
KernelBench
KernelBench: Can LLMs Write GPU Kernels? - Benchmark with Torch -> CUDA problems
Stars: 86
KernelBench is a benchmark tool designed to evaluate Large Language Models' (LLMs) ability to generate GPU kernels. It focuses on transpiling operators from PyTorch to CUDA kernels at different levels of granularity. The tool categorizes problems into four levels, ranging from single-kernel operators to full model architectures, and assesses solutions based on compilation, correctness, and speed. The repository provides a structured directory layout, setup instructions, usage examples for running single or multiple problems, and upcoming roadmap features like additional GPU platform support and integration with other frameworks.
README:
A benchmark for evaluating LLMs' ability to generate GPU kernels

See blog post for more details.
We structure the problem for LLM to transpile operators described in PyTorch to CUDA kernels, at whatever level of granularity it desires to.

We construct Kernel Bench to have 4 Levels of categories:
- Level 1: Single-kernel operators (100 Problems) The foundational building blocks of neural nets (Convolutions, Matrix multiplies, Layer normalization)
- Level 2: Simple fusion patterns (100 Problems) A fused kernel would be faster than separated kernels (Conv + Bias + ReLU, Matmul + Scale + Sigmoid)
- Level 3: Full model architectures (50 Problems) Optimize entire model architectures end-to-end (MobileNet, VGG, MiniGPT, Mamba)
- Level 4: Level Hugging Face Optimize whole model architectures from HuggngFace
For this benchmark, we care whether if a solution
- compiles: generated torch code was able to load the inline embedded CUDA Kernel and build the kernel
- is correct: check against reference torch operators n_correctness times on randomized inputs
- is fast: compare against reference torch operators n_trial times for both eager mode and torch.compile execution
We organize the repo into the following structure:
KernelBench/
├── assets/
├── KernelBench/ # Benchmark dataset files
├── src/ # KernelBench logic code
│ ├── unit_tests/
│ ├── prompts/
│ ├── ....
├── scripts/ # helpful scripts to run the benchmark
├── results/ # some baseline times
├── runs/ # where your runs will be stored
conda create --name kernel-bench python=3.10
conda activate kernel-bench
pip install -r requirements.txt
pip install -e .
To call LLM API providers, set your {INFERENCE_SERVER_PROVIDER}_API_KEY API key.
Running and profiling kernels require a GPU. [Coming soon] If you don't have GPU available locally, you can set up Modal. Set up your modal token.
It is easier to get started with a single problem. This will fetch the problem, generate a sample, and evaluate the sample.
# for example, run level 2 problem 40 from huggingface
python3 scripts/generate_and_eval_single_sample.py dataset_src="huggingface" level=2 problem_id=40
# dataset_src could be "local" or "huggingface"
# add .verbose_logging for more visbility
# 1. Generate responses and store kernels locally to runs/{run_name} directory
python3 scripts/generate_samples.py run_name="test_hf_level_1" dataset_src="huggingface" level="1" num_workers=50 server_type="deepseek" model_name="deepseek-coder" temperature=0
# 2. Evaluate on all generated kernels in runs/{run_name} directory
python3 scripts/eval_from_generations.py level=1 run_name="test_hf_level_1" dataset_src="local" level="1" num_gpu_devices=8 timeout=300
You can check out scripts/greedy_analysis.py to analyze the eval results.
We provide some reference baseline times on NVIDIA L40S in results/timing (soon also on H100).
- [ ] More reference baseline times on various GPU platforms
- [ ] Easy-to-use Cloud GPU Integration (via Modal)
- [ ] Integrate with more frameworks, such as ThunderKittens
- [ ] Add backward pass
- [ ] Integrate with toolchains such as NCU
MIT. Check LICENSE.md for more details.
@misc{ouyang2024kernelbench,
title={KernelBench: Can LLMs Write GPU Kernels?},
author={Anne Ouyang and Simon Guo and Azalia Mirhoseini},
year={2024},
url={https://scalingintelligence.stanford.edu/blogs/kernelbench/},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for KernelBench
Similar Open Source Tools
KernelBench
KernelBench is a benchmark tool designed to evaluate Large Language Models' (LLMs) ability to generate GPU kernels. It focuses on transpiling operators from PyTorch to CUDA kernels at different levels of granularity. The tool categorizes problems into four levels, ranging from single-kernel operators to full model architectures, and assesses solutions based on compilation, correctness, and speed. The repository provides a structured directory layout, setup instructions, usage examples for running single or multiple problems, and upcoming roadmap features like additional GPU platform support and integration with other frameworks.
torchtitan
Torchtitan is a PyTorch native platform designed for rapid experimentation and large-scale training of generative AI models. It provides a flexible foundation for developers to build upon with extension points for creating custom extensions. The tool showcases PyTorch's latest distributed training features and supports pretraining Llama 3.1 LLMs of various sizes. It offers key features like multi-dimensional parallelisms, FSDP2 with per-parameter sharding, Tensor Parallel, Pipeline Parallel, and more. Users can contribute to the tool through the experiments folder and core contributions guidelines. Installation can be done from source, nightly builds, or stable releases. The tool also supports training Llama 3.1 models and provides guidance on starting a training run and multi-node training. Citation information is available for referencing the tool in academic work, and the source code is under a BSD 3 license.
uTensor
uTensor is an extremely light-weight machine learning inference framework built on Tensorflow and optimized for Arm targets. It consists of a runtime library and an offline tool that handles most of the model translation work. The core runtime is only ~2KB. The workflow involves constructing and training a model in Tensorflow, then using uTensor to produce C++ code for inferencing. The runtime ensures system safety, guarantees RAM usage, and focuses on clear, concise, and debuggable code. The high-level API simplifies tensor handling and operator execution for embedded systems.
cuvs
cuVS is a library that contains state-of-the-art implementations of several algorithms for running approximate nearest neighbors and clustering on the GPU. It can be used directly or through the various databases and other libraries that have integrated it. The primary goal of cuVS is to simplify the use of GPUs for vector similarity search and clustering.
yalm
Yalm (Yet Another Language Model) is an LLM inference implementation in C++/CUDA, emphasizing performance engineering, documentation, scientific optimizations, and readability. It is not for production use and has been tested on Mistral-v0.2 and Llama-3.2. Requires C++20-compatible compiler, CUDA toolkit, and LLM safetensor weights in huggingface format converted to .yalm file.

