
PredictorLLM
None
Stars: 57

PredictorLLM is an advanced trading agent framework that utilizes large language models to automate trading in financial markets. It includes a profiling module to establish agent characteristics, a layered memory module for retaining and prioritizing financial data, and a decision-making module to convert insights into trading strategies. The framework mimics professional traders' behavior, surpassing human limitations in data processing and continuously evolving to adapt to market conditions for superior investment outcomes.
README:
This repository provides the Python source code for PredictorLLM, an advanced trading agent framework built upon large language models (LLMs) with enhanced memory architecture and intelligent design features.
PredictorLLM leverages the capabilities of large language models to facilitate automated trading in dynamic financial markets. This framework integrates three core components:
- Profiling Module: Establishes agent characteristics and operational scope.
- Layered Memory Module: Utilizes a structured memory system inspired by human cognitive processes for retaining and prioritizing financial data.
- Decision-Making Module: Converts insights from memory into actionable trading strategies.
With adjustable memory spans and the ability to assimilate hierarchical information, PredictorLLM mimics the behavior of professional traders while surpassing human limitations in data retention and processing. The framework continuously evolves to improve trading decisions and adapts to volatile market conditions, delivering superior investment outcomes.



We recommend using Docker for seamless code execution. The Dockerfile is available at Dockerfile, along with a development container setup for VSCode at devcontainer.json.
PredictorLLM runs on Python 3.10. Install all required dependencies using poetry:
poetry config virtualenvs.in-project true # Optional: Install virtualenv in the project
poetry installWe suggest using pipx to install poetry. Activate the virtual environment using poetry shell or source .venv/bin/activate (if virtualenv is installed in the project folder).
The entry point for the code is run.py. Use the following command to view available options:
python run.py --helpConfiguration settings are stored in config/config.toml.
To train the model, use:
python run.py trainDefault options include:
--market-data-path -mdp TEXT The market data path [default: /workspaces/ArkGPT/data/06_input/subset_symbols.pkl] │
--start-time -st TEXT The start time [default: 2022-03-14] │
--end-time -et TEXT The end time [default: 2022-06-27] │
--config-path -cp TEXT Config file path [default: config/config.toml] │
--checkpoint-path -ckp TEXT The checkpoint path [default: data/09_checkpoint] │
--save-every -se INTEGER Save every n steps [default: 1] │
--result-path -rp TEXT The result save path [default: data/11_train_result] │
--help Show this message and exit.
Training automatically saves checkpoints to resume progress in case of interruptions. Resume training using:
python run.py train-checkpoint| Type | Source | Notes | Download Method |
|---|---|---|---|
| Daily Stock Price | Yahoo Finance | Open, High, Low, Close, Volume | yfinance |
| Daily Market News | Alpaca Market News API | Historical news | Alpaca News API |
| Company 10-K | SEC EDGAR | Item 7 | SEC API |
| Company 10-Q | SEC EDGAR | Part 1 Item 2 | SEC API |
Daily Stock Price
| Column | Type | Notes |
|---|---|---|
| Date | datetime | - |
| Open | float | Opening price |
| High | float | Highest price |
| Low | float | Lowest price |
| Close | float | Closing price |
| Adj Close | float | Adjusted closing price |
| Volume | float | Trade volume |
| Symbol | str | Ticker symbol |
Daily Market News
| Column | Type | Notes |
|---|---|---|
| Author | str | - |
| Content | str | Content of news |
| DateTime | datetime | News timestamp |
| Date | datetime | Adjusted for trading hours |
| Source | str | News source |
| Summary | str | News summary |
| Title | str | News title |
| URL | str | News link |
| Equity | str | Ticker symbol |
| Text | str | Combined title and summary |
Company 10-K & 10-Q
| Column | Type | Notes |
|---|---|---|
| Document URL | str | Link to EDGAR file |
| Content | str | Extracted text content |
| Ticker | str | Company ticker symbol |
| UTC Timestamp | datetime | Coordinated Universal Time |
| EST Timestamp | datetime | Eastern Standard Time |
| Type | str | Report type ("10-K" or "10-Q") |
This revision avoids referencing the scientific paper and adjusts the language for general documentation purposes.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for PredictorLLM
Similar Open Source Tools
PredictorLLM
PredictorLLM is an advanced trading agent framework that utilizes large language models to automate trading in financial markets. It includes a profiling module to establish agent characteristics, a layered memory module for retaining and prioritizing financial data, and a decision-making module to convert insights into trading strategies. The framework mimics professional traders' behavior, surpassing human limitations in data processing and continuously evolving to adapt to market conditions for superior investment outcomes.

