
OpenAI-CLIP-Feature
An easy to use, user-friendly and efficient code for extracting OpenAI CLIP (Global/Grid) features from image and text respectively.
Stars: 115
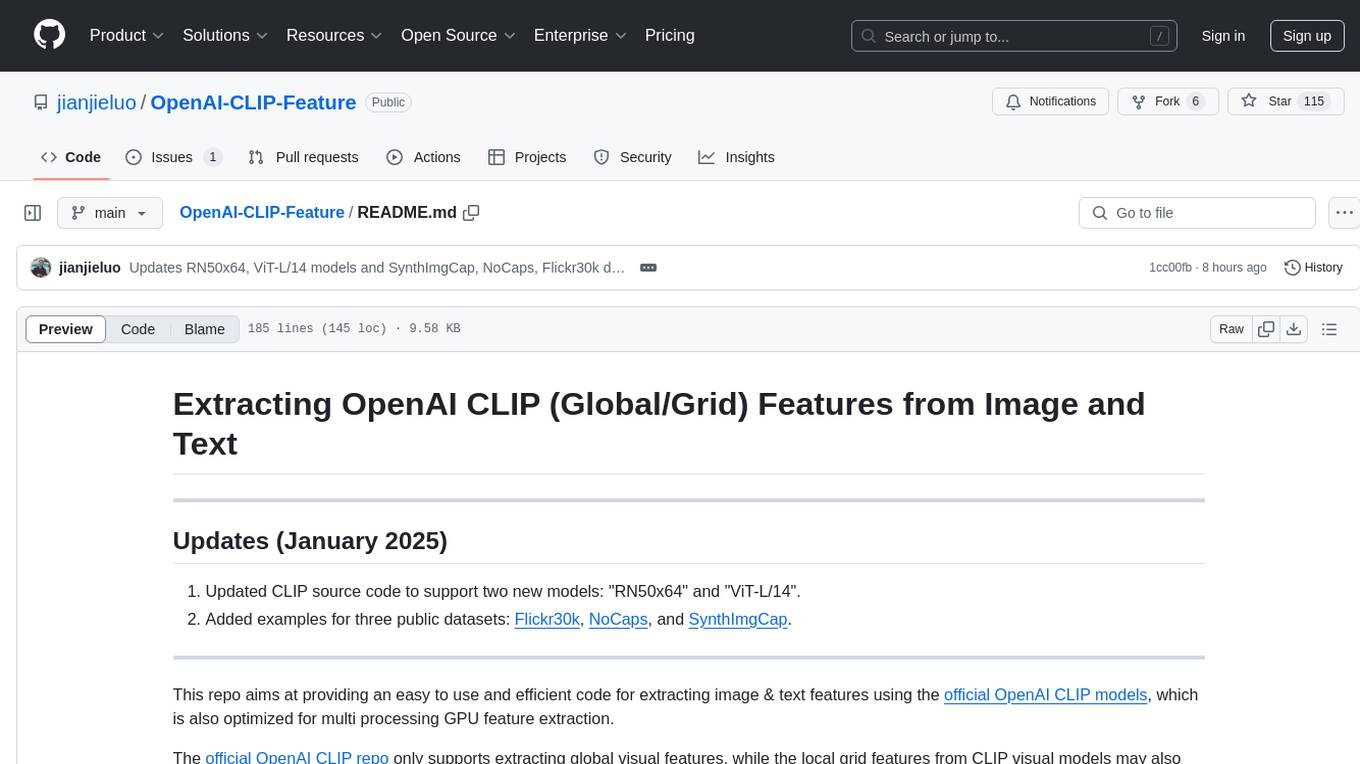
This repository provides code for extracting image and text features using OpenAI CLIP models, supporting both global and local grid visual features. It aims to facilitate multi visual-and-language downstream tasks by allowing users to customize input and output grid resolution easily. The extracted features have shown comparable or superior results in image captioning tasks without hyperparameter tuning. The repo supports various CLIP models and provides detailed information on supported settings and results on MSCOCO image captioning. Users can get started by setting up experiments with the extracted features using X-modaler.
README:
- Updated CLIP source code to support two new models: "RN50x64" and "ViT-L/14".
- Added examples for three public datasets: Flickr30k, NoCaps, and SynthImgCap.
