
FoR
Flow of Reasoning: Training LLMs for Divergent Problem Solving with Minimal Examples
Stars: 74
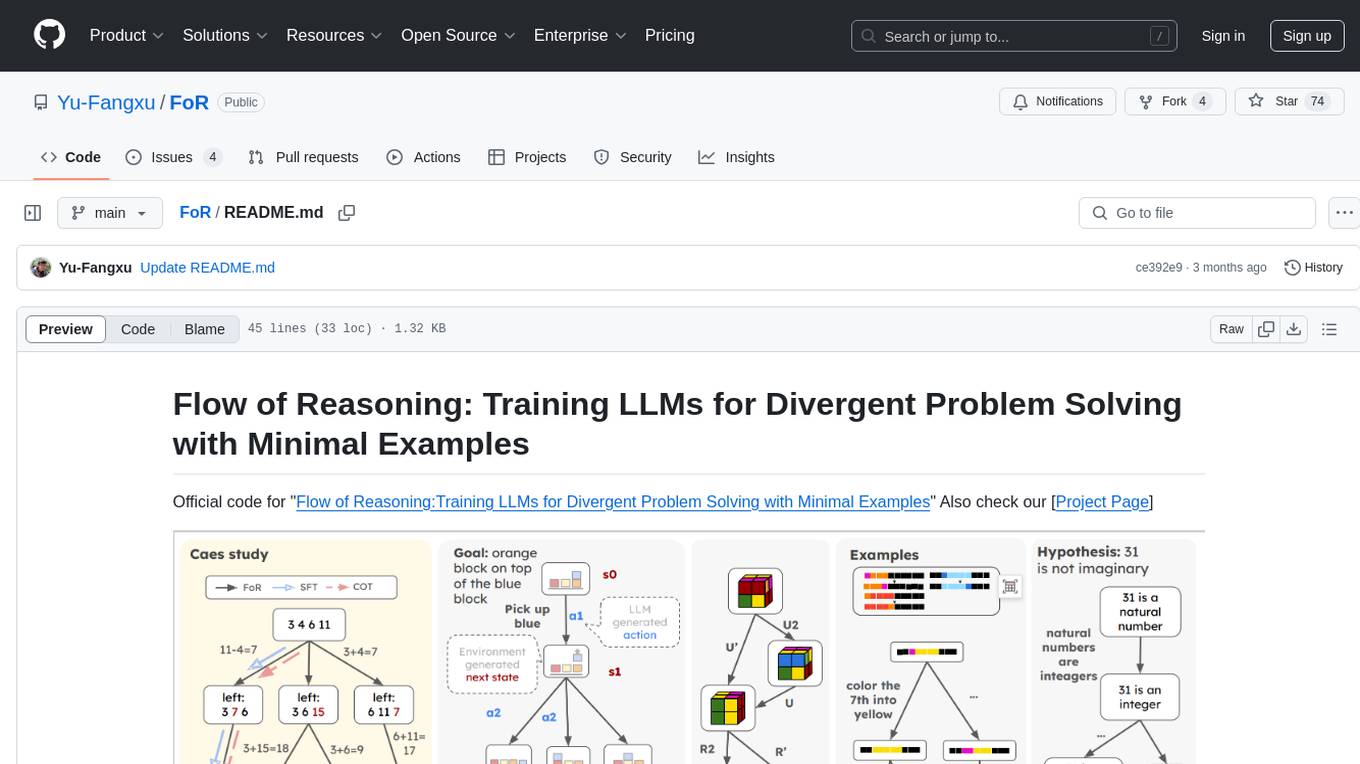
FoR is the official code repository for the 'Flow of Reasoning: Training LLMs for Divergent Problem Solving with Minimal Examples' project. It formulates multi-step reasoning tasks as a flow, involving designing reward functions, collecting trajectories, and training LLM policies with trajectory balance loss. The code provides tools for training and inference in a reproducible experiment environment using conda. Users can choose from 5 tasks to run, each with detailed instructions in the respective branches.
README:
Official code for "Flow of Reasoning:Training LLMs for Divergent Problem Solving with Minimal Examples" Also check our [Project Page]


