
jupyter-quant
A dockerized Jupyter quant research environment.
Stars: 58
Jupyter Quant is a dockerized environment tailored for quantitative research, equipped with essential tools like statsmodels, pymc, arch, py_vollib, zipline-reloaded, PyPortfolioOpt, numpy, pandas, sci-py, scikit-learn, yellowbricks, shap, optuna, ib_insync, Cython, Numba, bottleneck, numexpr, jedi language server, jupyterlab-lsp, black, isort, and more. It does not include conda/mamba and relies on pip for package installation. The image is optimized for size, includes common command line utilities, supports apt cache, and allows for the installation of additional packages. It is designed for ephemeral containers, ensuring data persistence, and offers volumes for data, configuration, and notebooks. Common tasks include setting up the server, managing configurations, setting passwords, listing installed packages, passing parameters to jupyter-lab, running commands in the container, building wheels outside the container, installing dotfiles and SSH keys, and creating SSH tunnels.
README:
A dockerized Jupyter quant research environment.
- Includes tools for quant analysis, statsmodels, pymc, arch, py_vollib, zipline-reloaded, PyPortfolioOpt, etc.
- The usual suspects are included, numpy, pandas, sci-py, scikit-learn, yellowbricks, shap, optuna.
- ib_async for Interactive Broker connectivity. Works well with IB Gateway docker image. ib_insync has been of invaluable all this time, RIP Ewald.
- Includes all major Python packages for statistical and time series analysis, see requirements. For an extensive list check list installed packages section.
- Zipline-reloaded, pyfolio-reloaded and alphalens-reloaded.
- Designed for ephemeral containers. Relevant data for your environment will survive your container.
- Optimized for size, it's a 2GB image vs 4GB for jupyter/scipy-notebook
- Includes jedi language server, jupyterlab-lsp, black and isort.
- It does NOT include conda/mamba. All packages are installed with pip under
~/.local/lib/python. Which should be mounted in a dedicated volume to preserver your environment. - Includes Cython, Numba, bottleneck and numexpr to speed up things
- sudo, so you can install new packages if needed.
- bash and stow, so you can BYODF (bring your own dot files). Plus common command line utilities like git, less, nano (tiny), jq, ssh, curl, bash completion and others.
- Support for apt cache. If you have other Linux boxes using it can leverage your cache. apt cache supports major Linux distributions not only Debian/Ubuntu.
- It does not include a built environment. If you need to install a package that does not provide wheels you can build your wheels, as explained in common tasks
Create a docker-compose.yml file with this content
services:
jupyter-quant:
image: gnzsnz/jupyter-quant:${IMAGE_VERSION}
environment:
APT_PROXY: ${APT_PROXY:-}
BYODF: ${BYODF:-}
SSH_KEYDIR: ${SSH_KEYDIR:-}
TZ: ${QUANT_TZ:-}
restart: unless-stopped
ports:
- ${LISTEN_PORT}:8888
volumes:
- quant_conf:/home/gordon/.config
- quant_data:/home/gordon/.local
- ${PWD}/Notebooks:/home/gordon/Notebooks
volumes:
quant_conf:
quant_data:You can use .env-dist as your starting point.
cp .env-dist .env
# verify everything looks good
docker compose config
docker compose upThe image is designed to work with 3 volumes:
-
quant_data- volume for ~/.local folder. It contains caches and all python packages. This enables to add additional packages through pip. -
quant_conf- volume for ~/.config, all config goes here. This includes jupyter, ipython, matplotlib, etc - Bind mount (but you could use a named volume) - volume for all notebooks,
under
~/Notebooks.
This allows to have ephemeral containers and to keep your notebooks (3), your
config (2) and your additional packages (1). Eventually you would need to
update the image, in this case your notebooks (3) can move without issues,
your config (2) should still work but no warranty, and your packages in
quant_data could still be used but you should refresh it with a new image.
