
ShieldLM
ShieldLM: Empowering LLMs as Aligned, Customizable and Explainable Safety Detectors [EMNLP 2024 Findings]
Stars: 139
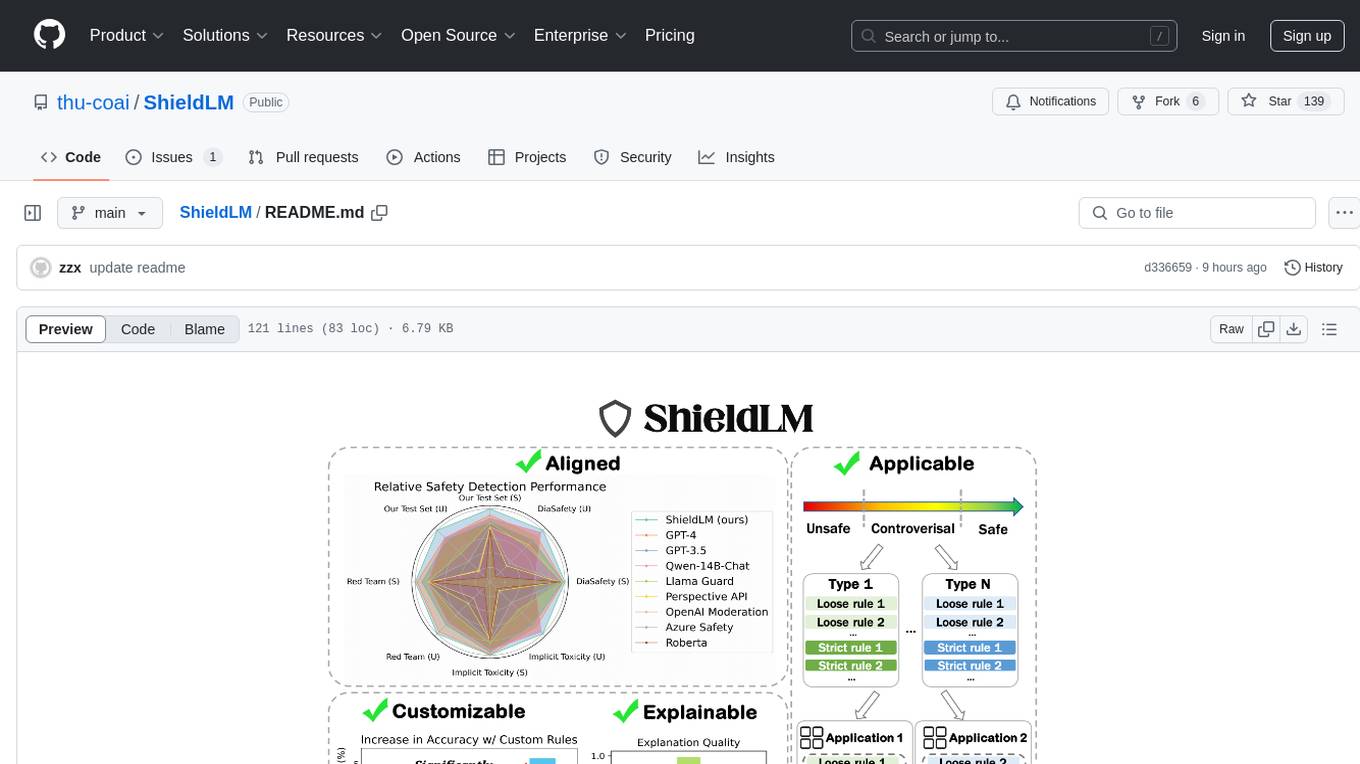
ShieldLM is a bilingual safety detector designed to detect safety issues in LLMs' generations. It aligns with human safety standards, supports customizable detection rules, and provides explanations for decisions. Outperforming strong baselines, ShieldLM is impressive across 4 test sets.
README:

