
OSWorld
[NeurIPS 2024] OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Stars: 2561

OSWorld is a benchmarking tool designed to evaluate multimodal agents for open-ended tasks in real computer environments. It provides a platform for running experiments, setting up virtual machines, and interacting with the environment using Python scripts. Users can install the tool on their desktop or server, manage dependencies with Conda, and run benchmark tasks. The tool supports actions like executing commands, checking for specific results, and evaluating agent performance. OSWorld aims to facilitate research in AI by providing a standardized environment for testing and comparing different agent baselines.
README:

Website • Paper • Doc • Data • Data Viewer • Discord • Cache

- 2025-07-28: Introducing OSWorld-Verified! We have made major updates, fixed several issues reported by the community, with more support for AWS (can reduce evaluation time to within 1 hour through parallelization!), and making the benchmark signals more effective. Check out more in the report. We have run new model results in the latest version and updated them on the official website. Please compare your OSWorld results with the new benchmark results when running the latest version.
- 2025-05-01: If you need pre-downloaded files for init state setup, we downloaded for you here.
- 2024-10-22: We supported Docker🐳 for hosting virtual machines on virtualized platforms. Check below for detailed instructions!
- 2024-06-15: We refactor the code of environment part to decompose VMware Integration, and start to support other platforms such as VirtualBox, AWS, Azure, etc. Hold tight!
- 2024-04-11: We released our paper, environment and benchmark, and project page. Check it out!
Suppose you are operating on a system that has not been virtualized (e.g. your desktop, laptop, bare metal machine), meaning you are not utilizing a virtualized environment like AWS, Azure, or k8s. If this is the case, proceed with the instructions below. However, if you are on a virtualized platform, please refer to the Docker section.
- First, clone this repository and
cdinto it. Then, install the dependencies listed inrequirements.txt. It is recommended that you use the latest version of Conda to manage the environment, but you can also choose to manually install the dependencies. Please ensure that the version of Python is >= 3.10.
# Clone the OSWorld repository
git clone https://github.com/xlang-ai/OSWorld
# Change directory into the cloned repository
cd OSWorld
# Optional: Create a Conda environment for OSWorld
# conda create -n osworld python=3.10
# conda activate osworld
# Install required dependencies
pip install -r requirements.txtAlternatively, you can install the environment without any benchmark tasks:
pip install desktop-env- Install VMware Workstation Pro (for systems with Apple Chips, you should install VMware Fusion) and configure the
vmruncommand. The installation process can refer to How to install VMware Workstation Pro. Verify the successful installation by running the following:
vmrun -T ws listIf the installation along with the environment variable set is successful, you will see the message showing the current running virtual machines.
Note: We also support using VirtualBox if you have issues with VMware Pro. However, features such as parallelism and macOS on Apple chips might not be well-supported.
All set! Our setup script will automatically download the necessary virtual machines and configure the environment for you.
If you are running on a non-bare metal server, or prefer not to use VMware and VirtualBox platforms, we recommend using our Docker support.
We recommend running the VM with KVM support. To check if your hosting platform supports KVM, run
egrep -c '(vmx|svm)' /proc/cpuinfo
on Linux. If the return value is greater than zero, the processor should be able to support KVM.
Note: macOS hosts generally do not support KVM. You are advised to use VMware if you would like to run OSWorld on macOS.
If your hosting platform supports a graphical user interface (GUI), you may refer to Install Docker Desktop on Linux or Install Docker Desktop on Windows based on your OS. Otherwise, you may Install Docker Engine.
Add the following arguments when initializing DesktopEnv:
-
provider_name:docker -
os_type:UbuntuorWindows, depending on the OS of the VM
Note: If the experiment is interrupted abnormally (e.g., by interrupting signals), there may be residual docker containers which could affect system performance over time. Please run
docker stop $(docker ps -q) && docker rm $(docker ps -a -q)to clean up.
Using cloud services for parallel evaluation can significantly accelerate evaluation efficiency (can reduce evaluation time to within 1 hour through parallelization!) and can even be used as infrastructure for training. We provide comprehensive AWS support with a Host-Client architecture that enables large-scale parallel evaluation of OSWorld tasks. For detailed setup instructions, see Setup Guideline and AWS Configuration Guide.
We are working on supporting more 👷. Please hold tight!
Run the following minimal example to interact with the environment:
# Basic usage with default settings
python quickstart.py
# Customize provider and VM path
python quickstart.py --provider_name vmware --path_to_vm "path/to/your/vm.vmx"You will see all the logs of the system running normally, including the successful creation of the environment, completion of setup, and successful execution of actions. In the end, you will observe a successful right-click on the screen, which means you are ready to go.
⚠️ Important Configuration Requirements:
- Google Account Tasks: Some tasks require Google account access and OAuth2.0 configuration. Please refer to Setup Guideline - Google Account Setup for detailed setup instructions.
- Proxy Configuration: Some tasks may require proxy settings to function properly (this depends on the strength of website defenses against your network location). Please refer to Setup Guideline - Proxy Configuration.
- Impact of Missing Configuration: If these configurations are not properly set up, the corresponding tasks will fail to execute correctly, leading to lower evaluation scores.
If you wish to run the baseline agent used in our paper, you can execute the following command as an example under the GPT-4o pure-screenshot setting:
