
llm-adaptive-attacks
Jailbreaking Leading Safety-Aligned LLMs with Simple Adaptive Attacks [arXiv, Apr 2024]
Stars: 183
This repository contains code and results for jailbreaking leading safety-aligned LLMs with simple adaptive attacks. We show that even the most recent safety-aligned LLMs are not robust to simple adaptive jailbreaking attacks. We demonstrate how to successfully leverage access to logprobs for jailbreaking: we initially design an adversarial prompt template (sometimes adapted to the target LLM), and then we apply random search on a suffix to maximize the target logprob (e.g., of the token ``Sure''), potentially with multiple restarts. In this way, we achieve nearly 100% attack success rate---according to GPT-4 as a judge---on GPT-3.5/4, Llama-2-Chat-7B/13B/70B, Gemma-7B, and R2D2 from HarmBench that was adversarially trained against the GCG attack. We also show how to jailbreak all Claude models---that do not expose logprobs---via either a transfer or prefilling attack with 100% success rate. In addition, we show how to use random search on a restricted set of tokens for finding trojan strings in poisoned models---a task that shares many similarities with jailbreaking---which is the algorithm that brought us the first place in the SaTML'24 Trojan Detection Competition. The common theme behind these attacks is that adaptivity is crucial: different models are vulnerable to different prompting templates (e.g., R2D2 is very sensitive to in-context learning prompts), some models have unique vulnerabilities based on their APIs (e.g., prefilling for Claude), and in some settings it is crucial to restrict the token search space based on prior knowledge (e.g., for trojan detection).
README:
Maksym Andriushchenko (EPFL), Francesco Croce (EPFL), Nicolas Flammarion (EPFL)
Paper: https://arxiv.org/abs/2404.02151
- 20 September 2024: We've added code and logs for Claude Sonnet 3.5 (100% attack success rate with the prompt template + prefilling).
- 15 June 2024: We've added jailbreak artifacts for Nemotron-4-340B-Instruct (100% attack success rate with our prompt template, even without any random search or random restarts).
-
4 May 2024: We've exported most of our jailbreak artifacts (see the
jailbreak_artifactsfolder) in a convenient form following the JailbreakBench format. - 26 April 2024: We've added code and jailbreak artifacts for Phi-3-Mini (100% attack success rate).
- 21 April 2024: We've added code and jailbreak artifacts for Llama-3-8B (100% attack success rate).
- 20 April 2024: We've fixed some inconsistencies with the chat templates in this commit https://github.com/tml-epfl/llm-adaptive-attacks/commit/eeb7424248998d63dce5cc09d825a51a3842a127 from 20 April. Please use the latest version of the codebase to reproduce our results.
-
6 April 2024: We've discovered that FastChat doesn't insert anymore the system prompt for Llama-2-Chat in the latest version (
0.2.36). We note that we performed our experiments with version0.2.23where the system prompt is inserted. Thus, to reproduce our experiments, it's important to use the older version of FastChat (i.e.,pip install fschat==0.2.23). The full story is here: https://github.com/tml-epfl/llm-adaptive-attacks/issues/2 (thanks to Zhaorui Yang for reporting this issue).
We show that even the most recent safety-aligned LLMs are not robust to simple adaptive jailbreaking attacks. First, we demonstrate how to successfully leverage access to logprobs for jailbreaking: we initially design an adversarial prompt template (sometimes adapted to the target LLM), and then we apply random search on a suffix to maximize the target logprob (e.g., of the token ``Sure''), potentially with multiple restarts. In this way, we achieve nearly 100% attack success rate---according to GPT-4 as a judge---on GPT-3.5/4, Llama-2-Chat-7B/13B/70B, Gemma-7B, and R2D2 from HarmBench that was adversarially trained against the GCG attack. We also show how to jailbreak all Claude models---that do not expose logprobs---via either a transfer or prefilling attack with 100% success rate. In addition, we show how to use random search on a restricted set of tokens for finding trojan strings in poisoned models---a task that shares many similarities with jailbreaking---which is the algorithm that brought us the first place in the SaTML'24 Trojan Detection Competition. The common theme behind these attacks is that adaptivity is crucial: different models are vulnerable to different prompting templates (e.g., R2D2 is very sensitive to in-context learning prompts), some models have unique vulnerabilities based on their APIs (e.g., prefilling for Claude), and in some settings it is crucial to restrict the token search space based on prior knowledge (e.g., for trojan detection).
The table below summarizes our main evaluations:

