
SheetCopilot
We release a general framework for prompting LLMs to manipulate software in a closed-loop manner.
Stars: 82

SheetCopilot is an assistant agent that manipulates spreadsheets by following user commands. It leverages Large Language Models (LLMs) to interact with spreadsheets like a human expert, enabling non-expert users to complete tasks on complex software such as Google Sheets and Excel via a language interface. The tool observes spreadsheet states, polishes generated solutions based on external action documents and error feedback, and aims to improve success rate and efficiency. SheetCopilot offers a dataset with diverse task categories and operations, supporting operations like entry & manipulation, management, formatting, charts, and pivot tables. Users can interact with SheetCopilot in Excel or Google Sheets, executing tasks like calculating revenue, creating pivot tables, and plotting charts. The tool's evaluation includes performance comparisons with leading LLMs and VBA-based methods on specific datasets, showcasing its capabilities in controlling various aspects of a spreadsheet.
README:
![]()
SheetCopilot Icon
Overview • Setup • Dataset • Sheetcopilot Usage • Evaluation • Poster • Paper • Citation
We release the SheetCopilot agent as well as the evaluation environment in this repository.
SheetCopilot is an assistant agent that manipulates spreadsheets by following user commands. It breaks new ground in human-computer interaction, opening up possibilities for enabling non-expert users to complete their mundane work on complex software (e.g. Google Sheets and Excel) via a language interface.
-
[2024/02/24] 🛠 Full SheetCopilot was released.
-
[2023/12/26] 🛠 SheetCopilot equipped with Chain-of-Thoughts and external document retrieval was released.
-
[2023/11/15] ✨ SheetCopilot for Google Sheets was released! You can now use SheetCopilot directly on Google Sheets. Check out our Google Sheets plugin store page and watch this tutorial for installation and usage guide.
-
[2023/10/27] 🛠 More ground truths! We added more reference solutions to our benchmark (
dataset/task_sheet_answers_v2) to obtain more accurate evaluation results. -
[2023/10/25] SheetCopilot benchmark was open-sourced.
-
[2023/9/22] 🎉 Our paper was accepted to NeurIPS 2023.
-
[2023/5/19] 👷🏻♂️ SheetCopilot was completed.
- Update the function call parsing code to fix the quote parsing errors
- Update API implementations
- Update the evaluation script to improve the checking accuracy
SheetCopilot employs a novel way of directing Large Language Models (LLMs) to manipulate spreadsheets like a human expert. To achieve elegant closed-loop control, SheetCopilot observes the spreadsheet state and polishes generated solutions according to external action documents and error feedback, thereby improving its success rate and efficiency.

SheetCopilot is only available on Windows. Python 3.10 is required to support the asynchronous implementation of SheetCopilot.
conda create -n sheetcopilot python=3.10
pip install -r requirements.txt
We released a spreadsheet task dataset containing 28 workbooks and 221 tasks applied to these workbooks. Each task is given one or more hand-made solutions.
Here is the overview of the dataset:

Our dataset contains diverse task categories and involves a wide range of operations:

Our dataset provides tasks with diverse complexity:

