Best AI tools for< Train Policy >
20 - AI tool Sites
The Institute for the Advancement of Legal and Ethical AI (ALEA)
The Institute for the Advancement of Legal and Ethical AI (ALEA) is a platform dedicated to supporting socially, economically, and environmentally sustainable futures through open research and education. They focus on developing legal and ethical frameworks to ensure that AI systems benefit society while minimizing harm to the economy and the environment. ALEA engages in activities such as open data collection, model training, technical and policy research, education, and community building to promote the responsible use of AI.

C3.ai Digital Transformation Institute
The C3.ai Digital Transformation Institute is a research consortium focused on accelerating the benefits of artificial intelligence for business, government, and society. It engages leading scientists in research related to the Science of Digital Transformation, which encompasses artificial intelligence, machine learning, cloud computing, internet of things, big data analytics, organizational behavior, public policy, and ethics. Established in March 2020, the institute consists of prominent institutions such as C3 AI, Microsoft Corporation, and various universities. The institute aims to drive innovation and collaboration in the field of AI and digital transformation.
Stanford HAI
Stanford HAI is a research institute at Stanford University dedicated to advancing AI research, education, and policy to improve the human condition. The institute brings together researchers from a variety of disciplines to work on a wide range of AI-related projects, including developing new AI algorithms, studying the ethical and societal implications of AI, and creating educational programs to train the next generation of AI leaders. Stanford HAI is committed to developing human-centered AI technologies and applications that benefit all of humanity.
Anthropic
Anthropic is an AI safety and research company based in San Francisco. Our interdisciplinary team has experience across ML, physics, policy, and product. Together, we generate research and create reliable, beneficial AI systems.
Cyberday.ai
Cyberday.ai is an AI-powered platform designed to help organizations improve and certify their cybersecurity. The platform offers a comprehensive set of tools and resources to guide users in implementing security tasks, creating policies, and generating compliance reports. With a focus on automation and efficiency, Cyberday.ai streamlines the process of managing information security, from risk assessment to employee training. By leveraging AI technology, Cyberday.ai aims to simplify the complex task of cybersecurity management for organizations of all sizes.
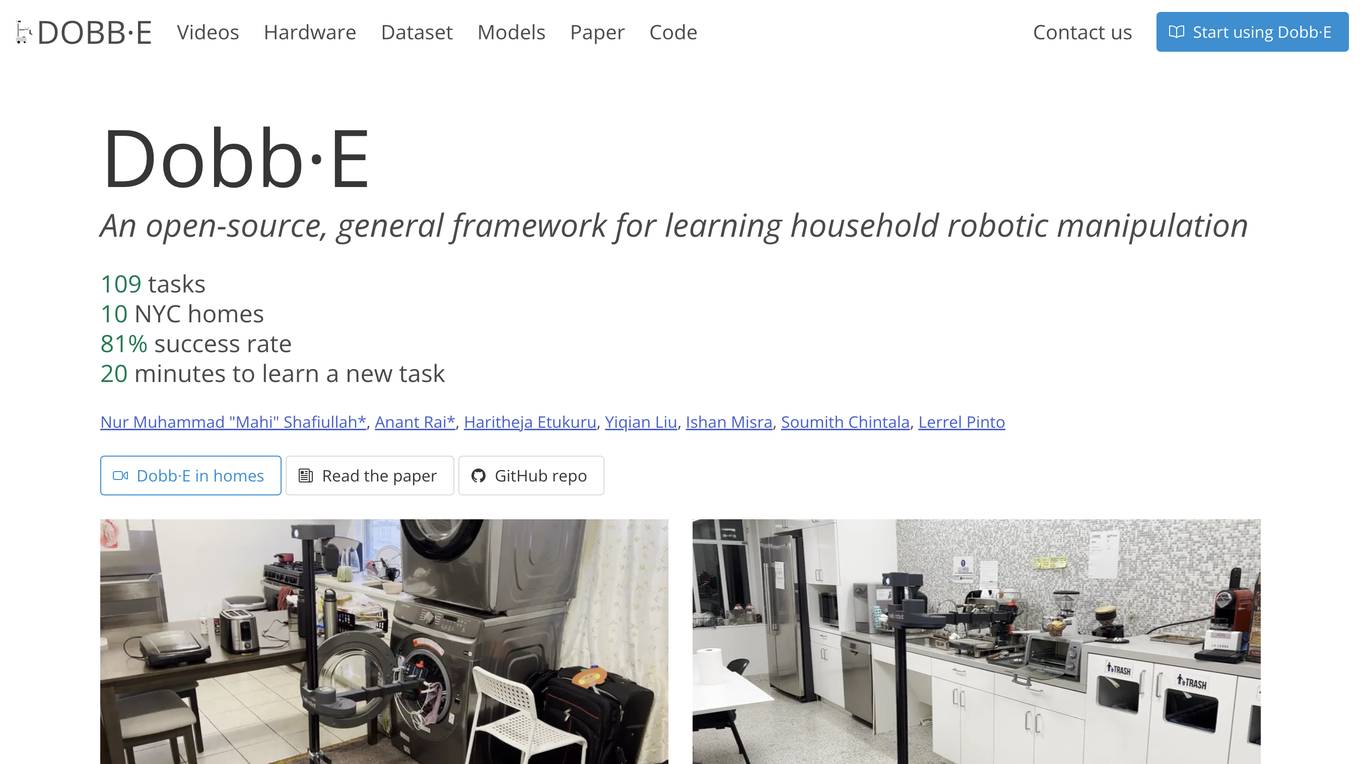
Dobb·E
Dobb·E is an open-source, general framework for learning household robotic manipulation. It aims to create a 'generalist machine' for homes, a domestic assistant that can adapt and learn various tasks cost-effectively. Dobb·E can learn a new task with just five minutes of demonstration, achieving an 81% success rate in 10 NYC homes. The system is designed to accelerate research on home robots and eventually enable robot butlers in every home.
