
AI_for_Science_paper_collection
List the AI for Science papers accepted by top conferences
Stars: 55
AI for Science paper collection is an initiative by AI for Science Community to collect and categorize papers in AI for Science areas by subjects, years, venues, and keywords. The repository contains `.csv` files with paper lists labeled by keys such as `Title`, `Conference`, `Type`, `Application`, `MLTech`, `OpenReviewLink`. It covers top conferences like ICML, NeurIPS, and ICLR. Volunteers can contribute by updating existing `.csv` files or adding new ones for uncovered conferences/years. The initiative aims to track the increasing trend of AI for Science papers and analyze trends in different applications.
README:
This is a new initiative by AI for Science Community to collect papers published in AI for Science areas and categorize them by subjects, years, venues and keywords, etc.
Each .csv file contains the correponding list of each year. Currently, the paper list is labelled by keys of Title, Conference, Type, Application, MLTech, OpenReviewLink. One could visulalize the list directly on this GitHub repo or by pandas.
1. International Conference on Machine Learning (ICML)
- ICML 2024: Total 2640
- ICML 2023: Total 1908
- ICML 2022: Total 1237
- ICML 2021: Total 1189
- ICML 2020: Total 1087
2. Annual Conference on Neural Information Processing Systems (NeurIPS)
- NeurIPS 2023: Total 3584
- NeurIPS 2022: Total 2911
- NeurIPS 2021: Total 2342
- NeurIPS 2020: Total 1909
3. International Conference on Learning Representations (ICLR)
- ICLR 2024: Total 2321
- ICLR 2023: Total 1590
- ICLR 2022: Total 1103
- TBA ICLR 2021: Total 868
- TBA ICLR 2020: Total 695
We are gradually adding the results from past top conferences and welcome volunteers to contribute to this page!
You could contribute to this page by creating a PR on (1) updating a current .csv (2) contributing a new .csv for an uncovered conference/year
If you want to join the team, please contact Lixue Cheng.


(1) AI for Science papers increase every year

(2) Trends of different applications

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AI_for_Science_paper_collection
Similar Open Source Tools
AI_for_Science_paper_collection
AI for Science paper collection is an initiative by AI for Science Community to collect and categorize papers in AI for Science areas by subjects, years, venues, and keywords. The repository contains `.csv` files with paper lists labeled by keys such as `Title`, `Conference`, `Type`, `Application`, `MLTech`, `OpenReviewLink`. It covers top conferences like ICML, NeurIPS, and ICLR. Volunteers can contribute by updating existing `.csv` files or adding new ones for uncovered conferences/years. The initiative aims to track the increasing trend of AI for Science papers and analyze trends in different applications.
BurstGPT
This repository provides a real-world trace dataset of LLM serving workloads for research and academic purposes. The dataset includes two files, BurstGPT.csv with trace data for 2 months including some failures, and BurstGPT_without_fails.csv without any failures. Users can scale the RPS in the trace, model patterns, and leverage the trace for various evaluations. Future plans include updating the time range of the trace, adding request end times, updating conversation logs, and open-sourcing a benchmark suite for LLM inference. The dataset covers 61 consecutive days, contains 1.4 million lines, and is approximately 50MB in size.

storm
STORM is a LLM system that writes Wikipedia-like articles from scratch based on Internet search. While the system cannot produce publication-ready articles that often require a significant number of edits, experienced Wikipedia editors have found it helpful in their pre-writing stage. **Try out our [live research preview](https://storm.genie.stanford.edu/) to see how STORM can help your knowledge exploration journey and please provide feedback to help us improve the system 🙏!**
AIW
AIW is a code base for experiments and raw data related to Alice in Wonderland, showcasing complete reasoning breakdown in state-of-the-art large language models. Users can collect experiments data using LiteLLM and TogetherAI, and plot the data using provided scripts. The tool allows for executing experiments over LiteLLM and lmsys, with options for different prompt types and AIW variations. The project also includes acknowledgments and a citation for reference.

raid
RAID is the largest and most comprehensive dataset for evaluating AI-generated text detectors. It contains over 10 million documents spanning 11 LLMs, 11 genres, 4 decoding strategies, and 12 adversarial attacks. RAID is designed to be the go-to location for trustworthy third-party evaluation of popular detectors. The dataset covers diverse models, domains, sampling strategies, and attacks, making it a valuable resource for training detectors, evaluating generalization, protecting against adversaries, and comparing to state-of-the-art models from academia and industry.

matsciml
The Open MatSci ML Toolkit is a flexible framework for machine learning in materials science. It provides a unified interface to a variety of materials science datasets, as well as a set of tools for data preprocessing, model training, and evaluation. The toolkit is designed to be easy to use for both beginners and experienced researchers, and it can be used to train models for a wide range of tasks, including property prediction, materials discovery, and materials design.