44 operations are supported and more will be added:
- Entry & manipulation: Write, CopyPaste, CutPaste, SetHyperlink, RemoveHyperlink, AutoFill, InsertRow, InsertColumn, Delete, Clear
- Management: Sort, Filter, DeleteFilter, MoveRow, MoveColumn, RemoveDuplicate
- Formatting: SetFormat, DeleteFormat, SetDataType, SetCellMerge, AutoFit, ResizeRowColumn, SetConditionalFormat, SetDataValidation, SetCellLock, FreezePanes, UnfreezePanes
- Chart: CreateChart, SetChartTrendline, SetChartTitle, SetChartHasAxis, SetChartAxis, SetChartHasLegend, SetChartLegend, SetChartType, AddChartErrorBars, RemoveChartErrorBars, AddDataLabels, RemoveDataLabels, SetChartMarker
- Pivot Table: CreatePivotTable, CreateChartFromPivotTable, CreateSheet, RemoveSheet
This dataset can be used to evaluate any spreadsheet agent including RL, LLM-based, or rule-based methods.
In the dataset folder, dataset.xlsx lists the 221 tasks, containing the target workbook name, task number, instruction, task categories, and involved atomic actions.
The fields are explained one by one as follows:
-
Sheet Name: The name of the sheet this task is applied to. -
No.: The number of this task. -
Context: The brief description of the sheet this task is applied to. This context will be added to the prompt to inform the LLM of the spreadsheet usage. -
Instructions: The task content. -
Categories: Each task is classified into multiple categories according to the atomic actions involved in the task. -
Atomic actions: The atomic actions used to solve the task -
Seed task: The number of the seed task (stored indataset/seed_tasks.xlsx) this task originates from. Our 221 tasks were produced by adapting the 67 seed tasks to apply them to the task sheets (thetask_sheetsfolder).
The task_sheets folder contains the 28 evaluation workbooks these tasks are applied to.
The task_sheet_answers folder contains the reference solutions of the tasks. Each solution consists of a reference workbook showing the expected outcome of the corresponding task and a *.yaml file listing the necessary sheet states to compare. If the necessary states of the result match those of one of the references, the result is seen as correct. (The v1 version is used in our paper while the v2 version contains more reference solutions collected after our paper was submitted)
Each solution folder (e.g. 1_BoomerangSales) contains at least 1 reference, which comprises a final spreadsheet (1_BoomerangSales_gt1.xlsx) and a checking list (1_BoomerangSales_gt1_check.yaml). Different tasks need different atomic actions so the checking lists are tailored to corresponding tasks.
The dataset_20Samples.xlsx file lists the 20 selected tasks used to compare the representative LLMs in our experiments (Table 1).
To dive deeper into the dataset collection details, refer to this tutorial.
This repo releases a simplified version of the SheetCopilot agent, whose state machine can do CoT reasoning and retrieve external documents.
SheetCopilot calls customized atomic actions to execute its generated solutions. We implement each atomic action using the pywin32 library. Please refer to API definitions to see the details. To compare with our SheetCopilot, your own agents should also adopt this action space.
Before running an experiment, please set max tokens, temperature, model_name, and API keys in config/config.yaml. (As launching multiple Excels still encounters certain unknown issues, we recommend worker=1. This can finish the evaluation in 1-2 hours.)
You can see two ChatGPT configs in this file - ChatGPT_1 is used to do planning while ChatGPT_2 is used to revise the format of the planning results. You can set use_same_LLM: true to use ChatGPT_1 to carry out both two jobs.
The underlying implementation of SheetCopilot is a state machine that implements planning by transitioning among 4 states (See the below figure). max_cycle_times is used to limit the number of times the agent visits the states.

SheetCopilot State Machine
Open an Excel workbook before running this command:
python interaction.py -c config/config.yaml
Now you can enter instructions and wait for SheetCoilot to finish them without human intervention.
To try SheetCopilot quickly, please open dataset/task_sheets/BoomerangSales.xlsx and then enter these instructions in order:
-
Calculate the revenue for each transaction considering the corresponding retail price and discount.
-
Highlight the Revenue cells greater than 500 in blue text.
-
Create a pivot table in a new sheet to show the counts of the websites on which boomerangs were sold.
-
Plot a bar chart for the pivot table in the same sheet.
-
Set the y-axis title as "Count" and turn off legends.
-
Create another pivot table in a new sheet to show the revenue sums of each product.
-
Plot a pie chart for the pivot table with the chart title "Revenue by Product" in this sheet.
You can also try more vague instructions like: Analyze the data and plot charts for the results.
Afterward, you may see SheetCopilot create pivot tables and plot proper charts for you (see the figure below).

Result of the example task
[Caution] Any operation executed by SheetCopilot cannot be undone by clicking the "Undo" button! We strongly recommend that our users use SheetCopilot on GoogleSheets to automate their spreadsheet tasks.
Open a GoogleSheets spreadsheet and install SheetCopilot on the Google Workspace Market like this:

Install SheetCopilot for GoogleSheets
Then you can hack SheetCopilot happily via chatting ...