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.

spiceai
Spice is a portable runtime written in Rust that offers developers a unified SQL interface to materialize, accelerate, and query data from any database, data warehouse, or data lake. It connects, fuses, and delivers data to applications, machine-learning models, and AI-backends, functioning as an application-specific, tier-optimized Database CDN. Built with industry-leading technologies such as Apache DataFusion, Apache Arrow, Apache Arrow Flight, SQLite, and DuckDB. Spice makes it fast and easy to query data from one or more sources using SQL, co-locating a managed dataset with applications or machine learning models, and accelerating it with Arrow in-memory, SQLite/DuckDB, or attached PostgreSQL for fast, high-concurrency, low-latency queries.

optillm
optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.
aideml
AIDE is a machine learning code generation agent that can generate solutions for machine learning tasks from natural language descriptions. It has the following features: 1. **Instruct with Natural Language**: Describe your problem or additional requirements and expert insights, all in natural language. 2. **Deliver Solution in Source Code**: AIDE will generate Python scripts for the **tested** machine learning pipeline. Enjoy full transparency, reproducibility, and the freedom to further improve the source code! 3. **Iterative Optimization**: AIDE iteratively runs, debugs, evaluates, and improves the ML code, all by itself. 4. **Visualization**: We also provide tools to visualize the solution tree produced by AIDE for a better understanding of its experimentation process. This gives you insights not only about what works but also what doesn't. AIDE has been benchmarked on over 60 Kaggle data science competitions and has demonstrated impressive performance, surpassing 50% of Kaggle participants on average. It is particularly well-suited for tasks that require complex data preprocessing, feature engineering, and model selection.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.

chat-your-doc
Chat Your Doc is an experimental project exploring various applications based on LLM technology. It goes beyond being just a chatbot project, focusing on researching LLM applications using tools like LangChain and LlamaIndex. The project delves into UX, computer vision, and offers a range of examples in the 'Lab Apps' section. It includes links to different apps, descriptions, launch commands, and demos, aiming to showcase the versatility and potential of LLM applications.
rag-web-ui
RAG Web UI is an intelligent dialogue system based on RAG (Retrieval-Augmented Generation) technology. It helps enterprises and individuals build intelligent Q&A systems based on their own knowledge bases. By combining document retrieval and large language models, it delivers accurate and reliable knowledge-based question-answering services. The system is designed with features like intelligent document management, advanced dialogue engine, and a robust architecture. It supports multiple document formats, async document processing, multi-turn contextual dialogue, and reference citations in conversations. The architecture includes a backend stack with Python FastAPI, MySQL + ChromaDB, MinIO, Langchain, JWT + OAuth2 for authentication, and a frontend stack with Next.js, TypeScript, Tailwind CSS, Shadcn/UI, and Vercel AI SDK for AI integration. Performance optimization includes incremental document processing, streaming responses, vector database performance tuning, and distributed task processing. The project is licensed under the Apache-2.0 License and is intended for learning and sharing RAG knowledge only, not for commercial purposes.

SemanticFinder
SemanticFinder is a frontend-only live semantic search tool that calculates embeddings and cosine similarity client-side using transformers.js and SOTA embedding models from Huggingface. It allows users to search through large texts like books with pre-indexed examples, customize search parameters, and offers data privacy by keeping input text in the browser. The tool can be used for basic search tasks, analyzing texts for recurring themes, and has potential integrations with various applications like wikis, chat apps, and personal history search. It also provides options for building browser extensions and future ideas for further enhancements and integrations.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.
learn-claude-code
Learn Claude Code is an educational project by shareAI Lab that aims to help users understand how modern AI agents work by building one from scratch. The repository provides original educational material on various topics such as the agent loop, tool design, explicit planning, context management, knowledge injection, task systems, parallel execution, team messaging, and autonomous teams. Users can follow a learning path through different versions of the project, each introducing new concepts and mechanisms. The repository also includes technical tutorials, articles, and example skills for users to explore and learn from. The project emphasizes the philosophy that the model is crucial in agent development, with code playing a supporting role.

jailbreak_llms
This is the official repository for the ACM CCS 2024 paper 'Do Anything Now': Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models. The project employs a new framework called JailbreakHub to conduct the first measurement study on jailbreak prompts in the wild, collecting 15,140 prompts from December 2022 to December 2023, including 1,405 jailbreak prompts. The dataset serves as the largest collection of in-the-wild jailbreak prompts. The repository contains examples of harmful language and is intended for research purposes only.