The key element for query efficiency and high success rates for many models is self-transfer (i.e., reusing a successful adversarial string found by random search on a single behavior as an initialization for all behaviors - see the adv_init variable in main.py) as clearly evidenced by these plots:


This repository is partially based on the excellent repository from the PAIR paper (https://github.com/patrickrchao/JailbreakingLLMs).
To get started, install dependencies:
pip install fschat==0.2.23 transformers openai anthropic
For experiments on GPT and Claude models, make sure you have the API key stored in OPENAI_API_KEY and ANTHROPIC_API_KEY respectively. For this, you can run:
export OPENAI_API_KEY=[YOUR_API_KEY_HERE]
export ANTHROPIC_API_KEY=[YOUR_API_KEY_HERE]
Similarly, some HuggingFace models, like Llama-2-Chat, require an API key, which can be set in HF_TOKEN.
All experiments used in the paper are collected in the bash files in the experiments folder. There are 3 main files:
-
main.py: runs random search on all models with logprobs (HuggingFace and GPT models), -
main_claude_transfer.py: runs a transfer attack on Claude models with a single adversarial suffix obtained on GPT-4, -
main_claude_prefilling.py: runs a prefilling attack on Claude models.
The logs of all attacks can be found here in the attack_logs folder. The logs also include all intermediate and final adversarial suffixes.
For the code used to obtain the 1st place in the SatML'24 Trojan Detection Competition, see https://github.com/fra31/rlhf-trojan-competition-submission.
If you find this work useful in your own research, please consider citing it:
@article{andriushchenko2024jailbreaking,
title={Jailbreaking Leading Safety-Aligned LLMs with Simple Adaptive Attacks},
author={Andriushchenko, Maksym and Croce, Francesco and Flammarion, Nicolas},
journal={arXiv preprint arXiv:2404.02151},
year={2024}
}This codebase is released under MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-adaptive-attacks
Similar Open Source Tools
llm-adaptive-attacks
This repository contains code and results for jailbreaking leading safety-aligned LLMs with simple adaptive attacks. We show that even the most recent safety-aligned LLMs are not robust to simple adaptive jailbreaking attacks. We demonstrate how to successfully leverage access to logprobs for jailbreaking: we initially design an adversarial prompt template (sometimes adapted to the target LLM), and then we apply random search on a suffix to maximize the target logprob (e.g., of the token ``Sure''), potentially with multiple restarts. In this way, we achieve nearly 100% attack success rate---according to GPT-4 as a judge---on GPT-3.5/4, Llama-2-Chat-7B/13B/70B, Gemma-7B, and R2D2 from HarmBench that was adversarially trained against the GCG attack. We also show how to jailbreak all Claude models---that do not expose logprobs---via either a transfer or prefilling attack with 100% success rate. In addition, we show how to use random search on a restricted set of tokens for finding trojan strings in poisoned models---a task that shares many similarities with jailbreaking---which is the algorithm that brought us the first place in the SaTML'24 Trojan Detection Competition. The common theme behind these attacks is that adaptivity is crucial: different models are vulnerable to different prompting templates (e.g., R2D2 is very sensitive to in-context learning prompts), some models have unique vulnerabilities based on their APIs (e.g., prefilling for Claude), and in some settings it is crucial to restrict the token search space based on prior knowledge (e.g., for trojan detection).

FigStep
FigStep is a black-box jailbreaking algorithm against large vision-language models (VLMs). It feeds harmful instructions through the image channel and uses benign text prompts to induce VLMs to output contents that violate common AI safety policies. The tool highlights the vulnerability of VLMs to jailbreaking attacks, emphasizing the need for safety alignments between visual and textual modalities.

