
RobustVLM
[ICML 2024] Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models
Stars: 58

This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.
README:
[Paper] [HuggingFace] [BibTeX]
This repository contains code for the paper "Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models" (Oral@ICML 2024).


We fine-tune CLIP in an unsupervised manner to improve its robustness to visual adversarial attacks. We show that replacing the vision encoder of large vision-language models with our fine-tuned CLIP models yields state-of-the-art adversarial robustness on a variety of vision-language tasks, without requiring any training of the large VLMs themselves. Moreover, we improve the robustness of CLIP to adversarial attacks in zero-shot classification settings, while maintaining higher clean accuracy than previous adversarial fine-tuning methods.
The code is tested with Python 3.11. To install the required packages, run:
pip install -r requirements.txtWe provide the following adversarially fine-tuned ViT-L/14 CLIP models (approx. 1.1 GB each):
| Model | Link | Proposed by | Notes |
|---|---|---|---|
| TeCoA2 | Link | Mao et al. (2023) | Supervised adversarial fine-tuning with $\ell_\infty$ norm, $\varepsilon=\frac{2}{255}$ |
| TeCoA4 | Link | Mao et al. (2023) | Supervised adversarial fine-tuning with $\ell_\infty$ norm, $\varepsilon=\frac{4}{255}$ |
| FARE2 | Link | ours | Unsupervised adversarial fine-tuning with $\ell_\infty$ norm, $\varepsilon=\frac{2}{255}$ |
| FARE4 | Link | ours | Unsupervised adversarial fine-tuning with $\ell_\infty$ norm, $\varepsilon=\frac{4}{255}$ |
The models are also available on HuggingFace.
All models are adversarially fine-tuned for two epochs on ImageNet. TeCoA is trained in a supervised fashion, utilizing ImageNet class labels. FARE, in contrast, does not require any labels for training.
The provided checkpoints correspond to the vision encoder of CLIP. To load the full CLIP model (including the text encoder), you can use the following code:
import torch
from open_clip import create_model_and_transforms
model, _, image_processor = create_model_and_transforms(
'ViT-L-14', pretrained='openai', device='cpu'
)
checkpoint = torch.load('/path/to/fare_eps_2.pt', map_location=torch.device('cpu'))
model.visual.load_state_dict(checkpoint)Alternatively load directly from HuggingFace:
from open_clip import create_model_and_transforms
model, _, image_processor = open_clip.create_model_and_transforms('hf-hub:chs20/fare2-clip')We show a summary of results on zero-shot classification and vision-language tasks for original and fine-tuned ViT-L/14 CLIP models. CLIP-only means that we evaluate the respective CLIP model in a standalone fashion for zero-shot classification, whereas OpenFlamingo and LLaVA evaluation means that we use the respective CLIP model as a vision encoder as part of these large vision-language models. Results for individual zero-shot datasets and more VLM tasks are provided in the paper.
- Clean evaluation:
| CLIP-only | OpenFlamingo 9B | LLaVA 1.5 7B | |||
| Model | Avg. zero-shot | COCO | TextVQA | COCO | TextVQA |
| OpenAI | 73.1 | 79.7 | 23.8 | 115.5 | 37.1 |
| TeCoA2 | 60.0 | 73.5 | 16.6 | 98.4 | 24.1 |
| FARE2 | 67.0 | 79.1 | 21.6 | 109.9 | 31.9 |
| TeCoA4 | 54.2 | 66.9 | 15.4 | 88.3 | 20.7 |
| FARE4 | 61.1 | 74.1 | 18.6 | 102.4 | 27.6 |
- Adversarial evaluation ($\ell_\infty, ~ \varepsilon=\frac{2}{255}$):
| CLIP-only | OpenFlamingo 9B | LLaVA 1.5 7B | |||
| Model | Avg. zero-shot | COCO | TextVQA | COCO | TextVQA |
| Openai | 0.0 | 1.5 | 0.0 | 4.0 | 0.5 |
| TeCoA2 | 43.6 | 31.6 | 3.5 | 44.2 | 12.1 |
| FARE2 | 43.1 | 34.2 | 4.1 | 53.6 | 14.7 |
| TeCoA4 | 42.3 | 28.5 | 2.1 | 50.9 | 12.6 |
| FARE4 | 45.9 | 30.9 | 3.4 | 57.1 | 15.8 |
- Adversarial evaluation ($\ell_\infty, ~ \varepsilon=\frac{4}{255}$):
| CLIP-only | OpenFlamingo 9B | LLaVA 1.5 7B | |||
| Model | Avg. zero-shot | COCO | TextVQA | COCO | TextVQA |
| Openai | 0.0 | 1.1 | 0.0 | 3.1 | 0.0 |