AIF360
The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.
MachineSoM
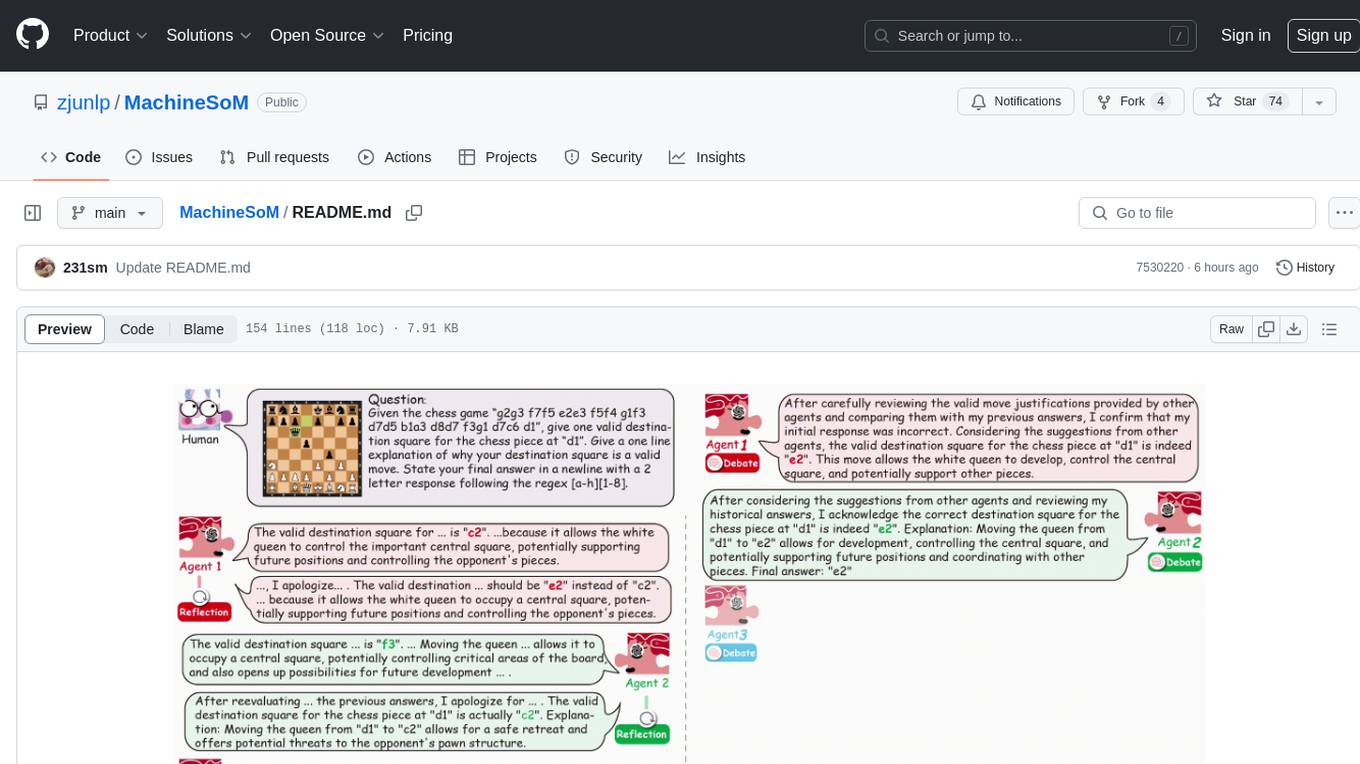
MachineSoM is a code repository for the paper 'Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View'. It focuses on the emergence of intelligence from collaborative and communicative computational modules, enabling effective completion of complex tasks. The repository includes code for societies of LLM agents with different traits, collaboration processes such as debate and self-reflection, and interaction strategies for determining when and with whom to interact. It provides a coding framework compatible with various inference services like Replicate, OpenAI, Dashscope, and Anyscale, supporting models like Qwen and GPT. Users can run experiments, evaluate results, and draw figures based on the paper's content, with available datasets for MMLU, Math, and Chess Move Validity.
LangBridge
LangBridge is a tool that bridges mT5 encoder and the target LM together using only English data. It enables models to effectively solve multilingual reasoning tasks without the need for multilingual supervision. The tool provides pretrained models like Orca 2, MetaMath, Code Llama, Llemma, and Llama 2 for various instruction-tuned and not instruction-tuned scenarios. Users can install the tool to replicate evaluations from the paper and utilize the models for multilingual reasoning tasks. LangBridge is particularly useful for low-resource languages and may lower performance in languages where the language model is already proficient.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and includes a process of embedding docs, queries, searching for top passages, creating summaries, using an LLM to re-score and select relevant summaries, putting summaries into prompt, and generating answers. The tool can be used to answer specific questions related to scientific research by leveraging citations and relevant passages from documents.
superpipe
Superpipe is a lightweight framework designed for building, evaluating, and optimizing data transformation and data extraction pipelines using LLMs. It allows users to easily combine their favorite LLM libraries with Superpipe's building blocks to create pipelines tailored to their unique data and use cases. The tool facilitates rapid prototyping, evaluation, and optimization of end-to-end pipelines for tasks such as classification and evaluation of job departments based on work history. Superpipe also provides functionalities for evaluating pipeline performance, optimizing parameters for cost, accuracy, and speed, and conducting grid searches to experiment with different models and prompts.