PromptAgent
PromptAgent is a repository for a novel automatic prompt optimization method that crafts expert-level prompts using language models. It provides a principled framework for prompt optimization by unifying prompt sampling and rewarding using MCTS algorithm. The tool supports different models like openai, palm, and huggingface models. Users can run PromptAgent to optimize prompts for specific tasks by strategically sampling model errors, generating error feedbacks, simulating future rewards, and searching for high-reward paths leading to expert prompts.
hackingBuddyGPT
hackingBuddyGPT is a framework for testing LLM-based agents for security testing. It aims to create common ground truth by creating common security testbeds and benchmarks, evaluating multiple LLMs and techniques against those, and publishing prototypes and findings as open-source/open-access reports. The initial focus is on evaluating the efficiency of LLMs for Linux privilege escalation attacks, but the framework is being expanded to evaluate the use of LLMs for web penetration-testing and web API testing. hackingBuddyGPT is released as open-source to level the playing field for blue teams against APTs that have access to more sophisticated resources.
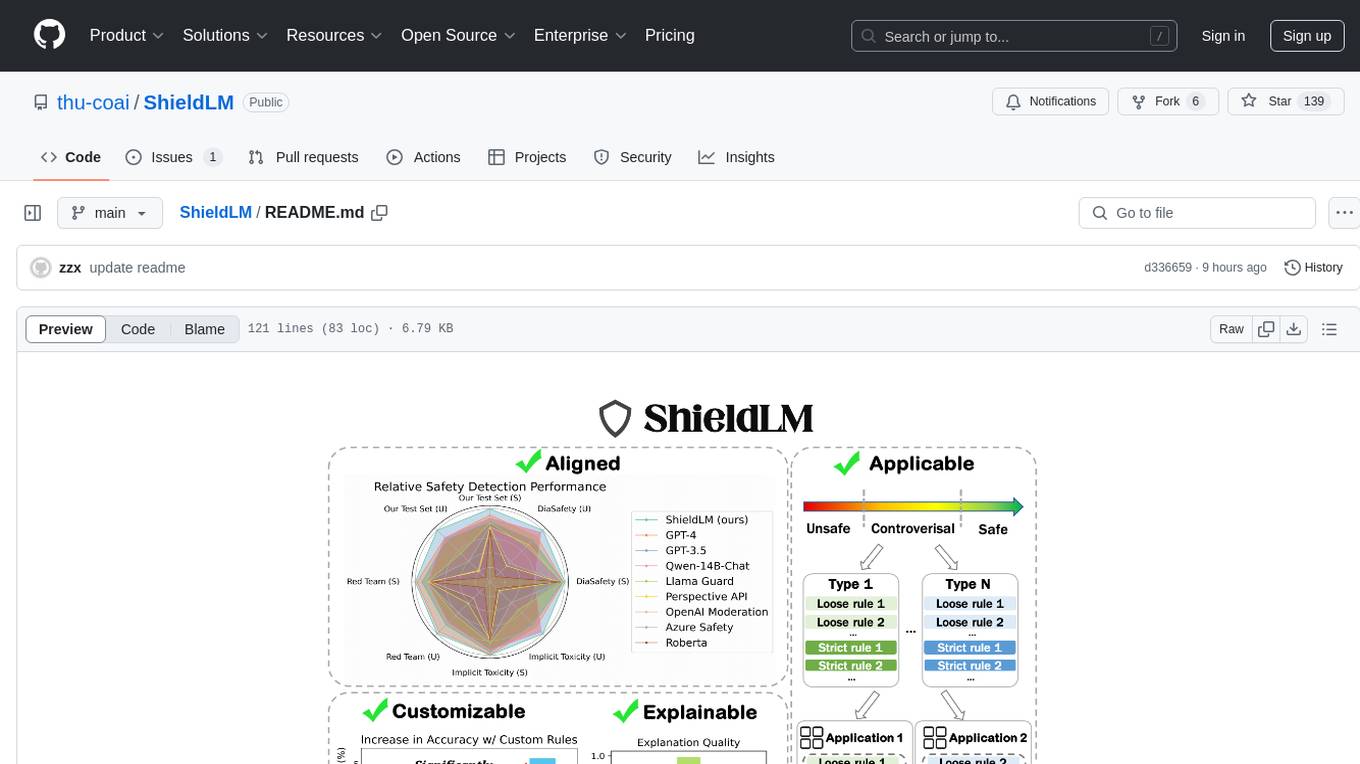
ShieldLM
ShieldLM is a bilingual safety detector designed to detect safety issues in LLMs' generations. It aligns with human safety standards, supports customizable detection rules, and provides explanations for decisions. Outperforming strong baselines, ShieldLM is impressive across 4 test sets.

TinyTroupe
TinyTroupe is an experimental Python library that leverages Large Language Models (LLMs) to simulate artificial agents called TinyPersons with specific personalities, interests, and goals in simulated environments. The focus is on understanding human behavior through convincing interactions and customizable personas for various applications like advertisement evaluation, software testing, data generation, project management, and brainstorming. The tool aims to enhance human imagination and provide insights for better decision-making in business and productivity scenarios.

