Best AI tools for< Reproduce Experiments >
9 - AI tool Sites
Sacred
Sacred is a tool to configure, organize, log and reproduce computational experiments. It is designed to introduce only minimal overhead, while encouraging modularity and configurability of experiments. The ability to conveniently make experiments configurable is at the heart of Sacred. If the parameters of an experiment are exposed in this way, it will help you to: keep track of all the parameters of your experiment easily run your experiment for different settings save configurations for individual runs in files or a database reproduce your results In Sacred we achieve this through the following main mechanisms: Config Scopes are functions with a @ex.config decorator, that turn all local variables into configuration entries. This helps to set up your configuration really easily. Those entries can then be used in captured functions via dependency injection. That way the system takes care of passing parameters around for you, which makes using your config values really easy. The command-line interface can be used to change the parameters, which makes it really easy to run your experiment with modified parameters. Observers log every information about your experiment and the configuration you used, and saves them for example to a Database. This helps to keep track of all your experiments. Automatic seeding helps controlling the randomness in your experiments, such that they stay reproducible.
Comet ML
Comet ML is a machine learning platform that integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring.
Comet ML
Comet ML is a machine learning platform that integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring.
Comet ML
Comet ML is an extensible, fully customizable machine learning platform that aims to move ML forward by supporting productivity, reproducibility, and collaboration. It integrates with existing infrastructure and tools to manage, visualize, and optimize models from training runs to production monitoring. Users can track and compare training runs, create a model registry, and monitor models in production all in one platform. Comet's platform can be run on any infrastructure, enabling users to reshape their ML workflow and bring their existing software and data stack.
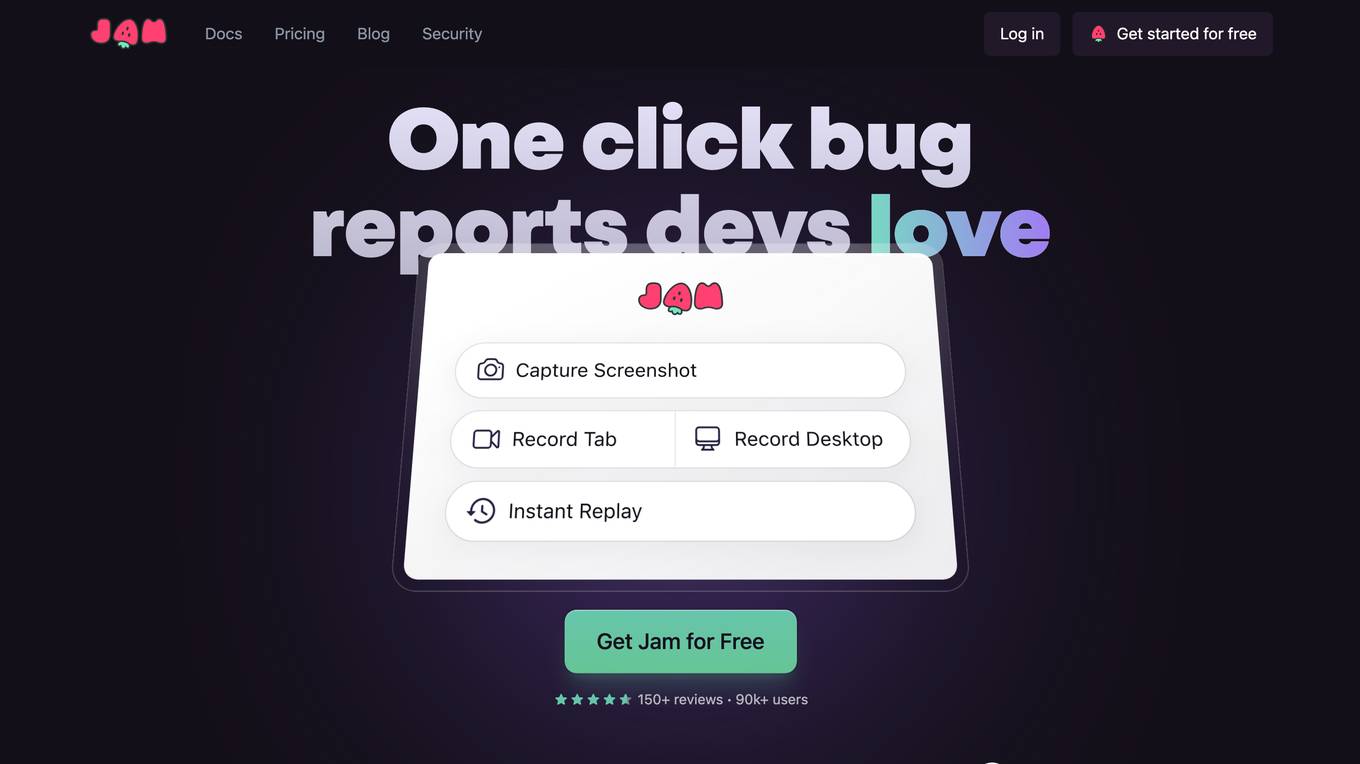
Jam
Jam is a bug-tracking tool that helps developers reproduce and debug issues quickly and easily. It automatically captures all the information engineers need to debug, including device and browser information, console logs, network logs, repro steps, and backend tracing. Jam also integrates with popular tools like GitHub, Jira, Linear, Slack, ClickUp, Asana, Sentry, Figma, Datadog, Gitlab, Notion, and Airtable. With Jam, developers can save time and effort by eliminating the need to write repro steps and manually collect information. Jam is used by over 90,000 developers and has received over 150 positive reviews.