Set OPENAI_API_KEY environment variable with your API key
export OPENAI_API_KEY='changeme'Optionally, set OPENAI_BASE_URL to use a custom OpenAI-compatible API endpoint
export OPENAI_BASE_URL='http://your-custom-endpoint.com/v1' # Optional: defaults to https://api.openai.comSingle-threaded execution (deprecated, using vmware provider as example)
python run.py \
--provider_name vmware \
--path_to_vm Ubuntu/Ubuntu.vmx \
--headless \
--observation_type screenshot \
--model gpt-4o \
--sleep_after_execution 3 \
--max_steps 15 \
--result_dir ./results \
--client_password passwordParallel execution (example showing switching provider to docker)
python scripts/python/run_multienv.py \
--provider_name docker \
--headless \
--observation_type screenshot \
--model gpt-4o \
--sleep_after_execution 3 \
--max_steps 15 \
--num_envs 10 \
--client_password passwordThe results, which include screenshots, actions, and video recordings of the agent's task completion, will be saved in the ./results (or other result_dir you specified) directory in this case.
You can then run the following command to obtain the result:
# Basic usage with default parameters
python show_result.py
# Specify custom parameters
python show_result.py \
--action_space pyautogui \
--model gpt-4o \
--observation_type screenshot \
--result_dir ./results
# Show detailed scores per domain (format: score/total)
python show_result.py --detailedThe script will display:
- Per-domain success rates
- Category-level statistics (Office, Daily, Professional)
- Overall success rate and total score
- With
--detailedflag: compact format showing "score/total" for each domain
For manual verification and examination of specific benchmark tasks, you can use the manual examination tool:
python scripts/python/manual_examine.py \
--headless \
--observation_type screenshot \
--result_dir ./results_human_examine \
--test_all_meta_path evaluation_examples/test_all.json \
--domain libreoffice_impress \
--example_id a669ef01-ded5-4099-9ea9-25e99b569840 \
--max_steps 3This tool allows you to:
- Manually execute tasks in the environment
- Verify task correctness and evaluation metrics
- Record the execution process with screenshots and videos
- Examine specific problematic tasks
See scripts/bash/run_manual_examine.sh for example task IDs across different domains.
Please start by reading through the agent interface and the environment interface.
Correctly implement the agent interface and import your customized version in the run.py (for single-threaded execution) or scripts/python/run_multienv.py / scripts/python/run_multienv_xxx.py (for parallel execution) file.
Afterward, you can execute a command similar to the one in the previous section to run the benchmark on your agent.
If you want your results to be verified and displayed on the verified leaderboard, you need to schedule a meeting with us (current maintainer: [email protected], [email protected]) to run your agent code on our side and have us report the results. You need to upload and allow us to disclose your agent implementation under the OSWorld framework (you may choose not to expose your model API to the public), along with a report that allows the public to understand what's happening behind the scenes. Alternatively, if you are from a trusted institution, you can share your monitoring data and trajectories with us. Please carefully follow the Setup Guideline - Public Evaluation Platform to get results.
The username and password for the virtual machines are as follows (for provider vmware, virtualbox and docker): we set the account credentials for Ubuntu as user / password.
For cloud service providers like aws, to prevent attacks due to weak passwords, we default to osworld-public-evaluation.
If you make further modifications, remember to set the client_password variable and pass it to DesktopEnv and Agent (if supported) when running experiments.
Some features like setting up proxy require the environment to have the client VM password to obtain sudo privileges, and for some OSWorld tasks, the agent needs the password to obtain sudo privileges to complete them.
See Setup Guideline - Google Account Setup.
How can I configure a proxy for the VM (if I'm behind the GFW, or I don't want some of my tasks to be identified as bot and get lower scores)?
See Setup Guideline - Proxy Configuration. We also provide a pre-configured solution based on DataImpulse, please refer to the proxy setup section.
Thanks to all the contributors!
If you find this environment useful, please consider citing our work:
@misc{OSWorld,
title={OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments},
author={Tianbao Xie and Danyang Zhang and Jixuan Chen and Xiaochuan Li and Siheng Zhao and Ruisheng Cao and Toh Jing Hua and Zhoujun Cheng and Dongchan Shin and Fangyu Lei and Yitao Liu and Yiheng Xu and Shuyan Zhou and Silvio Savarese and Caiming Xiong and Victor Zhong and Tao Yu},
year={2024},
eprint={2404.07972},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
Special thanks to the following institutions that provided feedback and participated in the fixes (as well as institutions that provided feedback during the process): MoonShot AI, a.k.a. Kimi,Human Data, OpenAI, ByteDance Seed TARS, Anthropic, Simular, HKU Data Intelligence Lab
Special thanks to the following students who participated in the specific fixes: Mengqi Yuan, Danyang Zhang, Xinzhuang Xiong, Zhennan Shen, Zilong Zhou, Yanxu Chen, Jiaqi Deng, Tianbao Xie, Junda Chen, Jixuan Chen, Haoyuan Wu.
Special thanks to the following students who participated in running the re-evaluation: Mengqi Yuan, Zilong Zhou, Xinyuan Wang, Bowen Wang.
- OSWorld-MCP: Benchmarking MCP Tool Invocation in Computer-Use Agents. Website
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for OSWorld
Similar Open Source Tools
OSWorld
OSWorld is a benchmarking tool designed to evaluate multimodal agents for open-ended tasks in real computer environments. It provides a platform for running experiments, setting up virtual machines, and interacting with the environment using Python scripts. Users can install the tool on their desktop or server, manage dependencies with Conda, and run benchmark tasks. The tool supports actions like executing commands, checking for specific results, and evaluating agent performance. OSWorld aims to facilitate research in AI by providing a standardized environment for testing and comparing different agent baselines.