Whale
Whale is an AI-powered software designed to help businesses document their standard operating procedures, policies, and internal company knowledge. It streamlines the process of onboarding, training, and growing teams by leveraging AI technology to assist in creating and organizing documentation. Whale offers features such as AI-assisted SOP and process documentation, automated training flows, a single source of truth for knowledge management, and an AI assistant named Alice to help with various tasks. The platform aims to systemize and scale businesses by providing a user-friendly interface and dedicated support services.
IBM Watsonx
IBM Watsonx is an enterprise studio for AI builders. It provides a platform to train, validate, tune, and deploy AI models quickly and efficiently. With Watsonx, users can access a library of pre-trained AI models, build their own models, and deploy them to the cloud or on-premises. Watsonx also offers a range of tools and services to help users manage and monitor their AI models.
Outlier AI
Outlier AI is a platform that connects subject matter experts to help build the world's most advanced Generative AI. It allows experts to work on various projects from generating training data to evaluating model performance. The platform offers flexibility, allowing contributors to work from home on their own schedule. Outlier AI aims to redefine how AI learns by leveraging the expertise of domain specialists across different fields.
Athletica AI
Athletica AI is an AI-powered athletic training and personalized fitness application that offers tailored coaching and training plans for various sports like cycling, running, duathlon, triathlon, and rowing. It adapts to individual fitness levels, abilities, and availability, providing daily step-by-step training plans and comprehensive session analyses. Athletica AI integrates seamlessly with workout data from platforms like Garmin, Strava, and Concept 2 to craft personalized training plans and workouts. The application aims to help athletes train smarter, not harder, by leveraging the power of AI to optimize performance and achieve fitness goals.
Backend.AI
Backend.AI is an enterprise-scale cluster backend for AI frameworks that offers scalability, GPU virtualization, HPC optimization, and DGX-Ready software products. It provides a fast and efficient way to build, train, and serve AI models of any type and size, with flexible infrastructure options. Backend.AI aims to optimize backend resources, reduce costs, and simplify deployment for AI developers and researchers. The platform integrates seamlessly with existing tools and offers fractional GPU usage and pay-as-you-play model to maximize resource utilization.
Kaiden AI
Kaiden AI is an AI-powered training platform that offers personalized, immersive simulations to enhance skills and performance across various industries and roles. It provides feedback-rich scenarios, voice-enabled interactions, and detailed performance insights. Users can create custom training scenarios, engage with AI personas, and receive real-time feedback to improve communication skills. Kaiden AI aims to revolutionize training solutions by combining AI technology with real-world practice.
