
FinMem-LLM-StockTrading
FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
Stars: 220
This repository contains the Python source code for FINMEM, a Performance-Enhanced Large Language Model Trading Agent with Layered Memory and Character Design. It introduces FinMem, a novel LLM-based agent framework devised for financial decision-making, encompassing three core modules: Profiling, Memory with layered processing, and Decision-making. FinMem's memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. The framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. It presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.
README:
"So we beat on, boats against the current, borne back ceaselessly into the past."
-- F. Scott Fitzgerald: The Great Gatsby
This repo provides the Python source code for the paper: FINMEM: A Performance-Enhanced Large Language Model Trading Agent with Layered Memory and Character Design [PDF]
@misc{yu2023finmem,
title={FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design},
author={Yangyang Yu and Haohang Li and Zhi Chen and Yuechen Jiang and Yang Li and Denghui Zhang and Rong Liu and Jordan W. Suchow and Khaldoun Khashanah},
year={2023},
eprint={2311.13743},
archivePrefix={arXiv},
primaryClass={q-fin.CP}
}📢 Update (Date: 01-16-2024)
🚀 We're excited to share that our work, "FINMEM: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design," has been selected for an extended abstract at the AAAI Spring Symposium on Human-Like Learning!
📢 Update (Date: 03-11-2024)
🚀 We're thrilled to announce that our paper, "FINMEM: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design", has been accepted by ICLR Workshop LLM Agents!
📢 Update (Date: 06-16-2024)
🎉 Thank you to all the participants and organizers of the IJCAI2024 challenge, "Financial Challenges in Large Language Models - FinLLM". Our team, FinMem, was thrilled to contribute to Task 3: Single Stock Trading.
As the challenge wrapped up yesterday (06/15/2024), we reflect on the innovative approaches and insights gained throughout this journey. A total of 12 teams participated, each bringing unique perspectives and solutions to the forefront of financial AI and Large Language Models.
We invite the community to continue engaging with us as we look forward to further developments and collaborations in this exciting field.
Recent advancements in Large Language Models (LLMs) have exhibited notable efficacy in question-answering (QA) tasks across diverse domains. Their prowess in integrating extensive web knowledge has fueled interest in developing LLM-based autonomous agents. While LLMs are efficient in decoding human instructions and deriving solutions by holistically processing historical inputs, transitioning to purpose-driven agents requires a supplementary rational architecture to process multi-source information, establish reasoning chains, and prioritize critical tasks. Addressing this, we introduce FinMem, a novel LLM-based agent framework devised for financial decision-making, encompassing three core modules: Profiling, to outline the agent's characteristics; Memory, with layered processing, to aid the agent in assimilating realistic hierarchical financial data; and Decision-making, to convert insights gained from memories into investment decisions. Notably, FinMem's memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. Its adjustable cognitive span allows for the retention of critical information beyond human perceptual limits, thereby enhancing trading outcomes. This framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. We first compare FinMem with various algorithmic agents on a scalable real-world financial dataset, underscoring its leading trading performance in stocks and funds. We then fine-tuned the agent's perceptual spans to achieve a significant trading performance. Collectively, FinMem presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.



finmem-docker
├── LICENSE
├── README.md
├── config -> Configurations for the program
├── data -> Data
├── puppy -> Source code
├── run.py -> Entry point of the program, see below for details
├── run_examples.sh -> Bash cmd for build the docker image and run the docker containerThe model can be run with LLMs on HuggingFace that can be deployed via TGI and has sufficient instruction following ability. As we will always use the text-embedding-ada-002 as our embedding model, the OPENAI_API_KEY variable needs to be set in .env no matter what backbone LLM is used.
If the LLM is gated, the HF_TOKEN needs to be set in .env
OPENAI_API_KEY = "<Your OpenAI Key>"
HF_TOKEN = "<Your HF token>"and set the config/config.toml
[chat]
model = "tgi"
end_point = "<set the your endpoint address>"
tokenization_model_name = "<model name>"
...To run the OpenAI model, the configuration file should be set as
model = "gpt-4"
end_point = "https://api.openai.com/v1/chat/completions"
tokenization_model_name = "gpt-4"and with comment out HF_TOKEN in .env
OPENAI_API_KEY = "<Your OpenAI Key>"
# HF_TOKEN = ""The dockerfile is based on Python 3.10 at
.devcontainer/DockerfileTo build the docker image, run
docker build -t test-finmem finmem/.devcontainer/. To start the container, run
docker run -it --rm -v $(pwd):/finmem test-finmem bashThis will enter the root folder of the project.