Our FoR formulates multi-step reasoning tasks as flow:
- Design reward $R(s_n)$ of terminal states for different tasks.
- Collect trajectories with the local search technique.
- Training LLM policy $P_{F}$ with trajectory balance loss.
1) Download this GitHub
git clone https://github.com/Yu-Fangxu/FoR.git
2) Prepare the environment
We recommend conda for setting up a reproducible experiment environment. We include environment.yaml for creating a working environment:
bash install.sh
3) Choose 1 of 5 tasks to run
cd BlocksWorld|Game24|prontoqa|1D-ARC|Rubik's_Cube|GSM8K
Check more detailed instructions in each branch.
@article{yu2024flow,
title={Flow of Reasoning: Efficient Training of LLM Policy with Divergent Thinking},
author={Yu, Fangxu and Jiang, Lai and Kang, Haoqiang and Hao, Shibo and Qin, Lianhui},
journal={arXiv preprint arXiv:2406.05673},
year={2024}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for FoR
Similar Open Source Tools
FoR
FoR is the official code repository for the 'Flow of Reasoning: Training LLMs for Divergent Problem Solving with Minimal Examples' project. It formulates multi-step reasoning tasks as a flow, involving designing reward functions, collecting trajectories, and training LLM policies with trajectory balance loss. The code provides tools for training and inference in a reproducible experiment environment using conda. Users can choose from 5 tasks to run, each with detailed instructions in the respective branches.

ControlFlow
ControlFlow is a Python framework designed for building agentic AI workflows. It provides a structured approach for defining tasks, assigning specialized AI agents, and orchestrating complex behaviors. By balancing AI autonomy with precise oversight, users can create sophisticated AI-powered applications with confidence. ControlFlow offers a task-centric architecture, structured results with type-safe outputs, specialized agents for efficient problem-solving, ecosystem integration with LangChain models, flexible control over workflows, multi-agent orchestration, and native observability and debugging capabilities.

ai-data-analysis-MulitAgent
AI-Driven Research Assistant is an advanced AI-powered system utilizing specialized agents for data analysis, visualization, and report generation. It integrates LangChain, OpenAI's GPT models, and LangGraph for complex research processes. Key features include hypothesis generation, data processing, web search, code generation, and report writing. The system's unique Note Taker agent maintains project state, reducing overhead and improving context retention. System requirements include Python 3.10+ and Jupyter Notebook environment. Installation involves cloning the repository, setting up a Conda virtual environment, installing dependencies, and configuring environment variables. Usage instructions include setting data, running Jupyter Notebook, customizing research tasks, and viewing results. Main components include agents for hypothesis generation, process supervision, visualization, code writing, search, report writing, quality review, and note-taking. Workflow involves hypothesis generation, processing, quality review, and revision. Customization is possible by modifying agent creation and workflow definition. Current issues include OpenAI errors, NoteTaker efficiency, runtime optimization, and refiner improvement. Contributions via pull requests are welcome under the MIT License.

llm-course
The LLM course is divided into three parts: 1. 🧩 **LLM Fundamentals** covers essential knowledge about mathematics, Python, and neural networks. 2. 🧑🔬 **The LLM Scientist** focuses on building the best possible LLMs using the latest techniques. 3. 👷 **The LLM Engineer** focuses on creating LLM-based applications and deploying them. For an interactive version of this course, I created two **LLM assistants** that will answer questions and test your knowledge in a personalized way: * 🤗 **HuggingChat Assistant**: Free version using Mixtral-8x7B. * 🤖 **ChatGPT Assistant**: Requires a premium account. ## 📝 Notebooks A list of notebooks and articles related to large language models. ### Tools | Notebook | Description | Notebook | |----------|-------------|----------| | 🧐 LLM AutoEval | Automatically evaluate your LLMs using RunPod |  | | 🥱 LazyMergekit | Easily merge models using MergeKit in one click. |  | | 🦎 LazyAxolotl | Fine-tune models in the cloud using Axolotl in one click. |  | | ⚡ AutoQuant | Quantize LLMs in GGUF, GPTQ, EXL2, AWQ, and HQQ formats in one click. |  | | 🌳 Model Family Tree | Visualize the family tree of merged models. |  | | 🚀 ZeroSpace | Automatically create a Gradio chat interface using a free ZeroGPU. |  |

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.