Endurance
Endurance is a platform designed for runners, swimmers, and cyclists to engage in group training activities with friends or local communities. Users can create or join teams, share structured workouts, and benefit from collective motivation and accountability. The platform aims to make training fun and effective by leveraging the power of group workouts and social connections.
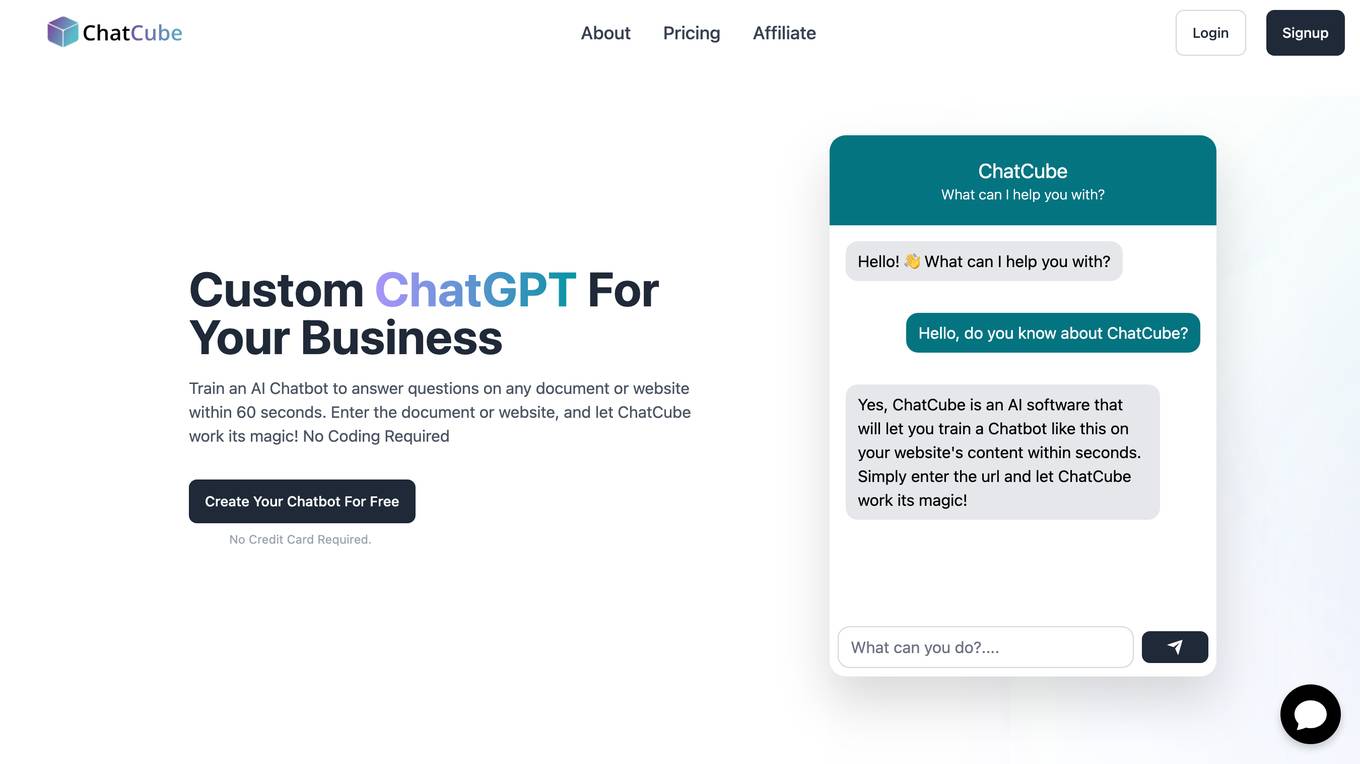
ChatCube
ChatCube is an AI-powered chatbot maker that allows users to create chatbots for their websites without coding. It uses advanced AI technology to train chatbots on any document or website within 60 seconds. ChatCube offers a range of features, including a user-friendly visual editor, lightning-fast integration, fine-tuning on specific data sources, data encryption and security, and customizable chatbots. By leveraging the power of AI, ChatCube helps businesses improve customer support efficiency and reduce support ticket reductions by up to 28%.