Let SheetCopilot solve complex tasks for you
You can undo any operations executed by SheetCopilot by just using Ctrl + Z.
The results generated by any method should be organized like this:
results
└── ([Order]_[Sheet Name])
└── 1_BoomerangSales
| └── ([Order]_[Sheet Name]_[Repeat_No.].xlsx)
| └── 1_BoomerangSales_log.yaml
...
└── 9_BoomerangSales
└── 10_DemographicProfile
...
└── 17_Dragging
...
└── 24_Dragging
...
└── 221_XYScatterPlot
[Order] is the row index of the task minus 1 and [Sheet Name] is the items of column A in dataset.xlsx. [Repeat_NO.] is used to differentiate multiple repeats of the same task. If you run each task only once (controlled by repeat in the config file), [Repeat_NO.] is 1.
1_BoomerangSales_log.yaml is the running log of the task saving the content of the planning process. Likewise, your method should also record a log for each task.
You can also use the "[No.]_[Sheet Name]" naming convention as follows ([No.] are the items of column B in dataset.xlsx):
results
└── ([No.]_[Sheet Name])
└── 1_BoomerangSales
| └── ([No.]_[Sheet Name]_[Repeat_No.].xlsx)
| └── 1_BoomerangSales_log.yaml
...
└── 9_BoomerangSales
...
└── 1_Dragging
...
└── 8_Dragging
...
You should set the global variable USE_NO_AND_SHEETNAME in evaluation.py as True to use such a naming convention.
As different agents may present plans in various formats, we recommend that each method outputs each step using this Chain-of-Thoughts (CoT) format:
Step X. [Thought]
Action API: @[Action call]@
For example,
Step 3. Fill the formula to other cells.
Action API: @AutoFill(source="Sheet1!A2", destination="Sheet1!A2:A36")@
agent/SheetCopilot_example_logs shows examples of the required log format (use the "[Order]_[Sheet Name]" naming convention).
Specify the correct paths in agent/config/config.yaml and then run this code within the agent folder to evaluate your results:
python evaluation.py
The evaluation results will be recorded in a file named eval_result.yaml under the result folder.
The evaluation can restart from a checkpoint if it has been aborted. If you want to re-evaluate, just delete the eval_result.yaml in the result folder.
Important: NOTE that
- Every new sheet must be created to the left of the very first sheet for correct matching with the references since sheet names are not to be checked.
- The sheet content must start from cell A1 and each sheet is required to contain contiguous tables.
The performances of SheetCopilot with 3 leading LLMs as its back-end on dataset/dataset_20Samples.xlsx.
| Models | Exec@1 | Pass@1 | A50 | A90 |
|---|---|---|---|---|
| GPT-3.5-Turbo | 85.0% | 45.0% | 2.00 | 4.50 |
| GPT-4 | 65.0% | 55.0% | 1.33 | 2.00 |
| Claude | 80.0% | 40.0% | 1.50 | 4.40 |
The performances of SheetCopilot and a VBA-based method were evaluated on dataset/dataset.xlsx using dataset/task_sheet_answers as the ground truths. (Note: as we also included the functionally correct results generated by GPT-3.5-Turbo to dataset/task_sheet_answers_v2, the evaluation results for this model remain the same whether you use v1 or v2 ground truths.)
| Methods | Exec@1 | Pass@1 |
|---|---|---|
| GPT-3.5-Turbo | 87.3% | 44.3% |
| VBA-based | 77.8% | 16.3% |
(1) Manipulation: Writing values and formulas, deleting cells, inserting a row/column, auto-filling, copy-pasting values, find-and-replacing, setting hyperlinks, removing duplicates, creating sheets, clearing formats.
(2) Management: Sorting, filtering, and freezing panes.
(3) Formatting: Setting format and conditional format (font, bold, italic, underline, text color, and fill color), setting data type (date, text, number, currency, time, general, percentage), and merging.
(4) Charts: Creating charts, creating charts from pivot tables, setting chart title/axis title/legends/chart type/marker/trendline/data labels.
(5) Pivot table: Creating pivot tables.
(More operations will be added once the developers finish testing them. Besides, you can raise issues to ask for more supported operations or pull requests to upload your implementations.)
This video shows that SheetCopilot conducts GDP data analysis successfully.