This is the codebase for our paper "ShieldLM: Empowering LLMs as Aligned, Customizable and Explainable Safety Detectors".
ShieldLM is a bilingual (Chinese and English) safety detector that mainly aims to help to detect safety issues in LLMs' generations. It aligns with general human safety standards, supports fine-grained customizable detection rules, and provides explanations for its decisions. The overall performance of ShieldLM is impressive, outperforming strong baselines (e.g., GPT-4, Llama Guard 2 and Perspective API) across 4 ID and OOD test sets.
-
🎉
2024/09/29: Our paper has been accepted to EMNLP 2024 Findings! -
🎉
2024/06/25: We have open-sourced a portion of our training set, including 2,000 English samples and 2,000 Chinese samples. We also provide the related data processing and training code. -
🎉
2024/06/25: We have added the evaluation results of Llama Guard 2 and found that ShieldLM outperforms Llama Guard 2 on all four evaluated datasets.
You can directly use ShieldLM without the need to carefully craft prompts, and it is also flexible to provide custom detection rules, which could be useful to address controversial cases across various application scenarios.
To run ShieldLM:
pip install -r requirements.txt
bash infer_shieldlm.sh
You can define different parameters in infer_shieldlm.sh, such as the model checkpoint and the input/output path. Note that it is optional to provide custom rules. Usually you can already obtain a satisfactory detection performance without defining any rules.
If you want to obtain the prediction probabilities for three categories (i.e., safe, unsafe and controversial), please run:
bash get_probability.sh
We also provide an example code to automatically extract the predicted labels (0 for safe, 1 for unsafe, 2 for controversial) from ShieldLM's generations. Just run this:
bash extract_label.sh
We have released four versions of ShieldLM with 6B, 7B, 13B or 14B parameters, each initialized from different base model. You are free to choose any version based on considerations of inference costs and detection performance. The referenced detection performances for these ShieldLM variants are as follows:

We have open-sourced a portion of our training set, including 2,000 English samples and 2,000 Chinese samples. You can train your own safety detector with these samples. We provide the example training code for using Qwen-14B-Chat as the base model. Simply use the following commands:
cd train_code
python sft_data_process.py
bash run_decoder_hf.shAfter training for three epochs, use the checkpoint for inference. Note that you can also freely change the hyperparameters to obtain better performance. We used 4 A100 GPUs (80 GB each) to run the training.
- What is the detection scope of ShieldLM?
ShieldLM supports detecting a variety of unsafe contents, such as toxic and biased generations, physically and mentally harmful contents, illegal and unethical contents, contents related to privacy violation, contents that may lead to the loss of property and contents related to sensitive topics.
- What are the expected application scenarios of ShieldLM?
We list some application scenarios of ShieldLM:
-
Act as the evaluator for safety evaluation benchmarks (e.g., Safety-Prompts).
-
Compute the Attack Success Rate (ASR) for red teaming attacks.
-
Compute the Attack Success Rate (ASR) for jailbreaking attacks. (~93% accuracy for the first 1200 jailbreaking samples in GPTFuzz)
-
Provide feedbacks to improve the safety of LLMs.
- Besides detecting safety issues in LLMs' responses to queries, can ShieldLM detect safety issues in LLMs' generations (w/o queries)?
Yes. A simple way to implement this is to set the query to an empty string or some general comment such as "Say anything you want". Moreover, in some cases where the queries are very long and don't contribute to the detection results, you can drop the queries using the above methods, which might bring similar performance but less inference time.
- How to decrease the inference time?
If you only need to obtain the safety judgement, then you can skip the generation of analysis by setting max_new_tokens to a small value (e.g., 8).
- How to handle the samples predicted as controversial?
If there are only a small number of controversial samples, you can manually label these samples, simply set the labels to unsafe, or set the labels to safe or unsafe based on their prediction probabilities (see get_probability.sh for reference). Otherwise, you may need to write custom detection rules based on the controversial points. You can refer to the Appendix of our paper for examples of custom rules.
- How can I obtain the complete training data for ShieldLM?
Please contact [email protected] for details.
We present some evaluation results of ShieldLM here. Please refer to our paper for more detailed results.
The detection performance across 4 ID and OOD test sets:

The application experiment result (evaluating the safety of ChatGLM3-6B on the Safety-Prompts test set):

We develop ShieldLM for research purposes. If you want to use ShieldLM for different purposes, please make sure that you adhere to the license of the base models from which ShieldLM is initialized. The contents generated by ShieldLM do not reflect the authors' opinions.
@article{zhang2024shieldlm,
title={ShieldLM: Empowering LLMs as Aligned, Customizable and Explainable Safety Detectors},
author={Zhexin Zhang and Yida Lu and Jingyuan Ma and Di Zhang and Rui Li and Pei Ke and Hao Sun and Lei Sha and Zhifang Sui and Hongning Wang and Minlie Huang},
journal = {arXiv preprint},
year={2024}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ShieldLM
Similar Open Source Tools
ShieldLM
ShieldLM is a bilingual safety detector designed to detect safety issues in LLMs' generations. It aligns with human safety standards, supports customizable detection rules, and provides explanations for decisions. Outperforming strong baselines, ShieldLM is impressive across 4 test sets.