This repo aims at providing an easy to use and efficient code for extracting image & text features using the official OpenAI CLIP models, which is also optimized for multi processing GPU feature extraction.
The official OpenAI CLIP repo only supports extracting global visual features, while the local grid features from CLIP visual models may also contain more detailed semantic information which can benefit multi visual-and-language downstream tasks[1][2]. As an alternative, this repo encapsulates minor-modified CLIP code in order to extract not only global visual features but also local grid visual features from different CLIP visual models. What's more, this repo is designed in a user-friendly object-oriented fashion, allowing users to add their customized visual_extractor classes easily to customize different input and output grid resolution.
To verify the semantic meaning of the extracted visual grid features, we also applied the extracted visual grid features of MSCOCO images from different official CLIP models for standard image captioning task. We got comparable or superior results in transformer baseline easily without hard-tuning hyperparameters, via simply replacing BUTD features with the extracted CLIP gird features. Surprisingly, we got 116.9 CIDEr score in teacher-forcing setting and 129.6 in reinforcement learning setting when using ViT-B/32 CLIP model, which conflicts with the experiment results in CLIP-ViL paper[1] where the authors observed that CLIP-ViT-B with grid features has a large performance degradation compared with other models (58.0 CIDEr score in CLIP-ViT-B_Transformer setting in COCO Captioning).
We provide supported CLIP models, results on MSCOCO image captioning, and other information below. We believe this repo can facilitate the usage of powerful CLIP models.
Currently this repo supports five visual extractor settings, including three standard pipelines used in official OpenAI CLIP repo and two additional customized pipelines supporting larger input resolution. You can refer to this file for more details about customizing your own visual backbones for different input and output resolution. In order to imporve training efficiency in image captioning task, we apply AvgPool2d to the output feature map to reduce grid features size in some settings without large performance degradation. We will support more CLIP models in the future.
| Visual Backbone | CLIP Model | Input Resolution | Output Resolution | Feature Map Downsample | Grid Feature Shape | Global Feature Shape | |
|---|---|---|---|---|---|---|---|
| Standard | RN101 | RN101 | 224 x 224 | 7 x 7 | None | 49 x 2048 | 1 x 512 |
| ViT-B/32 | ViT-B/32 | 224 x 224 | 7 x 7 | None | 49 x 768 | 1 x 512 | |
| ViT-B/16 | ViT-B/16 | 224 x 224 | 14 x 14 | AvgPool2d(kernel_size=(2,2), stride=2) | 49 x 768 | 1 x 512 | |
| Customized | RN101_448 | RN101 | 448 x 448 | 14 x 14 | AvgPool2d(kernel_size=(2,2), stride=2) | 49 x 2048 | 1 x 512 |
| ViT-B/32_448 | ViT-B/32 | 448 x 448 | 14 x 14 | AvgPool2d(kernel_size=(2,2), stride=2) | 49 x 768 | 1 x 512 |
We ran image captioning experiments on X-modaler with the extracted CLIP grid features. We easily got comparable or superior results in transformer baseline using the default hyperparameters in X-modaler's transformer baseline, except for SOLVER.BASE_LR=2e-4 in ViT-B/16 and ViT-B/32_448 teacher-forcing settings. The performance of transformer baseline using BUTD features is taken from X-modaler's paper.
