
CALF
An official implementation of "CALF: Aligning LLMs for Time Series Forecasting via Cross-modal Fine-Tuning"
Stars: 60
CALF (LLaTA) is a cross-modal fine-tuning framework that bridges the distribution discrepancy between temporal data and the textual nature of LLMs. It introduces three cross-modal fine-tuning techniques: Cross-Modal Match Module, Feature Regularization Loss, and Output Consistency Loss. The framework aligns time series and textual inputs, ensures effective weight updates, and maintains consistent semantic context for time series data. CALF provides scripts for long-term and short-term forecasting, requires Python 3.9, and utilizes word token embeddings for model training.
README:
![]()
CALF (Orignal name: LLaTA) is a novel cross-modal fine-tuing framework that effectively bridges the distribution discrepancy between temporal data and the textual nature of LLMs, as shown in Figure 1.

Figure 1: The t-SNE visualization of pre-trained word token embeddings of LLM with temporal tokens from GPT4TS (Left) and our method (Right). Our method shows more cohesive integration, indicating effective modality alignment.
To bridge the modality gap between textual and temporal data, we introduce three meticulously designed cross-modal fine-tuning techniques (see Figure 2):
- Cross-Modal Match Module integrates time series and textual inputs through principal word embedding extraction and a cross-attention mechanism, ensuring efficient alignment of the marginal input distribution between time series and text.
- Feature Regularization Loss aligns the outputs of each intermediate layer, ensuring that gradients at every layer are more effectively guided for better weight updates.
- Output Consistency Loss ensures that the output representations of textual and temporal series modalities correspond effectively, resolving discrepancies in the representation space and maintaining consistent semantic context for time series data.

Figure 2: Conceptual illustration of cross-modal fine-tuning technique.
Before proceeding, ensure Python 3.9 is installed. Install the required dependencies with the following command:
pip install -r requirements.txt
Acquire datasets from Autoformer. Organize them in the ./datasets directory as shown below:
datasets
├── electricity
│ └── electricity.csv
├── ETT-small
│ ├── ETTh1.csv
│ ├── ETTh2.csv
│ ├── ETTm1.csv
│ └── ETTm2.csv
├── traffic
│ └── traffic.csv
└── weather
└── weather.csv
For short-term forecasting, download the M4 datasets from Time-Series-Library. Place the m4 folder within ./datasets.
Execute the command below to extract principal components from the word token embeddings:
python pca.py
These embeddings will be saved in ./wte_pca_500.pt.
Training scripts are located in the ./scripts folder. For instance, to train the CALF model on the ETTh2 dataset for long-term forecasting, execute:
sh scripts/long_term_forecasting/ETTh2.sh
For short-term forecasting, use:
sh scripts/short_term_forecasting/m4.sh
Post-Training:
- Trained models will be saved in
./checkpoints. - Numerical results are available in
.npyformat under./results. - Detailed summaries of performance metrics can be found in
./results_{task_name}.txt.
If this repository contributes to your research, please consider citing our work:
@article{liu2024taming,
title={CALF: Aligning LLMs for Time Series Forecasting via Cross-modal Fine-Tuning},
author={Liu, Peiyuan and Guo, Hang and Dai, Tao and Li, Naiqi and Bao, Jigang and Ren, Xudong and Jiang, Yong and Xia, Shu-Tao},
journal={arXiv preprint arXiv:2403.07300},
year={2024},
arxiv={2403.07300}
}
Our gratitude extends to the authors of the following repositories for their foundational model implementations:
For inquiries or further assistance, contact us at [email protected] or open an issue on this repository.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for CALF
Similar Open Source Tools
CALF
CALF (LLaTA) is a cross-modal fine-tuning framework that bridges the distribution discrepancy between temporal data and the textual nature of LLMs. It introduces three cross-modal fine-tuning techniques: Cross-Modal Match Module, Feature Regularization Loss, and Output Consistency Loss. The framework aligns time series and textual inputs, ensures effective weight updates, and maintains consistent semantic context for time series data. CALF provides scripts for long-term and short-term forecasting, requires Python 3.9, and utilizes word token embeddings for model training.