The video below shows SheetCopilot deployed on Google Sheets.
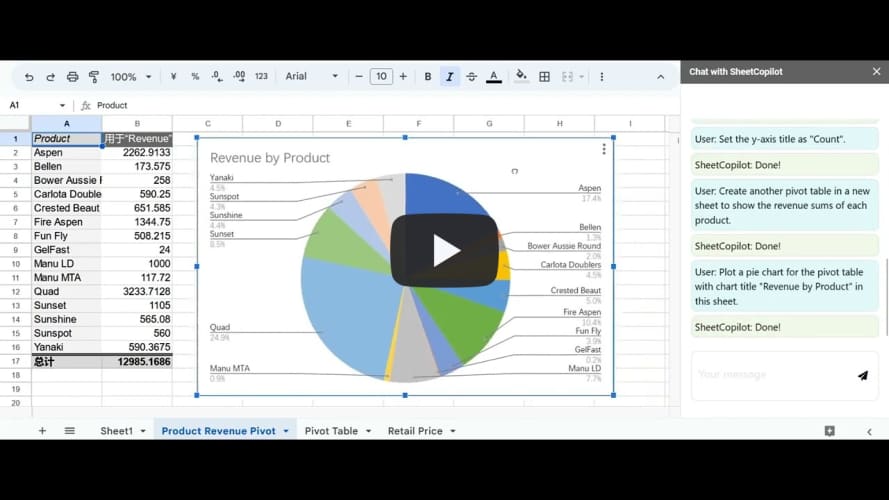
{kind=link}
You can upload task_sheets/BoomerangSales.xlsx and type in these instructions to reproduce the results in the demo:
- Calculate the revenue for each transaction in the sales table considering the corresponding retail price and discount.
- Highlight the Revenue cells greater than 500 in blue text.
- Create a pivot table in a new sheet to show the counts of the websites on which boomerangs were sold.
- Plot a bar chart for the pivot table in the same sheet.
- Set the y-axis title as "Count" and turn off legends.
- Create another pivot table in a new sheet to show the revenue sums of each product.
- Plot a pie chart for the pivot table with chart title "Revenue by Product" in this sheet.
SheetCopilot and the dataset can only be used for non-commercial purposes.
If you use the SheetCopilot agent and benchmark, feel free to cite us.
@inproceedings{li_sheetcopilot_2023,
title = {{SheetCopilot}: {Bringing} {Software} {Productivity} to the {Next} {Level} through {Large} {Language} {Models}},
volume = {36},
url = {https://proceedings.neurips.cc/paper_files/paper/2023/file/0ff30c4bf31db0119a6219e0d250e037-Paper-Conference.pdf},
booktitle = {Advances in {Neural} {Information} {Processing} {Systems}},
publisher = {Curran Associates, Inc.},
author = {Li, Hongxin and Su, Jingran and Chen, Yuntao and Li, Qing and ZHANG, ZHAO-XIANG},
editor = {Oh, A. and Neumann, T. and Globerson, A. and Saenko, K. and Hardt, M. and Levine, S.},
year = {2023},
pages = {4952--4984},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for SheetCopilot
Similar Open Source Tools
SheetCopilot
SheetCopilot is an assistant agent that manipulates spreadsheets by following user commands. It leverages Large Language Models (LLMs) to interact with spreadsheets like a human expert, enabling non-expert users to complete tasks on complex software such as Google Sheets and Excel via a language interface. The tool observes spreadsheet states, polishes generated solutions based on external action documents and error feedback, and aims to improve success rate and efficiency. SheetCopilot offers a dataset with diverse task categories and operations, supporting operations like entry & manipulation, management, formatting, charts, and pivot tables. Users can interact with SheetCopilot in Excel or Google Sheets, executing tasks like calculating revenue, creating pivot tables, and plotting charts. The tool's evaluation includes performance comparisons with leading LLMs and VBA-based methods on specific datasets, showcasing its capabilities in controlling various aspects of a spreadsheet.

RepoAgent
RepoAgent is an LLM-powered framework designed for repository-level code documentation generation. It automates the process of detecting changes in Git repositories, analyzing code structure through AST, identifying inter-object relationships, replacing Markdown content, and executing multi-threaded operations. The tool aims to assist developers in understanding and maintaining codebases by providing comprehensive documentation, ultimately improving efficiency and saving time.

MME-RealWorld
MME-RealWorld is a benchmark designed to address real-world applications with practical relevance, featuring 13,366 high-resolution images and 29,429 annotations across 43 tasks. It aims to provide substantial recognition challenges and overcome common barriers in existing Multimodal Large Language Model benchmarks, such as small data scale, restricted data quality, and insufficient task difficulty. The dataset offers advantages in data scale, data quality, task difficulty, and real-world utility compared to existing benchmarks. It also includes a Chinese version with additional images and QA pairs focused on Chinese scenarios.

poml
POML (Prompt Orchestration Markup Language) is a novel markup language designed to bring structure, maintainability, and versatility to advanced prompt engineering for Large Language Models (LLMs). It addresses common challenges in prompt development, such as lack of structure, complex data integration, format sensitivity, and inadequate tooling. POML provides a systematic way to organize prompt components, integrate diverse data types seamlessly, and manage presentation variations, empowering developers to create more sophisticated and reliable LLM applications.

