
raif
Ruby AI Framework
Stars: 280

Raif is a lightweight Python library for analyzing text data. It provides functionalities for text preprocessing, feature extraction, and text classification. With Raif, users can easily clean and preprocess text data, extract relevant features, and build machine learning models for text classification tasks. The library is designed to be user-friendly and efficient, making it suitable for both beginners and experienced data scientists.
README:
![]()
![]()
Raif (Ruby AI Framework) is a Rails engine that helps you add AI-powered features to your Rails apps, such as tasks, conversations, and agents. It supports for multiple LLM providers including OpenAI, Anthropic Claude, AWS Bedrock, and OpenRouter.
Raif is built by Cultivate Labs and is used to power ARC, an AI-powered research & analysis platform.
- Setup
- Chatting with the LLM
- Tasks
- Conversations
- Agents
- Model Tools
- Evals
- Images/Files/PDF's
- Embedding Models
- Web Admin
- Customization
- Testing
- Demo App
- Contributing
- License
View the setup guide.
View the chatting with the LLM docs.
We welcome contributions to Raif! Please see our Contributing Guide for details.
The gem is available as open source under the terms of the MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for raif
Similar Open Source Tools
raif
Raif is a lightweight Python library for analyzing text data. It provides functionalities for text preprocessing, feature extraction, and text classification. With Raif, users can easily clean and preprocess text data, extract relevant features, and build machine learning models for text classification tasks. The library is designed to be user-friendly and efficient, making it suitable for both beginners and experienced data scientists.
refly
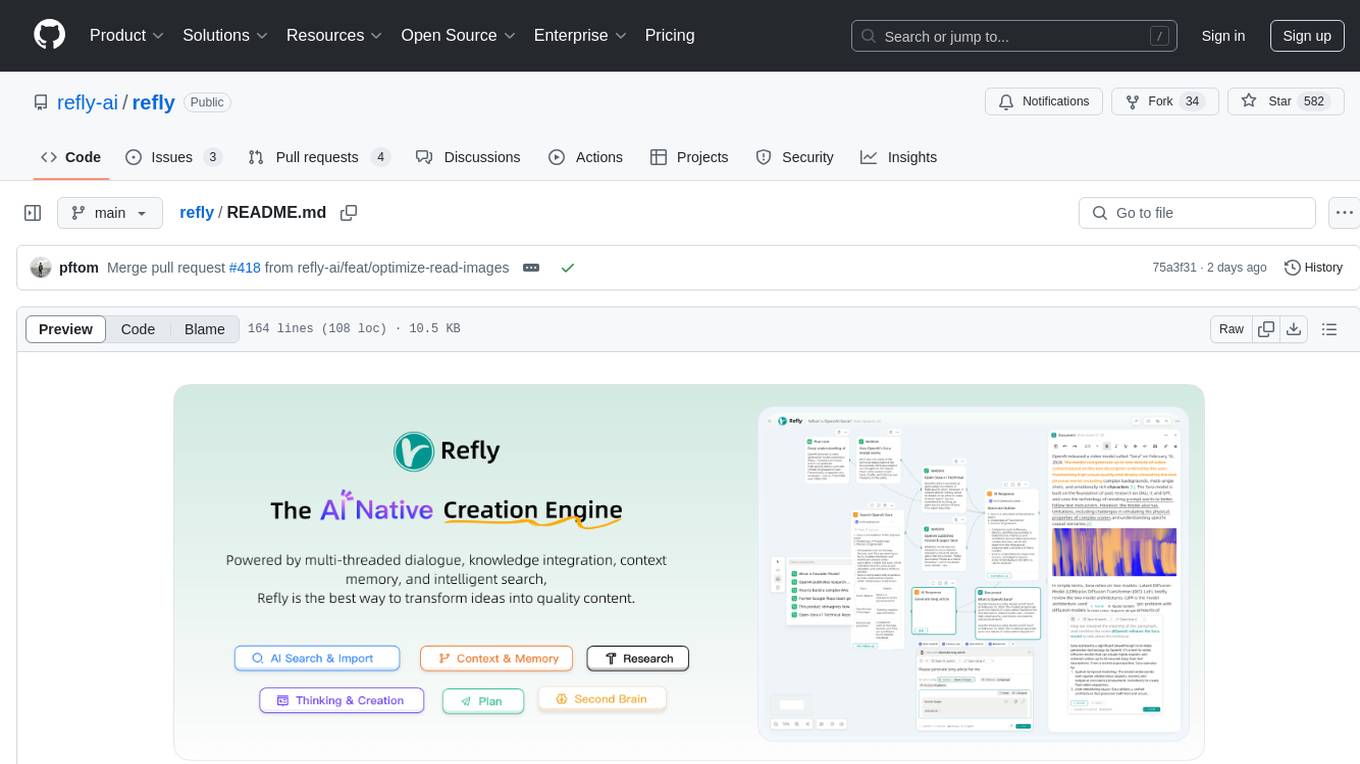
Refly.AI is an open-source AI-native creation engine that empowers users to transform ideas into production-ready content. It features a free-form canvas interface with multi-threaded conversations, knowledge base integration, contextual memory, intelligent search, WYSIWYG AI editor, and more. Users can leverage AI-powered capabilities, context memory, knowledge base integration, quotes, and AI document editing to enhance their content creation process. Refly offers both cloud and self-hosting options, making it suitable for individuals, enterprises, and organizations. The tool is designed to facilitate human-AI collaboration and streamline content creation workflows.