The program has two main functionalities:
Usage: run.py sim [OPTIONS]
Start Simulation
╭─ Options ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ --market-data-path -mdp TEXT The environment data pickle path [default: data/06_input/subset_symbols.pkl] │
│ --start-time -st TEXT The training or test start time [default: 2022-06-30 For Ticker 'TSLA'] │
│ --end-time -et TEXT The training or test end time [default: 2022-10-11] │
│ --run-model -rm TEXT Run mode: train or test [default: train] │
│ --config-path -cp TEXT config file path [default: config/config.toml] │
│ --checkpoint-path -ckp TEXT The checkpoint save path [default: data/10_checkpoint_test] │
│ --result-path -rp TEXT The result save path [default: data/11_train_result] │
│ --trained-agent-path -tap TEXT Only used in test mode, the path of trained agent [default: None. Can be changed to data/05_train_model_output OR data/06_train_checkpoint] │
│ --help Show this message and exit. │
╰──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
Notice our model has two modes: train and test. In the train mode, the information populate the agent's memory. In the test mode, the agent will use the information in the memory and new information to make decisions. When test mode is selected, the trained agent must be provided.
When the program stopped due to exceptions(OpenAI API is not stable, etc.), the training/testing process can be resumed with
Usage: run.py sim-checkpoint [OPTIONS]
Start Simulation from checkpoint
╭─ Options ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ --checkpoint-path -cp TEXT The checkpoint path [default: data/06_train_checkpoint] │
│ --result-path -rp TEXT The result save path [default: data/05_train_model_output] │
│ --config-path -ckp TEXT config file path [default: config/tsla_config.toml] │
│ --run-model -rm TEXT Run mode: train or test [default: train] │
│ --help Show this message and exit. │
╰──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for FinMem-LLM-StockTrading
Similar Open Source Tools
FinMem-LLM-StockTrading
This repository contains the Python source code for FINMEM, a Performance-Enhanced Large Language Model Trading Agent with Layered Memory and Character Design. It introduces FinMem, a novel LLM-based agent framework devised for financial decision-making, encompassing three core modules: Profiling, Memory with layered processing, and Decision-making. FinMem's memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. The framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. It presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.
gpt-all-star
GPT-All-Star is an AI-powered code generation tool designed for scratch development of web applications with team collaboration of autonomous AI agents. The primary focus of this research project is to explore the potential of autonomous AI agents in software development. Users can organize their team, choose leaders for each step, create action plans, and work together to complete tasks. The tool supports various endpoints like OpenAI, Azure, and Anthropic, and provides functionalities for project management, code generation, and team collaboration.
shell_gpt
ShellGPT is a command-line productivity tool powered by AI large language models (LLMs). This command-line tool offers streamlined generation of shell commands, code snippets, documentation, eliminating the need for external resources (like Google search). Supports Linux, macOS, Windows and compatible with all major Shells like PowerShell, CMD, Bash, Zsh, etc.
otter-camp
Otter Camp is an open source work management tool designed for AI agent teams. It provides a centralized platform for managing AI agents, ensuring that important context is not lost, enabling quick hiring and firing of agents, maintaining a single pipeline for all work types, keeping context organized within projects, facilitating work review processes, tracking team activities, and offering self-hosted data security. The tool integrates with OpenClaw to run agents and provides a user-friendly interface for managing agent teams efficiently.
kweaver
KWeaver is an open-source ecosystem for building, deploying, and running decision intelligence AI applications. It adopts ontology as the core methodology for business knowledge networks, with DIP as the core platform, aiming to provide elastic, agile, and reliable enterprise-grade decision intelligence to further unleash productivity. The DIP platform includes key subsystems such as ADP, Decision Agent, DIP Studio, and AI Store.
blendsql
BlendSQL is a superset of SQLite designed for problem decomposition and hybrid question-answering with Large Language Models (LLMs). It allows users to blend operations over heterogeneous data sources like tables, text, and images, combining the structured and interpretable reasoning of SQL with the generalizable reasoning of LLMs. Users can oversee all calls (LLM + SQL) within a unified query language, enabling tasks such as building LLM chatbots for travel planning and answering complex questions by injecting 'ingredients' as callable functions.
