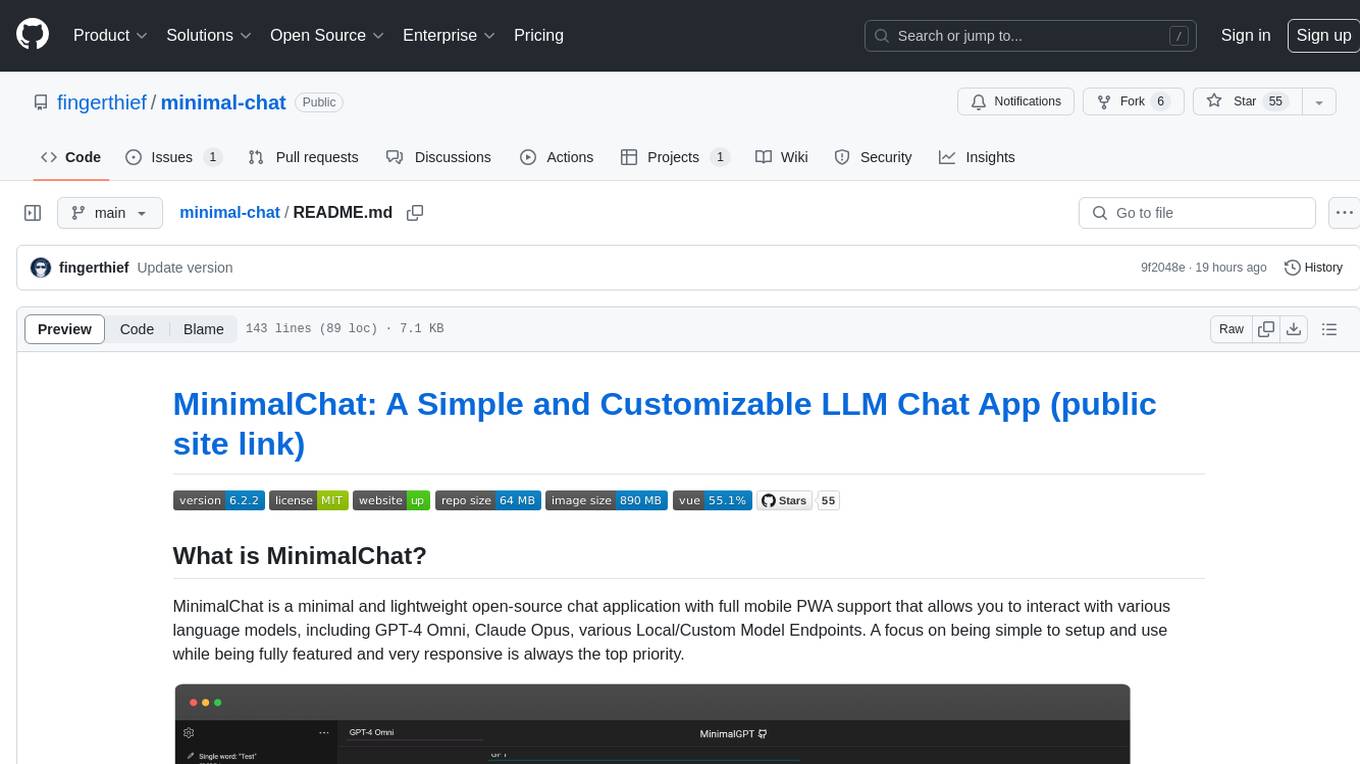
minimal-chat
MinimalChat is a minimal and lightweight open-source chat application with full mobile PWA support that allows users to interact with various language models, including GPT-4 Omni, Claude Opus, and various Local/Custom Model Endpoints. It focuses on simplicity in setup and usage while being fully featured and highly responsive. The application supports features like fully voiced conversational interactions, multiple language models, markdown support, code syntax highlighting, DALL-E 3 integration, conversation importing/exporting, and responsive layout for mobile use.