Eventually, you would need to refresh (1) and less frequently (2)
docker exec -it jupyterquant jupyter-server list
Currently running servers:
http://40798f7a604a:8888/?token=
ebf9e870d2aa0ed877590eb83b4d3bbbdfbd55467422a167 :: /home/gordon/Notebooksor
docker logs -t jupyter-quant 2>&1 | grep '127.0.0.1:8888/lab?token='You will need to change hostname (40798f7a604a in this case) or 127.0.0.1 by your docker host ip.
docker exec -it jupyter-quant jupyter-server --show-configdocker exec -it jupyter-quant jupyter-server passworddocker exec -it jupyter-quant jupyter-server --help
docker exec -it jupyter-quant jupyter-lab --helpdocker exec -it jupyter-quant pip list
# outdated packages
docker exec -it jupyter-quant pip list -odocker run -it --rm gnzsnz/jupyter-quant --core-mode
docker run -it --rm gnzsnz/jupyter-quant --show-config-jsondocker run -it --rm gnzsnz/jupyter-quant bashBuild wheels outside the container and import wheels into the container
# make sure python version match .env-dist
docker run -it --rm -v $PWD/wheels:/wheels python:3.11 bash
pip wheel --no-cache-dir --wheel-dir /wheels numpyThis will build wheels for numpy (or any other package that you need) and save
the file in $PWD/wheels. Then you can copy the wheels in your notebook mount
(3 above) and install it within the container. You can even drag and drop into
Jupyter.
git clone your dotfiles to Notebook/etc/dotfiles, set environment variable
BYODF=/home/gordon/Notebook/etc/dotfiles in your docker-compose.yml When
the container starts up stow will create links like /home/gordon/.bashrc
You need to define environment variable SSH_KEY_DIR which should point to a
location with your keys. The suggested place is
SSH_KEYDIR=/home/gordon/Notebooks/etc/ssh, make sure the director has the
right permissions. Something like chmod 700 Notebooks/etc/ssh should work.
The entrypoint.sh script will create a symbolic link pointing to
$SSH_KEYDIR on /home/gordon/.ssh.
Within Jupyter's terminal, you can then:
# start agent
eval $(ssh-agent)
# add keys to agent
ssh-add
# open a tunnel
ssh -fNL 4001:localhost:4001 gordon@bastion-sshFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for jupyter-quant
Similar Open Source Tools
jupyter-quant
Jupyter Quant is a dockerized environment tailored for quantitative research, equipped with essential tools like statsmodels, pymc, arch, py_vollib, zipline-reloaded, PyPortfolioOpt, numpy, pandas, sci-py, scikit-learn, yellowbricks, shap, optuna, ib_insync, Cython, Numba, bottleneck, numexpr, jedi language server, jupyterlab-lsp, black, isort, and more. It does not include conda/mamba and relies on pip for package installation. The image is optimized for size, includes common command line utilities, supports apt cache, and allows for the installation of additional packages. It is designed for ephemeral containers, ensuring data persistence, and offers volumes for data, configuration, and notebooks. Common tasks include setting up the server, managing configurations, setting passwords, listing installed packages, passing parameters to jupyter-lab, running commands in the container, building wheels outside the container, installing dotfiles and SSH keys, and creating SSH tunnels.