Shannon
Shannon is a battle-tested infrastructure for AI agents that solves problems at scale, such as runaway costs, non-deterministic failures, and security concerns. It offers features like intelligent caching, deterministic replay of workflows, time-travel debugging, WASI sandboxing, and hot-swapping between LLM providers. Shannon allows users to ship faster with zero configuration multi-agent setup, multiple AI patterns, time-travel debugging, and hot configuration changes. It is production-ready with features like WASI sandbox, token budget control, policy engine (OPA), and multi-tenancy. Shannon helps scale without breaking by reducing costs, being provider agnostic, observable by default, and designed for horizontal scaling with Temporal workflow orchestration.
giztoy
Giztoy is a multi-language framework designed for building AI toys and intelligent applications. It provides a unified abstraction layer that spans from resource-constrained embedded systems to powerful cloud services. With features like native support for ESP32 and other MCUs, cross-platform app development, a unified build system with Bazel, an agent framework for AI agents, audio processing capabilities, support for various Large Language Models, real-time models with WebSocket streaming, secure transport protocols, and multi-language implementations in Go, Rust, Zig, and C/C++, Giztoy serves as a versatile tool for developing AI-powered applications across different platforms and devices.
osmedeus
Osmedeus is a security-focused declarative orchestration engine that simplifies complex workflow automation into auditable YAML definitions. It provides powerful automation capabilities without compromising infrastructure integrity and safety. With features like declarative YAML workflows, multiple runners, event-driven triggers, template engine, utility functions, REST API server, distributed execution, notifications, cloud storage, AI integration, SAST integration, language detection, and preset installations, Osmedeus offers a comprehensive solution for security automation tasks.
memsearch
Memsearch is a tool that allows users to give their AI agents persistent memory in a few lines of code. It enables users to write memories as markdown and search them semantically. Inspired by OpenClaw's markdown-first memory architecture, Memsearch is pluggable into any agent framework. The tool offers features like smart deduplication, live sync, and a ready-made Claude Code plugin for building agent memory.
aiohomematic
AIO Homematic (hahomematic) is a lightweight Python 3 library for controlling and monitoring HomeMatic and HomematicIP devices, with support for third-party devices/gateways. It automatically creates entities for device parameters, offers custom entity classes for complex behavior, and includes features like caching paramsets for faster restarts. Designed to integrate with Home Assistant, it requires specific firmware versions for HomematicIP devices. The public API is defined in modules like central, client, model, exceptions, and const, with example usage provided. Useful links include changelog, data point definitions, troubleshooting, and developer resources for architecture, data flow, model extension, and Home Assistant lifecycle.
pilot
Pilot is an AI tool designed to streamline the process of handling tickets from GitHub, Linear, Jira, or Asana. It plans the implementation, writes the code, runs tests, and opens a PR for you to review and merge. With features like Autopilot, Epic Decomposition, Self-Review, and more, Pilot aims to automate the ticket handling process and reduce the time spent on prioritizing and completing tasks. It integrates with various platforms, offers intelligence features, and provides real-time visibility through a dashboard. Pilot is free to use, with costs associated with Claude API usage. It is designed for bug fixes, small features, refactoring, tests, docs, and dependency updates, but may not be suitable for large architectural changes or security-critical code.
observers
Observers is a lightweight library for AI observability that provides support for various generative AI APIs and storage backends. It allows users to track interactions with AI models and sync observations to different storage systems. The library supports OpenAI, Hugging Face transformers, AISuite, Litellm, and Docling for document parsing and export. Users can configure different stores such as Hugging Face Datasets, DuckDB, Argilla, and OpenTelemetry to manage and query their observations. Observers is designed to enhance AI model monitoring and observability in a user-friendly manner.