aimo-progress-prize
This repository contains the training and inference code needed to replicate the winning solution to the AI Mathematical Olympiad - Progress Prize 1. It consists of fine-tuning DeepSeekMath-Base 7B, high-quality training datasets, a self-consistency decoding algorithm, and carefully chosen validation sets. The training methodology involves Chain of Thought (CoT) and Tool Integrated Reasoning (TIR) training stages. Two datasets, NuminaMath-CoT and NuminaMath-TIR, were used to fine-tune the models. The models were trained using open-source libraries like TRL, PyTorch, vLLM, and DeepSpeed. Post-training quantization to 8-bit precision was done to improve performance on Kaggle's T4 GPUs. The project structure includes scripts for training, quantization, and inference, along with necessary installation instructions and hardware/software specifications.

CoLLM
CoLLM is a novel method that integrates collaborative information into Large Language Models (LLMs) for recommendation. It converts recommendation data into language prompts, encodes them with both textual and collaborative information, and uses a two-step tuning method to train the model. The method incorporates user/item ID fields in prompts and employs a conventional collaborative model to generate user/item representations. CoLLM is built upon MiniGPT-4 and utilizes pretrained Vicuna weights for training.

gepa
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.

fuse-med-ml
FuseMedML is a Python framework designed to accelerate machine learning-based discovery in the medical field by promoting code reuse. It provides a flexible design concept where data is stored in a nested dictionary, allowing easy handling of multi-modality information. The framework includes components for creating custom models, loss functions, metrics, and data processing operators. Additionally, FuseMedML offers 'batteries included' key components such as fuse.data for data processing, fuse.eval for model evaluation, and fuse.dl for reusable deep learning components. It supports PyTorch and PyTorch Lightning libraries and encourages the creation of domain extensions for specific medical domains.
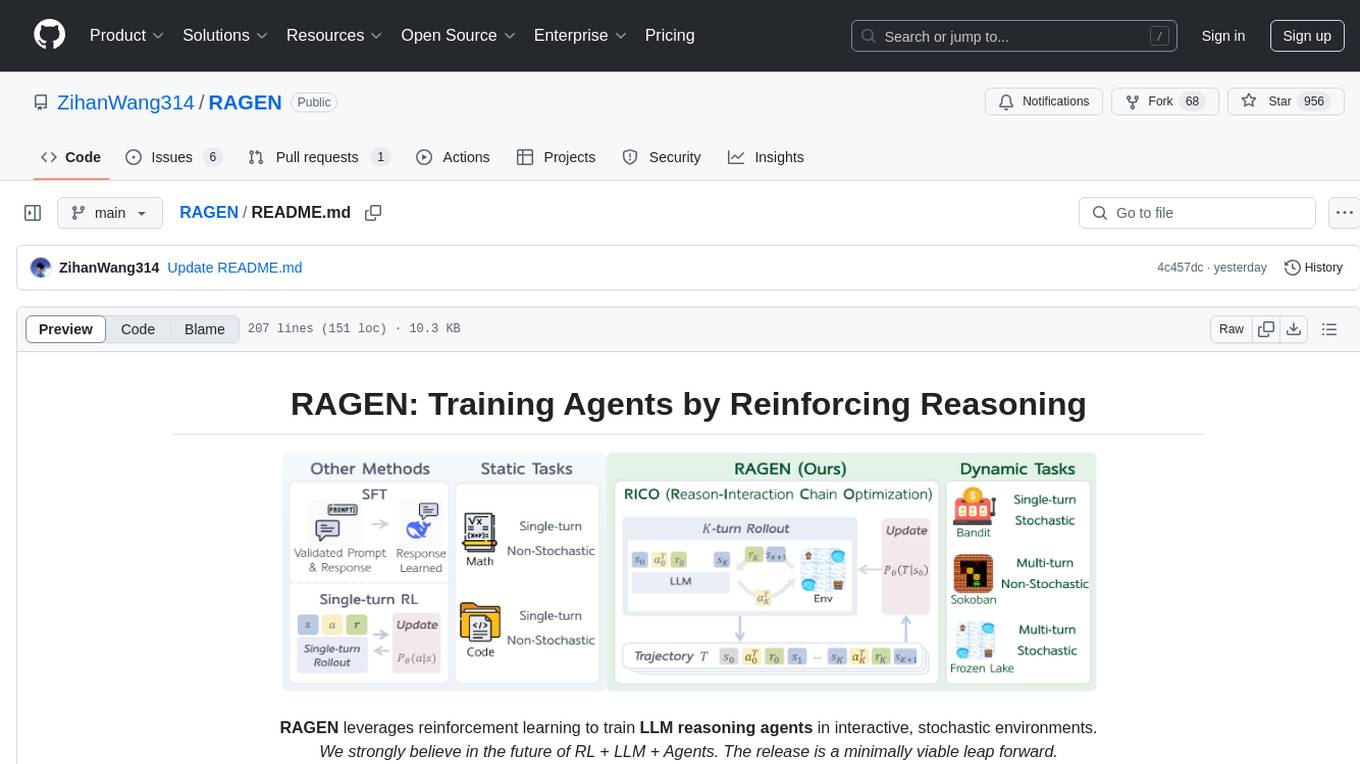
RAGEN
RAGEN is a reinforcement learning framework designed to train reasoning-capable large language model (LLM) agents in interactive, stochastic environments. It addresses challenges such as multi-turn interactions and stochastic environments through a Markov Decision Process (MDP) formulation, Reason-Interaction Chain Optimization (RICO) algorithm, and progressive reward normalization strategies. The framework enables LLMs to reason and interact with the environment, optimizing entire trajectories for long-horizon reasoning while maintaining computational efficiency.

