
hands-on-lab-neo4j-and-vertex-ai
Hands on Lab for Neo4j and Vertex AI
Stars: 114
This repository provides a hands-on lab for learning about Neo4j and Google Cloud Vertex AI. It is intended for data scientists and data engineers to deploy Neo4j and Vertex AI in a Google Cloud account, work with real-world datasets, apply generative AI, build a chatbot over a knowledge graph, and use vector search and index functionality for semantic search. The lab focuses on analyzing quarterly filings of asset managers with $100m+ assets under management, exploring relationships using Neo4j Browser and Cypher query language, and discussing potential applications in capital markets such as algorithmic trading and securities master data management.
README:
Neo4j is the leading graph database vendor. We’ve worked closely with Google Cloud engineering for years. Our products, AuraDB and AuraDS are offered as managed services on Google Cloud. Neo4j Enterprise Edition, which includes Graph Database, Graph Data Science and Bloom is offered in the Google Cloud Marketplace.
In this hands on lab, you’ll get to learn about Neo4j and Google Cloud Vertex AI. The lab is intended for data scientists and data engineers. We’ll walk through deploying Neo4j and Vertex AI in a Google Cloud account. Then we’ll get hands on with a real world dataset. First we'll use generative AI to parse and load data. Then we'll show how to layer a chatbot powered by generative AI with LangChain over the knowledge graph. We'll even use the new vector search and index functionality in Neo4j with Vertex AI for semantic search. You’ll come out of this lab with enough knowledge to apply graph generative AI to your own datasets.
We’re going to analyze the quarterly filings of asset managers with $100m+ assets under management (AUM). These are regulatory filings made to the Securities and Exchange Commission’s (SEC) EDGAR system. We’re going to show how to load that data from a Google Cloud Storage bucket into Neo4j. We’ll then explore the relationships of different asset managers and their holdings using the Neo4j Browser and Neo4j’s Cypher query language.
If you’re in the capital markets space, we think you’ll be interested in potential applications of this approach to creating new features for algorithmic trading, understanding tail risk, securities master data management and so on. If you’re not in the capital markets space, this session will still be useful to learn about building machine learning pipelines with Neo4j and Vertex AI.
These workshops are organized onsite in a Google office.
3 hours.
You'll need a laptop with a web browser. Your browser will need to be able to access the Google Cloud Console and port 7474 on a Neo4j deployment running on Google Cloud. If your laptop has a firewall you can't control on it, you may want to bring your personal laptop.
- Introductions
- Lecture - Introduction to Neo4j (10 min)
- What is Neo4j?
- How is it deployed and managed on Google Cloud?
-
Lab 0 - Sign In (5 min)
- Improving the Labs
- Sign into Google Cloud
-
Lab 1 - Deploy Neo4j (15 min)
- Deploying Neo4j AuraDS Professional
- Lab 2 - Connect to Neo4j (10 min)
- Break (5 min)
- Lecture - Moving Data (10 min)
- LOAD CSV
- Apache Beam and Google Dataflow
- Apache Spark and Google Dataproc
- Apache Kafka and Cloud Cloud
-
Lab 3 - Moving Data (15 min)
- Simple Load Statement
- More Performant Load
-
Lab 4 - Exploration 10 min)
- Exploration with Neo4j Bloom
- Break (5 min)
- Lecture - Vertex AI (15 min)
- What is Vertex AI?
- Workbench
- Generative AI
- Lecture - Neo4j and Generative AI (15 min)
- Generating Knowledge Graphs
- Retrieval Augmented Generation
- Semantic Search
- Using Vertex AI with Neo4j
-
Lab 5 - Parsing Data (20 min)
- Setup Vertex AI Workbench
- Parsing Data
-
Lab 6 - Chatbot (20 min)
- Prompt Engineering
- Few Shot Learning
- Using the Chatbot
-
Lab 7 - Semantic Search (20 min)
- Text Embedding
- Vector Search
- Graph Traversal
- Graph Algorithms for Similairty
- Questions and Next Steps (5 min)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for hands-on-lab-neo4j-and-vertex-ai
Similar Open Source Tools
hands-on-lab-neo4j-and-vertex-ai
This repository provides a hands-on lab for learning about Neo4j and Google Cloud Vertex AI. It is intended for data scientists and data engineers to deploy Neo4j and Vertex AI in a Google Cloud account, work with real-world datasets, apply generative AI, build a chatbot over a knowledge graph, and use vector search and index functionality for semantic search. The lab focuses on analyzing quarterly filings of asset managers with $100m+ assets under management, exploring relationships using Neo4j Browser and Cypher query language, and discussing potential applications in capital markets such as algorithmic trading and securities master data management.