Agentic-ADK
Agentic ADK is an Agent application development framework launched by Alibaba International AI Business, based on Google-ADK and Ali-LangEngine. It is used for developing, constructing, evaluating, and deploying powerful, flexible, and controllable complex AI Agents. ADK aims to make Agent development simpler and more user-friendly, enabling developers to more easily build, deploy, and orchestrate various Agent applications ranging from simple tasks to complex collaborations.
claudex
Claudex is an open-source, self-hosted Claude Code UI that runs entirely on your machine. It provides multiple sandboxes, allows users to use their own plans, offers a full IDE experience with VS Code in the browser, and is extensible with skills, agents, slash commands, and MCP servers. Users can run AI agents in isolated environments, view and interact with a browser via VNC, switch between multiple AI providers, automate tasks with Celery workers, and enjoy various chat features and preview capabilities. Claudex also supports marketplace plugins, secrets management, integrations like Gmail, and custom instructions. The tool is configured through providers and supports various providers like Anthropic, OpenAI, OpenRouter, and Custom. It has a tech stack consisting of React, FastAPI, Python, PostgreSQL, Celery, Redis, and more.
starknet-agentic
Open-source stack for giving AI agents wallets, identity, reputation, and execution rails on Starknet. `starknet-agentic` is a monorepo with Cairo smart contracts for agent wallets, identity, reputation, and validation, TypeScript packages for MCP tools, A2A integration, and payment signing, reusable skills for common Starknet agent capabilities, and examples and docs for integration. It provides contract primitives + runtime tooling in one place for integrating agents. The repo includes various layers such as Agent Frameworks / Apps, Integration + Runtime Layer, Packages / Tooling Layer, Cairo Contract Layer, and Starknet L2. It aims for portability of agent integrations without giving up Starknet strengths, with a cross-chain interop strategy and skills marketplace. The repository layout consists of directories for contracts, packages, skills, examples, docs, and website.
For similar tasks
FinMem-LLM-StockTrading
This repository contains the Python source code for FINMEM, a Performance-Enhanced Large Language Model Trading Agent with Layered Memory and Character Design. It introduces FinMem, a novel LLM-based agent framework devised for financial decision-making, encompassing three core modules: Profiling, Memory with layered processing, and Decision-making. FinMem's memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. The framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. It presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.

