
spider
Efficient Web Crawler and Scraper with AI Integration in Rust
Stars: 946
Spider is a high-performance web crawler and indexer designed to handle data curation workloads efficiently. It offers features such as concurrency, streaming, decentralization, headless Chrome rendering, HTTP proxies, cron jobs, subscriptions, smart mode, blacklisting, whitelisting, budgeting depth, dynamic AI prompt scripting, CSS scraping, and more. Users can easily get started with the Spider Cloud hosted service or set up local installations with spider-cli. The tool supports integration with Node.js and Python for additional flexibility. With a focus on speed and scalability, Spider is ideal for extracting and organizing data from the web.
README:
![]()


Website | Guides | API Docs | Chat
The fastest web crawler and indexer. Foundational building blocks for data curation workloads.
- Concurrent
- Streaming
- Decentralization
- Headless Chrome Rendering
- HTTP Proxies
- Cron Jobs
- Subscriptions
- Smart Mode
- Blacklisting, Whitelisting, and Budgeting Depth
- Dynamic AI Prompt Scripting Headless with Step Caching
- CSS Scraping with spider_utils
- Changelog
The simplest way to get started is to use the Spider Cloud hosted service. View the spider or spider_cli directory for local installations. You can also use spider with Node.js using spider-nodejs and Python using spider-py.
See BENCHMARKS.
See EXAMPLES.
This project is licensed under the MIT license.
See CONTRIBUTING.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for spider
Similar Open Source Tools
spider
Spider is a high-performance web crawler and indexer designed to handle data curation workloads efficiently. It offers features such as concurrency, streaming, decentralization, headless Chrome rendering, HTTP proxies, cron jobs, subscriptions, smart mode, blacklisting, whitelisting, budgeting depth, dynamic AI prompt scripting, CSS scraping, and more. Users can easily get started with the Spider Cloud hosted service or set up local installations with spider-cli. The tool supports integration with Node.js and Python for additional flexibility. With a focus on speed and scalability, Spider is ideal for extracting and organizing data from the web.
dreamfactory
DreamFactory is a self-hosted platform that provides governed API access to any data source for enterprise apps and local LLMs. It is a secure enterprise data access platform built on top of the Laravel framework, offering role-based access control, identity passthrough, and customization of API behavior using PHP, Python, and NodeJS scripting languages. DreamFactory allows users to generate powerful APIs for SQL and NoSQL databases, files, email, and push notifications in seconds, while ensuring security with features like user management, SSO authentication, OAuth, and Active Directory integration.
EDDI
E.D.D.I (Enhanced Dialog Driven Interface) is an enterprise-certified chatbot middleware that offers advanced prompt and conversation management for Conversational AI APIs. Developed in Java using Quarkus, it is lean, RESTful, scalable, and cloud-native. E.D.D.I is highly scalable and designed to efficiently manage conversations in AI-driven applications, with seamless API integration capabilities. Notable features include configurable NLP and Behavior rules, support for multiple chatbots running concurrently, and integration with MongoDB, OAuth 2.0, and HTML/CSS/JavaScript for UI. The project requires Java 21, Maven 3.8.4, and MongoDB >= 5.0 to run. It can be built as a Docker image and deployed using Docker or Kubernetes, with additional support for integration testing and monitoring through Prometheus and Kubernetes endpoints.

genkit
Firebase Genkit (beta) is a framework with powerful tooling to help app developers build, test, deploy, and monitor AI-powered features with confidence. Genkit is cloud optimized and code-centric, integrating with many services that have free tiers to get started. It provides unified API for generation, context-aware AI features, evaluation of AI workflow, extensibility with plugins, easy deployment to Firebase or Google Cloud, observability and monitoring with OpenTelemetry, and a developer UI for prototyping and testing AI features locally. Genkit works seamlessly with Firebase or Google Cloud projects through official plugins and templates.
ai-laravel
The Aimeos Laravel adapter allows integration of Aimeos web shop components into Laravel framework, leveraging native Laravel components for content caching, logging messages, session handling, generating URLs, and accessing the user table. Users of Laravel can quickly set up a web shop using the Aimeos Laravel package, saving time and effort in installation and configuration. The adapter is licensed under LGPLv3 and offers seamless integration with Laravel infrastructure for various functionalities like URL building, caching, logging, session management, email sending, and translations.