LLMeBench
LLMeBench is a flexible framework designed for accelerating benchmarking of Large Language Models (LLMs) in the field of Natural Language Processing (NLP). It supports evaluation of various NLP tasks using model providers like OpenAI, HuggingFace Inference API, and Petals. The framework is customizable for different NLP tasks, LLM models, and datasets across multiple languages. It features extensive caching capabilities, supports zero- and few-shot learning paradigms, and allows on-the-fly dataset download and caching. LLMeBench is open-source and continuously expanding to support new models accessible through APIs.

merlin
Merlin is a groundbreaking model capable of generating natural language responses intricately linked with object trajectories of multiple images. It excels in predicting and reasoning about future events based on initial observations, showcasing unprecedented capability in future prediction and reasoning. Merlin achieves state-of-the-art performance on the Future Reasoning Benchmark and multiple existing multimodal language models benchmarks, demonstrating powerful multi-modal general ability and foresight minds.
InfLLM
InfLLM is a training-free memory-based method that unveils the intrinsic ability of LLMs to process streaming long sequences. It stores distant contexts into additional memory units and employs an efficient mechanism to lookup token-relevant units for attention computation. Thereby, InfLLM allows LLMs to efficiently process long sequences while maintaining the ability to capture long-distance dependencies. Without any training, InfLLM enables LLMs pre-trained on sequences of a few thousand tokens to achieve superior performance than competitive baselines continually training these LLMs on long sequences. Even when the sequence length is scaled to 1, 024K, InfLLM still effectively captures long-distance dependencies.
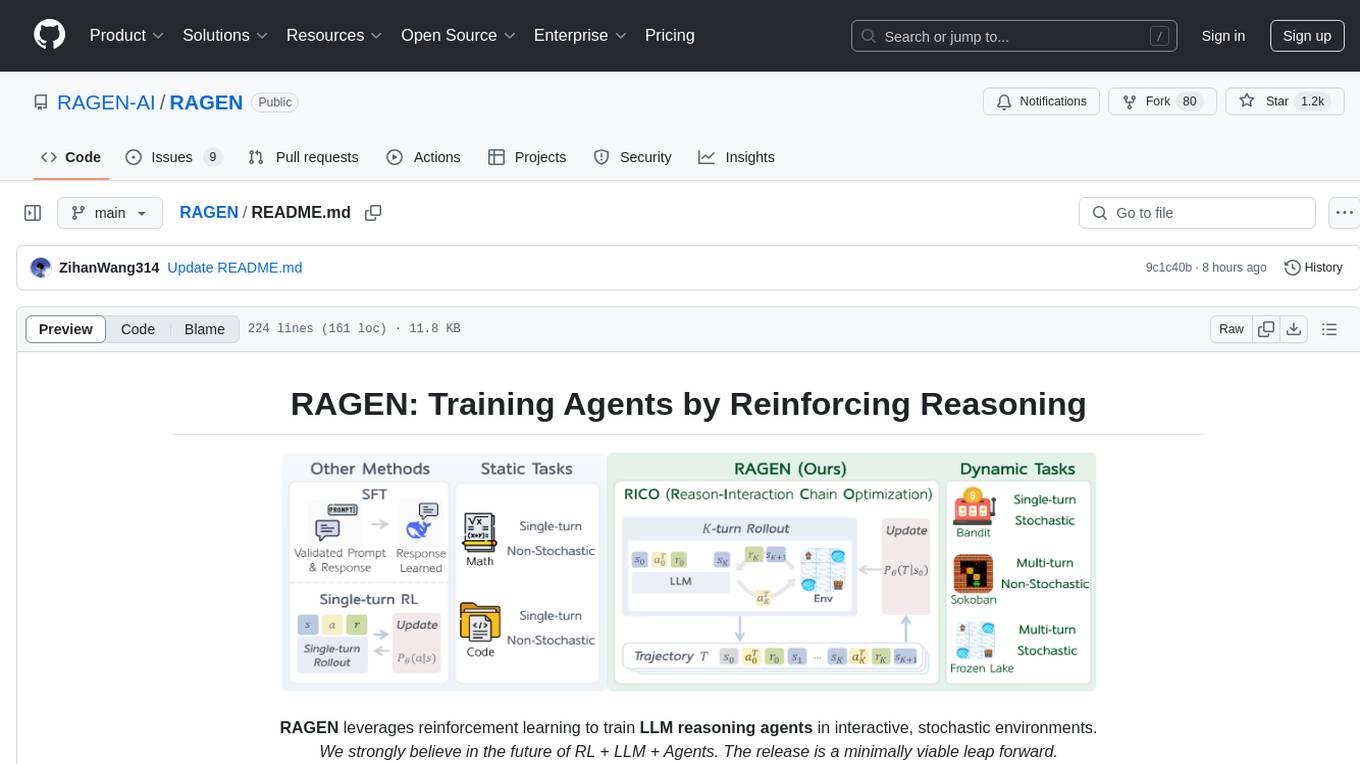
RAGEN
RAGEN is a reinforcement learning framework designed to train reasoning-capable large language model (LLM) agents in interactive, stochastic environments. It addresses challenges such as multi-turn interactions and stochastic environments through a Markov Decision Process (MDP) formulation, Reason-Interaction Chain Optimization (RICO) algorithm, and progressive reward normalization strategies. The framework consists of MDP formulation, RICO algorithm with rollout and update stages, and reward normalization strategies to stabilize training. RAGEN aims to optimize reasoning and action strategies for LLM agents operating in complex environments.

BambooAI
BambooAI is a lightweight library utilizing Large Language Models (LLMs) to provide natural language interaction capabilities, much like a research and data analysis assistant enabling conversation with your data. You can either provide your own data sets, or allow the library to locate and fetch data for you. It supports Internet searches and external API interactions.