DeepRetrieval
DeepRetrieval is a tool designed to enhance search engines and retrievers using Large Language Models (LLMs) and Reinforcement Learning (RL). It allows LLMs to learn how to search effectively by integrating with search engine APIs and customizing reward functions. The tool provides functionalities for data preparation, training, evaluation, and monitoring search performance. DeepRetrieval aims to improve information retrieval tasks by leveraging advanced AI techniques.
data-prep-kit
Data Prep Kit accelerates unstructured data preparation for LLM app developers. It allows developers to cleanse, transform, and enrich unstructured data for pre-training, fine-tuning, instruct-tuning LLMs, or building RAG applications. The kit provides modules for Python, Ray, and Spark runtimes, supporting Natural Language and Code data modalities. It offers a framework for custom transforms and uses Kubeflow Pipelines for workflow automation. Users can install the kit via PyPi and access a variety of transforms for data processing pipelines.
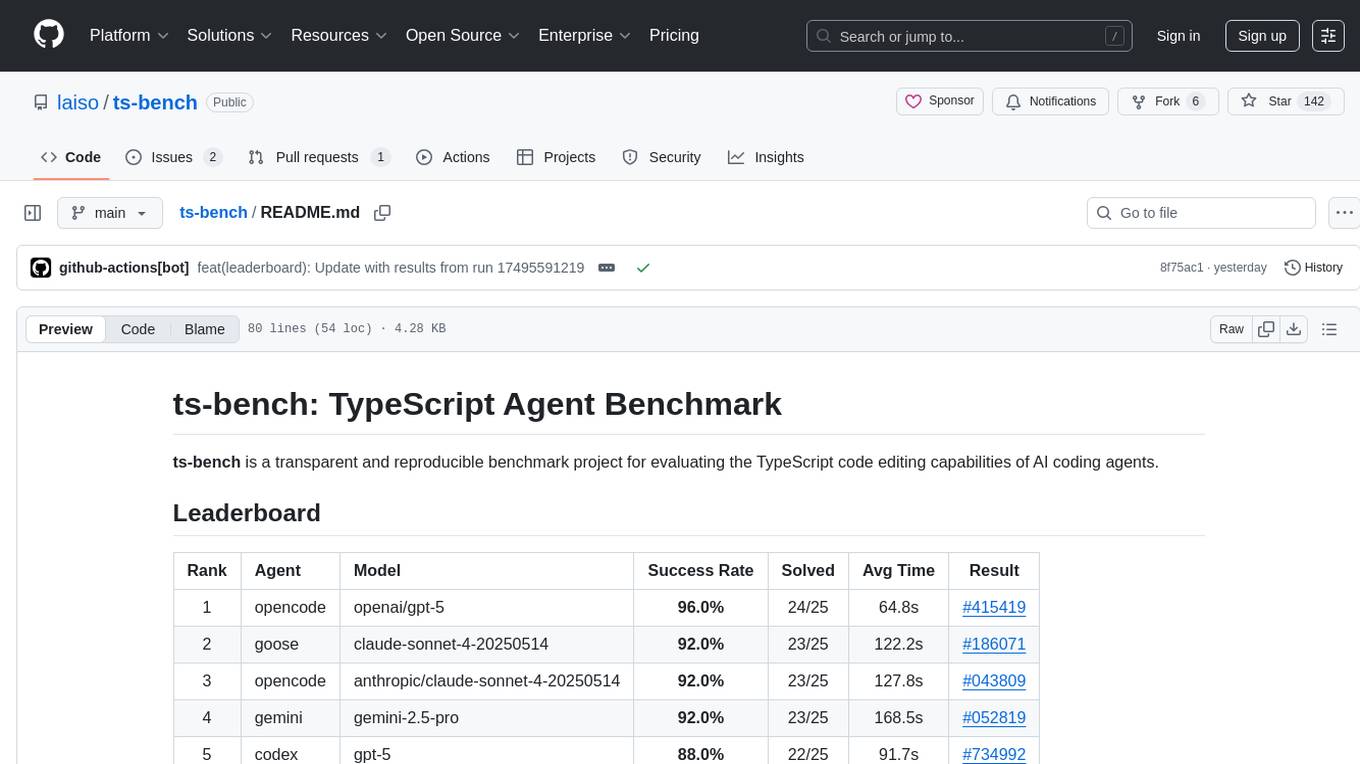
ts-bench
TS-Bench is a performance benchmarking tool for TypeScript projects. It provides detailed insights into the performance of TypeScript code, helping developers optimize their projects. With TS-Bench, users can measure and compare the execution time of different code snippets, functions, or modules. The tool offers a user-friendly interface for running benchmarks and analyzing the results. TS-Bench is a valuable asset for developers looking to enhance the performance of their TypeScript applications.
For similar tasks
FinRobot
FinRobot is an open-source AI agent platform designed for financial applications using large language models. It transcends the scope of FinGPT, offering a comprehensive solution that integrates a diverse array of AI technologies. The platform's versatility and adaptability cater to the multifaceted needs of the financial industry. FinRobot's ecosystem is organized into four layers, including Financial AI Agents Layer, Financial LLMs Algorithms Layer, LLMOps and DataOps Layers, and Multi-source LLM Foundation Models Layer. The platform's agent workflow involves Perception, Brain, and Action modules to capture, process, and execute financial data and insights. The Smart Scheduler optimizes model diversity and selection for tasks, managed by components like Director Agent, Agent Registration, Agent Adaptor, and Task Manager. The tool provides a structured file organization with subfolders for agents, data sources, and functional modules, along with installation instructions and hands-on tutorials.
AirdropsBot2024
AirdropsBot2024 is an efficient and secure solution for automated trading and sniping of coins on the Solana blockchain. It supports multiple chain networks such as Solana, BTC, and Ethereum. The bot utilizes premium APIs and Chromedriver to automate trading operations through web interfaces of popular exchanges. It offers high-speed data analysis, in-depth market analysis, support for major exchanges, complete security and control, data visualization, advanced notification options, flexibility and adaptability in trading strategies, and profile management.
gpt-bitcoin