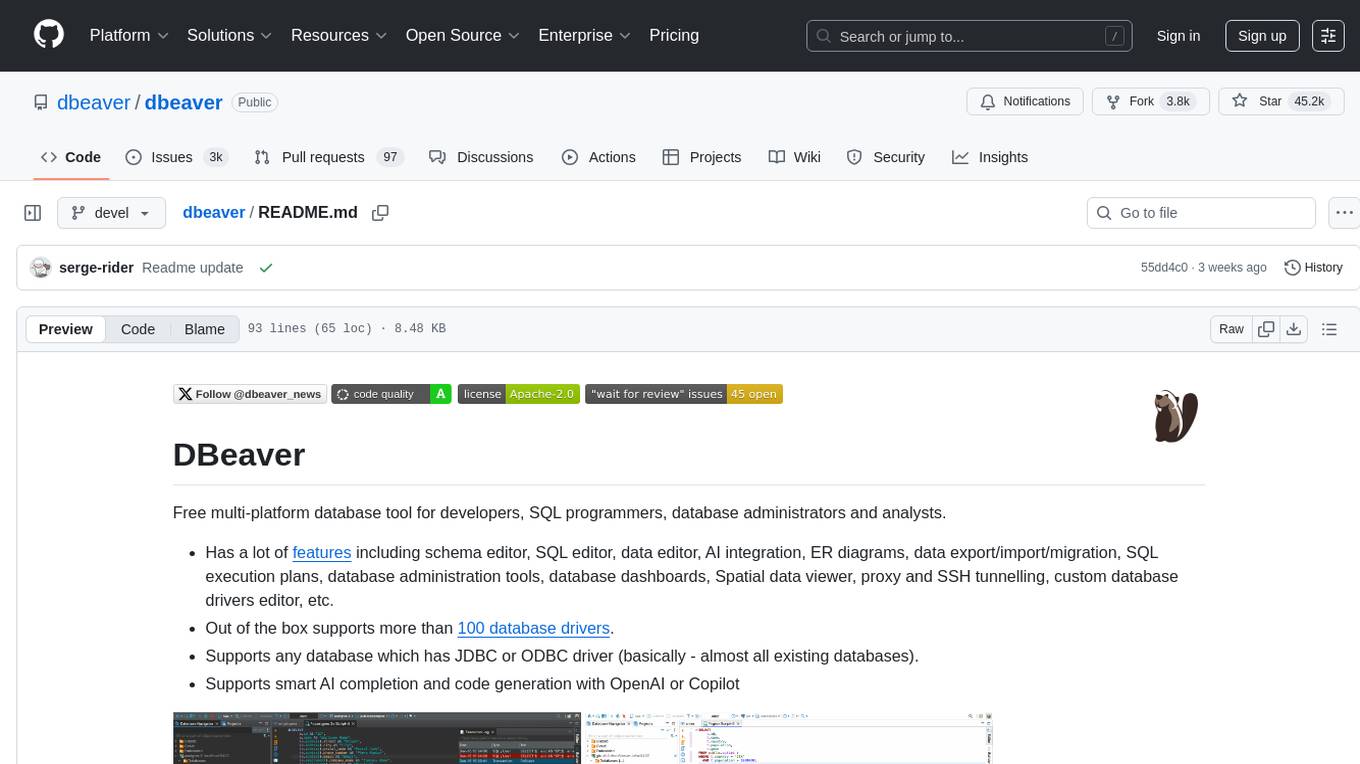
dbeaver
DBeaver is a free multi-platform database tool designed for developers, SQL programmers, database administrators, and analysts. It offers a wide range of features including schema editor, SQL editor, data editor, AI integration, ER diagrams, data export/import/migration, SQL execution plans, database administration tools, database dashboards, Spatial data viewer, proxy and SSH tunnelling, custom database drivers editor, etc. It supports over 100 database drivers out of the box and is compatible with any database that has a JDBC or ODBC driver. DBeaver also supports smart AI completion and code generation with OpenAI or Copilot.