AgentCPM
AgentCPM is a series of open-source LLM agents jointly developed by THUNLP, Renmin University of China, ModelBest, and the OpenBMB community. It addresses challenges faced by agents in real-world applications such as limited long-horizon capability, autonomy, and generalization. The team focuses on building deep research capabilities for agents, releasing AgentCPM-Explore, a deep-search LLM agent, and AgentCPM-Report, a deep-research LLM agent. AgentCPM-Explore is the first open-source agent model with 4B parameters to appear on widely used long-horizon agent benchmarks. AgentCPM-Report is built on the 8B-parameter base model MiniCPM4.1, autonomously generating long-form reports with extreme performance and minimal footprint, designed for high-privacy scenarios with offline and agile local deployment.

only_train_once
Only Train Once (OTO) is an automatic, architecture-agnostic DNN training and compression framework that allows users to train a general DNN from scratch or a pretrained checkpoint to achieve high performance and slimmer architecture simultaneously in a one-shot manner without fine-tuning. The framework includes features for automatic structured pruning and erasing operators, as well as hybrid structured sparse optimizers for efficient model compression. OTO provides tools for pruning zero-invariant group partitioning, constructing pruned models, and visualizing pruning and erasing dependency graphs. It supports the HESSO optimizer and offers a sanity check for compliance testing on various DNNs. The repository also includes publications, installation instructions, quick start guides, and a roadmap for future enhancements and collaborations.

RAG-FiT
RAG-FiT is a library designed to improve Language Models' ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library assists in creating training data, training models using parameter-efficient finetuning (PEFT), and evaluating performance using RAG-specific metrics. It is modular, customizable via configuration files, and facilitates fast prototyping and experimentation with various RAG settings and configurations.
AgentGym-RL
AgentGym-RL is a framework designed to train Long-Long Memory (LLM) agents for multi-turn interactive decision-making through Reinforcement Learning. It addresses challenges in training agents for real-world scenarios by supporting mainstream RL algorithms and introducing the ScalingInter-RL method for stable optimization. The framework includes modular components for environment, agent reasoning, and training pipelines. It offers diverse environments like Web Navigation, Deep Search, Digital Games, Embodied Tasks, and Scientific Tasks. AgentGym-RL also supports various online RL algorithms and post-training strategies. The tool aims to enhance agent performance and exploration capabilities through long-horizon planning and interaction with the environment.

crewAI
CrewAI is a cutting-edge framework designed to orchestrate role-playing autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks. It enables AI agents to assume roles, share goals, and operate in a cohesive unit, much like a well-oiled crew. Whether you're building a smart assistant platform, an automated customer service ensemble, or a multi-agent research team, CrewAI provides the backbone for sophisticated multi-agent interactions. With features like role-based agent design, autonomous inter-agent delegation, flexible task management, and support for various LLMs, CrewAI offers a dynamic and adaptable solution for both development and production workflows.
For similar tasks

Co-LLM-Agents
This repository contains code for building cooperative embodied agents modularly with large language models. The agents are trained to perform tasks in two different environments: ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH). TDW-MAT is a multi-agent environment where agents must transport objects to a goal position using containers. C-WAH is an extension of the Watch-And-Help challenge, which enables agents to send messages to each other. The code in this repository can be used to train agents to perform tasks in both of these environments.

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.

kan-gpt
The KAN-GPT repository is a PyTorch implementation of Generative Pre-trained Transformers (GPTs) using Kolmogorov-Arnold Networks (KANs) for language modeling. It provides a model for generating text based on prompts, with a focus on improving performance compared to traditional MLP-GPT models. The repository includes scripts for training the model, downloading datasets, and evaluating model performance. Development tasks include integrating with other libraries, testing, and documentation.

LLM-SFT
LLM-SFT is a Chinese large model fine-tuning tool that supports models such as ChatGLM, LlaMA, Bloom, Baichuan-7B, and frameworks like LoRA, QLoRA, DeepSpeed, UI, and TensorboardX. It facilitates tasks like fine-tuning, inference, evaluation, and API integration. The tool provides pre-trained weights for various models and datasets for Chinese language processing. It requires specific versions of libraries like transformers and torch for different functionalities.

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.