
raid
RAID is the largest and most challenging benchmark for AI-generated text detection. (ACL 2024)
Stars: 146

RAID is the largest and most comprehensive dataset for evaluating AI-generated text detectors. It contains over 10 million documents spanning 11 LLMs, 11 genres, 4 decoding strategies, and 12 adversarial attacks. RAID is designed to be the go-to location for trustworthy third-party evaluation of popular detectors. The dataset covers diverse models, domains, sampling strategies, and attacks, making it a valuable resource for training detectors, evaluating generalization, protecting against adversaries, and comparing to state-of-the-art models from academia and industry.
README:
Open Leaderboards. Trustworthy Evaluation. Robust AI Detection.


RAID is the largest & most comprehensive dataset for evaluating AI-generated text detectors. It contains over 10 million documents spanning 11 LLMs, 11 genres, 4 decoding strategies, and 12 adversarial attacks. It is designed to be the go-to location for trustworthy third-party evaluation of popular detectors.
|
Installation pip install raid-bench |
|
| Example Usage | |
|---|---|
from raid import run_detection, run_evaluation
from raid.utils import load_data
# Define your detector function
def my_detector(texts: list[str]) -> list[float]:
pass
# Download & Load the RAID dataset
train_df = load_data(split="train")
# Run your detector on the dataset
predictions = run_detection(my_detector, train_df)
# Evaluate your detector predictions
evaluation_result = run_evaluation(predictions, train_df)
|
|
With RAID you can:
- 🔬 Train Detectors: Use our dataset to train large robust detector models
- 🔄 Evaluate Generalization: Ensure your detectors maintain high performance across popular generators and domains
- 🤝 Protect Against Adversaries: Maintain high performance under common adversarial attacks
- 📊 Compare to SOTA: Compare your detector to state-of-the-art models from academia and industry.
- [Jan 15 2025] The results of the Shared Task are now public! Check out the Shared Task Leaderboard or read our Paper for the full analysis. Thanks so much to all who entered the competition!
- [Sep 24 2024] ANNOUNCEMENT - RAID will appear as a Shared Task at COLING 2025! See the Github and Website for more details! Submission Deadline is October 25th 2024.
The RAID dataset includes over 10 million generations from the following categories:
| Category | Values |
|---|---|
| Models | ChatGPT, GPT-4, GPT-3 (text-davinci-003), GPT-2 XL, Llama 2 70B (Chat), Cohere, Cohere (Chat), MPT-30B, MPT-30B (Chat), Mistral 7B, Mistral 7B (Chat) |
| Domains | ArXiv Abstracts, Recipes, Reddit Posts, Book Summaries, NYT News Articles, Poetry, IMDb Movie Reviews, Wikipedia, Czech News, German News, Python Code |
| Decoding Strategies | Greedy (T=0), Sampling (T=1), Greedy + Repetition Penalty (T=0, Θ=1.2), Sampling + Repetition Penalty (T=1, Θ=1.2) |
| Adversarial Attacks | Article Deletion, Homoglyph, Number Swap, Paraphrase, Synonym Swap, Misspelling, Whitespace Addition, Upper-Lower Swap, Zero-Width Space, Insert Paragraphs, Alternative Spelling |