jaison-core
J.A.I.son is a Python project designed for generating responses using various components and applications. It requires specific plugins like STT, T2T, TTSG, and TTSC to function properly. Users can customize responses, voice, and configurations. The project provides a Discord bot, Twitch events and chat integration, and VTube Studio Animation Hotkeyer. It also offers features for managing conversation history, training AI models, and monitoring conversations.

LARS
LARS is an application that enables users to run Large Language Models (LLMs) locally on their devices, upload their own documents, and engage in conversations where the LLM grounds its responses with the uploaded content. The application focuses on Retrieval Augmented Generation (RAG) to increase accuracy and reduce AI-generated inaccuracies. LARS provides advanced citations, supports various file formats, allows follow-up questions, provides full chat history, and offers customization options for LLM settings. Users can force enable or disable RAG, change system prompts, and tweak advanced LLM settings. The application also supports GPU-accelerated inferencing, multiple embedding models, and text extraction methods. LARS is open-source and aims to be the ultimate RAG-centric LLM application.

SWELancer-Benchmark
SWE-Lancer is a benchmark repository containing datasets and code for the paper 'SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?'. It provides instructions for package management, building Docker images, configuring environment variables, and running evaluations. Users can use this tool to assess the performance of language models in real-world freelance software engineering tasks.

gpustack
GPUStack is an open-source GPU cluster manager designed for running large language models (LLMs). It supports a wide variety of hardware, scales with GPU inventory, offers lightweight Python package with minimal dependencies, provides OpenAI-compatible APIs, simplifies user and API key management, enables GPU metrics monitoring, and facilitates token usage and rate metrics tracking. The tool is suitable for managing GPU clusters efficiently and effectively.
uwazi