Taiyi-LLM
Taiyi (太一) is a bilingual large language model fine-tuned for diverse biomedical tasks. It aims to facilitate communication between healthcare professionals and patients, provide medical information, and assist in diagnosis, biomedical knowledge discovery, drug development, and personalized healthcare solutions. The model is based on the Qwen-7B-base model and has been fine-tuned using rich bilingual instruction data. It covers tasks such as question answering, biomedical dialogue, medical report generation, biomedical information extraction, machine translation, title generation, text classification, and text semantic similarity. The project also provides standardized data formats, model training details, model inference guidelines, and overall performance metrics across various BioNLP tasks.
rosa
ROSA is an AI Agent designed to interact with ROS-based robotics systems using natural language queries. It can generate system reports, read and parse ROS log files, adapt to new robots, and run various ROS commands using natural language. The tool is versatile for robotics research and development, providing an easy way to interact with robots and the ROS environment.

guidellm
GuideLLM is a powerful tool for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM helps users gauge the performance, resource needs, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. Key features include performance evaluation, resource optimization, cost estimation, and scalability testing.

fuse-med-ml
FuseMedML is a Python framework designed to accelerate machine learning-based discovery in the medical field by promoting code reuse. It provides a flexible design concept where data is stored in a nested dictionary, allowing easy handling of multi-modality information. The framework includes components for creating custom models, loss functions, metrics, and data processing operators. Additionally, FuseMedML offers 'batteries included' key components such as fuse.data for data processing, fuse.eval for model evaluation, and fuse.dl for reusable deep learning components. It supports PyTorch and PyTorch Lightning libraries and encourages the creation of domain extensions for specific medical domains.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

neuron-ai
Neuron AI is a PHP framework that provides an Agent class for creating fully functional agents to perform tasks like analyzing text for SEO optimization. The framework manages advanced mechanisms such as memory, tools, and function calls. Users can extend the Agent class to create custom agents and interact with them to get responses based on the underlying LLM. Neuron AI aims to simplify the development of AI-powered applications by offering a structured framework with documentation and guidelines for contributions under the MIT license.

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.

VoiceStreamAI
VoiceStreamAI is a Python 3-based server and JavaScript client solution for near-realtime audio streaming and transcription using WebSocket. It employs Huggingface's Voice Activity Detection (VAD) and OpenAI's Whisper model for accurate speech recognition. The system features real-time audio streaming, modular design for easy integration of VAD and ASR technologies, customizable audio chunk processing strategies, support for multilingual transcription, and secure sockets support. It uses a factory and strategy pattern implementation for flexible component management and provides a unit testing framework for robust development.

giskard
Giskard is an open-source Python library that automatically detects performance, bias & security issues in AI applications. The library covers LLM-based applications such as RAG agents, all the way to traditional ML models for tabular data.
Video-MME
Video-MME is the first-ever comprehensive evaluation benchmark of Multi-modal Large Language Models (MLLMs) in Video Analysis. It assesses the capabilities of MLLMs in processing video data, covering a wide range of visual domains, temporal durations, and data modalities. The dataset comprises 900 videos with 256 hours and 2,700 human-annotated question-answer pairs. It distinguishes itself through features like duration variety, diversity in video types, breadth in data modalities, and quality in annotations.
zipnn
ZipNN is a lossless and near-lossless compression library optimized for numbers/tensors in the Foundation Models environment. It automatically prepares data for compression based on its type, allowing users to focus on core tasks without worrying about compression complexities. The library delivers effective compression techniques for different data types and structures, achieving high compression ratios and rates. ZipNN supports various compression methods like ZSTD, lz4, and snappy, and provides ready-made scripts for file compression/decompression. Users can also manually import the package to compress and decompress data. The library offers advanced configuration options for customization and validation tests for different input and compression types.