Geoweaver
Geoweaver is an in-browser software that enables users to easily compose and execute full-stack data processing workflows using online spatial data facilities, high-performance computation platforms, and open-source deep learning libraries. It provides server management, code repository, workflow orchestration software, and history recording capabilities. Users can run it from both local and remote machines. Geoweaver aims to make data processing workflows manageable for non-coder scientists and preserve model run history. It offers features like progress storage, organization, SSH connection to external servers, and a web UI with Python support.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.
oterm
Oterm is a text-based terminal client for Ollama, a large language model. It provides an intuitive and simple terminal UI, allowing users to interact with Ollama without running servers or frontends. Oterm supports multiple persistent chat sessions, which are stored along with context embeddings and system prompt customizations in a SQLite database. Users can easily customize the model's system prompt and parameters, and select from any of the models they have pulled in Ollama or their own custom models. Oterm also supports keyboard shortcuts for creating new chat sessions, editing existing sessions, renaming sessions, exporting sessions as markdown, deleting sessions, toggling between dark and light themes, quitting the application, switching to multiline input mode, selecting images to include with messages, and navigating through the history of previous prompts. Oterm is licensed under the MIT License.
rowfill
Rowfill is an open-source document processing platform designed for knowledge workers. It offers advanced AI capabilities to extract, analyze, and process data from complex documents, images, and PDFs. The platform features advanced OCR and processing functionalities, auto-schema generation, and custom actions for creating tailored workflows. It prioritizes privacy and security by supporting Local LLMs like Llama and Mistral, syncing with company data while maintaining privacy, and being open source with AGPLv3 licensing. Rowfill is a versatile tool that aims to streamline document processing tasks for users in various industries.
taipy
Taipy is an open-source Python library for easy, end-to-end application development, featuring what-if analyses, smart pipeline execution, built-in scheduling, and deployment tools.
ChatLab
ChatLab is a free, open-source, and local-first application dedicated to analyzing chat records. Through an AI Agent and a flexible SQL engine, you can freely dissect, query, and even reconstruct your social data. It provides ultimate performance, privacy protection, an intelligent AI Agent, multi-dimensional data visualization, and format standardization. The tool supports chat record analysis for various platforms like LINE, WeChat, QQ, WhatsApp, Instagram, and Discord. Users can export chat records, troubleshoot, and access standardized format specifications. The system architecture includes Electron Main Process, Worker and Data Pipeline, and Rendering Process. Local development setup steps are provided for Node.js environment. Contributions are welcome following specific guidelines. Users are advised to read the Privacy Policy & User Agreement before using the software. The tool is licensed under AGPL-3.0 License.