The gpt-bitcoin repository is focused on creating an automated trading system for Bitcoin using GPT AI technology. It provides different versions of trading strategies utilizing various data sources such as OHLCV, Moving Averages, RSI, Stochastic Oscillator, MACD, Bollinger Bands, Orderbook Data, news data, fear/greed index, and chart images. Users can set up the system by creating a .env file with necessary API keys and installing required dependencies. The repository also includes instructions for setting up the environment on local machines and AWS EC2 Ubuntu servers. The future plan includes expanding the system to support other cryptocurrency exchanges like Bithumb, Binance, Coinbase, OKX, and Bybit.
ai-hedge-fund
AI Hedge Fund is a proof of concept for an AI-powered hedge fund that explores the use of AI to make trading decisions. The project is for educational purposes only and simulates trading decisions without actual trading. It employs agents like Market Data Analyst, Valuation Agent, Sentiment Agent, Fundamentals Agent, Technical Analyst, Risk Manager, and Portfolio Manager to gather and analyze data, calculate risk metrics, and make trading decisions.
PredictorLLM
PredictorLLM is an advanced trading agent framework that utilizes large language models to automate trading in financial markets. It includes a profiling module to establish agent characteristics, a layered memory module for retaining and prioritizing financial data, and a decision-making module to convert insights into trading strategies. The framework mimics professional traders' behavior, surpassing human limitations in data processing and continuously evolving to adapt to market conditions for superior investment outcomes.
tradecat
TradeCat is a comprehensive data analysis and trading platform designed for cryptocurrency, stock, and macroeconomic data. It offers a wide range of features including multi-market data collection, technical indicator modules, AI analysis, signal detection engine, Telegram bot integration, and more. The platform utilizes technologies like Python, TimescaleDB, TA-Lib, Pandas, NumPy, and various APIs to provide users with valuable insights and tools for trading decisions. With a modular architecture and detailed documentation, TradeCat aims to empower users in making informed trading decisions across different markets.
Qbot
Qbot is an AI-oriented automated quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It provides a full closed-loop process from data acquisition, strategy development, backtesting, simulation trading to live trading. The platform emphasizes AI strategies such as machine learning, reinforcement learning, and deep learning, combined with multi-factor models to enhance returns. Users with some Python knowledge and trading experience can easily utilize the platform to address trading pain points and gaps in the market.
awesome-quant-ai
Awesome Quant AI is a curated list of resources focusing on quantitative investment and trading strategies using artificial intelligence and machine learning in finance. It covers key challenges in quantitative finance, AI/ML technical fit, predictive modeling, sequential decision-making, synthetic data generation, contextual reasoning, mathematical foundations, design approach, quantitative trading strategies, tools and platforms, learning resources, books, research papers, community, and conferences. The repository aims to provide a comprehensive resource for those interested in the intersection of AI, machine learning, and quantitative finance, with a focus on extracting alpha while managing risk in financial systems.
For similar jobs