KlicStudio
Klic Studio is a versatile audio and video localization and enhancement solution developed by Krillin AI. This minimalist yet powerful tool integrates video translation, dubbing, and voice cloning, supporting both landscape and portrait formats. With an end-to-end workflow, users can transform raw materials into beautifully ready-to-use cross-platform content with just a few clicks. The tool offers features like video acquisition, accurate speech recognition, intelligent segmentation, terminology replacement, professional translation, voice cloning, video composition, and cross-platform support. It also supports various speech recognition services, large language models, and TTS text-to-speech services. Users can easily deploy the tool using Docker and configure it for different tasks like subtitle translation, large model translation, and optional voice services.
For similar tasks
SheetCopilot
SheetCopilot is an assistant agent that manipulates spreadsheets by following user commands. It leverages Large Language Models (LLMs) to interact with spreadsheets like a human expert, enabling non-expert users to complete tasks on complex software such as Google Sheets and Excel via a language interface. The tool observes spreadsheet states, polishes generated solutions based on external action documents and error feedback, and aims to improve success rate and efficiency. SheetCopilot offers a dataset with diverse task categories and operations, supporting operations like entry & manipulation, management, formatting, charts, and pivot tables. Users can interact with SheetCopilot in Excel or Google Sheets, executing tasks like calculating revenue, creating pivot tables, and plotting charts. The tool's evaluation includes performance comparisons with leading LLMs and VBA-based methods on specific datasets, showcasing its capabilities in controlling various aspects of a spreadsheet.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.
vertex-ai-samples
The Google Cloud Vertex AI sample repository contains notebooks and community content that demonstrate how to develop and manage ML workflows using Google Cloud Vertex AI.
argilla
Argilla is a collaboration platform for AI engineers and domain experts that require high-quality outputs, full data ownership, and overall efficiency. It helps users improve AI output quality through data quality, take control of their data and models, and improve efficiency by quickly iterating on the right data and models. Argilla is an open-source community-driven project that provides tools for achieving and maintaining high-quality data standards, with a focus on NLP and LLMs. It is used by AI teams from companies like the Red Cross, Loris.ai, and Prolific to improve the quality and efficiency of AI projects.