Uwazi is a flexible database application designed for capturing and organizing collections of information, with a focus on document management. It is developed and supported by HURIDOCS, benefiting human rights organizations globally. The tool requires NodeJs, ElasticSearch, ICU Analysis Plugin, MongoDB, Yarn, and pdftotext for installation. It offers production and development installation guides, including Docker setup. Uwazi supports hot reloading, unit and integration testing with JEST, and end-to-end testing with Nightmare or Puppeteer. The system requirements include RAM, CPU, and disk space recommendations for on-premises and development usage.

ai-starter-kit
SambaNova AI Starter Kits is a collection of open-source examples and guides designed to facilitate the deployment of AI-driven use cases for developers and enterprises. The kits cover various categories such as Data Ingestion & Preparation, Model Development & Optimization, Intelligent Information Retrieval, and Advanced AI Capabilities. Users can obtain a free API key using SambaNova Cloud or deploy models using SambaStudio. Most examples are written in Python but can be applied to any programming language. The kits provide resources for tasks like text extraction, fine-tuning embeddings, prompt engineering, question-answering, image search, post-call analysis, and more.

agentok
Agentok Studio is a visual tool built for AutoGen, a cutting-edge agent framework from Microsoft and various contributors. It offers intuitive visual tools to simplify the construction and management of complex agent-based workflows. Users can create workflows visually as graphs, chat with agents, and share flow templates. The tool is designed to streamline the development process for creators and developers working on next-generation Multi-Agent Applications.
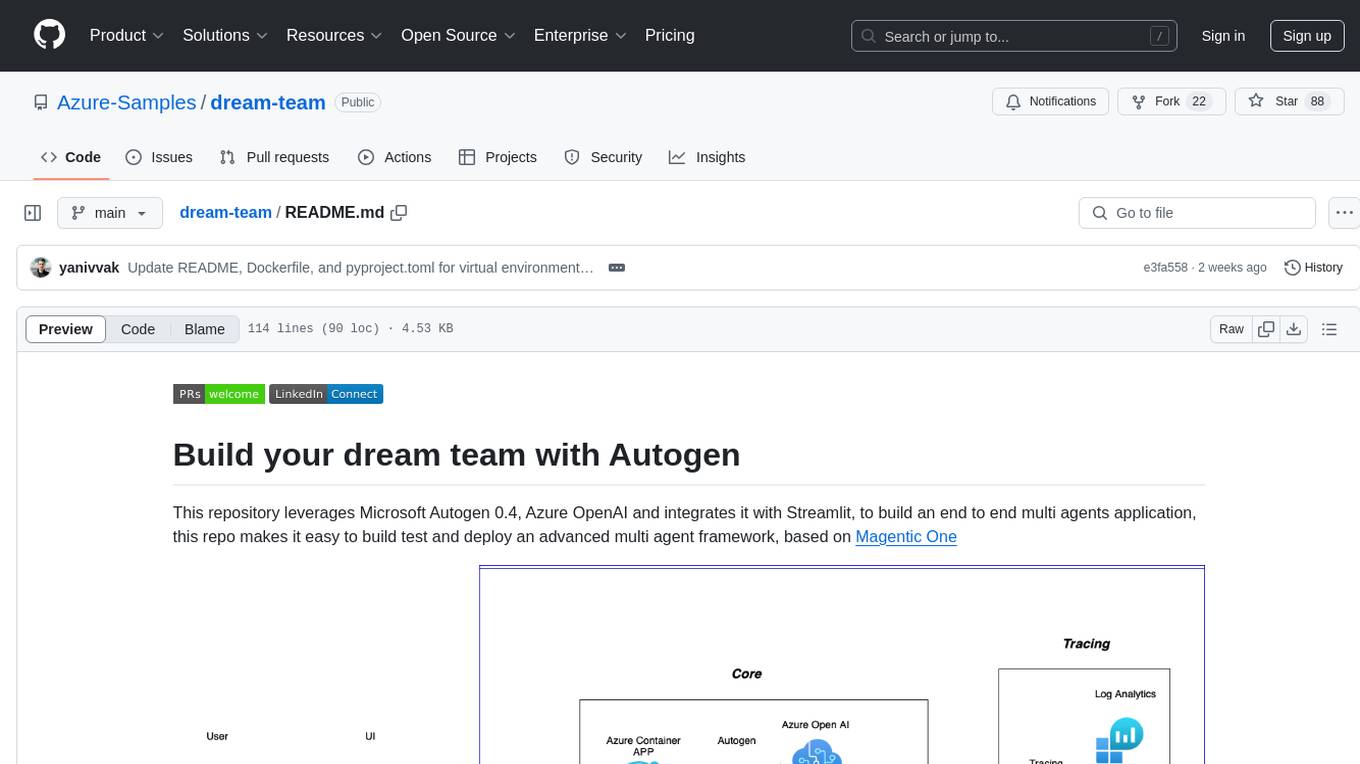
dream-team
Build your dream team with Autogen is a repository that leverages Microsoft Autogen 0.4, Azure OpenAI, and Streamlit to create an end-to-end multi-agent application. It provides an advanced multi-agent framework based on Magentic One, with features such as a friendly UI, single-line deployment, secure code execution, managed identities, and observability & debugging tools. Users can deploy Azure resources and the app with simple commands, work locally with virtual environments, install dependencies, update configurations, and run the application. The repository also offers resources for learning more about building applications with Autogen.
mint-bench
MINT benchmark aims to evaluate LLMs' ability to solve tasks with multi-turn interactions by (1) using tools and (2) leveraging natural language feedback.