Genkit
Genkit is an open-source framework for building full-stack AI-powered applications, used in production by Google's Firebase. It provides SDKs for JavaScript/TypeScript (Stable), Go (Beta), and Python (Alpha) with unified interface for integrating AI models from providers like Google, OpenAI, Anthropic, Ollama. Rapidly build chatbots, automations, and recommendation systems using streamlined APIs for multimodal content, structured outputs, tool calling, and agentic workflows. Genkit simplifies AI integration with open-source SDK, unified APIs, and offers text and image generation, structured data generation, tool calling, prompt templating, persisted chat interfaces, AI workflows, and AI-powered data retrieval (RAG).

Geoweaver
Geoweaver is an in-browser software that enables users to easily compose and execute full-stack data processing workflows using online spatial data facilities, high-performance computation platforms, and open-source deep learning libraries. It provides server management, code repository, workflow orchestration software, and history recording capabilities. Users can run it from both local and remote machines. Geoweaver aims to make data processing workflows manageable for non-coder scientists and preserve model run history. It offers features like progress storage, organization, SSH connection to external servers, and a web UI with Python support.
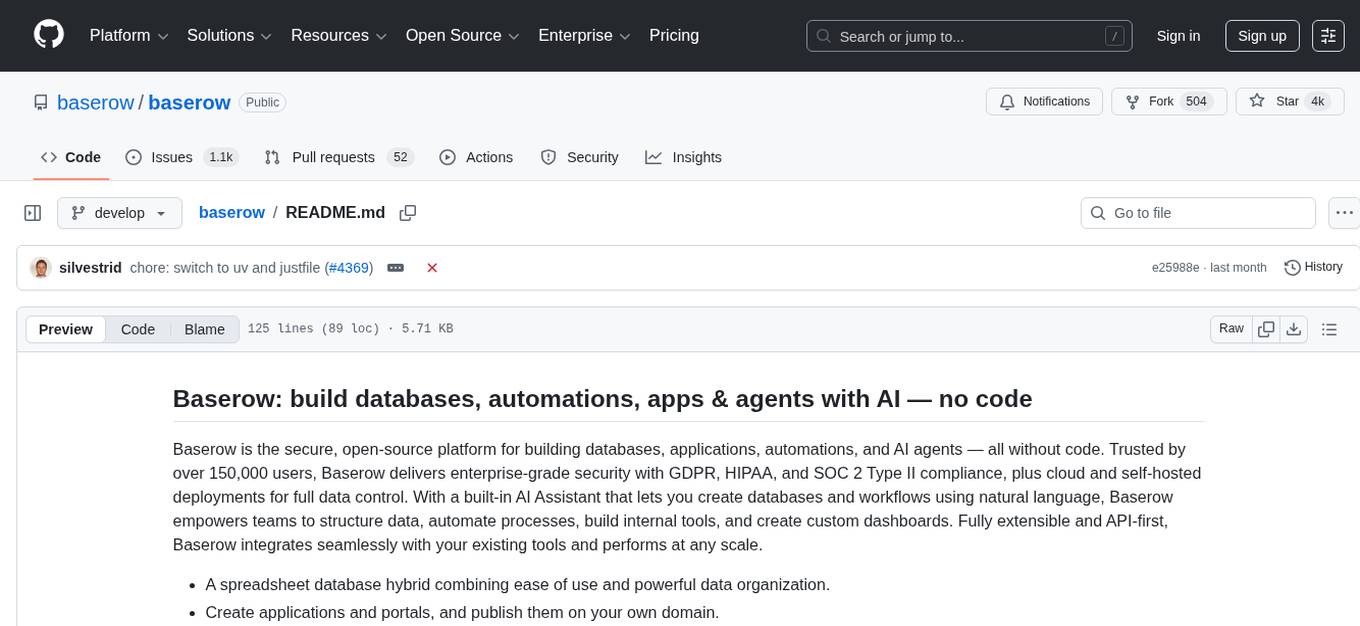
baserow
Baserow is a secure, open-source platform that allows users to build databases, applications, automations, and AI agents without writing any code. With enterprise-grade security compliance and both cloud and self-hosted deployment options, Baserow empowers teams to structure data, automate processes, create internal tools, and build custom dashboards. It features a spreadsheet database hybrid, AI Assistant for natural language database creation, GDPR, HIPAA, and SOC 2 Type II compliance, and seamless integration with existing tools. Baserow is API-first, extensible, and uses frameworks like Django, Vue.js, and PostgreSQL.