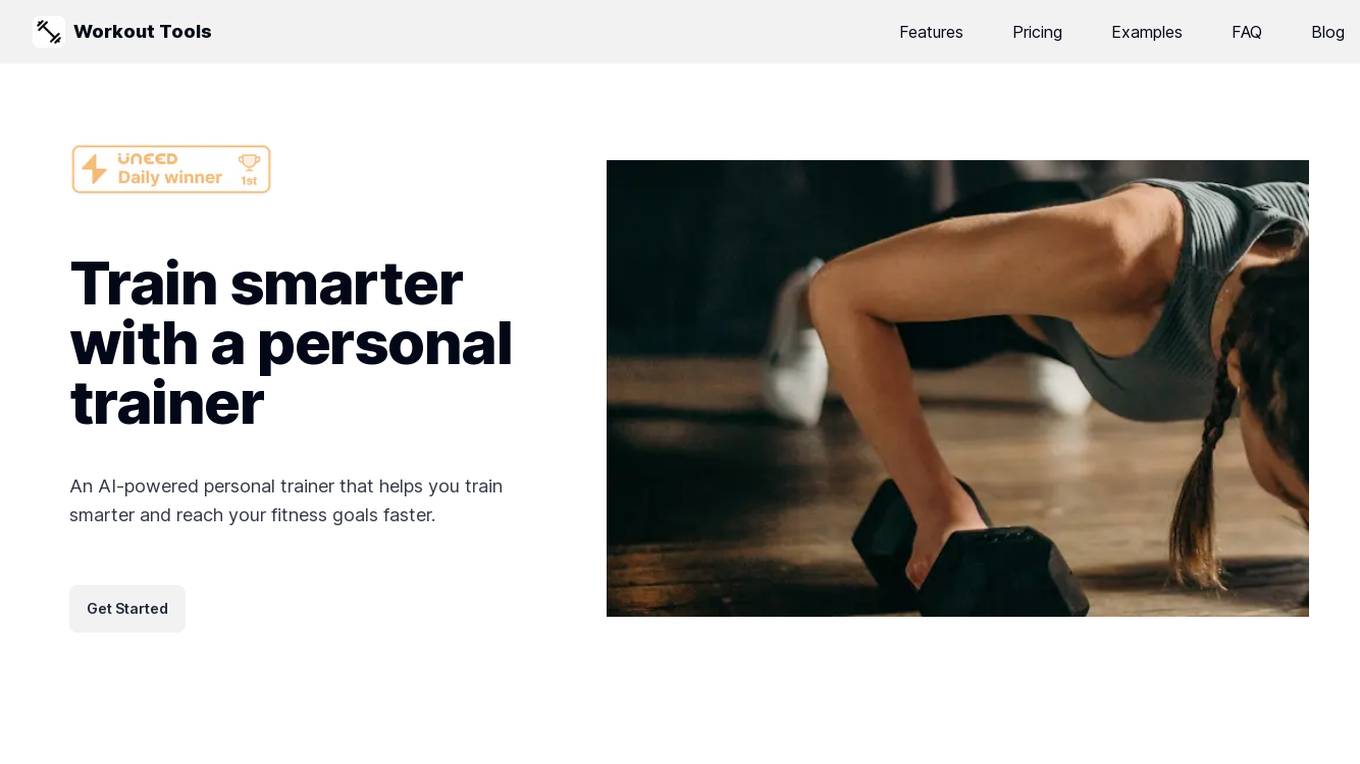
Workout Tools
Workout Tools is an AI-powered personal trainer that helps you train smarter and reach your fitness goals faster. It takes into account different parameters, such as your physics, the type of workout you're interested in, your available equipment, and comes up with a suggested workout. Don't like the workout? Just generate another one. It's that simple.