| TeCoA2 | 27.0 | 21.2 | 2.1 | 30.3 | 8.8 |
| FARE2 | 20.5 | 19.5 | 1.9 | 31.0 | 9.1 |
| TeCoA4 | 31.9 | 21.6 | 1.8 | 35.3 | 9.3 |
| FARE4 | 32.4 | 22.8 | 2.9 | 40.9 | 10.9 |
- TeCoA4
python -m train.adversarial_training_clip --clip_model_name ViT-L-14 --pretrained openai --dataset imagenet --imagenet_root /path/to/imagenet --template std --output_normalize True --steps 20000 --warmup 1400 --batch_size 128 --loss ce --opt adamw --lr 1e-5 --wd 1e-4 --attack pgd --inner_loss ce --norm linf --eps 4 --iterations_adv 10 --stepsize_adv 1 --wandb False --output_dir /path/to/out/dir --experiment_name TECOA4 --log_freq 10 --eval_freq 10```- FARE4
python -m train.adversarial_training_clip --clip_model_name ViT-L-14 --pretrained openai --dataset imagenet --imagenet_root /path/to/imagenet --template std --output_normalize False --steps 20000 --warmup 1400 --batch_size 128 --loss l2 --opt adamw --lr 1e-5 --wd 1e-4 --attack pgd --inner_loss l2 --norm linf --eps 4 --iterations_adv 10 --stepsize_adv 1 --wandb False --output_dir /path/to/out/dir --experiment_name FARE4 --log_freq 10 --eval_freq 10Set --eps 2 to obtain TeCoA2 and FARE2 models.
Make sure files in bash directory are executable: chmod +x bash/*
python -m CLIP_eval.clip_robustbench --clip_model_name ViT-L-14 --pretrained /path/to/ckpt.pt --dataset imagenet --imagenet_root /path/to/imagenet --wandb False --norm linf --eps 2Set models to be evaluated in CLIP_benchmark/benchmark/models.txt and datasets in CLIP_benchmark/benchmark/datasets.txt
(the datasets are downloaded from HuggingFace). Then run
cd CLIP_benchmark
./bash/run_benchmark_adv.shIn /bash/llava_eval.sh supply paths for the datasets. The required annotation files for the datasets can be obtained from this HuggingFace repository.
Set --vision_encoder_pretrained to openai or supply path to fine-tuned CLIP model checkpoint.
Then run
./bash/llava_eval.shThe LLaVA model will be automatically downloaded from HuggingFace.
Download the OpenFlamingo 9B model, supply paths in /bash/of_eval_9B.sh and run
./bash/of_eval_9B.shSome non-standard annotation files are supplied here and here.
For targeted attacks on COCO, run
./bash/llava_eval_targeted.shFor targeted attacks on self-selected images, set images and target captions in vlm_eval/run_evaluation_qualitative.py and run
python -m vlm_eval.run_evaluation_qualitative --precision float32 --attack apgd --eps 2 --steps 10000 --vlm_model_name llava --vision_encoder_pretrained openai --verboseWith 10,000 iterations it takes about 2 hours per image on an A100 GPU.
./bash/eval_pope.sh openai # for clean model evaluation
./bash/eval_pope.sh # for robust model evaluation - add path_to_ckpt in bash file./bash/eval_scienceqa.sh openai # for clean model evaluation
./bash/eval_scienceqa.sh # for robust model evaluation - add path_to_ckpt in bash fileThis repository gratefully forks from
If you find this repository useful, please consider citing our paper:
@article{schlarmann2024robustclip,
title={Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models},
author={Christian Schlarmann and Naman Deep Singh and Francesco Croce and Matthias Hein},
year={2024},
journal={ICML}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for RobustVLM
Similar Open Source Tools
RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.
OpenAI-CLIP-Feature
This repository provides code for extracting image and text features using OpenAI CLIP models, supporting both global and local grid visual features. It aims to facilitate multi visual-and-language downstream tasks by allowing users to customize input and output grid resolution easily. The extracted features have shown comparable or superior results in image captioning tasks without hyperparameter tuning. The repo supports various CLIP models and provides detailed information on supported settings and results on MSCOCO image captioning. Users can get started by setting up experiments with the extracted features using X-modaler.