RAID is the only dataset that covers diverse models, domains, sampling strategies, and attacks
See our ACL 2024 paper for a more detailed comparison
The partitions of the RAID dataset we provide are broken down as follows:
| Labels? | Domains | Dataset Size (w/o adversarial) | Dataset Size (w/ adversarial) | |
|---|---|---|---|---|
| RAID-train | ✅ | News, Books, Abstracts, Reviews, Reddit, Recipes, Wikipedia, Poetry | 802M | 11.8G |
| RAID-test | ❌ | News, Books, Abstracts, Reviews, Reddit, Recipes, Wikipedia, Poetry | 81.0M | 1.22G |
| RAID-extra | ✅ | Code, Czech, German | 275M | 3.71G |
To download RAID via the pypi package, run
from raid.utils import load_data
# Download the RAID dataset with adversarial attacks included
train_df = load_data(split="train")
test_df = load_data(split="test")
extra_df = load_data(split="extra")
# Download the RAID dataset without adversarial attacks
train_noadv_df = load_data(split="train", include_adversarial=False)
test_noadv_df = load_data(split="test", include_adversarial=False)
extra_noadv_df = load_data(split="extra", include_adversarial=False)You can also manually download the data using wget
$ wget https://dataset.raid-bench.xyz/train.csv
$ wget https://dataset.raid-bench.xyz/test.csv
$ wget https://dataset.raid-bench.xyz/extra.csv
$ wget https://dataset.raid-bench.xyz/train_none.csv
$ wget https://dataset.raid-bench.xyz/test_none.csv
$ wget https://dataset.raid-bench.xyz/extra_none.csv
NEW: You can also now download RAID through the HuggingFace Datasets 🤗 Library
from datasets import load_dataset
raid = load_dataset("liamdugan/raid")To submit to the leaderboard, you must first get predictions for your detector on the test set. You can do so using either the pypi package or the CLI:
import json
from raid import run_detection, run_evaluation
from raid.utils import load_data
# Define your detector function
def my_detector(texts: list[str]) -> list[float]:
pass
# Load the RAID test data
test_df = load_data(split="test")
# Run your detector on the dataset
predictions = run_detection(my_detector, test_df)
with open('predictions.json') as f:
json.dump(predictions, f)$ python detect_cli.py -m my_detector -d test.csv -o predictions.json
After you have the predictions.json file you must then write a metadata file for your submission. Your metadata file should use the template found in
this repository at leaderboard/template-metadata.json.
Finally, fork this repository. Add your generation files to leaderboard/submissions/YOUR-DETECTOR-NAME/predictions.json and your metadata file to leaderboard/submissions/YOUR-DETECTOR-NAME/metadata.json and make a pull request to this repository.
Our GitHub bot will automatically run evaluations on the submitted predictions and commit the results to
leaderboard/submissions/YOUR-DETECTOR-NAME/results.json. If all looks well, a maintainer will merge the PR and your
model will appear on the leaderboards!
[!NOTE] You may submit multiple detectors in a single PR - each detector should have its own directory.
If you want to run the detectors we have implemented or use our dataset generation code you should install from source. To do so first clone the repository. Then install in your virtual environment of choice
Conda:
conda create -n raid_env python=3.9.7
conda activate raid_env
pip install -r requirements.txt
venv:
python -m venv env
source env/bin/activate
pip install -r requirements.txt
Then, populate the set_api_keys.sh file with the API keys for your desired modules (OpenAI, Cohere, API detectors, etc.). After that, run source set_api_keys.sh to set the API key evironment variables.
To apply a detector to the dataset through our CLI run detect_cli.py and evaluate_cli.py. These wrap around the run_detection and run_evaluation functions from the pypi package. The options are listed below. See detectors/detector.py for a list of valid detector names.
$ python detect_cli.py -h
-m, --model The name of the detector model you wish to run
-d, --data_path The path to the csv file with the dataset
-o, --output_path The path to write the result JSON file
$ python evaluate_cli.py -h
-r, --results_path The path to the detection result JSON to evaluate
-d, --data_path The path to the csv file with the dataset
-o, --output_path The path to write the result JSON file
-t, --target_fpr The target FPR to evaluate at (Default: 0.05)
Example:
$ python detect_cli.py -m gltr -d train.csv -o gltr_predictions.json
$ python evaluate_cli.py -i gltr_predictions.json -d train.csv -o gltr_result.json
The output of evaluate_cli.py will be a JSON file containing the accuracy of the detector on each split of the RAID dataset at the target false positive rate as well as the thresholds found for the detector.
If you would like to implement your own detector and still run it via the CLI, you must add it to detectors/detector.py so that it can be called via command line argument.
After installing from source, you can also run any of the adversarial attacks from the paper.
To do this, navigate to the generation/adversarial subfolder and run the following
Example:
from attack import get_attack
attack_name = "homoglyph"
a = get_attack(attack_name)
print(a.attack("Hello World"))This will print a dictionary with the attacked text, the number of edits, and the indices of the edits in the string.
{'generation': 'Ηеllо Wоrld', 'num_edits': 4, 'edits': [(0, 1), (1, 2), (4, 5), (7, 8)]}
The list of all valid inputs to get_attack is listed below:
["homoglyph", "number", "article_deletion", "insert_paragraphs", "perplexity_misspelling", "upper_lower", "whitespace", "zero_width_space", "synonym", "paraphrase", "alternative_spelling"]
(This can also be found in generation/adversarial/attack.py)
If you use our code or findings in your research, please cite us as:
@inproceedings{dugan-etal-2024-raid,
title = "{RAID}: A Shared Benchmark for Robust Evaluation of Machine-Generated Text Detectors",
author = "Dugan, Liam and
Hwang, Alyssa and
Trhl{\'\i}k, Filip and
Zhu, Andrew and
Ludan, Josh Magnus and
Xu, Hainiu and
Ippolito, Daphne and
Callison-Burch, Chris",
booktitle = "Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = aug,
year = "2024",
address = "Bangkok, Thailand",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.acl-long.674",
pages = "12463--12492",
}
This research is supported in part by the Office of the Director of National Intelligence (ODNI), Intelligence Advanced Research Projects Activity (IARPA), via the HIATUS Program contract #2022-22072200005. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of ODNI, IARPA, or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for governmental purposes notwithstanding any copyright annotation therein.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for raid
Similar Open Source Tools
raid
RAID is the largest and most comprehensive dataset for evaluating AI-generated text detectors. It contains over 10 million documents spanning 11 LLMs, 11 genres, 4 decoding strategies, and 12 adversarial attacks. RAID is designed to be the go-to location for trustworthy third-party evaluation of popular detectors. The dataset covers diverse models, domains, sampling strategies, and attacks, making it a valuable resource for training detectors, evaluating generalization, protecting against adversaries, and comparing to state-of-the-art models from academia and industry.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