poml
POML (Prompt Orchestration Markup Language) is a novel markup language designed to bring structure, maintainability, and versatility to advanced prompt engineering for Large Language Models (LLMs). It addresses common challenges in prompt development, such as lack of structure, complex data integration, format sensitivity, and inadequate tooling. POML provides a systematic way to organize prompt components, integrate diverse data types seamlessly, and manage presentation variations, empowering developers to create more sophisticated and reliable LLM applications.
buildel
Buildel is an AI automation platform that empowers users to create versatile workflows without writing code. It supports multiple providers and interfaces, offers pre-built use cases, and allows users to bring their own API keys. Ideal for AI-powered document retrieval, conversational interfaces, and data integration. Users can get started at app.buildel.ai or run Buildel locally with Node.js, Elixir/Erlang, Docker, Git, and JQ installed. Join the community on Discord for support and discussions.

Genkit
Genkit is an open-source framework for building full-stack AI-powered applications, used in production by Google's Firebase. It provides SDKs for JavaScript/TypeScript (Stable), Go (Beta), and Python (Alpha) with unified interface for integrating AI models from providers like Google, OpenAI, Anthropic, Ollama. Rapidly build chatbots, automations, and recommendation systems using streamlined APIs for multimodal content, structured outputs, tool calling, and agentic workflows. Genkit simplifies AI integration with open-source SDK, unified APIs, and offers text and image generation, structured data generation, tool calling, prompt templating, persisted chat interfaces, AI workflows, and AI-powered data retrieval (RAG).
ten_framework
TEN Framework, short for Transformative Extensions Network, is the world's first real-time multimodal AI agent framework. It offers native support for high-performance, real-time multimodal interactions, supports multiple languages and platforms, enables edge-cloud integration, provides flexibility beyond model limitations, and allows for real-time agent state management. The framework facilitates the development of complex AI applications that transcend the limitations of large models by offering a drag-and-drop programming approach. It is suitable for scenarios like simultaneous interpretation, speech-to-text conversion, multilingual chat rooms, audio interaction, and audio-visual interaction.

genkit
Firebase Genkit (beta) is a framework with powerful tooling to help app developers build, test, deploy, and monitor AI-powered features with confidence. Genkit is cloud optimized and code-centric, integrating with many services that have free tiers to get started. It provides unified API for generation, context-aware AI features, evaluation of AI workflow, extensibility with plugins, easy deployment to Firebase or Google Cloud, observability and monitoring with OpenTelemetry, and a developer UI for prototyping and testing AI features locally. Genkit works seamlessly with Firebase or Google Cloud projects through official plugins and templates.
languine
Languine is a CLI tool that helps developers streamline the localization process by providing AI-powered translations, automation features, and developer-centric design. It allows users to easily manage translation files, maintain consistency in tone and style, and save time by automating tasks. With support for over 100 languages and smart detection capabilities, Languine simplifies the localization workflow for developers.

fenic
fenic is an opinionated DataFrame framework from typedef.ai for building AI and agentic applications. It transforms unstructured and structured data into insights using familiar DataFrame operations enhanced with semantic intelligence. With support for markdown, transcripts, and semantic operators, plus efficient batch inference across various model providers. fenic is purpose-built for LLM inference, providing a query engine designed for AI workloads, semantic operators as first-class citizens, native unstructured data support, production-ready infrastructure, and a familiar DataFrame API.
project-lakechain
Project Lakechain is a cloud-native, AI-powered framework for building document processing pipelines on AWS. It provides a composable API with built-in middlewares for common tasks, scalable architecture, cost efficiency, GPU and CPU support, and the ability to create custom transform middlewares. With ready-made examples and emphasis on modularity, Lakechain simplifies the deployment of scalable document pipelines for tasks like metadata extraction, NLP analysis, text summarization, translations, audio transcriptions, computer vision, and more.
For similar tasks

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.

adata
AData is a free and open-source A-share database that focuses on transaction-related data. It provides comprehensive data on stocks, including basic information, market data, and sentiment analysis. AData is designed to be easy to use and integrate with other applications, making it a valuable tool for quantitative trading and AI training.