LLaVA-MORE
LLaVA-MORE is a new family of Multimodal Language Models (MLLMs) that integrates recent language models with diverse visual backbones. The repository provides a unified training protocol for fair comparisons across all architectures and releases training code and scripts for distributed training. It aims to enhance Multimodal LLM performance and offers various models for different tasks. Users can explore different visual backbones like SigLIP and methods for managing image resolutions (S2) to improve the connection between images and language. The repository is a starting point for expanding the study of Multimodal LLMs and enhancing new features in the field.

MathEval
MathEval is a benchmark designed for evaluating the mathematical capabilities of large models. It includes over 20 evaluation datasets covering various mathematical domains with more than 30,000 math problems. The goal is to assess the performance of large models across different difficulty levels and mathematical subfields. MathEval serves as a reliable reference for comparing mathematical abilities among large models and offers guidance on enhancing their mathematical capabilities in the future.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.

IDvs.MoRec
This repository contains the source code for the SIGIR 2023 paper 'Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited'. It provides resources for evaluating foundation, transferable, multi-modal, and LLM recommendation models, along with datasets, pre-trained models, and training strategies for IDRec and MoRec using in-batch debiased cross-entropy loss. The repository also offers large-scale datasets, code for SASRec with in-batch debias cross-entropy loss, and information on joining the lab for research opportunities.

qserve
QServe is a serving system designed for efficient and accurate Large Language Models (LLM) on GPUs with W4A8KV4 quantization. It achieves higher throughput compared to leading industry solutions, allowing users to achieve A100-level throughput on cheaper L40S GPUs. The system introduces the QoQ quantization algorithm with 4-bit weight, 8-bit activation, and 4-bit KV cache, addressing runtime overhead challenges. QServe improves serving throughput for various LLM models by implementing compute-aware weight reordering, register-level parallelism, and fused attention memory-bound techniques.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.
ReST-MCTS
ReST-MCTS is a reinforced self-training approach that integrates process reward guidance with tree search MCTS to collect higher-quality reasoning traces and per-step value for training policy and reward models. It eliminates the need for manual per-step annotation by estimating the probability of steps leading to correct answers. The inferred rewards refine the process reward model and aid in selecting high-quality traces for policy model self-training.
LLMs-Planning
This repository contains code for three papers related to evaluating large language models on planning and reasoning about change. It includes benchmarking tools and analysis for assessing the planning abilities of large language models. The latest addition evaluates and enhances the planning and scheduling capabilities of a specific language reasoning model. The repository provides a static test set leaderboard showcasing model performance on various tasks with natural language and planning domain prompts.
ai-hands-on
A complete, hands-on guide to becoming an AI Engineer. This repository is designed to help you learn AI from first principles, build real neural networks, and understand modern LLM systems end-to-end. Progress through math, PyTorch, deep learning, transformers, RAG, and OCR with clean, intuitive Jupyter notebooks guiding you at every step. Suitable for beginners and engineers leveling up, providing clarity, structure, and intuition to build real AI systems.