chromem-go
chromem-go is an embeddable vector database for Go with a Chroma-like interface and zero third-party dependencies. It enables retrieval augmented generation (RAG) and similar embeddings-based features in Go apps without the need for a separate database. The focus is on simplicity and performance for common use cases, allowing querying of documents with minimal memory allocations. The project is in beta and may introduce breaking changes before v1.0.0.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and includes a process of embedding docs, queries, searching for top passages, creating summaries, using an LLM to re-score and select relevant summaries, putting summaries into prompt, and generating answers. The tool can be used to answer specific questions related to scientific research by leveraging citations and relevant passages from documents.

OpenMusic
OpenMusic is a repository providing an implementation of QA-MDT, a Quality-Aware Masked Diffusion Transformer for music generation. The code integrates state-of-the-art models and offers training strategies for music generation. The repository includes implementations of AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. Users can train or fine-tune the model using different strategies and datasets. The model is well-pretrained and can be used for music generation tasks. The repository also includes instructions for preparing datasets, training the model, and performing inference. Contact information is provided for any questions or suggestions regarding the project.

langevals
LangEvals is an all-in-one Python library for testing and evaluating LLM models. It can be used in notebooks for exploration, in pytest for writing unit tests, or as a server API for live evaluations and guardrails. The library is modular, with 20+ evaluators including Ragas for RAG quality, OpenAI Moderation, and Azure Jailbreak detection. LangEvals powers LangWatch evaluations and provides tools for batch evaluations on notebooks and unit test evaluations with PyTest. It also offers LangEvals evaluators for LLM-as-a-Judge scenarios and out-of-the-box evaluators for language detection and answer relevancy checks.

qa-mdt
This repository provides an implementation of QA-MDT, integrating state-of-the-art models for music generation. It offers a Quality-Aware Masked Diffusion Transformer for enhanced music generation. The code is based on various repositories like AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. The implementation allows for training and fine-tuning the model with different strategies and datasets. The repository also includes instructions for preparing datasets in LMDB format and provides a script for creating a toy LMDB dataset. The model can be used for music generation tasks, with a focus on quality injection to enhance the musicality of generated music.