azure-search-openai-javascript
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access the ChatGPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval.

geti-sdk
The Intel® Geti™ SDK is a python package that enables teams to rapidly develop AI models by easing the complexities of model development and enhancing collaboration between teams. It provides tools to interact with an Intel® Geti™ server via the REST API, allowing for project creation, downloading, uploading, deploying for local inference with OpenVINO, setting project and model configuration, launching and monitoring training jobs, and media upload and prediction. The SDK also includes tutorial-style Jupyter notebooks demonstrating its usage.

geti-sdk
The Intel® Geti™ SDK is a python package that enables teams to rapidly develop AI models by easing the complexities of model development and fostering collaboration. It provides tools to interact with an Intel® Geti™ server via the REST API, allowing for project creation, downloading, uploading, deploying for local inference with OpenVINO, configuration management, training job monitoring, media upload, and prediction. The repository also includes tutorial-style Jupyter notebooks demonstrating SDK usage.
AgentIQ
AgentIQ is a flexible library designed to seamlessly integrate enterprise agents with various data sources and tools. It enables true composability by treating agents, tools, and workflows as simple function calls. With features like framework agnosticism, reusability, rapid development, profiling, observability, evaluation system, user interface, and MCP compatibility, AgentIQ empowers developers to move quickly, experiment freely, and ensure reliability across agent-driven projects.
holohub
Holohub is a central repository for the NVIDIA Holoscan AI sensor processing community to share reference applications, operators, tutorials, and benchmarks. It includes example applications, community components, package configurations, and tutorials. Users and developers of the Holoscan platform are invited to reuse and contribute to this repository. The repository provides detailed instructions on prerequisites, building, running applications, contributing, and glossary terms. It also offers a searchable catalog of available components on the Holoscan SDK User Guide website.
aiarena-web
aiarena-web is a website designed for running the aiarena.net infrastructure. It consists of different modules such as core functionality, web API endpoints, frontend templates, and a module for linking users to their Patreon accounts. The website serves as a platform for obtaining new matches, reporting results, featuring match replays, and connecting with Patreon supporters. The project is licensed under GPLv3 in 2019.
For similar tasks
OSWorld
OSWorld is a benchmarking tool designed to evaluate multimodal agents for open-ended tasks in real computer environments. It provides a platform for running experiments, setting up virtual machines, and interacting with the environment using Python scripts. Users can install the tool on their desktop or server, manage dependencies with Conda, and run benchmark tasks. The tool supports actions like executing commands, checking for specific results, and evaluating agent performance. OSWorld aims to facilitate research in AI by providing a standardized environment for testing and comparing different agent baselines.
LLM-Agents-Papers
A repository that lists papers related to Large Language Model (LLM) based agents. The repository covers various topics including survey, planning, feedback & reflection, memory mechanism, role playing, game playing, tool usage & human-agent interaction, benchmark & evaluation, environment & platform, agent framework, multi-agent system, and agent fine-tuning. It provides a comprehensive collection of research papers on LLM-based agents, exploring different aspects of AI agent architectures and applications.