| Name | BLEU@1 | BLEU@2 | BLEU@3 | BLEU@4 | METEOR | ROUGE-L | CIDEr-D | SPICE |
|---|---|---|---|---|---|---|---|---|
| BUTD_feat | 76.4 | 60.3 | 46.5 | 35.8 | 28.2 | 56.7 | 116.6 | 21.3 |
| RN101 | 77.3 | 61.3 | 47.7 | 36.9 | 28.7 | 57.5 | 120.6 | 21.8 |
| ViT-B/32 | 76.4 | 60.3 | 46.5 | 35.6 | 28.1 | 56.7 | 116.9 | 21.2 |
| ViT-B/16 | 78.0 | 62.1 | 48.2 | 37.2 | 28.8 | 57.6 | 122.3 | 22.1 |
| RN101_448 | 78.0 | 62.4 | 48.9 | 38.0 | 29.0 | 57.9 | 123.6 | 22.1 |
| ViT-B/32_448 | 75.8 | 59.6 | 45.9 | 35.1 | 27.8 | 56.3 | 114.2 | 21.0 |
| Name | BLEU@1 | BLEU@2 | BLEU@3 | BLEU@4 | METEOR | ROUGE-L | CIDEr-D | SPICE |
|---|---|---|---|---|---|---|---|---|
| BUTD_feat | 80.5 | 65.4 | 51.1 | 39.2 | 29.1 | 58.7 | 130.0 | 23.0 |
| RN101 | 81.3 | 66.4 | 52.1 | 40.3 | 29.6 | 59.6 | 134.2 | 23.4 |
| ViT-B/32 | 79.9 | 64.6 | 50.4 | 38.5 | 29.0 | 58.6 | 129.6 | 22.8 |
| ViT-B/16 | 82.0 | 67.3 | 53.1 | 41.1 | 29.9 | 59.8 | 136.6 | 23.8 |
| RN101_448 | 81.6 | 66.9 | 52.6 | 40.6 | 29.9 | 59.8 | 136.2 | 23.9 |
| ViT-B/32_448 | 79.9 | 64.6 | 50.4 | 38.7 | 28.8 | 58.4 | 127.8 | 22.6 |
Note: The extracted feature files are compatible with X-modaler, where you can setup your experiments about cross-modal analytics conveniently.
- PyTorch ≥ 1.9 and torchvision that matches the PyTorch installation. Install them together at pytorch.org to make sure of this
- timm ≥ 0.4.5
- Use CLIP
ViT-B/32model to extract global textual features of MSCOCO sentences fromdataset_coco.jsonin Karpathy's released annotations.
CUDA_VISIBLE_DEVICES=0 python3 clip_textual_feats.py \
--anno dataset_coco.json \
--output_dir ${TXT_OUTPUT_DIR} \
--model_type_or_path 'ViT-B/32'- Use CLIP
ViT-B/16model to extract global and grid visual features of MSCOCO images.
CUDA_VISIBLE_DEVICES=0 python3 clip_visual_feats.py \
--image_list 'example/MSCOCO/image_list_2017.txt' \
--image_dir ${IMG_DIR} \
--output_dir ${IMG_OUTPUT_DIR} \
--ve_name 'ViT-B/16' \
--model_type_or_path 'ViT-B/16'- Use CLIP
RN101model to extract global and grid visual features of MSCOCO images.
CUDA_VISIBLE_DEVICES=0 python3 clip_visual_feats.py \
--image_list 'example/MSCOCO/image_list_2017.txt' \
--image_dir ${IMG_DIR} \
--output_dir ${IMG_OUTPUT_DIR} \
--ve_name 'RN101' \
--model_type_or_path 'RN101'- Use CLIP
RN101model to extract global and grid visual features of MSCOCO images with 448 x 448 resolution.
CUDA_VISIBLE_DEVICES=0 python3 clip_visual_feats.py \
--image_list 'example/MSCOCO/image_list_2017.txt' \
--image_dir ${IMG_DIR} \
--output_dir ${IMG_OUTPUT_DIR} \
--ve_name 'RN101_448' \
--model_type_or_path 'RN101'You can run the same script with same input list (i.e. --image_list or --anno) on another GPU (that can be from a different machine, provided that the disk to output the features is shared between the machines). The script will create a new feature extraction process that will only focus on processing the items that have not been processed yet, without overlapping with the other extraction process already running.
MIT
This repo used resources from OpenAI CLIP, timm, CLIP-ViL, X-modaler. The repo is implemented using PyTorch. We thank the authors for open-sourcing their awesome projects.
[1] How Much Can CLIP Benefit Vision-and-Language Tasks? Sheng Shen, Liunian Harold Li, Hao Tan, Mohit Bansal, Anna Rohrbach, Kai-Wei Chang, Zhewei Yao, Kurt Keutzer. In Arxiv2021.
[2] In Defense of Grid Features for Visual Question Answering. Huaizu Jiang, Ishan Misra, Marcus Rohrbach, Erik Learned-Miller, Xinlei Chen. In CVPR2020.