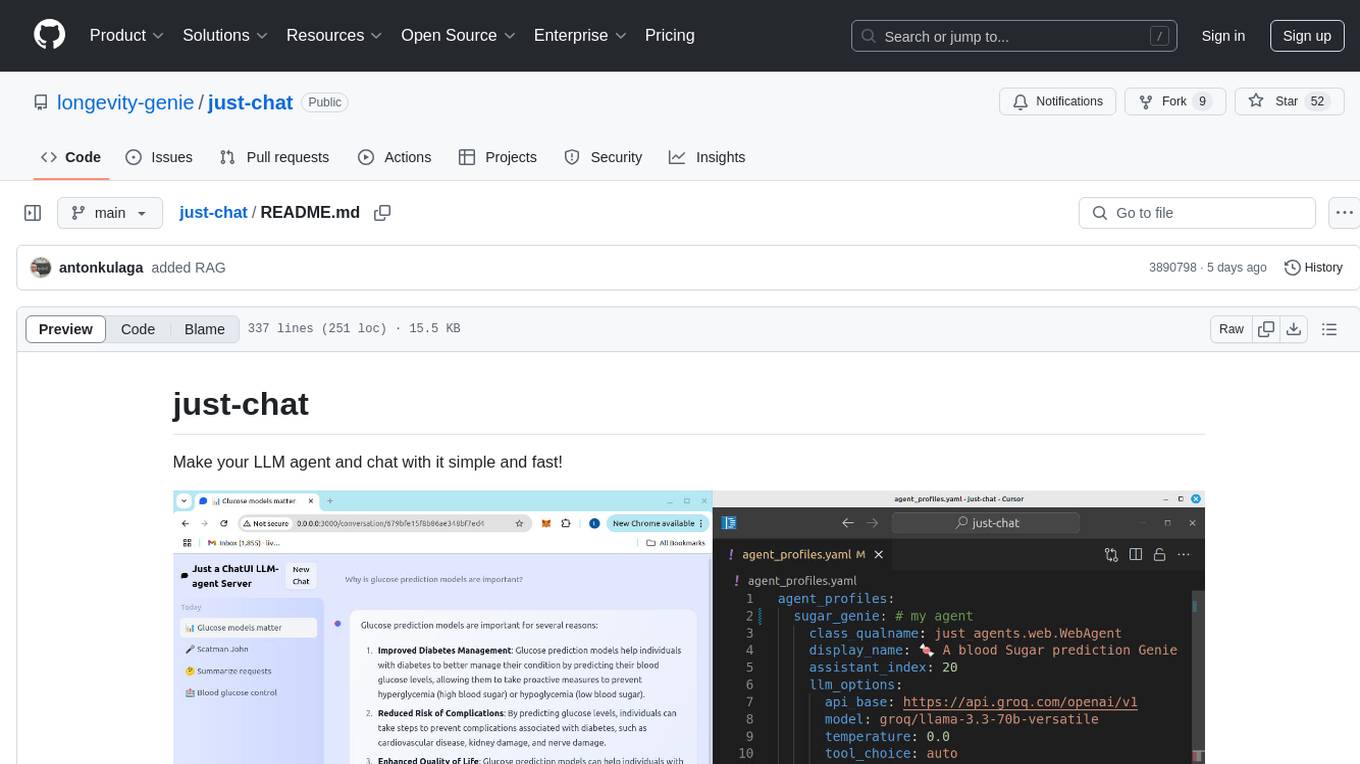
just-chat
Just-Chat is a containerized application that allows users to easily set up and chat with their AI agent. Users can customize their AI assistant using a YAML file, add new capabilities with Python tools, and interact with the agent through a chat web interface. The tool supports various modern models like DeepSeek Reasoner, ChatGPT, LLAMA3.3, etc. Users can also use semantic search capabilities with MeiliSearch to find and reference relevant information based on meaning. Just-Chat requires Docker or Podman for operation and provides detailed installation instructions for both Linux and Windows users.
vim-ollama
The 'vim-ollama' plugin for Vim adds Copilot-like code completion support using Ollama as a backend, enabling intelligent AI-based code completion and integrated chat support for code reviews. It does not rely on cloud services, preserving user privacy. The plugin communicates with Ollama via Python scripts for code completion and interactive chat, supporting Vim only. Users can configure LLM models for code completion tasks and interactive conversations, with detailed installation and usage instructions provided in the README.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.
air-light
Air-light is a minimalist WordPress starter theme designed to be an ultra minimal starting point for a WordPress project. It is built to be very straightforward, backwards compatible, front-end developer friendly and modular by its structure. Air-light is free of weird "app-like" folder structures or odd syntaxes that nobody else uses. It loves WordPress as it was and as it is.

log10
Log10 is a one-line Python integration to manage your LLM data. It helps you log both closed and open-source LLM calls, compare and identify the best models and prompts, store feedback for fine-tuning, collect performance metrics such as latency and usage, and perform analytics and monitor compliance for LLM powered applications. Log10 offers various integration methods, including a python LLM library wrapper, the Log10 LLM abstraction, and callbacks, to facilitate its use in both existing production environments and new projects. Pick the one that works best for you. Log10 also provides a copilot that can help you with suggestions on how to optimize your prompt, and a feedback feature that allows you to add feedback to your completions. Additionally, Log10 provides prompt provenance, session tracking and call stack functionality to help debug prompt chains. With Log10, you can use your data and feedback from users to fine-tune custom models with RLHF, and build and deploy more reliable, accurate and efficient self-hosted models. Log10 also supports collaboration, allowing you to create flexible groups to share and collaborate over all of the above features.