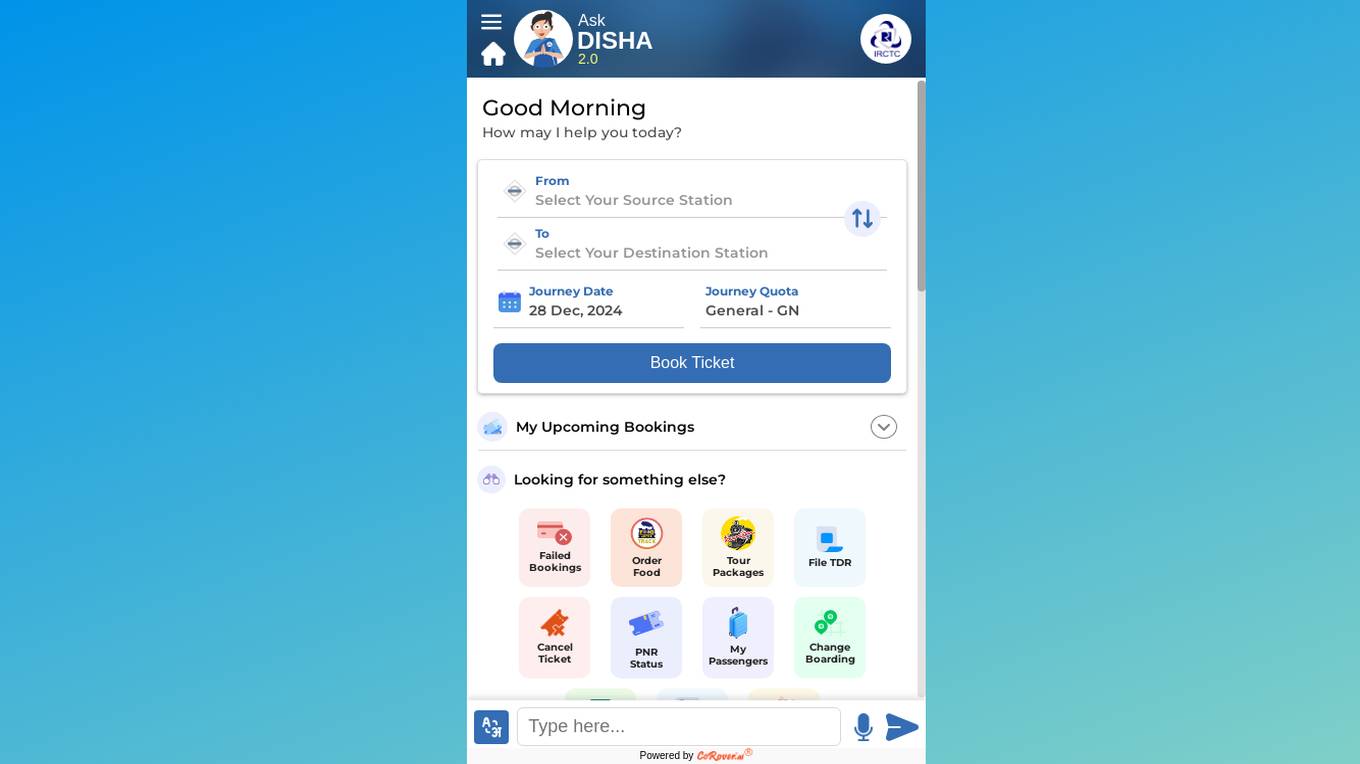
CoRover.ai
CoRover.ai is an AI-powered chatbot designed to help users book train tickets seamlessly through conversation. The chatbot, named AskDISHA, is integrated with the IRCTC platform, allowing users to inquire about train schedules, ticket availability, and make bookings effortlessly. CoRover.ai leverages artificial intelligence to provide personalized assistance and streamline the ticket booking process for users, enhancing their overall experience.
IllumiDesk
IllumiDesk is a generative AI platform for instructors and content developers that helps teams create and monetize content tailored 10X faster. With IllumiDesk, you can automate grading tasks, collaborate with your learners, create awesome content at the speed of AI, and integrate with the services you know and love. IllumiDesk's AI will help you create, maintain, and structure your content into interactive lessons. You can also leverage IllumiDesk's flexible integration options using the RESTful API and/or LTI v1.3 to leverage existing content and flows. IllumiDesk is trusted by training agencies and universities around the world.