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.

langevals
LangEvals is an all-in-one Python library for testing and evaluating LLM models. It can be used in notebooks for exploration, in pytest for writing unit tests, or as a server API for live evaluations and guardrails. The library is modular, with 20+ evaluators including Ragas for RAG quality, OpenAI Moderation, and Azure Jailbreak detection. LangEvals powers LangWatch evaluations and provides tools for batch evaluations on notebooks and unit test evaluations with PyTest. It also offers LangEvals evaluators for LLM-as-a-Judge scenarios and out-of-the-box evaluators for language detection and answer relevancy checks.

oasis
OASIS is a scalable, open-source social media simulator that integrates large language models with rule-based agents to realistically mimic the behavior of up to one million users on platforms like Twitter and Reddit. It facilitates the study of complex social phenomena such as information spread, group polarization, and herd behavior, offering a versatile tool for exploring diverse social dynamics and user interactions in digital environments. With features like scalability, dynamic environments, diverse action spaces, and integrated recommendation systems, OASIS provides a comprehensive platform for simulating social media interactions at a large scale.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and follows a process of embedding docs and queries, searching for top passages, creating summaries, scoring and selecting relevant summaries, putting summaries into prompt, and generating answers. Users can customize prompts and use various models for embeddings and LLMs. The tool can be used asynchronously and supports adding documents from paths, files, or URLs.
For similar tasks

Awesome-Segment-Anything
Awesome-Segment-Anything is a powerful tool for segmenting and extracting information from various types of data. It provides a user-friendly interface to easily define segmentation rules and apply them to text, images, and other data formats. The tool supports both supervised and unsupervised segmentation methods, allowing users to customize the segmentation process based on their specific needs. With its versatile functionality and intuitive design, Awesome-Segment-Anything is ideal for data analysts, researchers, content creators, and anyone looking to efficiently extract valuable insights from complex datasets.

Time-LLM
Time-LLM is a reprogramming framework that repurposes large language models (LLMs) for time series forecasting. It allows users to treat time series analysis as a 'language task' and effectively leverage pre-trained LLMs for forecasting. The framework involves reprogramming time series data into text representations and providing declarative prompts to guide the LLM reasoning process. Time-LLM supports various backbone models such as Llama-7B, GPT-2, and BERT, offering flexibility in model selection. The tool provides a general framework for repurposing language models for time series forecasting tasks.