torchchat
torchchat is a codebase showcasing the ability to run large language models (LLMs) seamlessly. It allows running LLMs using Python in various environments such as desktop, server, iOS, and Android. The tool supports running models via PyTorch, chatting, generating text, running chat in the browser, and running models on desktop/server without Python. It also provides features like AOT Inductor for faster execution, running in C++ using the runner, and deploying and running on iOS and Android. The tool supports popular hardware and OS including Linux, Mac OS, Android, and iOS, with various data types and execution modes available.

dstack
Dstack is an open-source orchestration engine for running AI workloads in any cloud. It supports a wide range of cloud providers (such as AWS, GCP, Azure, Lambda, TensorDock, Vast.ai, CUDO, RunPod, etc.) as well as on-premises infrastructure. With Dstack, you can easily set up and manage dev environments, tasks, services, and pools for your AI workloads.
open-cuak
Open CUAK (Computer Use Agent) is a platform for managing automation agents at scale, designed to run and manage thousands of automation agents with reliability. It allows for abundant productivity by ensuring scalability and profitability. The project aims to usher in a new era of work with equally distributed productivity, making it open-sourced for real businesses and real people. The core features include running operator-like automation workflows locally, vision-based automation, turning any browser into an operator-companion, utilizing a dedicated remote browser, and more.

LeanCopilot
Lean Copilot is a tool that enables the use of large language models (LLMs) in Lean for proof automation. It provides features such as suggesting tactics/premises, searching for proofs, and running inference of LLMs. Users can utilize built-in models from LeanDojo or bring their own models to run locally or on the cloud. The tool supports platforms like Linux, macOS, and Windows WSL, with optional CUDA and cuDNN for GPU acceleration. Advanced users can customize behavior using Tactic APIs and Model APIs. Lean Copilot also allows users to bring their own models through ExternalGenerator or ExternalEncoder. The tool comes with caveats such as occasional crashes and issues with premise selection and proof search. Users can get in touch through GitHub Discussions for questions, bug reports, feature requests, and suggestions. The tool is designed to enhance theorem proving in Lean using LLMs.
kazam
Kazam 2.0 is a versatile tool for screen recording, broadcasting, capturing, and optical character recognition (OCR). It allows users to capture screen content, broadcast live over the internet, extract text from captured content, record audio, and use a web camera for recording. The tool supports full screen, window, and area modes, and offers features like keyboard shortcuts, live broadcasting with Twitch and YouTube, and tips for recording quality. Users can install Kazam on Ubuntu and use it for various recording and broadcasting needs.
linkedin-api
The Linkedin API for Python allows users to programmatically search profiles, send messages, and find jobs using a regular Linkedin user account. It does not require 'official' API access, just a valid Linkedin account. However, it is important to note that this library is not officially supported by LinkedIn and using it may violate LinkedIn's Terms of Service. Users can authenticate using any Linkedin account credentials and access features like getting profiles, profile contact info, and connections. The library also provides commercial alternatives for extracting data, scraping public profiles, and accessing a full LinkedIn API. It is not endorsed or supported by LinkedIn and is intended for educational purposes and personal use only.