npcsh
`npcsh` is a python-based command-line tool designed to integrate Large Language Models (LLMs) and Agents into one's daily workflow by making them available and easily configurable through the command line shell. It leverages the power of LLMs to understand natural language commands and questions, execute tasks, answer queries, and provide relevant information from local files and the web. Users can also build their own tools and call them like macros from the shell. `npcsh` allows users to take advantage of agents (i.e. NPCs) through a managed system, tailoring NPCs to specific tasks and workflows. The tool is extensible with Python, providing useful functions for interacting with LLMs, including explicit coverage for popular providers like ollama, anthropic, openai, gemini, deepseek, and openai-like providers. Users can set up a flask server to expose their NPC team for use as a backend service, run SQL models defined in their project, execute assembly lines, and verify the integrity of their NPC team's interrelations. Users can execute bash commands directly, use favorite command-line tools like VIM, Emacs, ipython, sqlite3, git, pipe the output of these commands to LLMs, or pass LLM results to bash commands.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.

VMind
VMind is an open-source solution for intelligent visualization, providing an intelligent chart component based on LLM by VisActor. It allows users to create chart narrative works with natural language interaction, edit charts through dialogue, and export narratives as videos or GIFs. The tool is easy to use, scalable, supports various chart types, and offers one-click export functionality. Users can customize chart styles, specify themes, and aggregate data using LLM models. VMind aims to enhance efficiency in creating data visualization works through dialogue-based editing and natural language interaction.

continuous-eval
Open-Source Evaluation for LLM Applications. `continuous-eval` is an open-source package created for granular and holistic evaluation of GenAI application pipelines. It offers modularized evaluation, a comprehensive metric library covering various LLM use cases, the ability to leverage user feedback in evaluation, and synthetic dataset generation for testing pipelines. Users can define their own metrics by extending the Metric class. The tool allows running evaluation on a pipeline defined with modules and corresponding metrics. Additionally, it provides synthetic data generation capabilities to create user interaction data for evaluation or training purposes.

marqo
Marqo is more than a vector database, it's an end-to-end vector search engine for both text and images. Vector generation, storage and retrieval are handled out of the box through a single API. No need to bring your own embeddings.

invariant
Invariant Analyzer is an open-source scanner designed for LLM-based AI agents to find bugs, vulnerabilities, and security threats. It scans agent execution traces to identify issues like looping behavior, data leaks, prompt injections, and unsafe code execution. The tool offers a library of built-in checkers, an expressive policy language, data flow analysis, real-time monitoring, and extensible architecture for custom checkers. It helps developers debug AI agents, scan for security violations, and prevent security issues and data breaches during runtime. The analyzer leverages deep contextual understanding and a purpose-built rule matching engine for security policy enforcement.
superpipe
Superpipe is a lightweight framework designed for building, evaluating, and optimizing data transformation and data extraction pipelines using LLMs. It allows users to easily combine their favorite LLM libraries with Superpipe's building blocks to create pipelines tailored to their unique data and use cases. The tool facilitates rapid prototyping, evaluation, and optimization of end-to-end pipelines for tasks such as classification and evaluation of job departments based on work history. Superpipe also provides functionalities for evaluating pipeline performance, optimizing parameters for cost, accuracy, and speed, and conducting grid searches to experiment with different models and prompts.