cube
Cube is a semantic layer for building data applications, helping data engineers and application developers access data from modern data stores, organize it into consistent definitions, and deliver it to every application. It works with SQL-enabled data sources, providing sub-second latency and high concurrency for API requests. Cube addresses SQL code organization, performance, and access control issues in data applications, enabling efficient data modeling, access control, and performance optimizations for various tools like embedded analytics, dashboarding, reporting, and data notebooks.

morphik-core
Morphik is an AI-native toolset designed to help developers integrate context into their AI applications by providing tools to store, represent, and search unstructured data. It offers features such as multimodal search, fast metadata extraction, and integrations with existing tools. Morphik aims to address the challenges of traditional AI approaches that struggle with visually rich documents and provide a more comprehensive solution for understanding and processing complex data.

supervisely
Supervisely is a computer vision platform that provides a range of tools and services for developing and deploying computer vision solutions. It includes a data labeling platform, a model training platform, and a marketplace for computer vision apps. Supervisely is used by a variety of organizations, including Fortune 500 companies, research institutions, and government agencies.

mindsdb
MindsDB is a platform for customizing AI from enterprise data. You can create, serve, and fine-tune models in real-time from your database, vector store, and application data. MindsDB "enhances" SQL syntax with AI capabilities to make it accessible for developers worldwide. With MindsDB’s nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely. Their AI systems will constantly improve themselves — using companies’ own data, in real-time.
aitour26-WRK541-real-world-code-migration-with-github-copilot-agent-mode
Microsoft AI Tour 2026 WRK541 is a workshop focused on real-world code migration using GitHub Copilot Agent Mode. The session is designed for technologists interested in applying AI pair-programming techniques to challenging tasks like migrating or translating code between different programming languages. Participants will learn advanced GitHub Copilot techniques, differences between Python and C#, JSON serialization and deserialization in C#, developing and validating endpoints, integrating Swagger/OpenAPI documentation, and writing unit tests with MSTest. The workshop aims to help users gain hands-on experience in using GitHub Copilot for real-world code migration scenarios.

oreilly-retrieval-augmented-gen-ai
This repository focuses on Retrieval-Augmented Generation (RAG) and Large Language Models (LLMs). It provides code and resources to augment LLMs with real-time data for dynamic, context-aware applications. The content covers topics such as semantic search, fine-tuning embeddings, building RAG chatbots, evaluating LLMs, and using knowledge graphs in RAG. Prerequisites include Python skills, knowledge of machine learning and LLMs, and introductory experience with NLP and AI models.

wren-engine
Wren Engine is a semantic engine designed to serve as the backbone of the semantic layer for LLMs. It simplifies the user experience by translating complex data structures into a business-friendly format, enabling end-users to interact with data using familiar terminology. The engine powers the semantic layer with advanced capabilities to define and manage modeling definitions, metadata, schema, data relationships, and logic behind calculations and aggregations through an analytics-as-code design approach. By leveraging Wren Engine, organizations can ensure a developer-friendly semantic layer that reflects nuanced data relationships and dynamics, facilitating more informed decision-making and strategic insights.