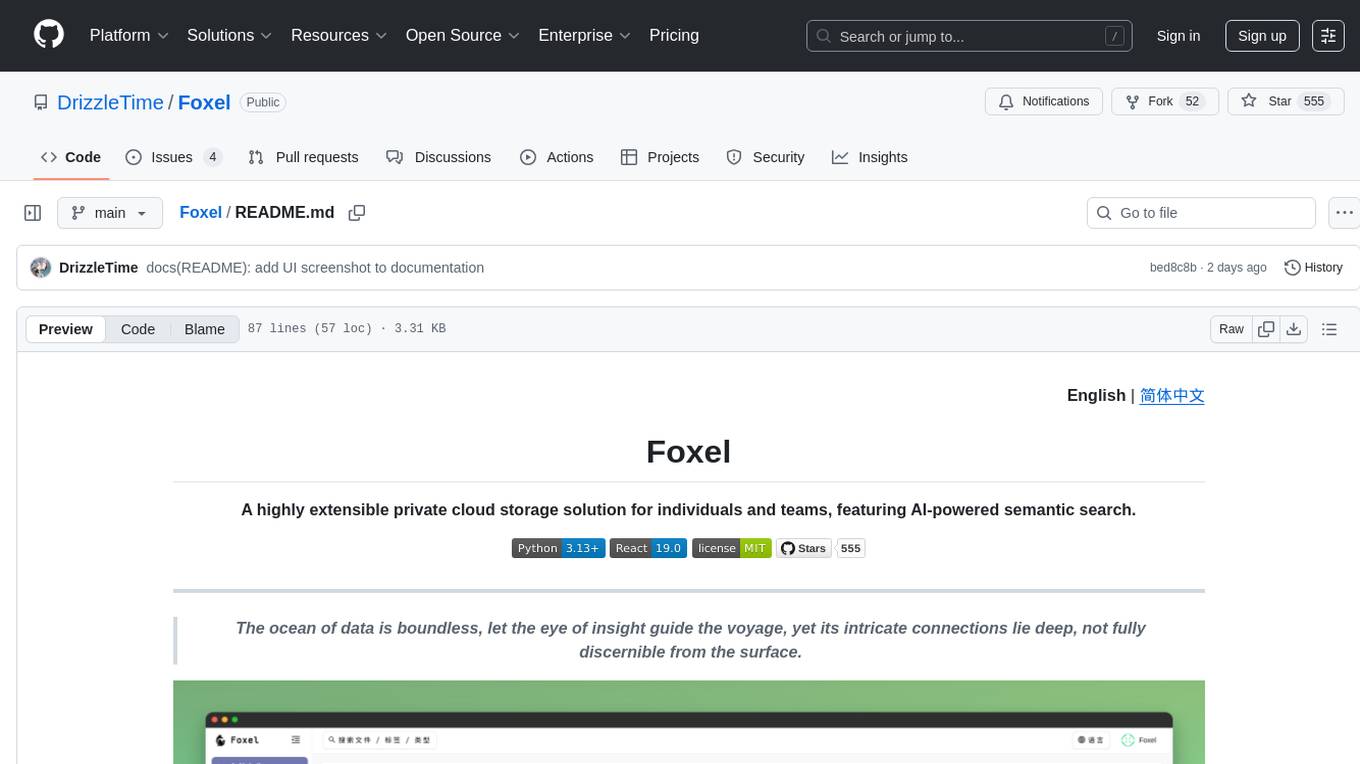
Foxel
Foxel is a highly extensible private cloud storage solution for individuals and teams, featuring AI-powered semantic search. It offers unified file management, pluggable storage backends, semantic search capabilities, built-in file preview, permissions and sharing options, and a task processing center. Users can easily manage files, search content within unstructured data, preview various file types, share files, and process tasks asynchronously. Foxel is designed to centralize file management and enhance search capabilities for users.

cossistant
Cossistant is an open source chat support widget tailored for the React ecosystem. It offers headless components for building customizable chat interfaces, real-time messaging with WebSocket technology, and tools for managing customer conversations. The tool is API-first, self-hosted, developer-friendly with TypeScript support, and provides complete integration flexibility. It uses technologies like Next.js, TailwindCSS, and WebSockets, and supports databases like PlanetScale for production and DBgin for local development. Cossistant is ideal for developers seeking a versatile chat solution that can be easily integrated into their applications.