For similar jobs
SheetCopilot
SheetCopilot is an assistant agent that manipulates spreadsheets by following user commands. It leverages Large Language Models (LLMs) to interact with spreadsheets like a human expert, enabling non-expert users to complete tasks on complex software such as Google Sheets and Excel via a language interface. The tool observes spreadsheet states, polishes generated solutions based on external action documents and error feedback, and aims to improve success rate and efficiency. SheetCopilot offers a dataset with diverse task categories and operations, supporting operations like entry & manipulation, management, formatting, charts, and pivot tables. Users can interact with SheetCopilot in Excel or Google Sheets, executing tasks like calculating revenue, creating pivot tables, and plotting charts. The tool's evaluation includes performance comparisons with leading LLMs and VBA-based methods on specific datasets, showcasing its capabilities in controlling various aspects of a spreadsheet.
LangGraph-Expense-Tracker
LangGraph Expense tracker is a small project that explores the possibilities of LangGraph. It allows users to send pictures of invoices, which are then structured and categorized into expenses and stored in a database. The project includes functionalities for invoice extraction, database setup, and API configuration. It consists of various modules for categorizing expenses, creating database tables, and running the API. The database schema includes tables for categories, payment methods, and expenses, each with specific columns to track transaction details. The API documentation is available for reference, and the project utilizes LangChain for processing expense data.
receipt-scanner
The receipt-scanner repository is an AI-Powered Receipt and Invoice Scanner for Laravel that allows users to easily extract structured receipt data from images, PDFs, and emails within their Laravel application using OpenAI. It provides a light wrapper around OpenAI Chat and Completion endpoints, supports various input formats, and integrates with Textract for OCR functionality. Users can install the package via composer, publish configuration files, and use it to extract data from plain text, PDFs, images, Word documents, and web content. The scanned receipt data is parsed into a DTO structure with main classes like Receipt, Merchant, and LineItem.
actual-ai