kdbai-samples
KDB.AI is a time-based vector database that allows developers to build scalable, reliable, and real-time applications by providing advanced search, recommendation, and personalization for Generative AI applications. It supports multiple index types, distance metrics, top-N and metadata filtered retrieval, as well as Python and REST interfaces. The repository contains samples demonstrating various use-cases such as temporal similarity search, document search, image search, recommendation systems, sentiment analysis, and more. KDB.AI integrates with platforms like ChatGPT, Langchain, and LlamaIndex. The setup steps require Unix terminal, Python 3.8+, and pip installed. Users can install necessary Python packages and run Jupyter notebooks to interact with the samples.
applied-ai-engineering-samples
The Google Cloud Applied AI Engineering repository provides reference guides, blueprints, code samples, and hands-on labs developed by the Google Cloud Applied AI Engineering team. It contains resources for Generative AI on Vertex AI, including code samples and hands-on labs demonstrating the use of Generative AI models and tools in Vertex AI. Additionally, it offers reference guides and blueprints that compile best practices and prescriptive guidance for running large-scale AI/ML workloads on Google Cloud AI/ML infrastructure.
Sarvadnya
Sarvadnya is a repository focused on interfacing custom data using Large Language Models (LLMs) through Proof-of-Concepts (PoCs) like Retrieval Augmented Generation (RAG) and Fine-Tuning. It aims to enable domain adaptation for LLMs to answer on user-specific corpora. The repository also covers topics such as Indic-languages models, 3D World Simulations, Knowledge Graphs Generation, Signal Processing, Drones, UAV Image Processing, and Floor Plan Segmentation. It provides insights into building chatbots of various modalities, preparing videos, and creating content for different platforms like Medium, LinkedIn, and YouTube. The tech stacks involved range from enterprise solutions like Google Doc AI and Microsoft Azure Language AI Services to open-source tools like Langchain and HuggingFace.
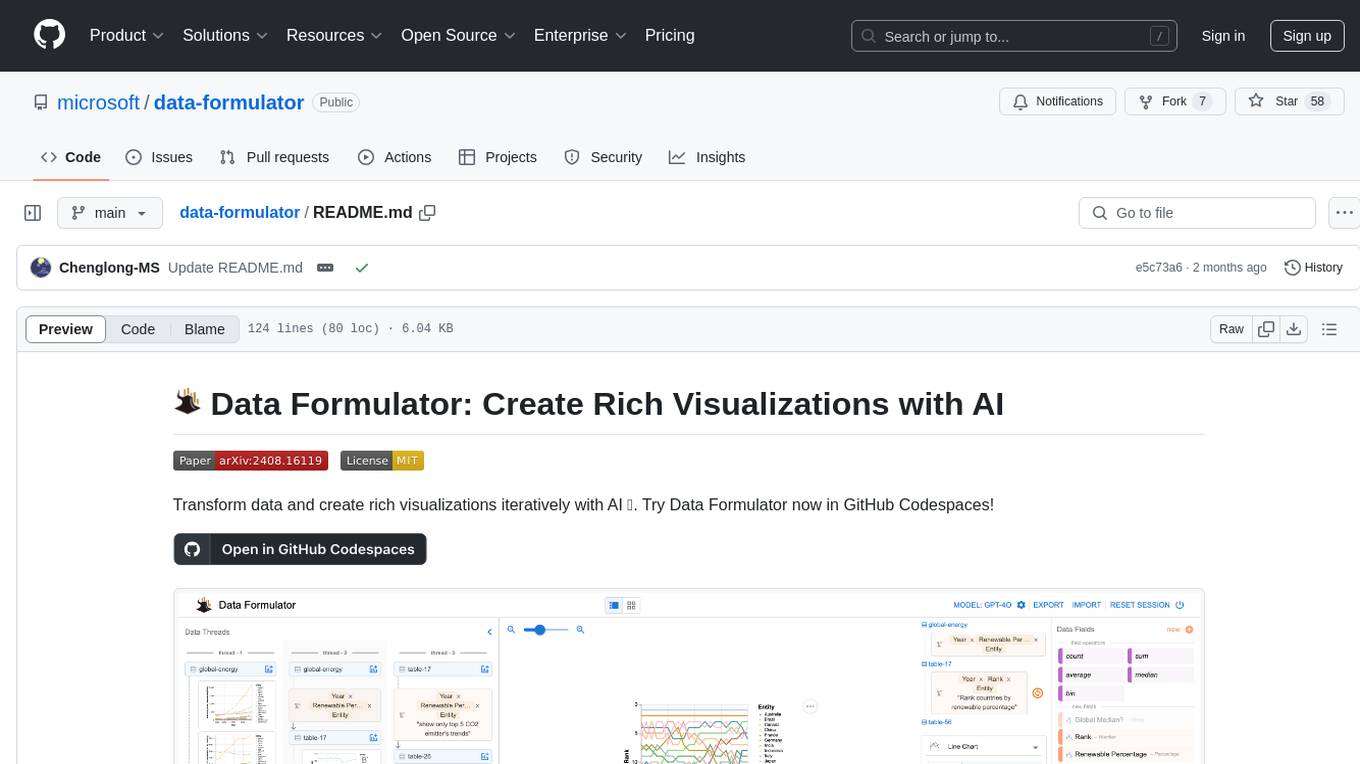
data-formulator
Data Formulator is an AI-powered tool developed by Microsoft Research to help data analysts create rich visualizations iteratively. It combines user interface interactions with natural language inputs to simplify the process of describing chart designs while delegating data transformation to AI. Users can utilize features like blended UI and NL inputs, data threads for history navigation, and code inspection to create impressive visualizations. The tool supports local installation for customization and Codespaces for quick setup. Developers can build new data analysis tools on top of Data Formulator, and research papers are available for further reading.