RainbowGPT
RainbowGPT is a versatile tool that offers a range of functionalities, including Stock Analysis for financial decision-making, MySQL Management for database navigation, and integration of AI technologies like GPT-4 and ChatGlm3. It provides a user-friendly interface suitable for all skill levels, ensuring seamless information flow and continuous expansion of emerging technologies. The tool enhances adaptability, creativity, and insight, making it a valuable asset for various projects and tasks.
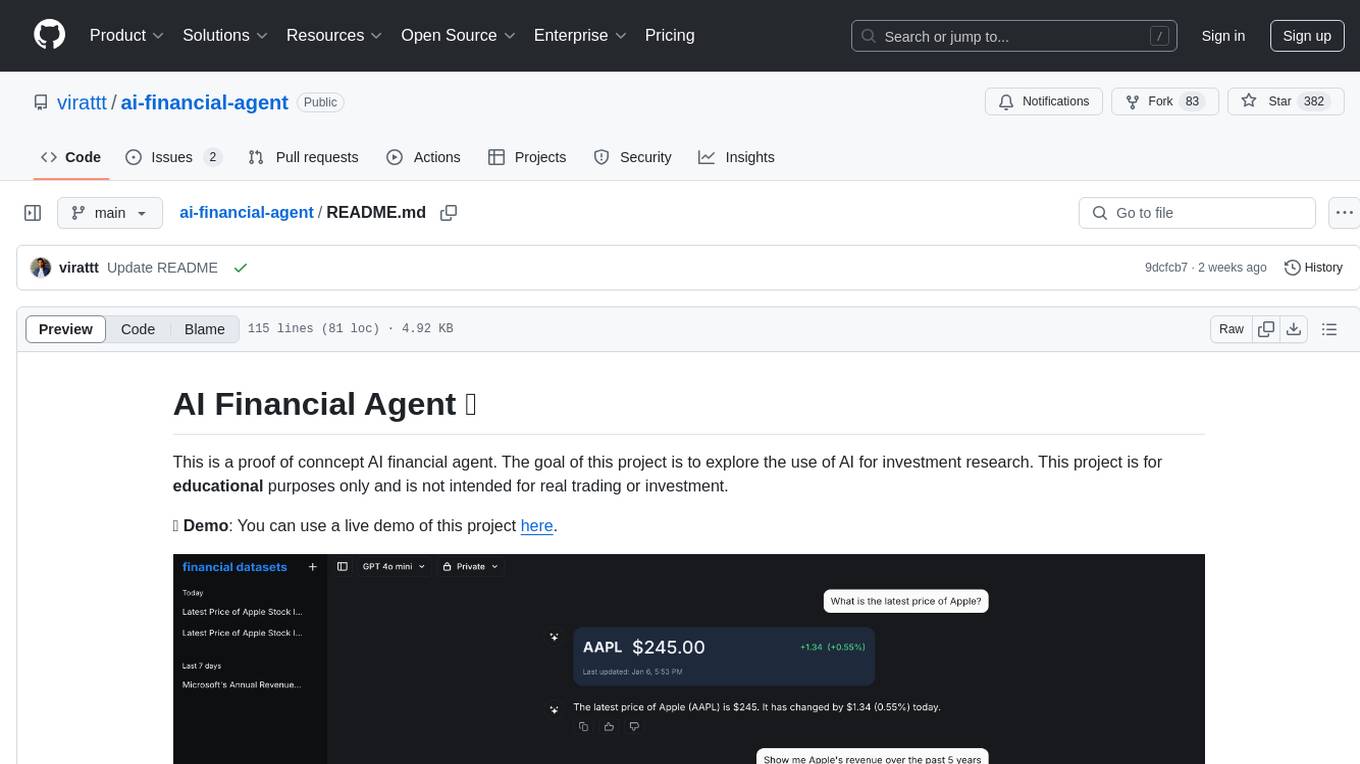
ai-financial-agent
AI Financial Agent is a proof of concept project exploring the use of AI for investment research. It provides an AI SDK with a unified API for generating text and structured objects, along with access to real-time and historical stock market data optimized for AI financial agents. The project includes features like dynamic chat interfaces, support for multiple model providers, and styling with Tailwind CSS. Users can deploy their own version of the AI Financial Agent using Vercel and GitHub integration.
stock-trading
StockTrading AI is a small model stock automatic trading system that integrates with securities platforms, implements automated stock trading, utilizes QuartZ for scheduled tasks to update data daily, employs DL4J framework for LSTM model guidance on stock buying with T+1 short-term trading strategy, utilizes K8S+GithubAction for DevOps, and supports distributed offline training. Future optimizations include obtaining more historical stock data for incremental model training and tuning model hyperparameters to improve price trend prediction accuracy. The system provides various page displays for profit data statistics, trade order queries, stock price viewing, model prediction performance, scheduled task scheduling, and real-time log tracking.
FinanceMCP
FinanceMCP is a professional financial data server based on the MCP protocol, integrating the Tushare API to provide real-time financial data and technical indicator analysis for AI assistants like Claude. It offers various free public cloud services, including a web-based experience version and desktop configuration for production environments. The core features include an intelligent technical indicator system with 5 core indicators, comprehensive market coverage across 10 markets, tools for stock, index, company, macroeconomic, and fund data analysis, as well as specific modules for analyzing US and Hong Kong stock companies. The tool supports tasks like stock technical analysis, comprehensive analysis, news and macroeconomic analysis, fund and bond data queries, among others. It can be locally deployed using Streamable HTTP or SSE modes, with detailed installation and configuration instructions provided.