[3] X-modaler: A Versatile and High-performance Codebase for Cross-modal Analytics. Yehao Li, Yingwei Pan, Jingwen Chen, Ting Yao, Tao Mei. In ACMMM2021 Open Source Software Competition.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for OpenAI-CLIP-Feature
Similar Open Source Tools
OpenAI-CLIP-Feature
This repository provides code for extracting image and text features using OpenAI CLIP models, supporting both global and local grid visual features. It aims to facilitate multi visual-and-language downstream tasks by allowing users to customize input and output grid resolution easily. The extracted features have shown comparable or superior results in image captioning tasks without hyperparameter tuning. The repo supports various CLIP models and provides detailed information on supported settings and results on MSCOCO image captioning. Users can get started by setting up experiments with the extracted features using X-modaler.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.

LLaVA-MORE
LLaVA-MORE is a new family of Multimodal Language Models (MLLMs) that integrates recent language models with diverse visual backbones. The repository provides a unified training protocol for fair comparisons across all architectures and releases training code and scripts for distributed training. It aims to enhance Multimodal LLM performance and offers various models for different tasks. Users can explore different visual backbones like SigLIP and methods for managing image resolutions (S2) to improve the connection between images and language. The repository is a starting point for expanding the study of Multimodal LLMs and enhancing new features in the field.
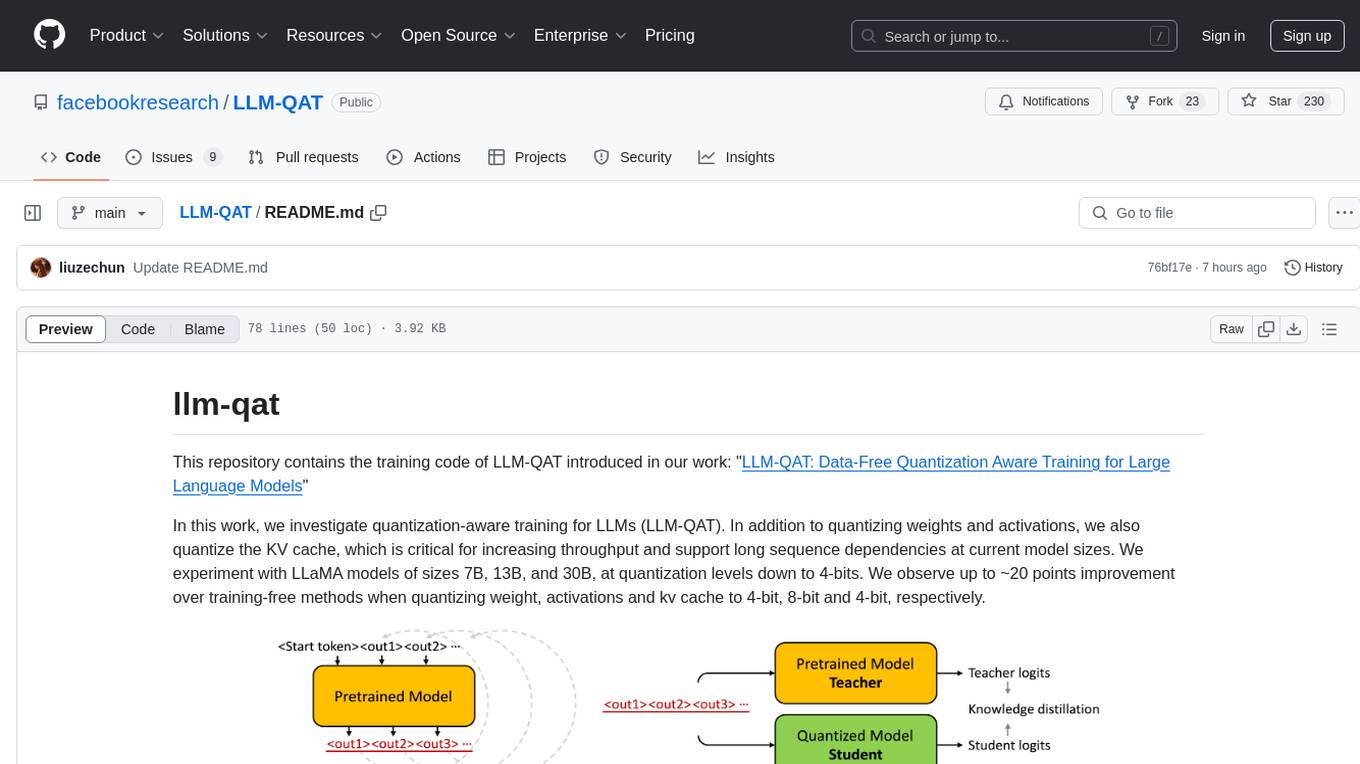
LLM-QAT
This repository contains the training code of LLM-QAT for large language models. The work investigates quantization-aware training for LLMs, including quantizing weights, activations, and the KV cache. Experiments were conducted on LLaMA models of sizes 7B, 13B, and 30B, at quantization levels down to 4-bits. Significant improvements were observed when quantizing weight, activations, and kv cache to 4-bit, 8-bit, and 4-bit, respectively.