PIXIU
PIXIU is a project designed to support the development, fine-tuning, and evaluation of Large Language Models (LLMs) in the financial domain. It includes components like FinBen, a Financial Language Understanding and Prediction Evaluation Benchmark, FIT, a Financial Instruction Dataset, and FinMA, a Financial Large Language Model. The project provides open resources, multi-task and multi-modal financial data, and diverse financial tasks for training and evaluation. It aims to encourage open research and transparency in the financial NLP field.

hezar
Hezar is an all-in-one AI library designed specifically for the Persian community. It brings together various AI models and tools, making it easy to use AI with just a few lines of code. The library seamlessly integrates with Hugging Face Hub, offering a developer-friendly interface and task-based model interface. In addition to models, Hezar provides tools like word embeddings, tokenizers, feature extractors, and more. It also includes supplementary ML tools for deployment, benchmarking, and optimization.

text-embeddings-inference
Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for popular models like FlagEmbedding, Ember, GTE, and E5. It implements features such as no model graph compilation step, Metal support for local execution on Macs, small docker images with fast boot times, token-based dynamic batching, optimized transformers code for inference using Flash Attention, Candle, and cuBLASLt, Safetensors weight loading, and production-ready features like distributed tracing with Open Telemetry and Prometheus metrics.

CodeProject.AI-Server
CodeProject.AI Server is a standalone, self-hosted, fast, free, and open-source Artificial Intelligence microserver designed for any platform and language. It can be installed locally without the need for off-device or out-of-network data transfer, providing an easy-to-use solution for developers interested in AI programming. The server includes a HTTP REST API server, backend analysis services, and the source code, enabling users to perform various AI tasks locally without relying on external services or cloud computing. Current capabilities include object detection, face detection, scene recognition, sentiment analysis, and more, with ongoing feature expansions planned. The project aims to promote AI development, simplify AI implementation, focus on core use-cases, and leverage the expertise of the developer community.

spark-nlp
Spark NLP is a state-of-the-art Natural Language Processing library built on top of Apache Spark. It provides simple, performant, and accurate NLP annotations for machine learning pipelines that scale easily in a distributed environment. Spark NLP comes with 36000+ pretrained pipelines and models in more than 200+ languages. It offers tasks such as Tokenization, Word Segmentation, Part-of-Speech Tagging, Named Entity Recognition, Dependency Parsing, Spell Checking, Text Classification, Sentiment Analysis, Token Classification, Machine Translation, Summarization, Question Answering, Table Question Answering, Text Generation, Image Classification, Image to Text (captioning), Automatic Speech Recognition, Zero-Shot Learning, and many more NLP tasks. Spark NLP is the only open-source NLP library in production that offers state-of-the-art transformers such as BERT, CamemBERT, ALBERT, ELECTRA, XLNet, DistilBERT, RoBERTa, DeBERTa, XLM-RoBERTa, Longformer, ELMO, Universal Sentence Encoder, Llama-2, M2M100, BART, Instructor, E5, Google T5, MarianMT, OpenAI GPT2, Vision Transformers (ViT), OpenAI Whisper, and many more not only to Python and R, but also to JVM ecosystem (Java, Scala, and Kotlin) at scale by extending Apache Spark natively.

scikit-llm
Scikit-LLM is a tool that seamlessly integrates powerful language models like ChatGPT into scikit-learn for enhanced text analysis tasks. It allows users to leverage large language models for various text analysis applications within the familiar scikit-learn framework. The tool simplifies the process of incorporating advanced language processing capabilities into machine learning pipelines, enabling users to benefit from the latest advancements in natural language processing.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.