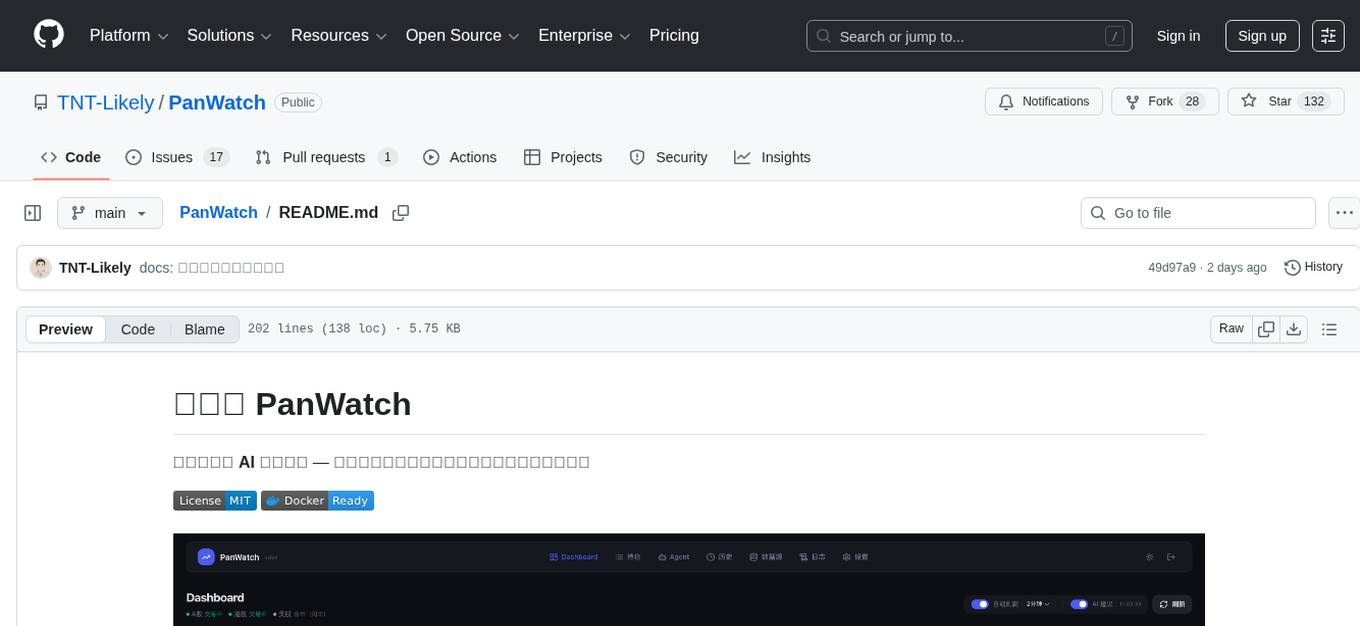
PanWatch
PanWatch is a private AI stock assistant for real-time market monitoring, intelligent technical analysis, and multi-account portfolio management. It offers data privacy through self-hosted deployment, AI-native features that understand user's holdings, style, and goals, and easy setup with Docker. The core functions include intelligent agent system for pre-market analysis, real-time intraday monitoring, end-of-day reports, and news updates. It also provides professional technical analysis with trend indicators, momentum indicators, volume-price analysis, pattern recognition, and support/resistance calculations. PanWatch supports multiple markets and accounts, covering A shares, Hong Kong stocks, and US stocks, with customizable trading styles for accurate AI suggestions. Notifications are available through various channels like Telegram, WeChat Work, DingTalk, Feishu, Bark, and custom webhooks.

qlib
Qlib is an open-source, AI-oriented quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It covers the entire chain of quantitative investment, from alpha seeking to order execution. The platform empowers researchers to explore ideas and implement productions using AI technologies in quantitative investment. Qlib collaboratively solves key challenges in quantitative investment by releasing state-of-the-art research works in various paradigms. It provides a full ML pipeline for data processing, model training, and back-testing, enabling users to perform tasks such as forecasting market patterns, adapting to market dynamics, and modeling continuous investment decisions.
solana-trading-bot
Solana AI Trade Bot is an advanced trading tool specifically designed for meme token trading on the Solana blockchain. It leverages AI technology powered by GPT-4.0 to automate trades, identify low-risk/high-potential tokens, and assist in token creation and management. The bot offers cross-platform compatibility and a range of configurable settings for buying, selling, and filtering tokens. Users can benefit from real-time AI support and enhance their trading experience with features like automatic selling, slippage management, and profit/loss calculations. To optimize performance, it is recommended to connect the bot to a private light node for efficient trading execution.