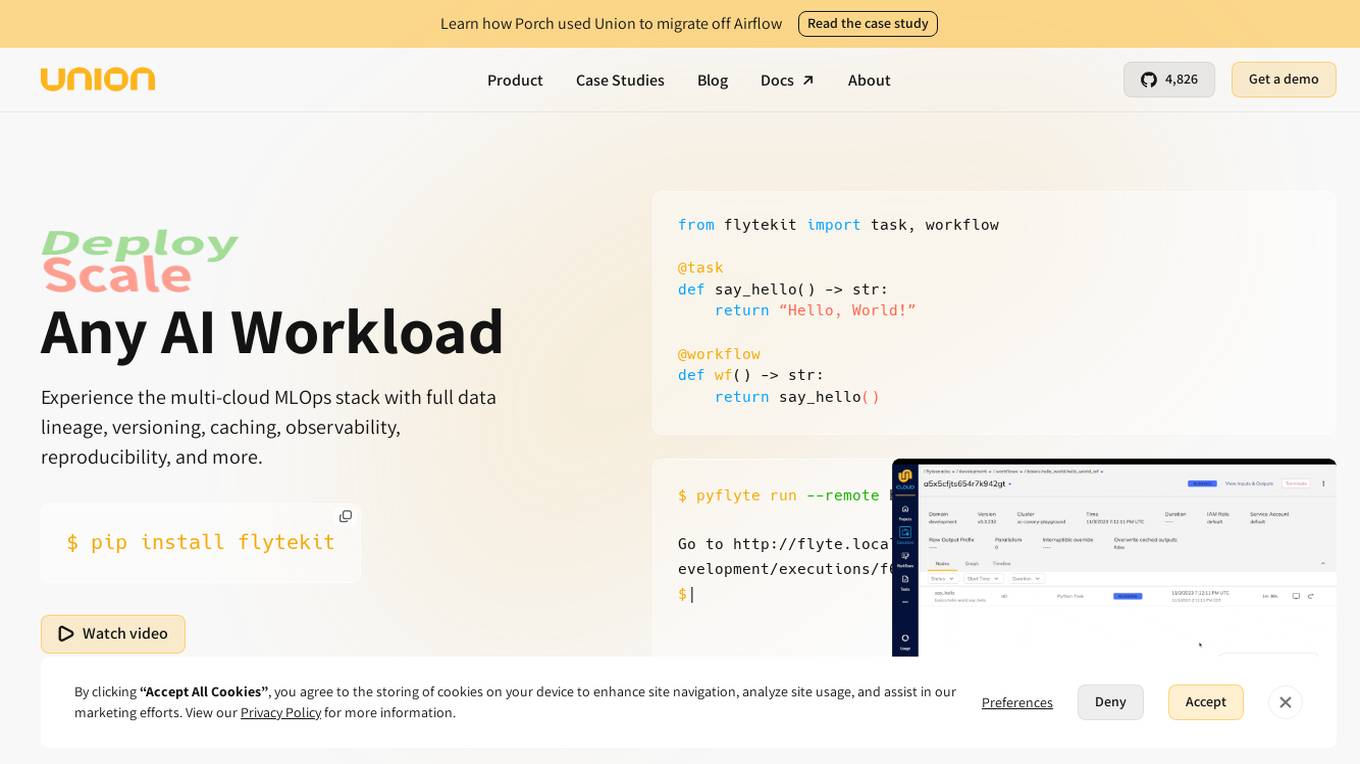
Union.ai
Union.ai is an infrastructure platform designed for AI, ML, and data workloads. It offers a scalable MLOps platform that optimizes resources, reduces costs, and fosters collaboration among team members. Union.ai provides features such as declarative infrastructure, data lineage tracking, accelerated datasets, and more to streamline AI orchestration on Kubernetes. It aims to simplify the management of AI, ML, and data workflows in production environments by addressing complexities and offering cost-effective strategies.
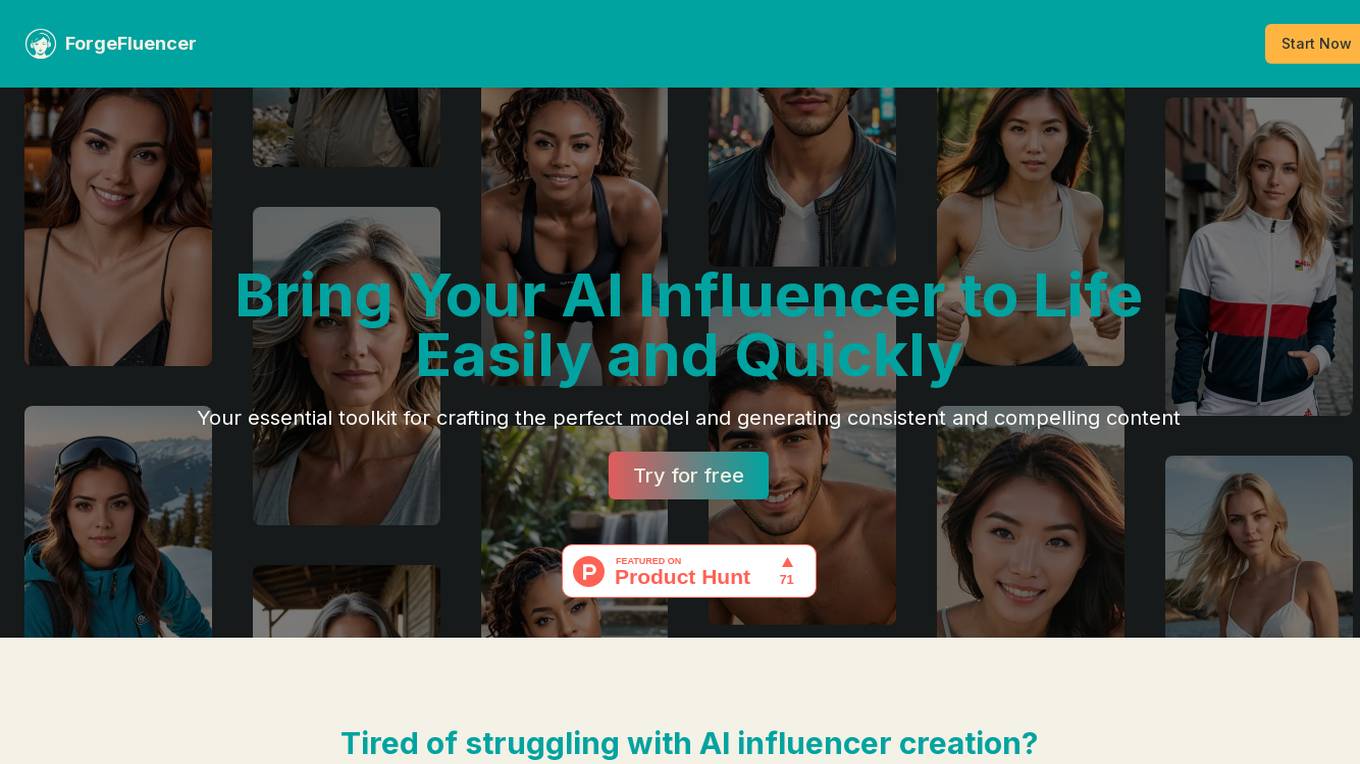
ForgeFluencer
ForgeFluencer is an AI application that serves as an essential toolkit for crafting AI influencers and generating consistent and compelling content. It offers a user-friendly platform optimized for desktop and mobile, allowing users to create models, control various aspects of content generation, edit images with AI, and more. With features like Virtual Wardrobe, Pose Controller, and Photo Studio, ForgeFluencer empowers users to elevate their projects with AI-generated content effortlessly.
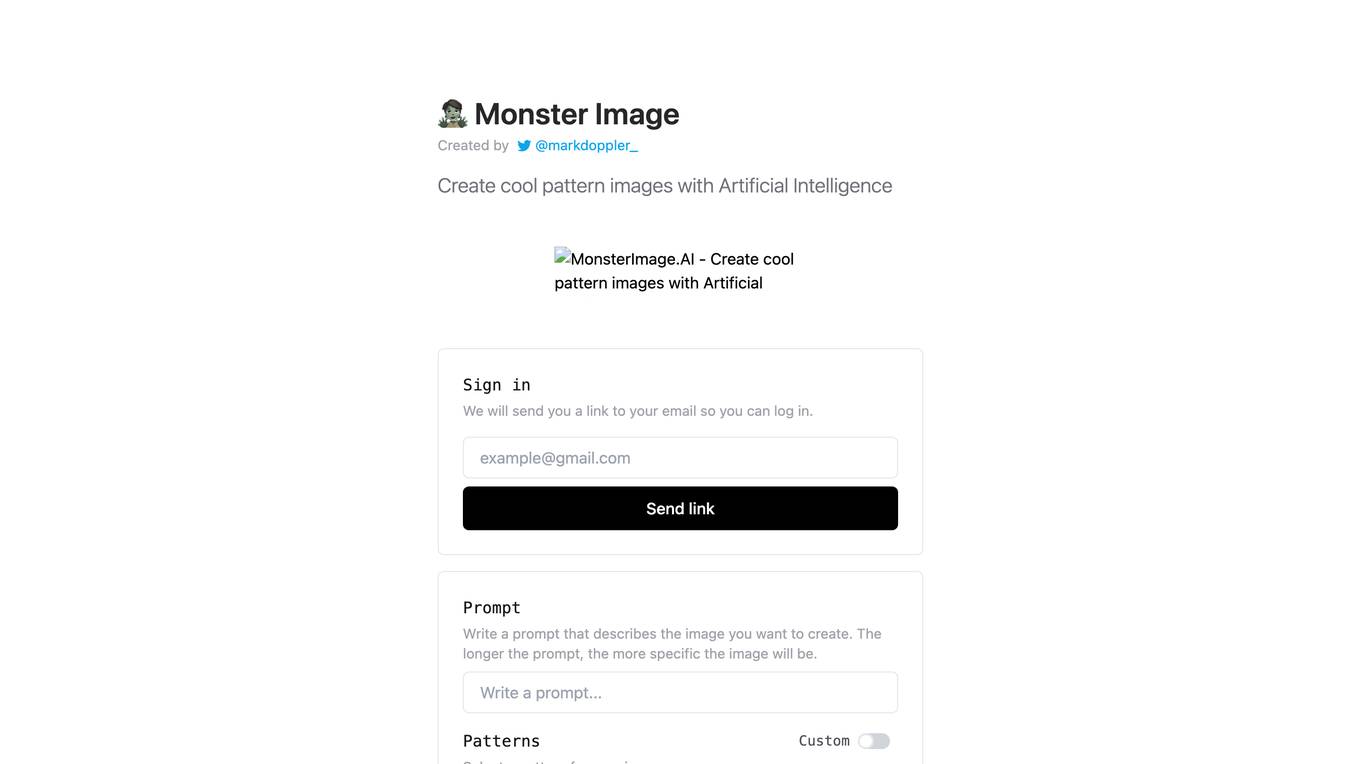
MonsterImage.AI
MonsterImage.AI is an AI-powered tool that allows users to create cool pattern images using Artificial Intelligence. Users can sign in to the platform and receive a link via email to log in. They can write a prompt to describe the image they want to create, select