DeepRetrieval
DeepRetrieval is a tool designed to enhance search engines and retrievers using Large Language Models (LLMs) and Reinforcement Learning (RL). It allows LLMs to learn how to search effectively by integrating with search engine APIs and customizing reward functions. The tool provides functionalities for data preparation, training, evaluation, and monitoring search performance. DeepRetrieval aims to improve information retrieval tasks by leveraging advanced AI techniques.
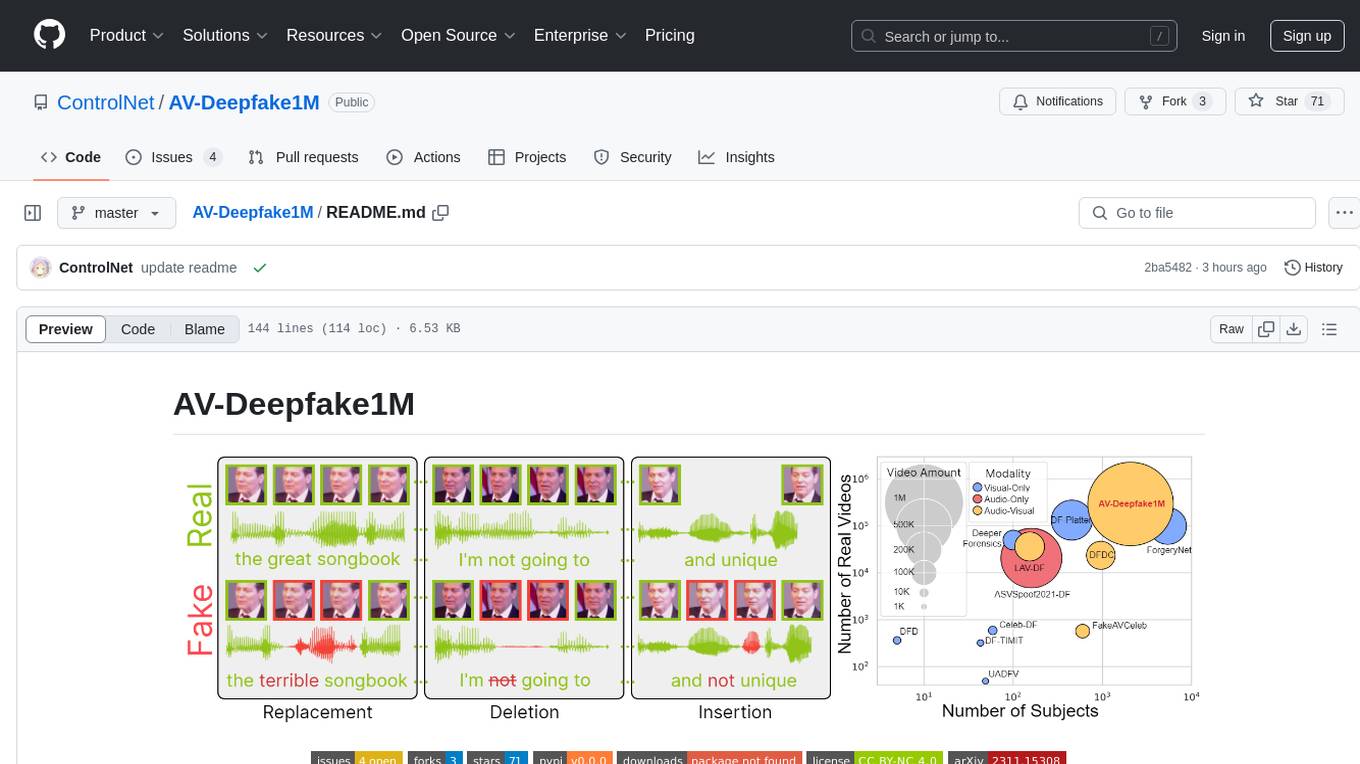
AV-Deepfake1M
The AV-Deepfake1M repository is the official repository for the paper AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset. It addresses the challenge of detecting and localizing deepfake audio-visual content by proposing a dataset containing video manipulations, audio manipulations, and audio-visual manipulations for over 2K subjects resulting in more than 1M videos. The dataset is crucial for developing next-generation deepfake localization methods.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.

UniCoT
Uni-CoT is a unified reasoning framework that extends Chain-of-Thought (CoT) principles to the multimodal domain, enabling Multimodal Large Language Models (MLLMs) to perform interpretable, step-by-step reasoning across both text and vision. It decomposes complex multimodal tasks into structured, manageable steps that can be executed sequentially or in parallel, allowing for more scalable and systematic reasoning.
rubra
Rubra is a collection of open-weight large language models enhanced with tool-calling capability. It allows users to call user-defined external tools in a deterministic manner while reasoning and chatting, making it ideal for agentic use cases. The models are further post-trained to teach instruct-tuned models new skills and mitigate catastrophic forgetting. Rubra extends popular inferencing projects for easy use, enabling users to run the models easily.
For similar tasks

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.

edsl
The Expected Parrot Domain-Specific Language (EDSL) package enables users to conduct computational social science and market research with AI. It facilitates designing surveys and experiments, simulating responses using large language models, and performing data labeling and other research tasks. EDSL includes built-in methods for analyzing, visualizing, and sharing research results. It is compatible with Python 3.9 - 3.11 and requires API keys for LLMs stored in a `.env` file.

fast-stable-diffusion
Fast-stable-diffusion is a project that offers notebooks for RunPod, Paperspace, and Colab Pro adaptations with AUTOMATIC1111 Webui and Dreambooth. It provides tools for running and implementing Dreambooth, a stable diffusion project. The project includes implementations by XavierXiao and is sponsored by Runpod, Paperspace, and Colab Pro.
RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

LLM-LieDetector
This repository contains code for reproducing experiments on lie detection in black-box LLMs by asking unrelated questions. It includes Q/A datasets, prompts, and fine-tuning datasets for generating lies with language models. The lie detectors rely on asking binary 'elicitation questions' to diagnose whether the model has lied. The code covers generating lies from language models, training and testing lie detectors, and generalization experiments. It requires access to GPUs and OpenAI API calls for running experiments with open-source models. Results are stored in the repository for reproducibility.