uzu
uzu is a high-performance inference engine for AI models on Apple Silicon. It features a simple, high-level API, hybrid architecture for GPU kernel computation, unified model configurations, traceable computations, and utilizes unified memory on Apple devices. The tool provides a CLI mode for running models, supports its own model format, and offers prebuilt Swift and TypeScript frameworks for bindings. Users can quickly start by adding the uzu dependency to their Cargo.toml and creating an inference Session with a specific model and configuration. Performance benchmarks show metrics for various models on Apple M2, highlighting the tokens/s speed for each model compared to llama.cpp with bf16/f16 precision.
TriForce
TriForce is a training-free tool designed to accelerate long sequence generation. It supports long-context Llama models and offers both on-chip and offloading capabilities. Users can achieve a 2.2x speedup on a single A100 GPU. TriForce also provides options for offloading with tensor parallelism or without it, catering to different hardware configurations. The tool includes a baseline for comparison and is optimized for performance on RTX 4090 GPUs. Users can cite the associated paper if they find TriForce useful for their projects.
llm-applications
A comprehensive guide to building Retrieval Augmented Generation (RAG)-based LLM applications for production. This guide covers developing a RAG-based LLM application from scratch, scaling the major components, evaluating different configurations, implementing LLM hybrid routing, serving the application in a highly scalable and available manner, and sharing the impacts LLM applications have had on products.

lmql
LMQL is a programming language designed for large language models (LLMs) that offers a unique way of integrating traditional programming with LLM interaction. It allows users to write programs that combine algorithmic logic with LLM calls, enabling model reasoning capabilities within the context of the program. LMQL provides features such as Python syntax integration, rich control-flow options, advanced decoding techniques, powerful constraints via logit masking, runtime optimization, sync and async API support, multi-model compatibility, and extensive applications like JSON decoding and interactive chat interfaces. The tool also offers library integration, flexible tooling, and output streaming options for easy model output handling.