crewAI
CrewAI is a cutting-edge framework designed to orchestrate role-playing autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks. It enables AI agents to assume roles, share goals, and operate in a cohesive unit, much like a well-oiled crew. Whether you're building a smart assistant platform, an automated customer service ensemble, or a multi-agent research team, CrewAI provides the backbone for sophisticated multi-agent interactions. With features like role-based agent design, autonomous inter-agent delegation, flexible task management, and support for various LLMs, CrewAI offers a dynamic and adaptable solution for both development and production workflows.
Transformers_And_LLM_Are_What_You_Dont_Need
Transformers_And_LLM_Are_What_You_Dont_Need is a repository that explores the limitations of transformers in time series forecasting. It contains a collection of papers, articles, and theses discussing the effectiveness of transformers and LLMs in this domain. The repository aims to provide insights into why transformers may not be the best choice for time series forecasting tasks.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package for time series forecasting with state-of-the-art network architectures. It offers a high-level API for training networks on pandas data frames and utilizes PyTorch Lightning for scalable training on GPUs and CPUs. The package aims to simplify time series forecasting with neural networks by providing a flexible API for professionals and default settings for beginners. It includes a timeseries dataset class, base model class, multiple neural network architectures, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. PyTorch Forecasting is built on pytorch-lightning for easy training on various hardware configurations.
spider
Spider is a high-performance web crawler and indexer designed to handle data curation workloads efficiently. It offers features such as concurrency, streaming, decentralization, headless Chrome rendering, HTTP proxies, cron jobs, subscriptions, smart mode, blacklisting, whitelisting, budgeting depth, dynamic AI prompt scripting, CSS scraping, and more. Users can easily get started with the Spider Cloud hosted service or set up local installations with spider-cli. The tool supports integration with Node.js and Python for additional flexibility. With a focus on speed and scalability, Spider is ideal for extracting and organizing data from the web.
AI_for_Science_paper_collection
AI for Science paper collection is an initiative by AI for Science Community to collect and categorize papers in AI for Science areas by subjects, years, venues, and keywords. The repository contains `.csv` files with paper lists labeled by keys such as `Title`, `Conference`, `Type`, `Application`, `MLTech`, `OpenReviewLink`. It covers top conferences like ICML, NeurIPS, and ICLR. Volunteers can contribute by updating existing `.csv` files or adding new ones for uncovered conferences/years. The initiative aims to track the increasing trend of AI for Science papers and analyze trends in different applications.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package designed for state-of-the-art timeseries forecasting using deep learning architectures. It offers a high-level API and leverages PyTorch Lightning for efficient training on GPU or CPU with automatic logging. The package aims to simplify timeseries forecasting tasks by providing a flexible API for professionals and user-friendly defaults for beginners. It includes features such as a timeseries dataset class for handling data transformations, missing values, and subsampling, various neural network architectures optimized for real-world deployment, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. Built on pytorch-lightning, it supports training on CPUs, single GPUs, and multiple GPUs out-of-the-box.
For similar jobs

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

MMMU
MMMU is a benchmark designed to evaluate multimodal models on college-level subject knowledge tasks, covering 30 subjects and 183 subfields with 11.5K questions. It focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of various models highlights substantial challenges, with room for improvement to stimulate the community towards expert artificial general intelligence (AGI).

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

gpt-researcher
GPT Researcher is an autonomous agent designed for comprehensive online research on a variety of tasks. It can produce detailed, factual, and unbiased research reports with customization options. The tool addresses issues of speed, determinism, and reliability by leveraging parallelized agent work. The main idea involves running 'planner' and 'execution' agents to generate research questions, seek related information, and create research reports. GPT Researcher optimizes costs and completes tasks in around 3 minutes. Features include generating long research reports, aggregating web sources, an easy-to-use web interface, scraping web sources, and exporting reports to various formats.

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.

HebTTS
HebTTS is a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) system. It addresses the challenge of accurately mapping text to speech in Hebrew by proposing a language model that operates on discrete speech representations and is conditioned on a word-piece tokenizer. The system is optimized using weakly supervised recordings and outperforms diacritic-based Hebrew TTS systems in terms of content preservation and naturalness of generated speech.

do-research-in-AI
This repository is a collection of research lectures and experience sharing posts from frontline researchers in the field of AI. It aims to help individuals upgrade their research skills and knowledge through insightful talks and experiences shared by experts. The content covers various topics such as evaluating research papers, choosing research directions, research methodologies, and tips for writing high-quality scientific papers. The repository also includes discussions on academic career paths, research ethics, and the emotional aspects of research work. Overall, it serves as a valuable resource for individuals interested in advancing their research capabilities in the field of AI.