SwiftSage
SwiftSage is a tool designed for conducting experiments in the field of machine learning and artificial intelligence. It provides a platform for researchers and developers to implement and test various algorithms and models. The tool is particularly useful for exploring new ideas and conducting experiments in a controlled environment. SwiftSage aims to streamline the process of developing and testing machine learning models, making it easier for users to iterate on their ideas and achieve better results. With its user-friendly interface and powerful features, SwiftSage is a valuable tool for anyone working in the field of AI and ML.

Controllable-RAG-Agent
This repository contains a sophisticated deterministic graph-based solution for answering complex questions using a controllable autonomous agent. The solution is designed to ensure that answers are solely based on the provided data, avoiding hallucinations. It involves various steps such as PDF loading, text preprocessing, summarization, database creation, encoding, and utilizing large language models. The algorithm follows a detailed workflow involving planning, retrieval, answering, replanning, content distillation, and performance evaluation. Heuristics and techniques implemented focus on content encoding, anonymizing questions, task breakdown, content distillation, chain of thought answering, verification, and model performance evaluation.

baal
Baal is an active learning library that supports both industrial applications and research use cases. It provides a framework for Bayesian active learning methods such as Monte-Carlo Dropout, MCDropConnect, Deep ensembles, and Semi-supervised learning. Baal helps in labeling the most uncertain items in the dataset pool to improve model performance and reduce annotation effort. The library is actively maintained by a dedicated team and has been used in various research papers for production and experimentation.

Me-LLaMA
Me LLaMA introduces a suite of open-source medical Large Language Models (LLMs), including Me LLaMA 13B/70B and their chat-enhanced versions. Developed through innovative continual pre-training and instruction tuning, these models leverage a vast medical corpus comprising PubMed papers, medical guidelines, and general domain data. Me LLaMA sets new benchmarks on medical reasoning tasks, making it a significant asset for medical NLP applications and research. The models are intended for computational linguistics and medical research, not for clinical decision-making without validation and regulatory approval.