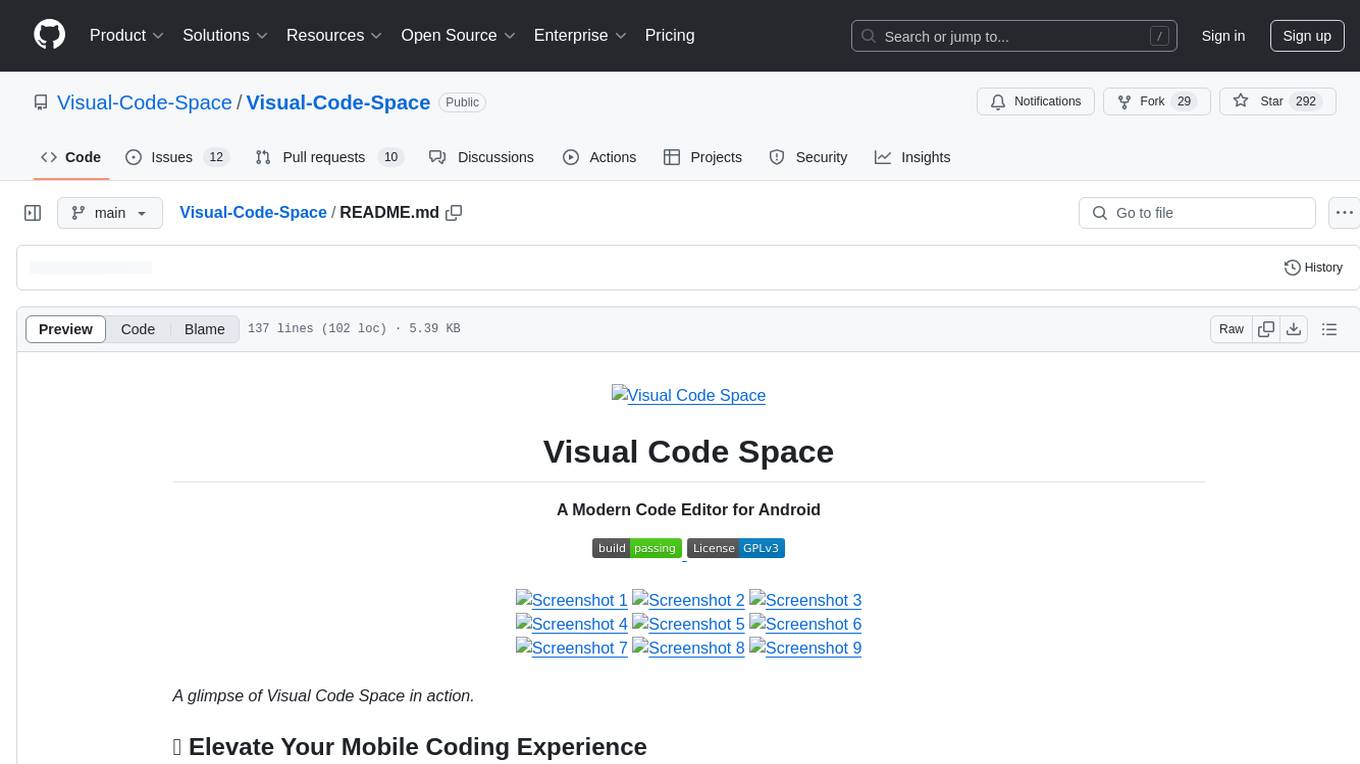
Visual-Code-Space
Visual Code Space is a modern code editor designed specifically for Android devices. It offers a seamless and efficient coding environment with features like blazing fast file explorer, multi-language syntax highlighting, tabbed editor, integrated terminal emulator, ad-free experience, and plugin support. Users can enhance their mobile coding experience with this cutting-edge editor that allows customization through custom plugins written in BeanShell. The tool aims to simplify coding on the go by providing a user-friendly interface and powerful functionalities.
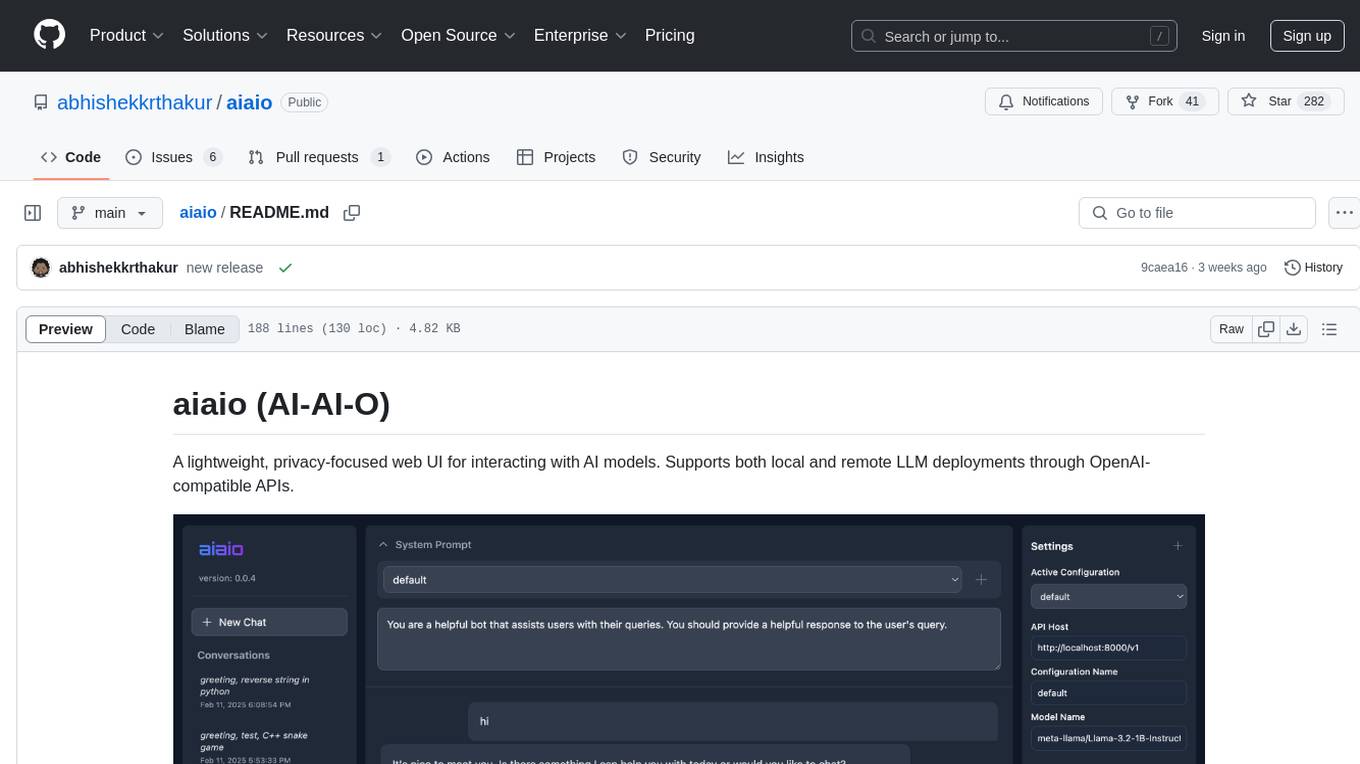
aiaio
aiaio (AI-AI-O) is a lightweight, privacy-focused web UI for interacting with AI models. It supports both local and remote LLM deployments through OpenAI-compatible APIs. The tool provides features such as dark/light mode support, local SQLite database for conversation storage, file upload and processing, configurable model parameters