council
Council is an open-source platform designed for the rapid development and deployment of customized generative AI applications using teams of agents. It extends the LLM tool ecosystem by providing advanced control flow and scalable oversight for AI agents. Users can create sophisticated agents with predictable behavior by leveraging Council's powerful approach to control flow using Controllers, Filters, Evaluators, and Budgets. The framework allows for automated routing between agents, comparing, evaluating, and selecting the best results for a task. Council aims to facilitate packaging and deploying agents at scale on multiple platforms while enabling enterprise-grade monitoring and quality control.
ComfyBench
ComfyBench is a comprehensive benchmark tool designed to evaluate agents' ability to design collaborative AI systems in ComfyUI. It provides tasks for agents to learn from documents and create workflows, which are then converted into code for better understanding by LLMs. The tool measures performance based on pass rate and resolve rate, reflecting the correctness of workflow execution and task realization. ComfyAgent, a component of ComfyBench, autonomously designs new workflows by learning from existing ones, interpreting them as collaborative AI systems to complete given tasks.
MARBLE
MARBLE (Multi-Agent Coordination Backbone with LLM Engine) is a modular framework for developing, testing, and evaluating multi-agent systems leveraging Large Language Models. It provides a structured environment for agents to interact in simulated environments, utilizing cognitive abilities and communication mechanisms for collaborative or competitive tasks. The framework features modular design, multi-agent support, LLM integration, shared memory, flexible environments, metrics and evaluation, industrial coding standards, and Docker support.
Awesome-Agent-Papers
This repository is a comprehensive collection of research papers on Large Language Model (LLM) agents, organized across key categories including agent construction, collaboration mechanisms, evolution, tools, security, benchmarks, and applications. The taxonomy provides a structured framework for understanding the field of LLM agents, bridging fragmented research threads by highlighting connections between agent design principles and emergent behaviors.
LLM-Agent-Evaluation-Survey
LLM-Agent-Evaluation-Survey is a tool designed to gather feedback and evaluate the performance of AI agents. It provides a user-friendly interface for users to rate and provide comments on the interactions with AI agents. The tool aims to collect valuable insights to improve the AI agents' capabilities and enhance user experience. With LLM-Agent-Evaluation-Survey, users can easily assess the effectiveness and efficiency of AI agents in various scenarios, leading to better decision-making and optimization of AI systems.
get-started-with-ai-agents
The 'Getting Started with Agents Using Azure AI Foundry' repository provides a solution that deploys a web-based chat application with an AI agent running in Azure Container App. The agent leverages Azure AI services for knowledge retrieval from uploaded files, enabling it to generate responses with citations. The solution includes built-in monitoring capabilities for easier troubleshooting and optimized performance. Users can deploy AI models, customize the agent, and evaluate its performance. The repository offers flexible deployment options through GitHub Codespaces, VS Code Dev Containers, or local environments.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.