bigcodebench
BigCodeBench is an easy-to-use benchmark for code generation with practical and challenging programming tasks. It aims to evaluate the true programming capabilities of large language models (LLMs) in a more realistic setting. The benchmark is designed for HumanEval-like function-level code generation tasks, but with much more complex instructions and diverse function calls. BigCodeBench focuses on the evaluation of LLM4Code with diverse function calls and complex instructions, providing precise evaluation & ranking and pre-generated samples to accelerate code intelligence research. It inherits the design of the EvalPlus framework but differs in terms of execution environment and test evaluation.
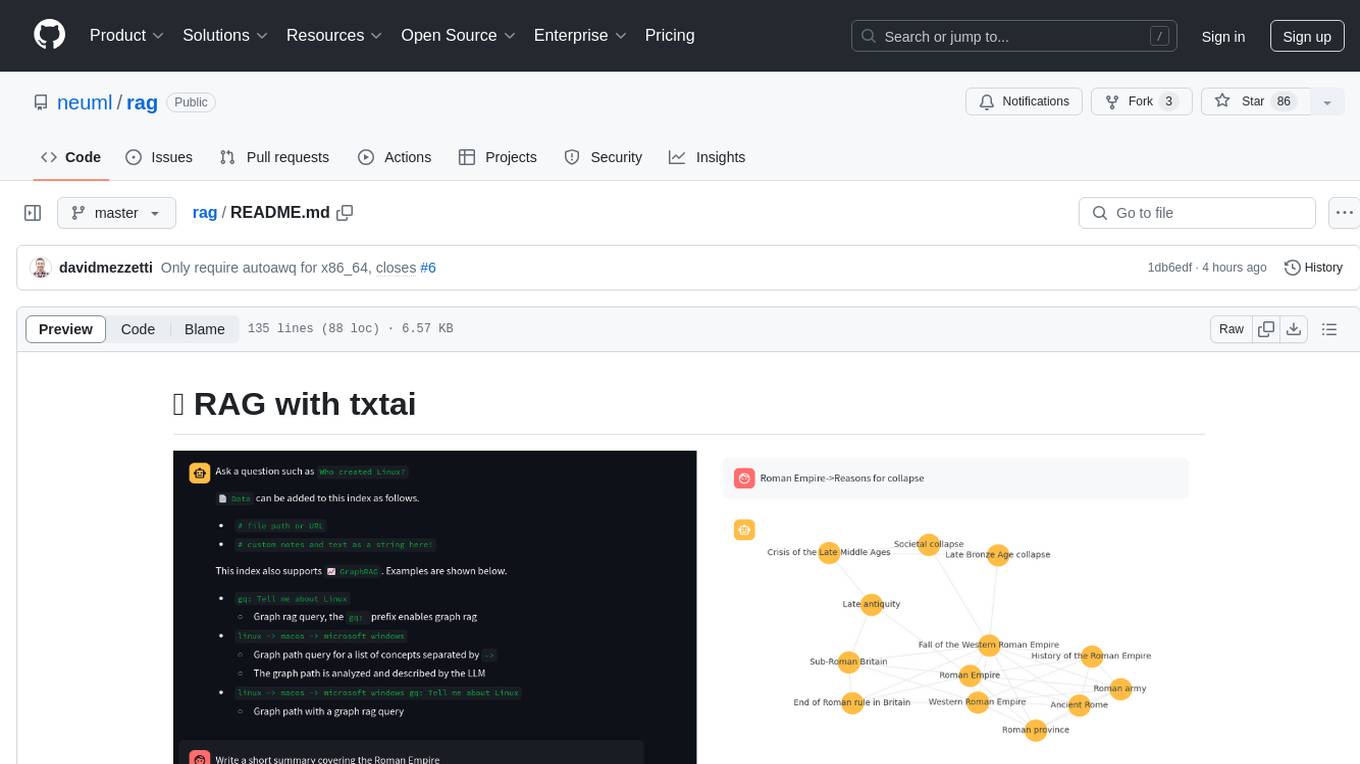
rag
RAG with txtai is a Retrieval Augmented Generation (RAG) Streamlit application that helps generate factually correct content by limiting the context in which a Large Language Model (LLM) can generate answers. It supports two categories of RAG: Vector RAG, where context is supplied via a vector search query, and Graph RAG, where context is supplied via a graph path traversal query. The application allows users to run queries, add data to the index, and configure various parameters to control its behavior.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.