through UI, privacy-focused design, responsive design for mobile/desktop, syntax highlighting for code blocks, real-time conversation updates, automatic conversation summarization, customizable system prompts, WebSocket support for real-time updates, Docker support for deployment, multiple API endpoint support, and multiple system prompt support. Users can configure model parameters and API settings through the UI, handle file uploads, manage conversations, and use keyboard shortcuts for efficient interaction. The tool uses SQLite for storage with tables for conversations, messages, attachments, and settings. Contributions to the project are welcome under the Apache License 2.0.
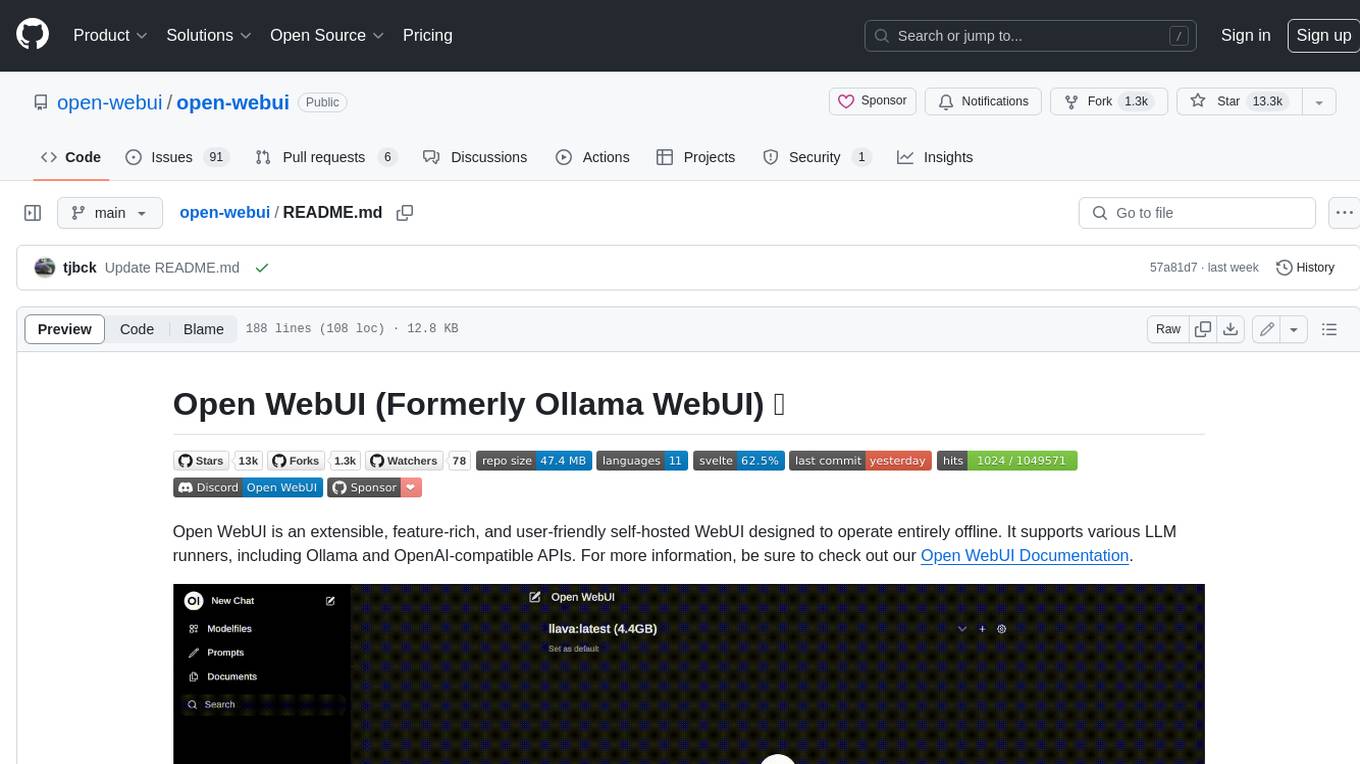
open-webui
Open WebUI is an extensible, feature-rich, and user-friendly self-hosted WebUI designed to operate entirely offline. It supports various LLM runners, including Ollama and OpenAI-compatible APIs. For more information, be sure to check out our Open WebUI Documentation.