CoLLM
CoLLM is a novel method that integrates collaborative information into Large Language Models (LLMs) for recommendation. It converts recommendation data into language prompts, encodes them with both textual and collaborative information, and uses a two-step tuning method to train the model. The method incorporates user/item ID fields in prompts and employs a conventional collaborative model to generate user/item representations. CoLLM is built upon MiniGPT-4 and utilizes pretrained Vicuna weights for training.
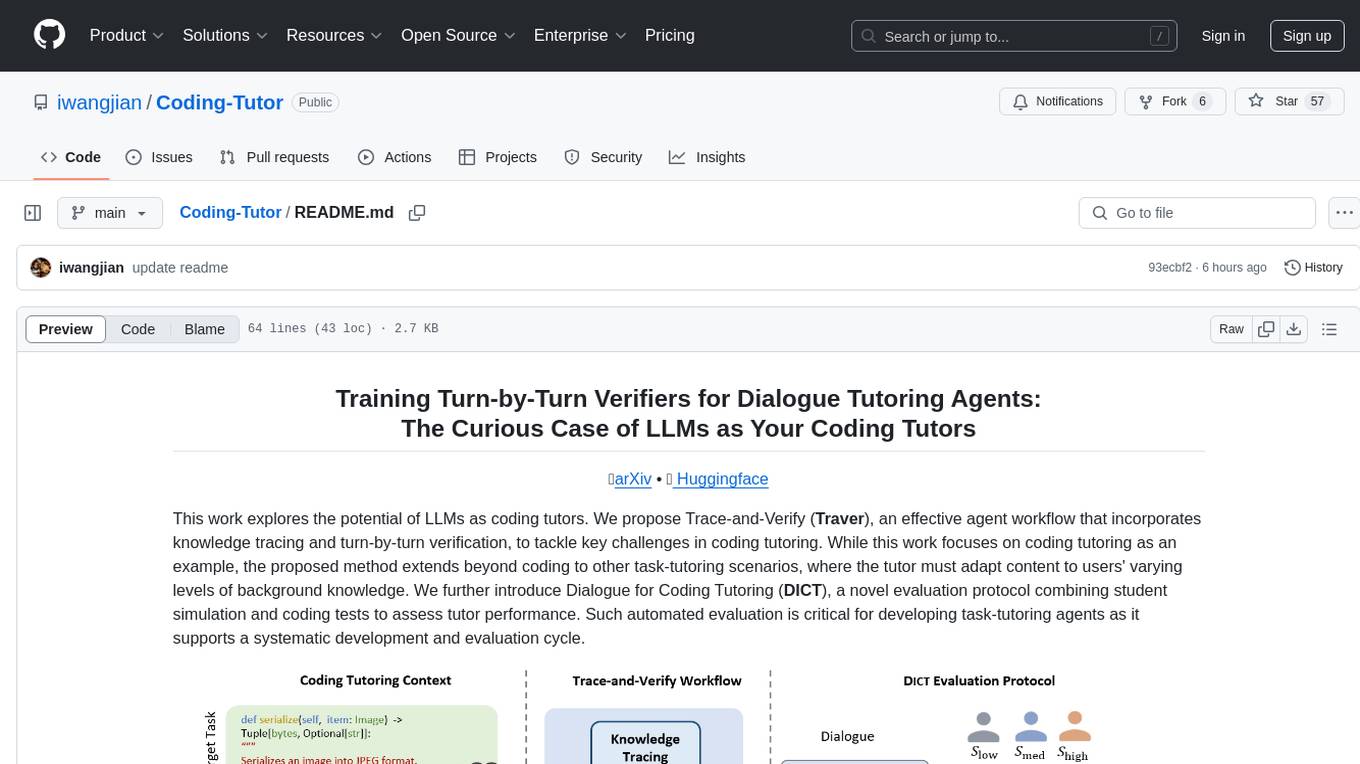
Coding-Tutor
This repository explores the potential of LLMs as coding tutors through the proposed Traver agent workflow. It focuses on incorporating knowledge tracing and turn-by-turn verification to tackle challenges in coding tutoring. The method extends beyond coding to other task-tutoring scenarios, adapting content to users' varying levels of background knowledge. The repository introduces the DICT evaluation protocol for assessing tutor performance through student simulation and coding tests. It also discusses the inference-time scaling with verifiers and provides resources for training and evaluation.
gromacs_copilot
GROMACS Copilot is an agent designed to automate molecular dynamics simulations for proteins in water using GROMACS. It handles system setup, simulation execution, and result analysis automatically, providing outputs such as RMSD, RMSF, Rg, and H-bonds. Users can interact with the agent through prompts and API keys from DeepSeek and OpenAI. The tool aims to simplify the process of running MD simulations, allowing users to focus on other tasks while it handles the technical aspects of the simulations.

ianvs
Ianvs is a distributed synergy AI benchmarking project incubated in KubeEdge SIG AI. It aims to test the performance of distributed synergy AI solutions following recognized standards, providing end-to-end benchmark toolkits, test environment management tools, test case control tools, and benchmark presentation tools. It also collaborates with other organizations to establish comprehensive benchmarks and related applications. The architecture includes critical components like Test Environment Manager, Test Case Controller, Generation Assistant, Simulation Controller, and Story Manager. Ianvs documentation covers quick start, guides, dataset descriptions, algorithms, user interfaces, stories, and roadmap.
Nucleoid
Nucleoid is a declarative (logic) runtime environment that manages both data and logic under the same runtime. It uses a declarative programming paradigm, which allows developers to focus on the business logic of the application, while the runtime manages the technical details. This allows for faster development and reduces the amount of code that needs to be written. Additionally, the sharding feature can help to distribute the load across multiple instances, which can further improve the performance of the system.

aitlas
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as a repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which allows benchmarking of various existing and novel AI methods tailored for EO data.
For similar tasks
FoR
FoR is the official code repository for the 'Flow of Reasoning: Training LLMs for Divergent Problem Solving with Minimal Examples' project. It formulates multi-step reasoning tasks as a flow, involving designing reward functions, collecting trajectories, and training LLM policies with trajectory balance loss. The code provides tools for training and inference in a reproducible experiment environment using conda. Users can choose from 5 tasks to run, each with detailed instructions in the respective branches.