buildel
Buildel is an AI automation platform that empowers users to create versatile workflows without writing code. It supports multiple providers and interfaces, offers pre-built use cases, and allows users to bring their own API keys. Ideal for AI-powered document retrieval, conversational interfaces, and data integration. Users can get started at app.buildel.ai or run Buildel locally with Node.js, Elixir/Erlang, Docker, Git, and JQ installed. Join the community on Discord for support and discussions.
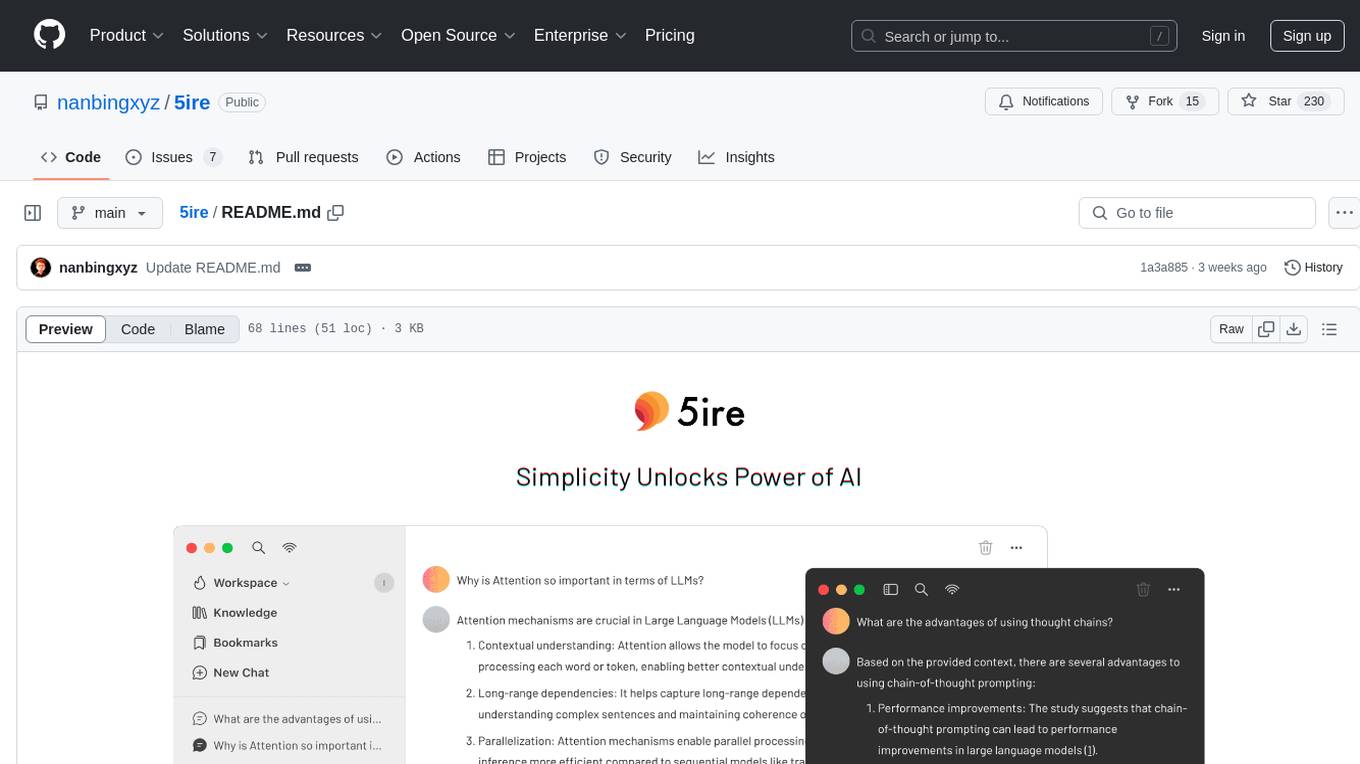
5ire
5ire is a cross-platform desktop client that integrates a local knowledge base for multilingual vectorization, supports parsing and vectorization of various document formats, offers usage analytics to track API spending, provides a prompts library for creating and organizing prompts with variable support, allows bookmarking of conversations, and enables quick keyword searches across conversations. It is licensed under the GNU General Public License version 3.
goose
Codename Goose is an open-source, extensible AI agent designed to provide functionalities beyond code suggestions. Users can install, execute, edit, and test with any LLM. The tool aims to enhance the coding experience by offering advanced features and capabilities. Stay updated for the upcoming 1.0 release scheduled by the end of January 2025. Explore the v0.X documentation available on the project's GitHub pages.
Memoh
Memoh is a multi-member, structured long-memory, containerized AI agent system platform that allows users to create AI bots for communication via platforms like Telegram, Discord, and Lark. Each bot operates in its own isolated container with a memory system for file editing, command execution, and self-building. Memoh offers a secure, flexible, and scalable solution for multi-bot management, distinguishing and remembering requests from multiple users and bots.