ControlLLM
ControlLLM is a framework that empowers large language models to leverage multi-modal tools for solving complex real-world tasks. It addresses challenges like ambiguous user prompts, inaccurate tool selection, and inefficient tool scheduling by utilizing a task decomposer, a Thoughts-on-Graph paradigm, and an execution engine with a rich toolbox. The framework excels in tasks involving image, audio, and video processing, showcasing superior accuracy, efficiency, and versatility compared to existing methods.

llm-analysis
llm-analysis is a tool designed for Latency and Memory Analysis of Transformer Models for Training and Inference. It automates the calculation of training or inference latency and memory usage for Large Language Models (LLMs) or Transformers based on specified model, GPU, data type, and parallelism configurations. The tool helps users to experiment with different setups theoretically, understand system performance, and optimize training/inference scenarios. It supports various parallelism schemes, communication methods, activation recomputation options, data types, and fine-tuning strategies. Users can integrate llm-analysis in their code using the `LLMAnalysis` class or use the provided entry point functions for command line interface. The tool provides lower-bound estimations of memory usage and latency, and aims to assist in achieving feasible and optimal setups for training or inference.
raft
RAFT (Reusable Accelerated Functions and Tools) is a C++ header-only template library with an optional shared library that contains fundamental widely-used algorithms and primitives for machine learning and information retrieval. The algorithms are CUDA-accelerated and form building blocks for more easily writing high performance applications.
falkon
Falkon is a Python implementation of the Falkon algorithm for large-scale, approximate kernel ridge regression. The code is optimized for scalability to large datasets with tens of millions of points and beyond. Full kernel matrices are never computed explicitly so that you will not run out of memory on larger problems. Preconditioned conjugate gradient optimization ensures that only few iterations are necessary to obtain good results. The basic algorithm is a Nyström approximation to kernel ridge regression, which needs only three hyperparameters: 1. The number of centers M - this controls the quality of the approximation: a higher number of centers will produce more accurate results at the expense of more computation time, and higher memory requirements. 2. The penalty term, which controls the amount of regularization. 3. The kernel function. A good default is always the Gaussian (RBF) kernel (`falkon.kernels.GaussianKernel`).
simply
Simply is a minimal and scalable research codebase in JAX, designed for rapid iteration on frontier research in LLM and other autoregressive models. It is quick to fork and hack for fast iteration, with minimal abstractions and dependencies for a simple and self-contained codebase. Users can easily implement new architectures, optimizers, training losses, etc., in a few hours. Simply allows users to get started with hacking quickly, providing example commands for local testing and running on Google Cloud TPUs. The main dependencies include Jax for model and training, Orbax for checkpoint management, and Grain for data pipeline. Users can install dependencies, set up model checkpoints and datasets, and cite the tool if found helpful.

oasis
OASIS is a scalable, open-source social media simulator that integrates large language models with rule-based agents to realistically mimic the behavior of up to one million users on platforms like Twitter and Reddit. It facilitates the study of complex social phenomena such as information spread, group polarization, and herd behavior, offering a versatile tool for exploring diverse social dynamics and user interactions in digital environments. With features like scalability, dynamic environments, diverse action spaces, and integrated recommendation systems, OASIS provides a comprehensive platform for simulating social media interactions at a large scale.
llm-d-inference-sim
The `llm-d-inference-sim` is a lightweight, configurable, and real-time simulator designed to mimic the behavior of vLLM without the need for GPUs or running heavy models. It operates as an OpenAI-compliant server, allowing developers to test clients, schedulers, and infrastructure using realistic request-response cycles, token streaming, and latency patterns. The simulator offers modes of operation, response generation from predefined text or real datasets, latency simulation, tokenization options, LoRA management, KV cache simulation, failure injection, and deployment options for standalone or Kubernetes testing. It supports a subset of standard vLLM Prometheus metrics for observability.
For similar tasks

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.

edsl
The Expected Parrot Domain-Specific Language (EDSL) package enables users to conduct computational social science and market research with AI. It facilitates designing surveys and experiments, simulating responses using large language models, and performing data labeling and other research tasks. EDSL includes built-in methods for analyzing, visualizing, and sharing research results. It is compatible with Python 3.9 - 3.11 and requires API keys for LLMs stored in a `.env` file.

fast-stable-diffusion
Fast-stable-diffusion is a project that offers notebooks for RunPod, Paperspace, and Colab Pro adaptations with AUTOMATIC1111 Webui and Dreambooth. It provides tools for running and implementing Dreambooth, a stable diffusion project. The project includes implementations by XavierXiao and is sponsored by Runpod, Paperspace, and Colab Pro.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

LLM-LieDetector
This repository contains code for reproducing experiments on lie detection in black-box LLMs by asking unrelated questions. It includes Q/A datasets, prompts, and fine-tuning datasets for generating lies with language models. The lie detectors rely on asking binary 'elicitation questions' to diagnose whether the model has lied. The code covers generating lies from language models, training and testing lie detectors, and generalization experiments. It requires access to GPUs and OpenAI API calls for running experiments with open-source models. Results are stored in the repository for reproducibility.