ck
Collective Mind (CM) is a collection of portable, extensible, technology-agnostic and ready-to-use automation recipes with a human-friendly interface (aka CM scripts) to unify and automate all the manual steps required to compose, run, benchmark and optimize complex ML/AI applications on any platform with any software and hardware: see online catalog and source code. CM scripts require Python 3.7+ with minimal dependencies and are continuously extended by the community and MLCommons members to run natively on Ubuntu, MacOS, Windows, RHEL, Debian, Amazon Linux and any other operating system, in a cloud or inside automatically generated containers while keeping backward compatibility - please don't hesitate to report encountered issues here and contact us via public Discord Server to help this collaborative engineering effort! CM scripts were originally developed based on the following requirements from the MLCommons members to help them automatically compose and optimize complex MLPerf benchmarks, applications and systems across diverse and continuously changing models, data sets, software and hardware from Nvidia, Intel, AMD, Google, Qualcomm, Amazon and other vendors: * must work out of the box with the default options and without the need to edit some paths, environment variables and configuration files; * must be non-intrusive, easy to debug and must reuse existing user scripts and automation tools (such as cmake, make, ML workflows, python poetry and containers) rather than substituting them; * must have a very simple and human-friendly command line with a Python API and minimal dependencies; * must require minimal or zero learning curve by using plain Python, native scripts, environment variables and simple JSON/YAML descriptions instead of inventing new workflow languages; * must have the same interface to run all automations natively, in a cloud or inside containers. CM scripts were successfully validated by MLCommons to modularize MLPerf inference benchmarks and help the community automate more than 95% of all performance and power submissions in the v3.1 round across more than 120 system configurations (models, frameworks, hardware) while reducing development and maintenance costs.
repromodel
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.
ChatAFL
ChatAFL is a protocol fuzzer guided by large language models (LLMs) that extracts machine-readable grammar for protocol mutation, increases message diversity, and breaks coverage plateaus. It integrates with ProfuzzBench for stateful fuzzing of network protocols, providing smooth integration. The artifact includes modified versions of AFLNet and ProfuzzBench, source code for ChatAFL with proposed strategies, and scripts for setup, execution, analysis, and cleanup. Users can analyze data, construct plots, examine LLM-generated grammars, enriched seeds, and state-stall responses, and reproduce results with downsized experiments. Customization options include modifying fuzzers, tuning parameters, adding new subjects, troubleshooting, and working on GPT-4. Limitations include interaction with OpenAI's Large Language Models and a hard limit of 150,000 tokens per minute.
aiomultiprocess
aiomultiprocess is a Python library that combines AsyncIO and multiprocessing to achieve high levels of concurrency in Python applications. It allows running a full AsyncIO event loop on each child process, enabling multiple coroutines to execute simultaneously. The library provides a simple interface for executing asynchronous tasks on a pool of worker processes, making it easy to gather large amounts of network requests quickly. aiomultiprocess is designed to take Python codebases to the next level of performance by leveraging the combined power of AsyncIO and multiprocessing.

promptwright
Promptwright is a Python library designed for generating large synthetic datasets using a local LLM and various LLM service providers. It offers flexible interfaces for generating prompt-led synthetic datasets. The library supports multiple providers, configurable instructions and prompts, YAML configuration for tasks, command line interface for running tasks, push to Hugging Face Hub for dataset upload, and system message control. Users can define generation tasks using YAML configuration or Python code. Promptwright integrates with LiteLLM to interface with LLM providers and supports automatic dataset upload to Hugging Face Hub.

llmariner
LLMariner is an extensible open source platform built on Kubernetes to simplify the management of generative AI workloads. It enables efficient handling of training and inference data within clusters, with OpenAI-compatible APIs for seamless integration with a wide range of AI-driven applications.
mindcraft
Mindcraft is a project that crafts minds for Minecraft using Large Language Models (LLMs) and Mineflayer. It allows an LLM to write and execute code on your computer, with code sandboxed but still vulnerable to injection attacks. The project requires Minecraft Java Edition, Node.js, and one of several API keys. Users can run tasks to acquire specific items or construct buildings, customize project details in settings.js, and connect to online servers with a Microsoft/Minecraft account. The project also supports Docker container deployment for running in a secure environment.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.