Tovuti LMS
Tovuti LMS is an adaptive, people-first learning platform that helps organizations create engaging courses, train teams, and track progress. With its easy-to-use interface and powerful features, Tovuti LMS makes learning fun and easy. Tovuti LMS is trusted by leading organizations around the world to provide their employees with the training they need to succeed.

Kaba
Kaba is an open-source digital laboratory that empowers users to build their own AI models easily. It emphasizes privacy, security, and user control over data. The platform enables users to observe their attention and create brain-like mechanisms for intelligent systems based on their observable context. Kaba offers multi-modal, multi-input, and multi-context capabilities to enhance user experiences. The team behind Kaba comprises experts in design, technical advancements, innovation, security, and privacy, aiming to revolutionize technology interactions.
Chatbond
Chatbond is an AI chatbot builder that enables users to create customized chatbots for websites and messaging platforms without the need for coding skills. With Chatbond, users can design conversational interfaces, integrate AI capabilities, and deploy chatbots to enhance customer engagement and streamline communication processes. The platform offers a user-friendly interface with drag-and-drop functionality, pre-built templates, and analytics tools to monitor chatbot performance and optimize interactions. Chatbond empowers businesses to automate customer support, lead generation, and sales processes, improving efficiency and scalability.
2 - Open Source AI Tools
robot-3dlotus
Towards Generalizable Vision-Language Robotic Manipulation: A Benchmark and LLM-guided 3D Policy is a research project focusing on addressing the challenge of generalizing language-conditioned robotic policies to new tasks. The project introduces GemBench, a benchmark to evaluate the generalization capabilities of vision-language robotic manipulation policies. It also presents the 3D-LOTUS approach, which leverages rich 3D information for action prediction conditioned on language. Additionally, the project introduces 3D-LOTUS++, a framework that integrates 3D-LOTUS's motion planning capabilities with the task planning capabilities of LLMs and the object grounding accuracy of VLMs to achieve state-of-the-art performance on novel tasks in robotic manipulation.
FoR
FoR is the official code repository for the 'Flow of Reasoning: Training LLMs for Divergent Problem Solving with Minimal Examples' project. It formulates multi-step reasoning tasks as a flow, involving designing reward functions, collecting trajectories, and training LLM policies with trajectory balance loss. The code provides tools for training and inference in a reproducible experiment environment using conda. Users can choose from 5 tasks to run, each with detailed instructions in the respective branches.
20 - OpenAI Gpts

Battle GPT
AI Battle Realism Simulator | Realistic combat outcomes, with policy-compliant visuals

WM Crisis Response Simulator
Strategize in global crises and see what the AI will do in this interactive game!

Compliance Advisor
Ensures organizational adherence to laws, regulations, and internal policies.
Your AI Ethical Guide
Trained in kindness, empathy & respect based on ethics from global philosophies
ProtectED
A safeguarding advisor for schools, aligned with 'Keeping Children Safe In Education' guidelines.
Urban Ag Expert
Leading-edge Urban Ag Expert, blending accuracy with approachability. Powered by OpenAI.
未来教育
你是课程设计专家,心理学家,两个孩子的母亲,你非常关注如何让孩子更好地适应未来地世界,帮他们筛选最必要的技能。你擅长保护孩子的天然的兴趣,用游戏等有趣的方式帮助他们找到各种学习的乐趣。
Diversity & Inclusion Advisor
Promotes inclusive culture and diversity within the organization.
👑 Data Privacy for Real Estate Agencies 👑
Real Estate Agencies and Brokers deal with personal data of clients, including financial information and preferences, requiring careful handling and protection of such data.

H&J Medical Supplies HIPAA Compliance Expert
Expert in HIPAA compliance for medical supplies
Contemporary Compliance
🤓💡📃Engaging and positive US compliance expert helping professionals with DOJ-guidance based programs.
USA Data Compliance Master
Expert in answering Data Compliance queries for small businesses in the USA
Cyber Shielder
Expert in cyber security (NIST, OWASP, NIS2, MITRE ATT&CK, DORA) and GDPR, offering clear and concise guidance.


OAI Governance Emulator
I simulate the governance of a unique company focused on AI for good