qlib
Qlib is an open-source, AI-oriented quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It covers the entire chain of quantitative investment, from alpha seeking to order execution. The platform empowers researchers to explore ideas and implement productions using AI technologies in quantitative investment. Qlib collaboratively solves key challenges in quantitative investment by releasing state-of-the-art research works in various paradigms. It provides a full ML pipeline for data processing, model training, and back-testing, enabling users to perform tasks such as forecasting market patterns, adapting to market dynamics, and modeling continuous investment decisions.
jupyter-quant
Jupyter Quant is a dockerized environment tailored for quantitative research, equipped with essential tools like statsmodels, pymc, arch, py_vollib, zipline-reloaded, PyPortfolioOpt, numpy, pandas, sci-py, scikit-learn, yellowbricks, shap, optuna, ib_insync, Cython, Numba, bottleneck, numexpr, jedi language server, jupyterlab-lsp, black, isort, and more. It does not include conda/mamba and relies on pip for package installation. The image is optimized for size, includes common command line utilities, supports apt cache, and allows for the installation of additional packages. It is designed for ephemeral containers, ensuring data persistence, and offers volumes for data, configuration, and notebooks. Common tasks include setting up the server, managing configurations, setting passwords, listing installed packages, passing parameters to jupyter-lab, running commands in the container, building wheels outside the container, installing dotfiles and SSH keys, and creating SSH tunnels.
FinRobot
FinRobot is an open-source AI agent platform designed for financial applications using large language models. It transcends the scope of FinGPT, offering a comprehensive solution that integrates a diverse array of AI technologies. The platform's versatility and adaptability cater to the multifaceted needs of the financial industry. FinRobot's ecosystem is organized into four layers, including Financial AI Agents Layer, Financial LLMs Algorithms Layer, LLMOps and DataOps Layers, and Multi-source LLM Foundation Models Layer. The platform's agent workflow involves Perception, Brain, and Action modules to capture, process, and execute financial data and insights. The Smart Scheduler optimizes model diversity and selection for tasks, managed by components like Director Agent, Agent Registration, Agent Adaptor, and Task Manager. The tool provides a structured file organization with subfolders for agents, data sources, and functional modules, along with installation instructions and hands-on tutorials.
hands-on-lab-neo4j-and-vertex-ai
This repository provides a hands-on lab for learning about Neo4j and Google Cloud Vertex AI. It is intended for data scientists and data engineers to deploy Neo4j and Vertex AI in a Google Cloud account, work with real-world datasets, apply generative AI, build a chatbot over a knowledge graph, and use vector search and index functionality for semantic search. The lab focuses on analyzing quarterly filings of asset managers with $100m+ assets under management, exploring relationships using Neo4j Browser and Cypher query language, and discussing potential applications in capital markets such as algorithmic trading and securities master data management.
jupyter-quant
Jupyter Quant is a dockerized environment tailored for quantitative research, equipped with essential tools like statsmodels, pymc, arch, py_vollib, zipline-reloaded, PyPortfolioOpt, numpy, pandas, sci-py, scikit-learn, yellowbricks, shap, optuna, and more. It provides Interactive Broker connectivity via ib_async and includes major Python packages for statistical and time series analysis. The image is optimized for size, includes jedi language server, jupyterlab-lsp, and common command line utilities. Users can install new packages with sudo, leverage apt cache, and bring their own dot files and SSH keys. The tool is designed for ephemeral containers, ensuring data persistence and flexibility for quantitative analysis tasks.
Qbot
Qbot is an AI-oriented automated quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It provides a full closed-loop process from data acquisition, strategy development, backtesting, simulation trading to live trading. The platform emphasizes AI strategies such as machine learning, reinforcement learning, and deep learning, combined with multi-factor models to enhance returns. Users with some Python knowledge and trading experience can easily utilize the platform to address trading pain points and gaps in the market.
FinMem-LLM-StockTrading
This repository contains the Python source code for FINMEM, a Performance-Enhanced Large Language Model Trading Agent with Layered Memory and Character Design. It introduces FinMem, a novel LLM-based agent framework devised for financial decision-making, encompassing three core modules: Profiling, Memory with layered processing, and Decision-making. FinMem's memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. The framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. It presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.
LLMs-in-Finance
This repository focuses on the application of Large Language Models (LLMs) in the field of finance. It provides insights and knowledge about how LLMs can be utilized in various scenarios within the finance industry, particularly in generating AI agents. The repository aims to explore the potential of LLMs to enhance financial processes and decision-making through the use of advanced natural language processing techniques.