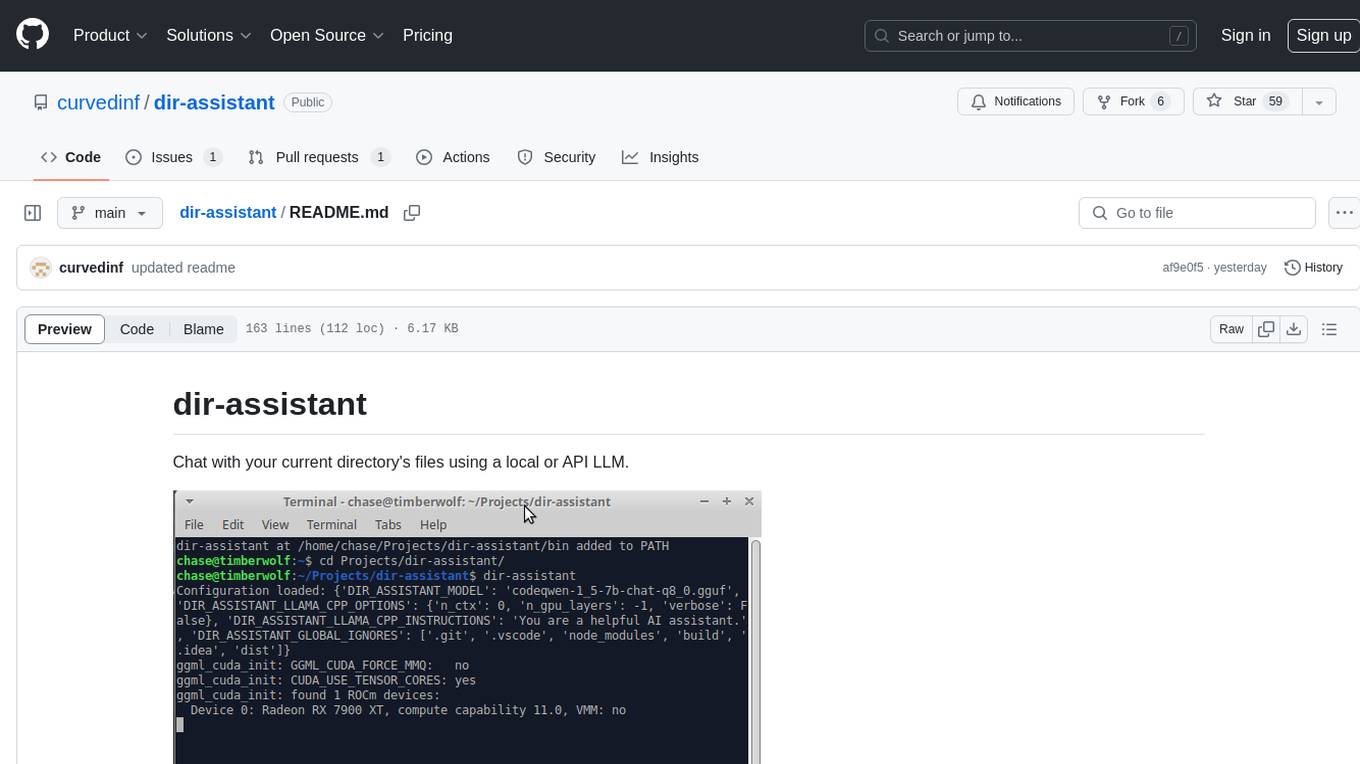
dir-assistant
Dir-assistant is a tool that allows users to interact with their current directory's files using local or API Language Models (LLMs). It supports various platforms and provides API support for major LLM APIs. Users can configure and customize their local LLMs and API LLMs using the tool. Dir-assistant also supports model downloads and configurations for efficient usage. It is designed to enhance file interaction and retrieval using advanced language models.

ai-starter-kit
SambaNova AI Starter Kits is a collection of open-source examples and guides designed to facilitate the deployment of AI-driven use cases for developers and enterprises. The kits cover various categories such as Data Ingestion & Preparation, Model Development & Optimization, Intelligent Information Retrieval, and Advanced AI Capabilities. Users can obtain a free API key using SambaNova Cloud or deploy models using SambaStudio. Most examples are written in Python but can be applied to any programming language. The kits provide resources for tasks like text extraction, fine-tuning embeddings, prompt engineering, question-answering, image search, post-call analysis, and more.

lhotse
Lhotse is a Python library designed to make speech and audio data preparation flexible and accessible. It aims to attract a wider community to speech processing tasks by providing a Python-centric design and an expressive command-line interface. Lhotse offers standard data preparation recipes, PyTorch Dataset classes for speech tasks, and efficient data preparation for model training with audio cuts. It supports data augmentation, feature extraction, and feature-space cut mixing. The tool extends Kaldi's data preparation recipes with seamless PyTorch integration, human-readable text manifests, and convenient Python classes.
Upscaler
Holloway's Upscaler is a consolidation of various compiled open-source AI image/video upscaling products for a CLI-friendly image and video upscaling program. It provides low-cost AI upscaling software that can run locally on a laptop, programmable for albums and videos, reliable for large video files, and works without GUI overheads. The repository supports hardware testing on various systems and provides important notes on GPU compatibility, video types, and image decoding bugs. Dependencies include ffmpeg and ffprobe for video processing. The user manual covers installation, setup pathing, calling for help, upscaling images and videos, and contributing back to the project. Benchmarks are provided for performance evaluation on different hardware setups.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

qlib
Qlib is an open-source, AI-oriented quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It covers the entire chain of quantitative investment, from alpha seeking to order execution. The platform empowers researchers to explore ideas and implement productions using AI technologies in quantitative investment. Qlib collaboratively solves key challenges in quantitative investment by releasing state-of-the-art research works in various paradigms. It provides a full ML pipeline for data processing, model training, and back-testing, enabling users to perform tasks such as forecasting market patterns, adapting to market dynamics, and modeling continuous investment decisions.