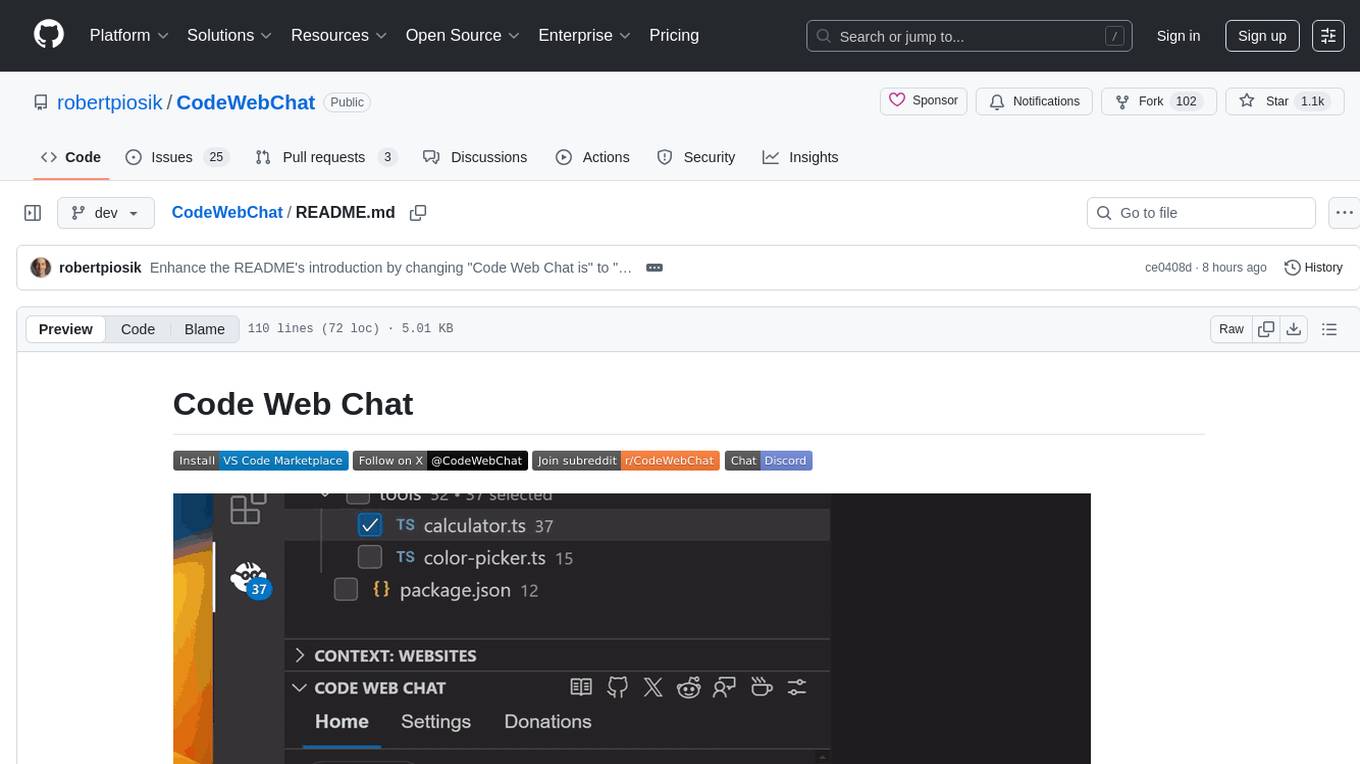
CodeWebChat
Code Web Chat is a versatile, free, and open-source AI pair programming tool with a unique web-based workflow. Users can select files, type instructions, and initialize various chatbots like ChatGPT, Gemini, Claude, and more hands-free. The tool helps users save money with free tiers and subscription-based billing and save time with multi-file edits from a single prompt. It supports chatbot initialization through the Connector browser extension and offers API tools for code completions, editing context, intelligent updates, and commit messages. Users can handle AI responses, code completions, and version control through various commands. The tool is privacy-focused, operates locally, and supports any OpenAI-API compatible provider for its utilities.