AIlice
AIlice is a fully autonomous, general-purpose AI agent that aims to create a standalone artificial intelligence assistant, similar to JARVIS, based on the open-source LLM. AIlice achieves this goal by building a "text computer" that uses a Large Language Model (LLM) as its core processor. Currently, AIlice demonstrates proficiency in a range of tasks, including thematic research, coding, system management, literature reviews, and complex hybrid tasks that go beyond these basic capabilities. AIlice has reached near-perfect performance in everyday tasks using GPT-4 and is making strides towards practical application with the latest open-source models. We will ultimately achieve self-evolution of AI agents. That is, AI agents will autonomously build their own feature expansions and new types of agents, unleashing LLM's knowledge and reasoning capabilities into the real world seamlessly.

ezkl
EZKL is a library and command-line tool for doing inference for deep learning models and other computational graphs in a zk-snark (ZKML). It enables the following workflow: 1. Define a computational graph, for instance a neural network (but really any arbitrary set of operations), as you would normally in pytorch or tensorflow. 2. Export the final graph of operations as an .onnx file and some sample inputs to a .json file. 3. Point ezkl to the .onnx and .json files to generate a ZK-SNARK circuit with which you can prove statements such as: > "I ran this publicly available neural network on some private data and it produced this output" > "I ran my private neural network on some public data and it produced this output" > "I correctly ran this publicly available neural network on some public data and it produced this output" In the backend we use the collaboratively-developed Halo2 as a proof system. The generated proofs can then be verified with much less computational resources, including on-chain (with the Ethereum Virtual Machine), in a browser, or on a device.

aici
The Artificial Intelligence Controller Interface (AICI) lets you build Controllers that constrain and direct output of a Large Language Model (LLM) in real time. Controllers are flexible programs capable of implementing constrained decoding, dynamic editing of prompts and generated text, and coordinating execution across multiple, parallel generations. Controllers incorporate custom logic during the token-by-token decoding and maintain state during an LLM request. This allows diverse Controller strategies, from programmatic or query-based decoding to multi-agent conversations to execute efficiently in tight integration with the LLM itself.

ChainForge
ChainForge is a visual programming environment for battle-testing prompts to LLMs. It is geared towards early-stage, quick-and-dirty exploration of prompts, chat responses, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can: * Query multiple LLMs at once to test prompt ideas and variations quickly and effectively. * Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case. * Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings. * Hold multiple conversations at once across template parameters and chat models. Template not just prompts, but follow-up chat messages, and inspect and evaluate outputs at each turn of a chat conversation. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals. This is an open beta of Chainforge. We support model providers OpenAI, HuggingFace, Anthropic, Google PaLM2, Azure OpenAI endpoints, and Dalai-hosted models Alpaca and Llama. You can change the exact model and individual model settings. Visualization nodes support numeric and boolean evaluation metrics. ChainForge is built on ReactFlow and Flask.

EdgeChains
EdgeChains is an open-source chain-of-thought engineering framework tailored for Large Language Models (LLMs)- like OpenAI GPT, LLama2, Falcon, etc. - With a focus on enterprise-grade deployability and scalability. EdgeChains is specifically designed to **orchestrate** such applications. At EdgeChains, we take a unique approach to Generative AI - we think Generative AI is a deployment and configuration management challenge rather than a UI and library design pattern challenge. We build on top of a tech that has solved this problem in a different domain - Kubernetes Config Management - and bring that to Generative AI. Edgechains is built on top of jsonnet, originally built by Google based on their experience managing a vast amount of configuration code in the Borg infrastructure.
chatgpt-universe
ChatGPT is a large language model that can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in a conversational way. It is trained on a massive amount of text data, and it is able to understand and respond to a wide range of natural language prompts. Here are 5 jobs suitable for this tool, in lowercase letters: 1. content writer 2. chatbot assistant 3. language translator 4. creative writer 5. researcher
quimera
Quimera is an exploit-generator tool that utilizes large language models (LLMs) to uncover smart contract exploits in Foundry. It follows steps such as obtaining the smart contract's source code, creating a prompt for the exploit goal, generating or enhancing a Foundry test case, running the test, and analyzing the transaction trace for profitability. The tool is currently in an experimental prototype stage, focusing on optimizing settings, prompt creation, and exploring its capabilities. It has successfully rediscovered known exploits like APEMAGA, VISOR, FIRE, XAI, and Thunder-Loan using Gemini Pro 2.5 06-05.