spring-ai
The Spring AI project provides a Spring-friendly API and abstractions for developing AI applications. It offers a portable client API for interacting with generative AI models, enabling developers to easily swap out implementations and access various models like OpenAI, Azure OpenAI, and HuggingFace. Spring AI also supports prompt engineering, providing classes and interfaces for creating and parsing prompts, as well as incorporating proprietary data into generative AI without retraining the model. This is achieved through Retrieval Augmented Generation (RAG), which involves extracting, transforming, and loading data into a vector database for use by AI models. Spring AI's VectorStore abstraction allows for seamless transitions between different vector database implementations.
Symposium2023
Symposium2023 is a project aimed at enabling Delphi users to incorporate AI technology into their applications. It provides generalized interfaces to different AI models, making them easily accessible. The project showcases AI's versatility in tasks like language translation, human-like conversations, image generation, data analysis, and more. Users can experiment with different AI models, change providers easily, and avoid vendor lock-in. The project supports various AI features like vision support and function calling, utilizing providers like Google, Microsoft Azure, Amazon, OpenAI, and more. It includes example programs demonstrating tasks such as text-to-speech, language translation, face detection, weather querying, audio transcription, voice recognition, image generation, invoice processing, and API testing. The project also hints at potential future research areas like using embeddings for data search and integrating Python AI libraries with Delphi.

PulsarRPA
PulsarRPA is a high-performance, distributed, open-source Robotic Process Automation (RPA) framework designed to handle large-scale RPA tasks with ease. It provides a comprehensive solution for browser automation, web content understanding, and data extraction. PulsarRPA addresses challenges of browser automation and accurate web data extraction from complex and evolving websites. It incorporates innovative technologies like browser rendering, RPA, intelligent scraping, advanced DOM parsing, and distributed architecture to ensure efficient, accurate, and scalable web data extraction. The tool is open-source, customizable, and supports cutting-edge information extraction technology, making it a preferred solution for large-scale web data extraction.
awesome-ai
Awesome AI is a curated list of artificial intelligence resources including courses, tools, apps, and open-source projects. It covers a wide range of topics such as machine learning, deep learning, natural language processing, robotics, conversational interfaces, data science, and more. The repository serves as a comprehensive guide for individuals interested in exploring the field of artificial intelligence and its applications across various domains.
For similar tasks
hands-on-lab-neo4j-and-vertex-ai
This repository provides a hands-on lab for learning about Neo4j and Google Cloud Vertex AI. It is intended for data scientists and data engineers to deploy Neo4j and Vertex AI in a Google Cloud account, work with real-world datasets, apply generative AI, build a chatbot over a knowledge graph, and use vector search and index functionality for semantic search. The lab focuses on analyzing quarterly filings of asset managers with $100m+ assets under management, exploring relationships using Neo4j Browser and Cypher query language, and discussing potential applications in capital markets such as algorithmic trading and securities master data management.