WeKnora
WeKnora is a document understanding and semantic retrieval framework based on large language models (LLM), designed specifically for scenarios with complex structures and heterogeneous content. The framework adopts a modular architecture, integrating multimodal preprocessing, semantic vector indexing, intelligent recall, and large model generation reasoning to build an efficient and controllable document question-answering process. The core retrieval process is based on the RAG (Retrieval-Augmented Generation) mechanism, combining context-relevant segments with language models to achieve higher-quality semantic answers. It supports various document formats, intelligent inference, flexible extension, efficient retrieval, ease of use, and security and control. Suitable for enterprise knowledge management, scientific literature analysis, product technical support, legal compliance review, and medical knowledge assistance.
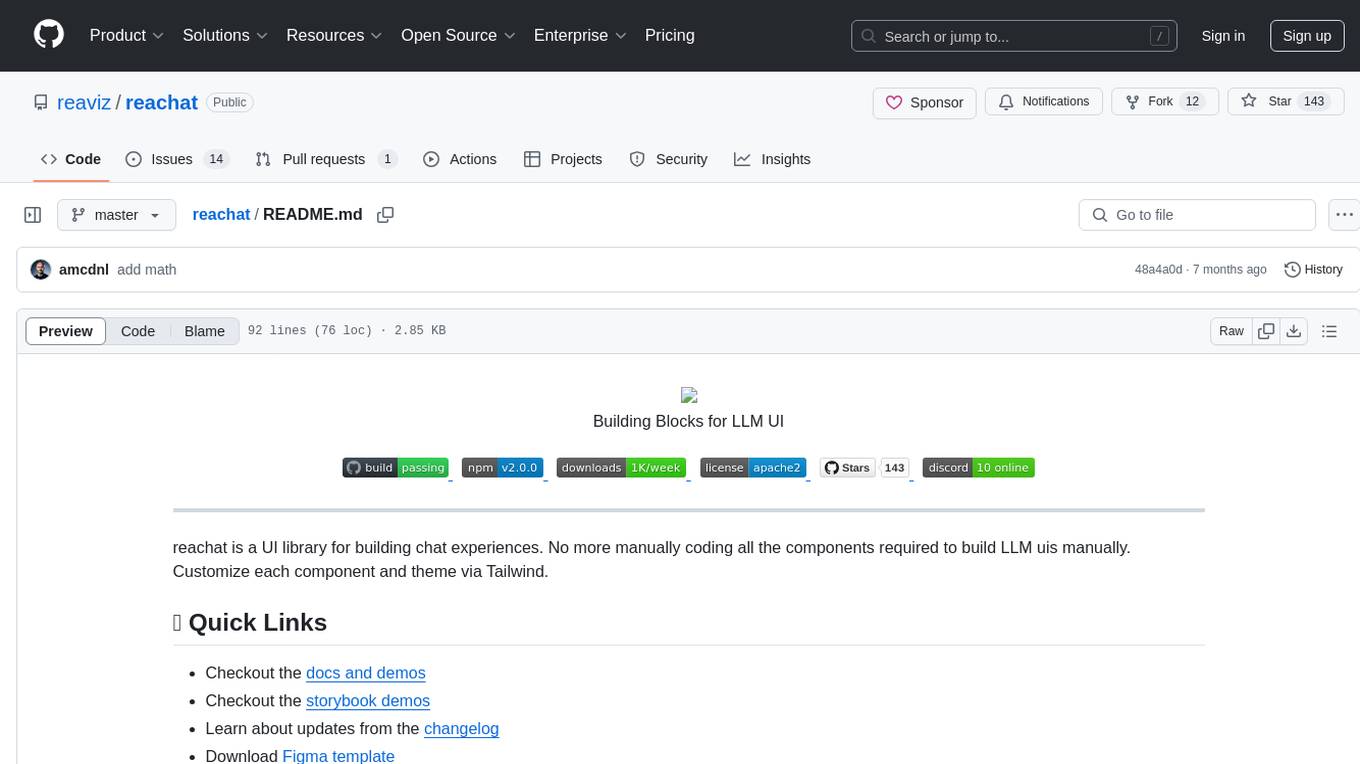
reachat
Reachat is a UI library designed for building chat experiences without the need for manual coding of components. Users can customize each component and theme using Tailwind. The library offers features such as console and companion modes, markdown rendering, code highlighting, tables, JSON support, math rendering, YouTube embeds, file uploads, message sources, animations, conversation pagination, keyboard shortcuts, responsive design, and more. Reachat is highly customizable and suitable for creating interactive chat interfaces.

swark
Swark is a VS Code extension that automatically generates architecture diagrams from code using large language models (LLMs). It is directly integrated with GitHub Copilot, requires no authentication or API key, and supports all languages. Swark helps users learn new codebases, review AI-generated code, improve documentation, understand legacy code, spot design flaws, and gain test coverage insights. It saves output in a 'swark-output' folder with diagram and log files. Source code is only shared with GitHub Copilot for privacy. The extension settings allow customization for file reading, file extensions, exclusion patterns, and language model selection. Swark is open source under the GNU Affero General Public License v3.0.