a pattern, specify negative prompts, use a seed for reproduction, adjust guidance scale, controlnet conditioning scale, and inference steps. The tool offers advanced options for creating images and allows users to save their creations in a public collection.

GoDaddy
The website www.godaddy.com is a domain registrar and web hosting company that offers services to help individuals and businesses establish their online presence. It provides domain registration, website building tools, hosting services, and online marketing solutions. With a user-friendly interface, GoDaddy aims to simplify the process of creating and managing websites for users of all technical levels.
4 - Open Source AI Tools

ck
Collective Mind (CM) is a collection of portable, extensible, technology-agnostic and ready-to-use automation recipes with a human-friendly interface (aka CM scripts) to unify and automate all the manual steps required to compose, run, benchmark and optimize complex ML/AI applications on any platform with any software and hardware: see online catalog and source code. CM scripts require Python 3.7+ with minimal dependencies and are continuously extended by the community and MLCommons members to run natively on Ubuntu, MacOS, Windows, RHEL, Debian, Amazon Linux and any other operating system, in a cloud or inside automatically generated containers while keeping backward compatibility - please don't hesitate to report encountered issues here and contact us via public Discord Server to help this collaborative engineering effort! CM scripts were originally developed based on the following requirements from the MLCommons members to help them automatically compose and optimize complex MLPerf benchmarks, applications and systems across diverse and continuously changing models, data sets, software and hardware from Nvidia, Intel, AMD, Google, Qualcomm, Amazon and other vendors: * must work out of the box with the default options and without the need to edit some paths, environment variables and configuration files; * must be non-intrusive, easy to debug and must reuse existing user scripts and automation tools (such as cmake, make, ML workflows, python poetry and containers) rather than substituting them; * must have a very simple and human-friendly command line with a Python API and minimal dependencies; * must require minimal or zero learning curve by using plain Python, native scripts, environment variables and simple JSON/YAML descriptions instead of inventing new workflow languages; * must have the same interface to run all automations natively, in a cloud or inside containers. CM scripts were successfully validated by MLCommons to modularize MLPerf inference benchmarks and help the community automate more than 95% of all performance and power submissions in the v3.1 round across more than 120 system configurations (models, frameworks, hardware) while reducing development and maintenance costs.