Actual AI is a project designed to categorize uncategorized transactions for Actual Budget using OpenAI or OpenAI specification compatible API. It sends requests to the OpenAI API to classify transactions based on their description, amount, and notes. Transactions that cannot be classified are marked as 'not guessed' in notes. The tool allows users to sync accounts before classification and classify transactions on a cron schedule. Guessed transactions are marked in notes for easy review.
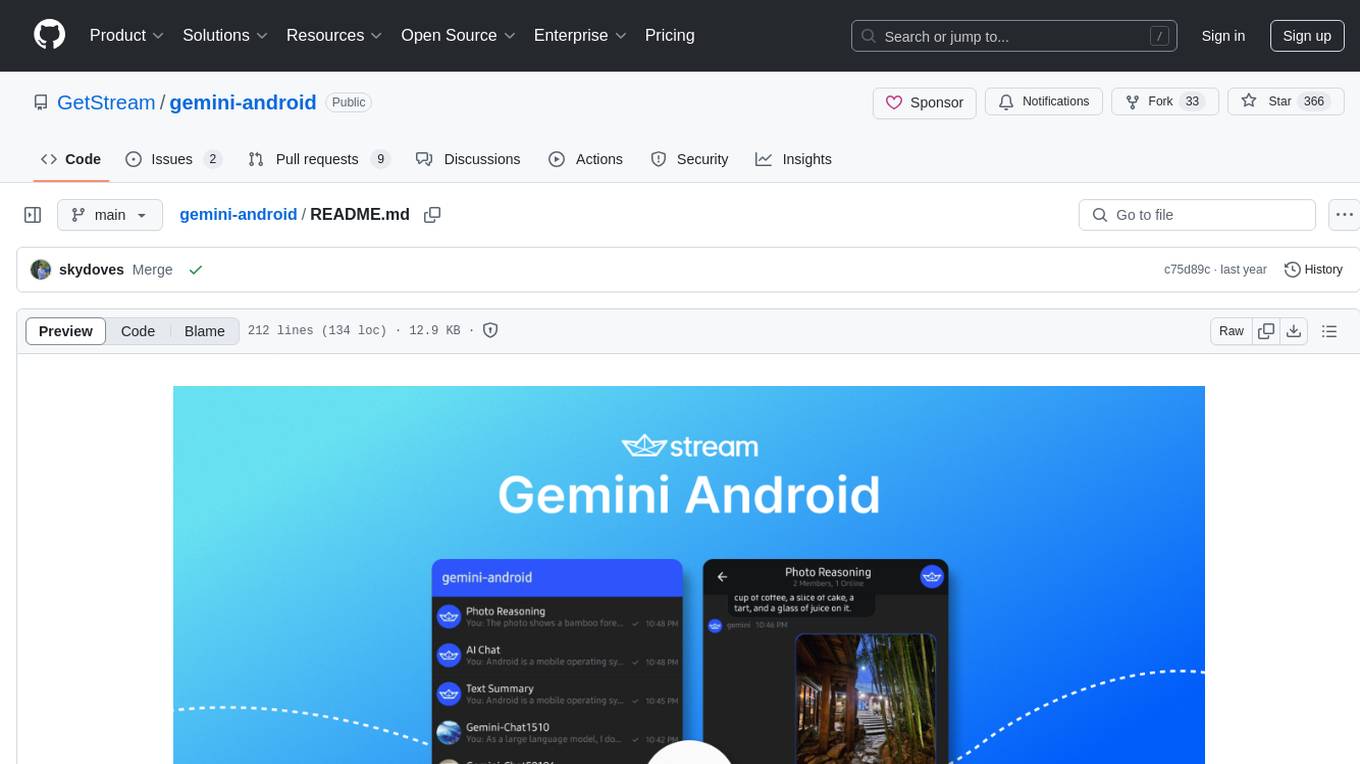
gemini-android
Gemini-Android is a mobile application that allows users to track their expenses and manage their finances on the go. The app provides a user-friendly interface for adding and categorizing expenses, setting budgets, and generating reports to help users make informed financial decisions. With Gemini-Android, users can easily monitor their spending habits, identify areas for saving, and stay on top of their financial goals.
wealth-tracker
Wealth Tracker is a personal finance management tool designed to help users track their income, expenses, and investments in one place. With intuitive features and customizable categories, users can easily monitor their financial health and make informed decisions. The tool provides detailed reports and visualizations to analyze spending patterns and set financial goals. Whether you are budgeting, saving for a big purchase, or planning for retirement, Wealth Tracker offers a comprehensive solution to manage your money effectively.
TaxHacker
TaxHacker is a self-hosted accountant app designed for freelancers and small businesses to automate expense and income tracking using the power of GenAI. It can analyze uploaded photos, receipts, or PDFs to extract important data like name, total amount, date, merchant, and VAT, saving them as structured transactions. The tool supports automatic currency conversion, filters, multiple projects, import-export functionalities, custom categories, and allows users to create custom fields for extraction. TaxHacker simplifies reporting and tax filing by organizing and storing data efficiently.
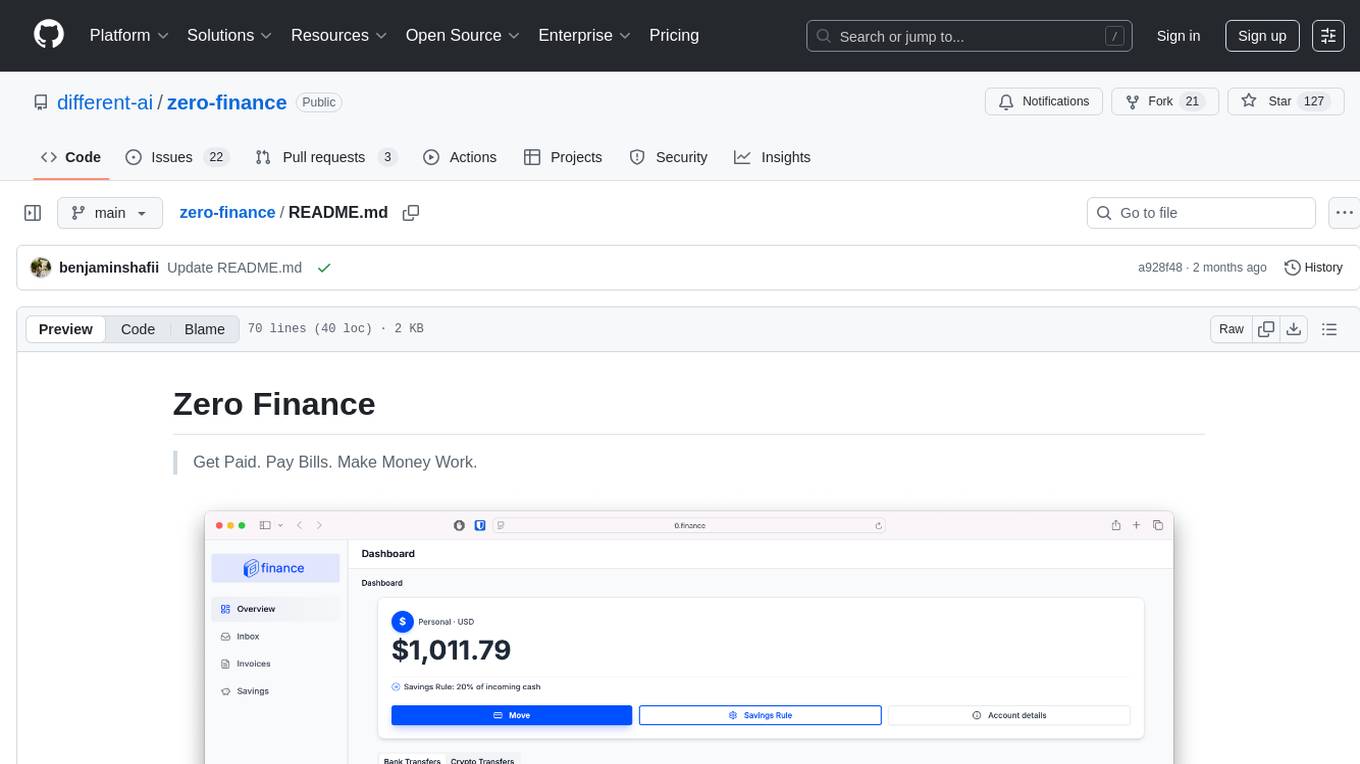
zero-finance
Zero Finance is a bank account that automates your finances, allowing you to easily create invoices, get paid directly to your personal IBAN, use a debit card worldwide with 0% conversion fees, optimize yield by automatically allocating idle funds to highest-yielding opportunities, and automate finances with a complete accounting system including expense tracking and tax optimization. The tool also syncs with various data sources to help you stay on track of your financial tasks by surfacing critical information, auto-categorizing based on AI-rules, auto-scheduling vendor payments from invoices via AI-rules, and allowing export to CSV. The project is structured as a monorepo containing multiple packages for the bank web app and a smart contract for securely automating savings.