cline-based-code-generator
HAI Code Generator is a cutting-edge tool designed to simplify and automate task execution while enhancing code generation workflows. Leveraging Specif AI, it streamlines processes like task execution, file identification, and code documentation through intelligent automation and AI-driven capabilities. Built on Cline's powerful foundation for AI-assisted development, HAI Code Generator boosts productivity and precision by automating task execution and integrating file management capabilities. It combines intelligent file indexing, context generation, and LLM-driven automation to minimize manual effort and ensure task accuracy. Perfect for developers and teams aiming to enhance their workflows.
synmetrix
Synmetrix is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube.js to consolidate metrics from various sources and distribute them downstream via a SQL API. Use cases include data democratization, business intelligence and reporting, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.
gitdiagram
GitDiagram is a tool that turns any GitHub repository into an interactive diagram for visualization in seconds. It offers instant visualization, interactivity, fast generation, customization, and API access. The tool utilizes a tech stack including Next.js, FastAPI, PostgreSQL, Claude 3.5 Sonnet, Vercel, EC2, GitHub Actions, PostHog, and Api-Analytics. Users can self-host the tool for local development and contribute to its development. GitDiagram is inspired by Gitingest and has future plans to use larger context models, allow user API key input, implement RAG with Mermaid.js docs, and include font-awesome icons in diagrams.

mlcraft
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.
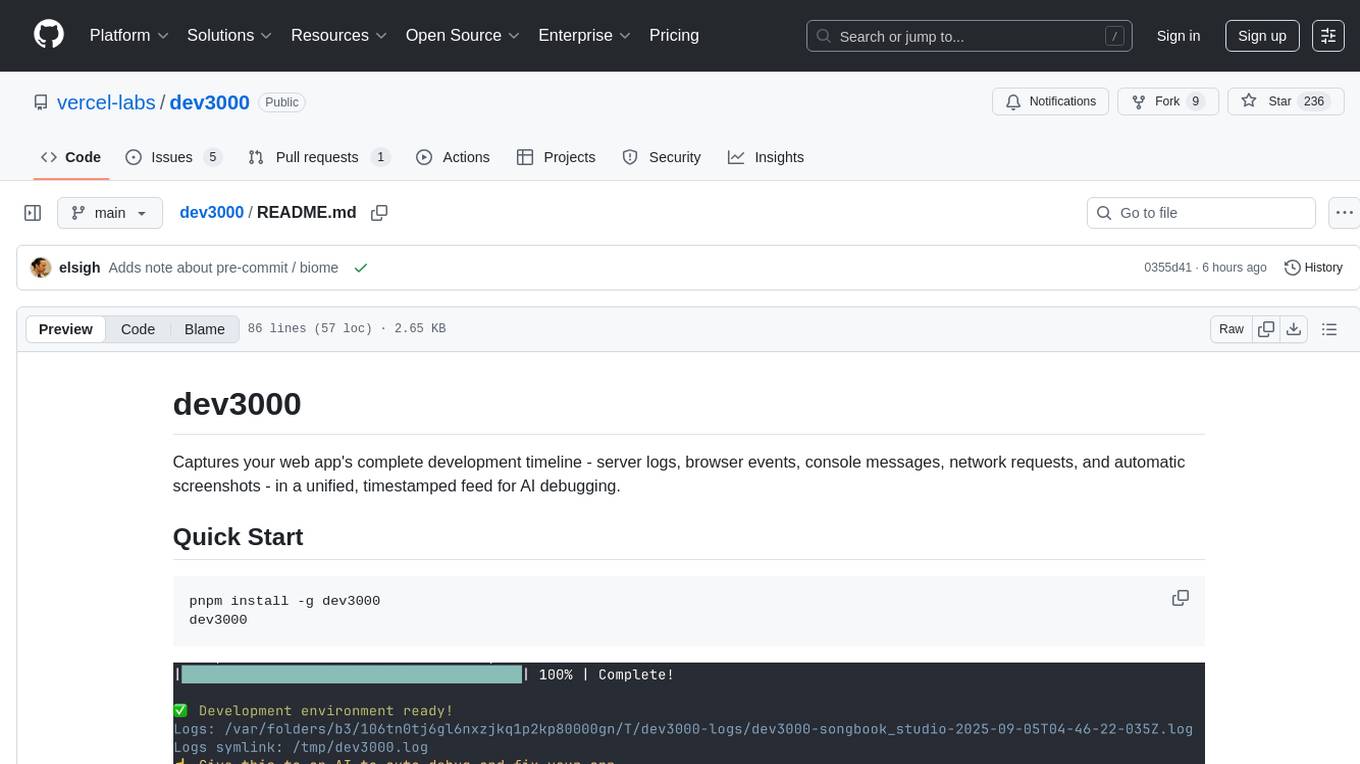
dev3000
dev3000 captures your web app's complete development timeline including server logs, browser events, console messages, network requests, and automatic screenshots in a unified, timestamped feed for AI debugging. It creates a comprehensive log of your development session that AI assistants can easily understand, monitoring your app in a real browser and capturing server logs, console output, browser console messages and errors, network requests and responses, and automatic screenshots on navigation, errors, and key events. Logs are saved with timestamps and rotated to keep the 10 most recent per project, with the current session symlinked for easy access. The tool integrates with AI assistants for instant debugging and provides advanced querying options through the MCP server.