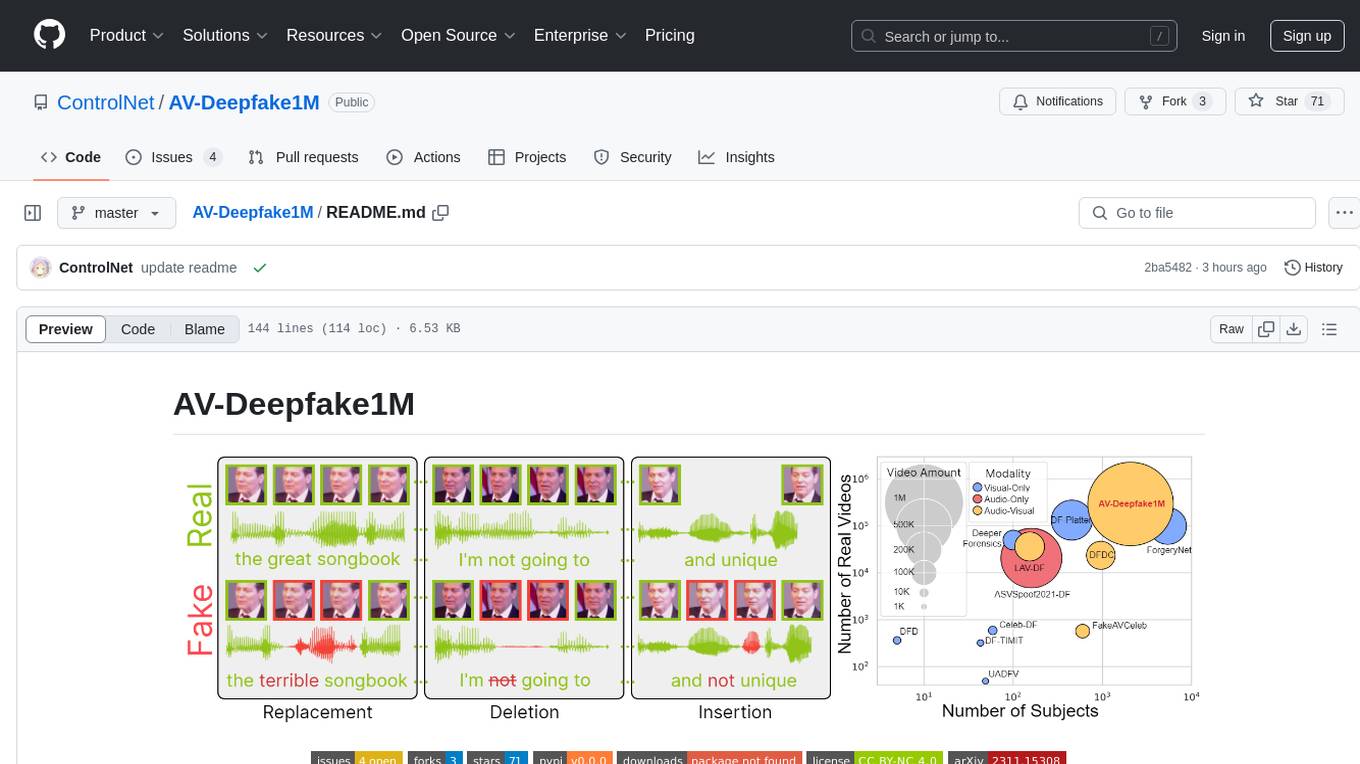
AV-Deepfake1M
The AV-Deepfake1M repository is the official repository for the paper AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset. It addresses the challenge of detecting and localizing deepfake audio-visual content by proposing a dataset containing video manipulations, audio manipulations, and audio-visual manipulations for over 2K subjects resulting in more than 1M videos. The dataset is crucial for developing next-generation deepfake localization methods.