graphrag-visualizer
GraphRAG Visualizer is an application designed to visualize Microsoft GraphRAG artifacts by uploading parquet files generated from the GraphRAG indexing pipeline. Users can view and analyze data in 2D or 3D graphs, display data tables, search for specific nodes or relationships, and process artifacts locally for data security and privacy.
Flowise
Flowise is a tool that allows users to build customized LLM flows with a drag-and-drop UI. It is open-source and self-hostable, and it supports various deployments, including AWS, Azure, Digital Ocean, GCP, Railway, Render, HuggingFace Spaces, Elestio, Sealos, and RepoCloud. Flowise has three different modules in a single mono repository: server, ui, and components. The server module is a Node backend that serves API logics, the ui module is a React frontend, and the components module contains third-party node integrations. Flowise supports different environment variables to configure your instance, and you can specify these variables in the .env file inside the packages/server folder.

nlux
nlux is an open-source Javascript and React JS library that makes it super simple to integrate powerful large language models (LLMs) like ChatGPT into your web app or website. With just a few lines of code, you can add conversational AI capabilities and interact with your favourite LLM.
generative-ai-go
The Google AI Go SDK enables developers to use Google's state-of-the-art generative AI models (like Gemini) to build AI-powered features and applications. It supports use cases like generating text from text-only input, generating text from text-and-images input (multimodal), building multi-turn conversations (chat), and embedding.
awesome-langchain-zh
The awesome-langchain-zh repository is a collection of resources related to LangChain, a framework for building AI applications using large language models (LLMs). The repository includes sections on the LangChain framework itself, other language ports of LangChain, tools for low-code development, services, agents, templates, platforms, open-source projects related to knowledge management and chatbots, as well as learning resources such as notebooks, videos, and articles. It also covers other LLM frameworks and provides additional resources for exploring and working with LLMs. The repository serves as a comprehensive guide for developers and AI enthusiasts interested in leveraging LangChain and LLMs for various applications.

Large-Language-Model-Notebooks-Course
This practical free hands-on course focuses on Large Language models and their applications, providing a hands-on experience using models from OpenAI and the Hugging Face library. The course is divided into three major sections: Techniques and Libraries, Projects, and Enterprise Solutions. It covers topics such as Chatbots, Code Generation, Vector databases, LangChain, Fine Tuning, PEFT Fine Tuning, Soft Prompt tuning, LoRA, QLoRA, Evaluate Models, Knowledge Distillation, and more. Each section contains chapters with lessons supported by notebooks and articles. The course aims to help users build projects and explore enterprise solutions using Large Language Models.
ai-chatbot
Next.js AI Chatbot is an open-source app template for building AI chatbots using Next.js, Vercel AI SDK, OpenAI, and Vercel KV. It includes features like Next.js App Router, React Server Components, Vercel AI SDK for streaming chat UI, support for various AI models, Tailwind CSS styling, Radix UI for headless components, chat history management, rate limiting, session storage with Vercel KV, and authentication with NextAuth.js. The template allows easy deployment to Vercel and customization of AI model providers.
For similar jobs