jupyter-quant
Jupyter Quant is a dockerized environment tailored for quantitative research, equipped with essential tools like statsmodels, pymc, arch, py_vollib, zipline-reloaded, PyPortfolioOpt, numpy, pandas, sci-py, scikit-learn, yellowbricks, shap, optuna, ib_insync, Cython, Numba, bottleneck, numexpr, jedi language server, jupyterlab-lsp, black, isort, and more. It does not include conda/mamba and relies on pip for package installation. The image is optimized for size, includes common command line utilities, supports apt cache, and allows for the installation of additional packages. It is designed for ephemeral containers, ensuring data persistence, and offers volumes for data, configuration, and notebooks. Common tasks include setting up the server, managing configurations, setting passwords, listing installed packages, passing parameters to jupyter-lab, running commands in the container, building wheels outside the container, installing dotfiles and SSH keys, and creating SSH tunnels.
FinRobot
FinRobot is an open-source AI agent platform designed for financial applications using large language models. It transcends the scope of FinGPT, offering a comprehensive solution that integrates a diverse array of AI technologies. The platform's versatility and adaptability cater to the multifaceted needs of the financial industry. FinRobot's ecosystem is organized into four layers, including Financial AI Agents Layer, Financial LLMs Algorithms Layer, LLMOps and DataOps Layers, and Multi-source LLM Foundation Models Layer. The platform's agent workflow involves Perception, Brain, and Action modules to capture, process, and execute financial data and insights. The Smart Scheduler optimizes model diversity and selection for tasks, managed by components like Director Agent, Agent Registration, Agent Adaptor, and Task Manager. The tool provides a structured file organization with subfolders for agents, data sources, and functional modules, along with installation instructions and hands-on tutorials.
hands-on-lab-neo4j-and-vertex-ai
This repository provides a hands-on lab for learning about Neo4j and Google Cloud Vertex AI. It is intended for data scientists and data engineers to deploy Neo4j and Vertex AI in a Google Cloud account, work with real-world datasets, apply generative AI, build a chatbot over a knowledge graph, and use vector search and index functionality for semantic search. The lab focuses on analyzing quarterly filings of asset managers with $100m+ assets under management, exploring relationships using Neo4j Browser and Cypher query language, and discussing potential applications in capital markets such as algorithmic trading and securities master data management.
jupyter-quant
Jupyter Quant is a dockerized environment tailored for quantitative research, equipped with essential tools like statsmodels, pymc, arch, py_vollib, zipline-reloaded, PyPortfolioOpt, numpy, pandas, sci-py, scikit-learn, yellowbricks, shap, optuna, and more. It provides Interactive Broker connectivity via ib_async and includes major Python packages for statistical and time series analysis. The image is optimized for size, includes jedi language server, jupyterlab-lsp, and common command line utilities. Users can install new packages with sudo, leverage apt cache, and bring their own dot files and SSH keys. The tool is designed for ephemeral containers, ensuring data persistence and flexibility for quantitative analysis tasks.
Qbot
Qbot is an AI-oriented automated quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It provides a full closed-loop process from data acquisition, strategy development, backtesting, simulation trading to live trading. The platform emphasizes AI strategies such as machine learning, reinforcement learning, and deep learning, combined with multi-factor models to enhance returns. Users with some Python knowledge and trading experience can easily utilize the platform to address trading pain points and gaps in the market.
FinMem-LLM-StockTrading
This repository contains the Python source code for FINMEM, a Performance-Enhanced Large Language Model Trading Agent with Layered Memory and Character Design. It introduces FinMem, a novel LLM-based agent framework devised for financial decision-making, encompassing three core modules: Profiling, Memory with layered processing, and Decision-making. FinMem's memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. The framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. It presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.
LLMs-in-Finance
This repository focuses on the application of Large Language Models (LLMs) in the field of finance. It provides insights and knowledge about how LLMs can be utilized in various scenarios within the finance industry, particularly in generating AI agents. The repository aims to explore the potential of LLMs to enhance financial processes and decision-making through the use of advanced natural language processing techniques.