qserve
QServe is a serving system designed for efficient and accurate Large Language Models (LLM) on GPUs with W4A8KV4 quantization. It achieves higher throughput compared to leading industry solutions, allowing users to achieve A100-level throughput on cheaper L40S GPUs. The system introduces the QoQ quantization algorithm with 4-bit weight, 8-bit activation, and 4-bit KV cache, addressing runtime overhead challenges. QServe improves serving throughput for various LLM models by implementing compute-aware weight reordering, register-level parallelism, and fused attention memory-bound techniques.

YuLan-Mini
YuLan-Mini is a lightweight language model with 2.4 billion parameters that achieves performance comparable to industry-leading models despite being pre-trained on only 1.08T tokens. It excels in mathematics and code domains. The repository provides pre-training resources, including data pipeline, optimization methods, and annealing approaches. Users can pre-train their own language models, perform learning rate annealing, fine-tune the model, research training dynamics, and synthesize data. The team behind YuLan-Mini is AI Box at Renmin University of China. The code is released under the MIT License with future updates on model weights usage policies. Users are advised on potential safety concerns and ethical use of the model.
llm4regression
This project explores the capability of Large Language Models (LLMs) to perform regression tasks using in-context examples. It compares the performance of LLMs like GPT-4 and Claude 3 Opus with traditional supervised methods such as Linear Regression and Gradient Boosting. The project provides preprints and results demonstrating the strong performance of LLMs in regression tasks. It includes datasets, models used, and experiments on adaptation and contamination. The code and data for the experiments are available for interaction and analysis.

EVE
EVE is an official PyTorch implementation of Unveiling Encoder-Free Vision-Language Models. The project aims to explore the removal of vision encoders from Vision-Language Models (VLMs) and transfer LLMs to encoder-free VLMs efficiently. It also focuses on bridging the performance gap between encoder-free and encoder-based VLMs. EVE offers a superior capability with arbitrary image aspect ratio, data efficiency by utilizing publicly available data for pre-training, and training efficiency with a transparent and practical strategy for developing a pure decoder-only architecture across modalities.

IDvs.MoRec
This repository contains the source code for the SIGIR 2023 paper 'Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited'. It provides resources for evaluating foundation, transferable, multi-modal, and LLM recommendation models, along with datasets, pre-trained models, and training strategies for IDRec and MoRec using in-batch debiased cross-entropy loss. The repository also offers large-scale datasets, code for SASRec with in-batch debias cross-entropy loss, and information on joining the lab for research opportunities.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.

MathEval
MathEval is a benchmark designed for evaluating the mathematical capabilities of large models. It includes over 20 evaluation datasets covering various mathematical domains with more than 30,000 math problems. The goal is to assess the performance of large models across different difficulty levels and mathematical subfields. MathEval serves as a reliable reference for comparing mathematical abilities among large models and offers guidance on enhancing their mathematical capabilities in the future.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.

PredictorLLM
PredictorLLM is an advanced trading agent framework that utilizes large language models to automate trading in financial markets. It includes a profiling module to establish agent characteristics, a layered memory module for retaining and prioritizing financial data, and a decision-making module to convert insights into trading strategies. The framework mimics professional traders' behavior, surpassing human limitations in data processing and continuously evolving to adapt to market conditions for superior investment outcomes.
For similar tasks
OpenAI-CLIP-Feature
This repository provides code for extracting image and text features using OpenAI CLIP models, supporting both global and local grid visual features. It aims to facilitate multi visual-and-language downstream tasks by allowing users to customize input and output grid resolution easily. The extracted features have shown comparable or superior results in image captioning tasks without hyperparameter tuning. The repo supports various CLIP models and provides detailed information on supported settings and results on MSCOCO image captioning. Users can get started by setting up experiments with the extracted features using X-modaler.
seemore
seemore is a vision language model developed in Pytorch, implementing components like image encoder, vision-language projector, and decoder language model. The model is built from scratch, including attention mechanisms and patch creation. It is designed for readability and hackability, with the intention to be improved upon. The implementation is based on public publications and borrows attention mechanism from makemore by Andrej Kapathy. The code was developed on Databricks using a single A100 for compute, and MLFlow is used for tracking metrics. The tool aims to provide a simplistic version of vision language models like Grok 1.5/GPT-4 Vision, suitable for experimentation and learning.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.