raif
Raif is a lightweight Python library for analyzing text data. It provides functionalities for text preprocessing, feature extraction, and text classification. With Raif, users can easily clean and preprocess text data, extract relevant features, and build machine learning models for text classification tasks. The library is designed to be user-friendly and efficient, making it suitable for both beginners and experienced data scientists.
ai-typo3
The Aimeos TYPO3 adapter is an extension that integrates Aimeos web shop components into the TYPO3 CMS. It leverages native TYPO3 components for content caching, sending mails, session handling, and generating URLs. By using the Aimeos TYPO3 package, users can quickly set up a web shop within minutes without the need for manual installation and configuration. The extension is licensed under LGPLv3 and offers seamless integration with TYPO3 infrastructure for various functionalities like URL building, content caching, email sending, and translation handling.

super-agent-party
A 3D AI desktop companion with endless possibilities! This repository provides a platform for enhancing the LLM API without code modification, supporting seamless integration of various functionalities such as knowledge bases, real-time networking, multimodal capabilities, automation, and deep thinking control. It offers one-click deployment to multiple terminals, ecological tool interconnection, standardized interface opening, and compatibility across all platforms. Users can deploy the tool on Windows, macOS, Linux, or Docker, and access features like intelligent agent deployment, VRM desktop pets, Tavern character cards, QQ bot deployment, and developer-friendly interfaces. The tool supports multi-service providers, extensive tool integration, and ComfyUI workflows. Hardware requirements are minimal, making it suitable for various deployment scenarios.