qlib
Qlib is an open-source, AI-oriented quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It covers the entire chain of quantitative investment, from alpha seeking to order execution. The platform empowers researchers to explore ideas and implement productions using AI technologies in quantitative investment. Qlib collaboratively solves key challenges in quantitative investment by releasing state-of-the-art research works in various paradigms. It provides a full ML pipeline for data processing, model training, and back-testing, enabling users to perform tasks such as forecasting market patterns, adapting to market dynamics, and modeling continuous investment decisions.
jupyter-quant
Jupyter Quant is a dockerized environment tailored for quantitative research, equipped with essential tools like statsmodels, pymc, arch, py_vollib, zipline-reloaded, PyPortfolioOpt, numpy, pandas, sci-py, scikit-learn, yellowbricks, shap, optuna, ib_insync, Cython, Numba, bottleneck, numexpr, jedi language server, jupyterlab-lsp, black, isort, and more. It does not include conda/mamba and relies on pip for package installation. The image is optimized for size, includes common command line utilities, supports apt cache, and allows for the installation of additional packages. It is designed for ephemeral containers, ensuring data persistence, and offers volumes for data, configuration, and notebooks. Common tasks include setting up the server, managing configurations, setting passwords, listing installed packages, passing parameters to jupyter-lab, running commands in the container, building wheels outside the container, installing dotfiles and SSH keys, and creating SSH tunnels.
FinRobot
FinRobot is an open-source AI agent platform designed for financial applications using large language models. It transcends the scope of FinGPT, offering a comprehensive solution that integrates a diverse array of AI technologies. The platform's versatility and adaptability cater to the multifaceted needs of the financial industry. FinRobot's ecosystem is organized into four layers, including Financial AI Agents Layer, Financial LLMs Algorithms Layer, LLMOps and DataOps Layers, and Multi-source LLM Foundation Models Layer. The platform's agent workflow involves Perception, Brain, and Action modules to capture, process, and execute financial data and insights. The Smart Scheduler optimizes model diversity and selection for tasks, managed by components like Director Agent, Agent Registration, Agent Adaptor, and Task Manager. The tool provides a structured file organization with subfolders for agents, data sources, and functional modules, along with installation instructions and hands-on tutorials.
hands-on-lab-neo4j-and-vertex-ai
This repository provides a hands-on lab for learning about Neo4j and Google Cloud Vertex AI. It is intended for data scientists and data engineers to deploy Neo4j and Vertex AI in a Google Cloud account, work with real-world datasets, apply generative AI, build a chatbot over a knowledge graph, and use vector search and index functionality for semantic search. The lab focuses on analyzing quarterly filings of asset managers with $100m+ assets under management, exploring relationships using Neo4j Browser and Cypher query language, and discussing potential applications in capital markets such as algorithmic trading and securities master data management.
jupyter-quant
Jupyter Quant is a dockerized environment tailored for quantitative research, equipped with essential tools like statsmodels, pymc, arch, py_vollib, zipline-reloaded, PyPortfolioOpt, numpy, pandas, sci-py, scikit-learn, yellowbricks, shap, optuna, and more. It provides Interactive Broker connectivity via ib_async and includes major Python packages for statistical and time series analysis. The image is optimized for size, includes jedi language server, jupyterlab-lsp, and common command line utilities. Users can install new packages with sudo, leverage apt cache, and bring their own dot files and SSH keys. The tool is designed for ephemeral containers, ensuring data persistence and flexibility for quantitative analysis tasks.
Qbot
Qbot is an AI-oriented automated quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It provides a full closed-loop process from data acquisition, strategy development, backtesting, simulation trading to live trading. The platform emphasizes AI strategies such as machine learning, reinforcement learning, and deep learning, combined with multi-factor models to enhance returns. Users with some Python knowledge and trading experience can easily utilize the platform to address trading pain points and gaps in the market.
FinMem-LLM-StockTrading
This repository contains the Python source code for FINMEM, a Performance-Enhanced Large Language Model Trading Agent with Layered Memory and Character Design. It introduces FinMem, a novel LLM-based agent framework devised for financial decision-making, encompassing three core modules: Profiling, Memory with layered processing, and Decision-making. FinMem's memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. The framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. It presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.
LLMs-in-Finance
This repository focuses on the application of Large Language Models (LLMs) in the field of finance. It provides insights and knowledge about how LLMs can be utilized in various scenarios within the finance industry, particularly in generating AI agents. The repository aims to explore the potential of LLMs to enhance financial processes and decision-making through the use of advanced natural language processing techniques.