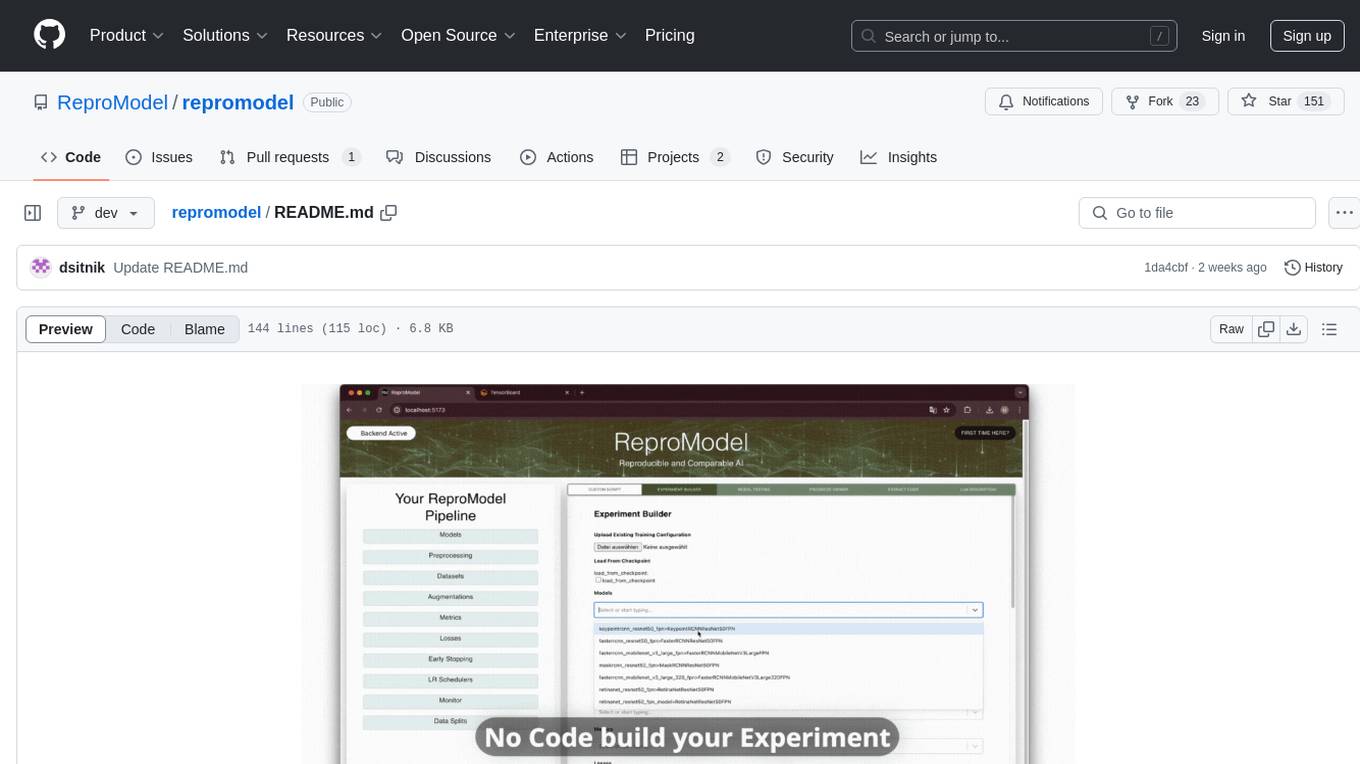
repromodel
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.
ChatAFL
ChatAFL is a protocol fuzzer guided by large language models (LLMs) that extracts machine-readable grammar for protocol mutation, increases message diversity, and breaks coverage plateaus. It integrates with ProfuzzBench for stateful fuzzing of network protocols, providing smooth integration. The artifact includes modified versions of AFLNet and ProfuzzBench, source code for ChatAFL with proposed strategies, and scripts for setup, execution, analysis, and cleanup. Users can analyze data, construct plots, examine LLM-generated grammars, enriched seeds, and state-stall responses, and reproduce results with downsized experiments. Customization options include modifying fuzzers, tuning parameters, adding new subjects, troubleshooting, and working on GPT-4. Limitations include interaction with OpenAI's Large Language Models and a hard limit of 150,000 tokens per minute.