llama-on-lambda
This project provides a proof of concept for deploying a scalable, serverless LLM Generative AI inference engine on AWS Lambda. It leverages the llama.cpp project to enable the usage of more accessible CPU and RAM configurations instead of limited and expensive GPU capabilities. By deploying a container with the llama.cpp converted models onto AWS Lambda, this project offers the advantages of scale, minimizing cost, and maximizing compute availability. The project includes AWS CDK code to create and deploy a Lambda function leveraging your model of choice, with a FastAPI frontend accessible from a Lambda URL. It is important to note that you will need ggml quantized versions of your model and model sizes under 6GB, as your inference RAM requirements cannot exceed 9GB or your Lambda function will fail.

serena
Serena is a powerful coding agent that integrates with existing LLMs to provide essential semantic code retrieval and editing tools. It is free to use and does not require API keys or subscriptions. Serena can be used for coding tasks such as analyzing, planning, and editing code directly on your codebase. It supports various programming languages and offers semantic code analysis capabilities through language servers. Serena can be integrated with different LLMs using the model context protocol (MCP) or Agno framework. The tool provides a range of functionalities for code retrieval, editing, and execution, making it a versatile coding assistant for developers.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.
For similar tasks
llm-adaptive-attacks
This repository contains code and results for jailbreaking leading safety-aligned LLMs with simple adaptive attacks. We show that even the most recent safety-aligned LLMs are not robust to simple adaptive jailbreaking attacks. We demonstrate how to successfully leverage access to logprobs for jailbreaking: we initially design an adversarial prompt template (sometimes adapted to the target LLM), and then we apply random search on a suffix to maximize the target logprob (e.g., of the token ``Sure''), potentially with multiple restarts. In this way, we achieve nearly 100% attack success rate---according to GPT-4 as a judge---on GPT-3.5/4, Llama-2-Chat-7B/13B/70B, Gemma-7B, and R2D2 from HarmBench that was adversarially trained against the GCG attack. We also show how to jailbreak all Claude models---that do not expose logprobs---via either a transfer or prefilling attack with 100% success rate. In addition, we show how to use random search on a restricted set of tokens for finding trojan strings in poisoned models---a task that shares many similarities with jailbreaking---which is the algorithm that brought us the first place in the SaTML'24 Trojan Detection Competition. The common theme behind these attacks is that adaptivity is crucial: different models are vulnerable to different prompting templates (e.g., R2D2 is very sensitive to in-context learning prompts), some models have unique vulnerabilities based on their APIs (e.g., prefilling for Claude), and in some settings it is crucial to restrict the token search space based on prior knowledge (e.g., for trojan detection).
LLMTSCS
LLMLight is a novel framework that employs Large Language Models (LLMs) as decision-making agents for Traffic Signal Control (TSC). The framework leverages the advanced generalization capabilities of LLMs to engage in a reasoning and decision-making process akin to human intuition for effective traffic control. LLMLight has been demonstrated to be remarkably effective, generalizable, and interpretable against various transportation-based and RL-based baselines on nine real-world and synthetic datasets.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.
For similar jobs
llm-adaptive-attacks
This repository contains code and results for jailbreaking leading safety-aligned LLMs with simple adaptive attacks. We show that even the most recent safety-aligned LLMs are not robust to simple adaptive jailbreaking attacks. We demonstrate how to successfully leverage access to logprobs for jailbreaking: we initially design an adversarial prompt template (sometimes adapted to the target LLM), and then we apply random search on a suffix to maximize the target logprob (e.g., of the token ``Sure''), potentially with multiple restarts. In this way, we achieve nearly 100% attack success rate---according to GPT-4 as a judge---on GPT-3.5/4, Llama-2-Chat-7B/13B/70B, Gemma-7B, and R2D2 from HarmBench that was adversarially trained against the GCG attack. We also show how to jailbreak all Claude models---that do not expose logprobs---via either a transfer or prefilling attack with 100% success rate. In addition, we show how to use random search on a restricted set of tokens for finding trojan strings in poisoned models---a task that shares many similarities with jailbreaking---which is the algorithm that brought us the first place in the SaTML'24 Trojan Detection Competition. The common theme behind these attacks is that adaptivity is crucial: different models are vulnerable to different prompting templates (e.g., R2D2 is very sensitive to in-context learning prompts), some models have unique vulnerabilities based on their APIs (e.g., prefilling for Claude), and in some settings it is crucial to restrict the token search space based on prior knowledge (e.g., for trojan detection).