bigcodebench
BigCodeBench is an easy-to-use benchmark for code generation with practical and challenging programming tasks. It aims to evaluate the true programming capabilities of large language models (LLMs) in a more realistic setting. The benchmark is designed for HumanEval-like function-level code generation tasks, but with much more complex instructions and diverse function calls. BigCodeBench focuses on the evaluation of LLM4Code with diverse function calls and complex instructions, providing precise evaluation & ranking and pre-generated samples to accelerate code intelligence research. It inherits the design of the EvalPlus framework but differs in terms of execution environment and test evaluation.
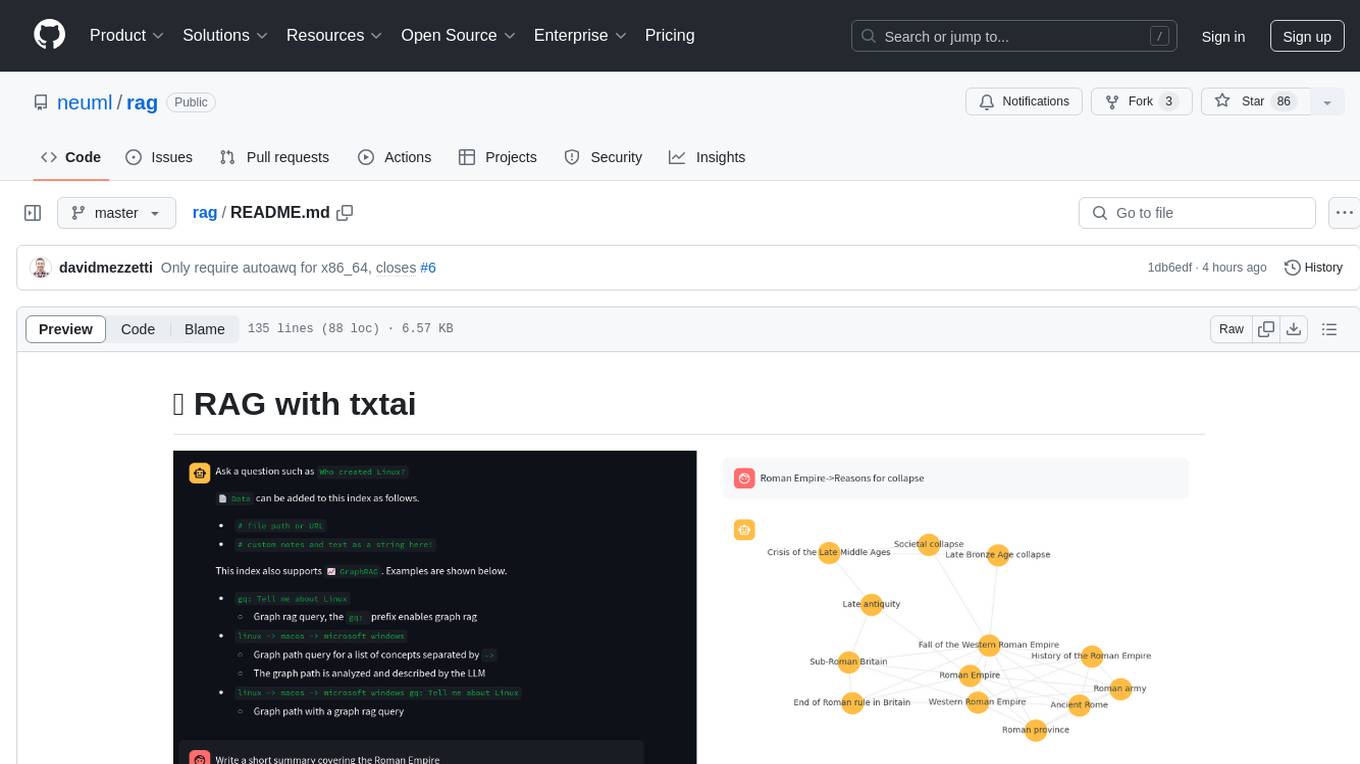
rag
RAG with txtai is a Retrieval Augmented Generation (RAG) Streamlit application that helps generate factually correct content by limiting the context in which a Large Language Model (LLM) can generate answers. It supports two categories of RAG: Vector RAG, where context is supplied via a vector search query, and Graph RAG, where context is supplied via a graph path traversal query. The application allows users to run queries, add data to the index, and configure various parameters to control its behavior.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.