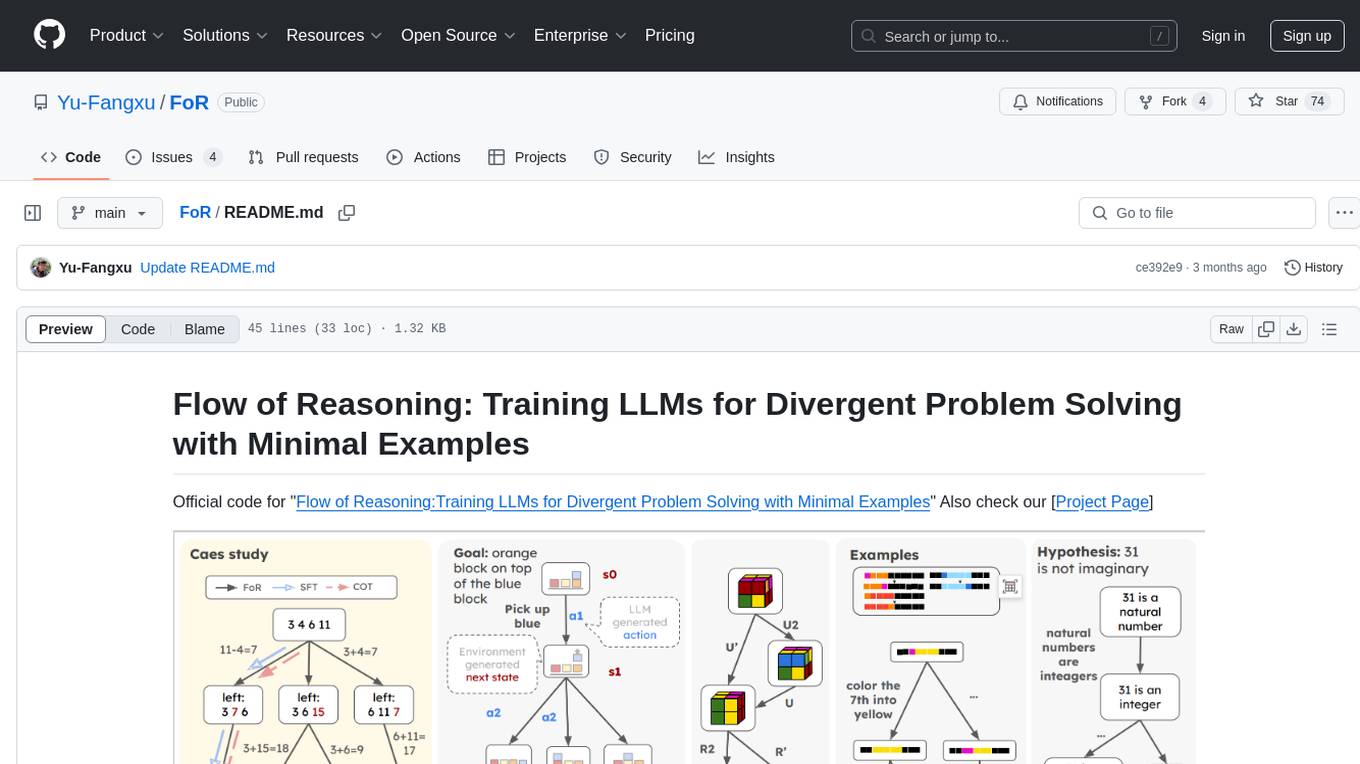
FoR
FoR is the official code repository for the 'Flow of Reasoning: Training LLMs for Divergent Problem Solving with Minimal Examples' project. It formulates multi-step reasoning tasks as a flow, involving designing reward functions, collecting trajectories, and training LLM policies with trajectory balance loss. The code provides tools for training and inference in a reproducible experiment environment using conda. Users can choose from 5 tasks to run, each with detailed instructions in the respective branches.
1 - OpenAI Gpts

Infinite Image Creator
キーワードやコンテクストに基づいて、詳細な画像プロンプトを時間軸、文化軸、感情軸、現実と虚構軸など、多角的な視点を取り入れて、あなたのビジョンを忠実に再現します。