For similar tasks

Awesome-Segment-Anything
Awesome-Segment-Anything is a powerful tool for segmenting and extracting information from various types of data. It provides a user-friendly interface to easily define segmentation rules and apply them to text, images, and other data formats. The tool supports both supervised and unsupervised segmentation methods, allowing users to customize the segmentation process based on their specific needs. With its versatile functionality and intuitive design, Awesome-Segment-Anything is ideal for data analysts, researchers, content creators, and anyone looking to efficiently extract valuable insights from complex datasets.

Time-LLM
Time-LLM is a reprogramming framework that repurposes large language models (LLMs) for time series forecasting. It allows users to treat time series analysis as a 'language task' and effectively leverage pre-trained LLMs for forecasting. The framework involves reprogramming time series data into text representations and providing declarative prompts to guide the LLM reasoning process. Time-LLM supports various backbone models such as Llama-7B, GPT-2, and BERT, offering flexibility in model selection. The tool provides a general framework for repurposing language models for time series forecasting tasks.

crewAI
CrewAI is a cutting-edge framework designed to orchestrate role-playing autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks. It enables AI agents to assume roles, share goals, and operate in a cohesive unit, much like a well-oiled crew. Whether you're building a smart assistant platform, an automated customer service ensemble, or a multi-agent research team, CrewAI provides the backbone for sophisticated multi-agent interactions. With features like role-based agent design, autonomous inter-agent delegation, flexible task management, and support for various LLMs, CrewAI offers a dynamic and adaptable solution for both development and production workflows.
Transformers_And_LLM_Are_What_You_Dont_Need
Transformers_And_LLM_Are_What_You_Dont_Need is a repository that explores the limitations of transformers in time series forecasting. It contains a collection of papers, articles, and theses discussing the effectiveness of transformers and LLMs in this domain. The repository aims to provide insights into why transformers may not be the best choice for time series forecasting tasks.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package for time series forecasting with state-of-the-art network architectures. It offers a high-level API for training networks on pandas data frames and utilizes PyTorch Lightning for scalable training on GPUs and CPUs. The package aims to simplify time series forecasting with neural networks by providing a flexible API for professionals and default settings for beginners. It includes a timeseries dataset class, base model class, multiple neural network architectures, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. PyTorch Forecasting is built on pytorch-lightning for easy training on various hardware configurations.
spider
Spider is a high-performance web crawler and indexer designed to handle data curation workloads efficiently. It offers features such as concurrency, streaming, decentralization, headless Chrome rendering, HTTP proxies, cron jobs, subscriptions, smart mode, blacklisting, whitelisting, budgeting depth, dynamic AI prompt scripting, CSS scraping, and more. Users can easily get started with the Spider Cloud hosted service or set up local installations with spider-cli. The tool supports integration with Node.js and Python for additional flexibility. With a focus on speed and scalability, Spider is ideal for extracting and organizing data from the web.
AI_for_Science_paper_collection
AI for Science paper collection is an initiative by AI for Science Community to collect and categorize papers in AI for Science areas by subjects, years, venues, and keywords. The repository contains `.csv` files with paper lists labeled by keys such as `Title`, `Conference`, `Type`, `Application`, `MLTech`, `OpenReviewLink`. It covers top conferences like ICML, NeurIPS, and ICLR. Volunteers can contribute by updating existing `.csv` files or adding new ones for uncovered conferences/years. The initiative aims to track the increasing trend of AI for Science papers and analyze trends in different applications.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package designed for state-of-the-art timeseries forecasting using deep learning architectures. It offers a high-level API and leverages PyTorch Lightning for efficient training on GPU or CPU with automatic logging. The package aims to simplify timeseries forecasting tasks by providing a flexible API for professionals and user-friendly defaults for beginners. It includes features such as a timeseries dataset class for handling data transformations, missing values, and subsampling, various neural network architectures optimized for real-world deployment, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. Built on pytorch-lightning, it supports training on CPUs, single GPUs, and multiple GPUs out-of-the-box.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.