For similar tasks
hollama
Hollama is a minimal web-UI tool designed for interacting with Ollama servers. It features large prompt fields, streams completions, ability to copy completions as raw text, Markdown parsing with syntax highlighting, and saves sessions/context in the browser's localStorage. Users can access the latest version of Hollama at https://hollama.fernando.is without sign up, and data is stored locally on the browser. The tool can also be run as a Docker image by executing a specific command. Developers can connect to an Ollama server by updating the ORIGIN settings. Hollama facilitates easy development by providing instructions to set up the environment, install dependencies, and start a development server. Building a production version of the app is straightforward with a single command, and deployment may require installing an adapter for the target environment.
comfyui_LLM_party
COMFYUI LLM PARTY is a node library designed for LLM workflow development in ComfyUI, an extremely minimalist UI interface primarily used for AI drawing and SD model-based workflows. The project aims to provide a complete set of nodes for constructing LLM workflows, enabling users to easily integrate them into existing SD workflows. It features various functionalities such as API integration, local large model integration, RAG support, code interpreters, online queries, conditional statements, looping links for large models, persona mask attachment, and tool invocations for weather lookup, time lookup, knowledge base, code execution, web search, and single-page search. Users can rapidly develop web applications using API + Streamlit and utilize LLM as a tool node. Additionally, the project includes an omnipotent interpreter node that allows the large model to perform any task, with recommendations to use the 'show_text' node for display output.

learn-modern-ai-python
This repository is part of the Certified Agentic & Robotic AI Engineer program, covering the first quarter of the course work. It focuses on Modern AI Python Programming, emphasizing static typing for robust and scalable AI development. The course includes modules on Python fundamentals, object-oriented programming, advanced Python concepts, AI-assisted Python programming, web application basics with Python, and the future of Python in AI. Upon completion, students will be able to write proficient Modern Python code, apply OOP principles, implement asynchronous programming, utilize AI-powered tools, develop basic web applications, and understand the future directions of Python in AI.
Operit
Operit AI is a fully functional AI assistant application for mobile devices, running independently on Android devices with powerful tool invocation capabilities. It offers over 40 built-in tools for file system operations, HTTP requests, system operations, UI automation, and media processing. The app combines these tools with rich plugins to enable a wide range of tasks, from simple to complex, providing a comprehensive experience of a smartphone AI assistant.

echo
Echo is a tool that simplifies the integration of AI SDKs into applications, providing instant OAuth, user accounts, and usage billing in just 5 lines of code. It eliminates the need to manage API keys, build authentication flows, or set up payment processing, allowing developers to go live in minutes. Users benefit from a universal balance that works across all Echo-powered apps, with revenue directly hitting the developer's GitHub account. Echo offers various SDKs for different frameworks like Next.js and React, along with templates to quickly start projects with Echo integration.
For similar jobs

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

nvidia_gpu_exporter
Nvidia GPU exporter for prometheus, using `nvidia-smi` binary to gather metrics.

tracecat
Tracecat is an open-source automation platform for security teams. It's designed to be simple but powerful, with a focus on AI features and a practitioner-obsessed UI/UX. Tracecat can be used to automate a variety of tasks, including phishing email investigation, evidence collection, and remediation plan generation.

openinference
OpenInference is a set of conventions and plugins that complement OpenTelemetry to enable tracing of AI applications. It provides a way to capture and analyze the performance and behavior of AI models, including their interactions with other components of the application. OpenInference is designed to be language-agnostic and can be used with any OpenTelemetry-compatible backend. It includes a set of instrumentations for popular machine learning SDKs and frameworks, making it easy to add tracing to your AI applications.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

kong
Kong, or Kong API Gateway, is a cloud-native, platform-agnostic, scalable API Gateway distinguished for its high performance and extensibility via plugins. It also provides advanced AI capabilities with multi-LLM support. By providing functionality for proxying, routing, load balancing, health checking, authentication (and more), Kong serves as the central layer for orchestrating microservices or conventional API traffic with ease. Kong runs natively on Kubernetes thanks to its official Kubernetes Ingress Controller.