MemoryLLM
MemoryLLM is a large language model designed for self-updating capabilities. It offers pretrained models with different memory capacities and features, such as chat models. The repository provides training code, evaluation scripts, and datasets for custom experiments. MemoryLLM aims to enhance knowledge retention and performance on various natural language processing tasks.
gritlm
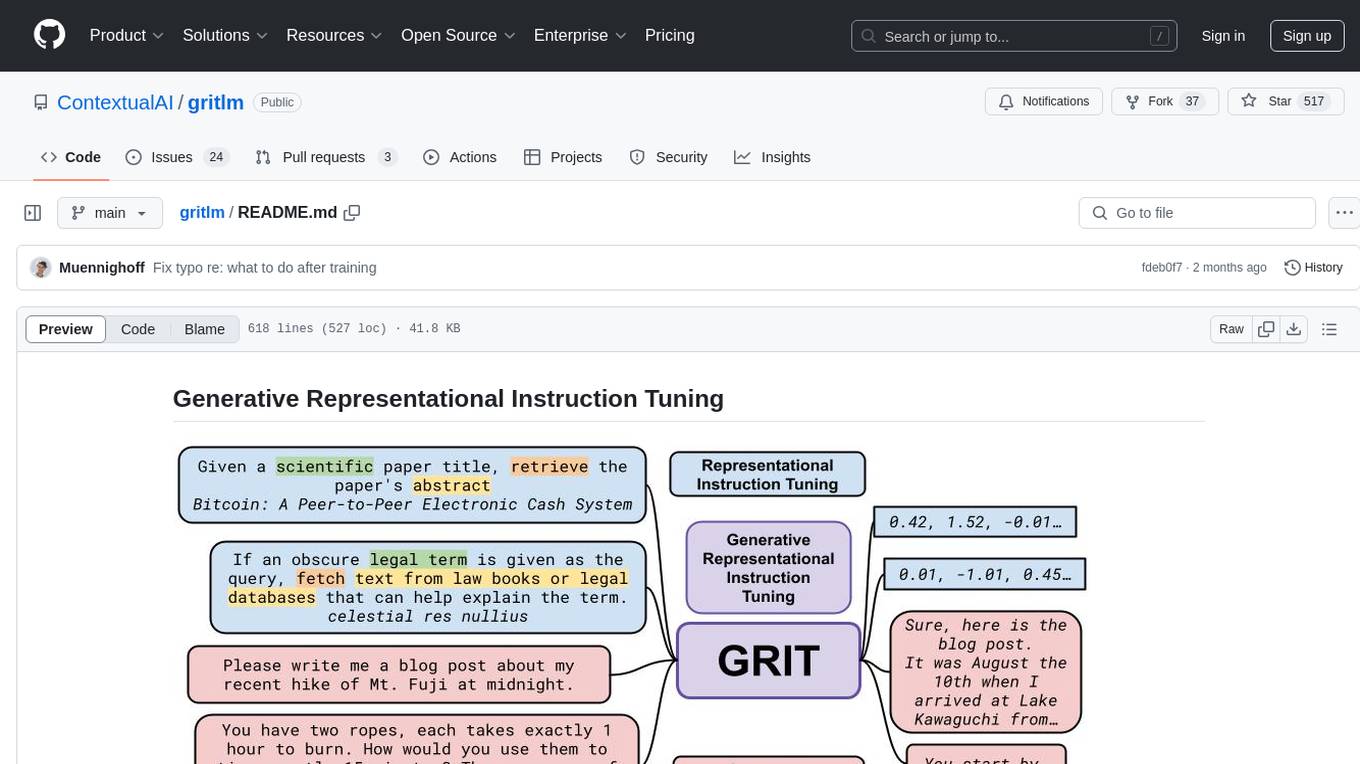
The 'gritlm' repository provides all materials for the paper Generative Representational Instruction Tuning. It includes code for inference, training, evaluation, and known issues related to the GritLM model. The repository also offers models for embedding and generation tasks, along with instructions on how to train and evaluate the models. Additionally, it contains visualizations, acknowledgements, and a citation for referencing the work.
For similar tasks
raid
RAID is the largest and most comprehensive dataset for evaluating AI-generated text detectors. It contains over 10 million documents spanning 11 LLMs, 11 genres, 4 decoding strategies, and 12 adversarial attacks. RAID is designed to be the go-to location for trustworthy third-party evaluation of popular detectors. The dataset covers diverse models, domains, sampling strategies, and attacks, making it a valuable resource for training detectors, evaluating generalization, protecting against adversaries, and comparing to state-of-the-art models from academia and industry.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.