For similar jobs
qlib
Qlib is an open-source, AI-oriented quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It covers the entire chain of quantitative investment, from alpha seeking to order execution. The platform empowers researchers to explore ideas and implement productions using AI technologies in quantitative investment. Qlib collaboratively solves key challenges in quantitative investment by releasing state-of-the-art research works in various paradigms. It provides a full ML pipeline for data processing, model training, and back-testing, enabling users to perform tasks such as forecasting market patterns, adapting to market dynamics, and modeling continuous investment decisions.
jupyter-quant
Jupyter Quant is a dockerized environment tailored for quantitative research, equipped with essential tools like statsmodels, pymc, arch, py_vollib, zipline-reloaded, PyPortfolioOpt, numpy, pandas, sci-py, scikit-learn, yellowbricks, shap, optuna, ib_insync, Cython, Numba, bottleneck, numexpr, jedi language server, jupyterlab-lsp, black, isort, and more. It does not include conda/mamba and relies on pip for package installation. The image is optimized for size, includes common command line utilities, supports apt cache, and allows for the installation of additional packages. It is designed for ephemeral containers, ensuring data persistence, and offers volumes for data, configuration, and notebooks. Common tasks include setting up the server, managing configurations, setting passwords, listing installed packages, passing parameters to jupyter-lab, running commands in the container, building wheels outside the container, installing dotfiles and SSH keys, and creating SSH tunnels.
FinRobot
FinRobot is an open-source AI agent platform designed for financial applications using large language models. It transcends the scope of FinGPT, offering a comprehensive solution that integrates a diverse array of AI technologies. The platform's versatility and adaptability cater to the multifaceted needs of the financial industry. FinRobot's ecosystem is organized into four layers, including Financial AI Agents Layer, Financial LLMs Algorithms Layer, LLMOps and DataOps Layers, and Multi-source LLM Foundation Models Layer. The platform's agent workflow involves Perception, Brain, and Action modules to capture, process, and execute financial data and insights. The Smart Scheduler optimizes model diversity and selection for tasks, managed by components like Director Agent, Agent Registration, Agent Adaptor, and Task Manager. The tool provides a structured file organization with subfolders for agents, data sources, and functional modules, along with installation instructions and hands-on tutorials.
hands-on-lab-neo4j-and-vertex-ai
This repository provides a hands-on lab for learning about Neo4j and Google Cloud Vertex AI. It is intended for data scientists and data engineers to deploy Neo4j and Vertex AI in a Google Cloud account, work with real-world datasets, apply generative AI, build a chatbot over a knowledge graph, and use vector search and index functionality for semantic search. The lab focuses on analyzing quarterly filings of asset managers with $100m+ assets under management, exploring relationships using Neo4j Browser and Cypher query language, and discussing potential applications in capital markets such as algorithmic trading and securities master data management.
jupyter-quant
Jupyter Quant is a dockerized environment tailored for quantitative research, equipped with essential tools like statsmodels, pymc, arch, py_vollib, zipline-reloaded, PyPortfolioOpt, numpy, pandas, sci-py, scikit-learn, yellowbricks, shap, optuna, and more. It provides Interactive Broker connectivity via ib_async and includes major Python packages for statistical and time series analysis. The image is optimized for size, includes jedi language server, jupyterlab-lsp, and common command line utilities. Users can install new packages with sudo, leverage apt cache, and bring their own dot files and SSH keys. The tool is designed for ephemeral containers, ensuring data persistence and flexibility for quantitative analysis tasks.
Qbot
Qbot is an AI-oriented automated quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It provides a full closed-loop process from data acquisition, strategy development, backtesting, simulation trading to live trading. The platform emphasizes AI strategies such as machine learning, reinforcement learning, and deep learning, combined with multi-factor models to enhance returns. Users with some Python knowledge and trading experience can easily utilize the platform to address trading pain points and gaps in the market.
FinMem-LLM-StockTrading
This repository contains the Python source code for FINMEM, a Performance-Enhanced Large Language Model Trading Agent with Layered Memory and Character Design. It introduces FinMem, a novel LLM-based agent framework devised for financial decision-making, encompassing three core modules: Profiling, Memory with layered processing, and Decision-making. FinMem's memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. The framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. It presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.
LLMs-in-Finance
This repository focuses on the application of Large Language Models (LLMs) in the field of finance. It provides insights and knowledge about how LLMs can be utilized in various scenarios within the finance industry, particularly in generating AI agents. The repository aims to explore the potential of LLMs to enhance financial processes and decision-making through the use of advanced natural language processing techniques.