eureka-ml-insights
The Eureka ML Insights Framework is a repository containing code designed to help researchers and practitioners run reproducible evaluations of generative models efficiently. Users can define custom pipelines for data processing, inference, and evaluation, as well as utilize pre-defined evaluation pipelines for key benchmarks. The framework provides a structured approach to conducting experiments and analyzing model performance across various tasks and modalities.

PromptAgent
PromptAgent is a repository for a novel automatic prompt optimization method that crafts expert-level prompts using language models. It provides a principled framework for prompt optimization by unifying prompt sampling and rewarding using MCTS algorithm. The tool supports different models like openai, palm, and huggingface models. Users can run PromptAgent to optimize prompts for specific tasks by strategically sampling model errors, generating error feedbacks, simulating future rewards, and searching for high-reward paths leading to expert prompts.

FigStep
FigStep is a black-box jailbreaking algorithm against large vision-language models (VLMs). It feeds harmful instructions through the image channel and uses benign text prompts to induce VLMs to output contents that violate common AI safety policies. The tool highlights the vulnerability of VLMs to jailbreaking attacks, emphasizing the need for safety alignments between visual and textual modalities.
SciMLBenchmarks.jl
SciMLBenchmarks.jl holds webpages, pdfs, and notebooks showing the benchmarks for the SciML Scientific Machine Learning Software ecosystem, including: * Benchmarks of equation solver implementations * Speed and robustness comparisons of methods for parameter estimation / inverse problems * Training universal differential equations (and subsets like neural ODEs) * Training of physics-informed neural networks (PINNs) * Surrogate comparisons, including radial basis functions, neural operators (DeepONets, Fourier Neural Operators), and more The SciML Bench suite is made to be a comprehensive open source benchmark from the ground up, covering the methods of computational science and scientific computing all the way to AI for science.
llm-adaptive-attacks
This repository contains code and results for jailbreaking leading safety-aligned LLMs with simple adaptive attacks. We show that even the most recent safety-aligned LLMs are not robust to simple adaptive jailbreaking attacks. We demonstrate how to successfully leverage access to logprobs for jailbreaking: we initially design an adversarial prompt template (sometimes adapted to the target LLM), and then we apply random search on a suffix to maximize the target logprob (e.g., of the token ``Sure''), potentially with multiple restarts. In this way, we achieve nearly 100% attack success rate---according to GPT-4 as a judge---on GPT-3.5/4, Llama-2-Chat-7B/13B/70B, Gemma-7B, and R2D2 from HarmBench that was adversarially trained against the GCG attack. We also show how to jailbreak all Claude models---that do not expose logprobs---via either a transfer or prefilling attack with 100% success rate. In addition, we show how to use random search on a restricted set of tokens for finding trojan strings in poisoned models---a task that shares many similarities with jailbreaking---which is the algorithm that brought us the first place in the SaTML'24 Trojan Detection Competition. The common theme behind these attacks is that adaptivity is crucial: different models are vulnerable to different prompting templates (e.g., R2D2 is very sensitive to in-context learning prompts), some models have unique vulnerabilities based on their APIs (e.g., prefilling for Claude), and in some settings it is crucial to restrict the token search space based on prior knowledge (e.g., for trojan detection).
Electronic-Component-Sorter
The Electronic Component Classifier is a project that uses machine learning and artificial intelligence to automate the identification and classification of electrical and electronic components. It features component classification into seven classes, user-friendly design, and integration with Flask for a user-friendly interface. The project aims to reduce human error in component identification, make the process safer and more reliable, and potentially help visually impaired individuals in identifying electronic components.

AIlice
AIlice is a fully autonomous, general-purpose AI agent that aims to create a standalone artificial intelligence assistant, similar to JARVIS, based on the open-source LLM. AIlice achieves this goal by building a "text computer" that uses a Large Language Model (LLM) as its core processor. Currently, AIlice demonstrates proficiency in a range of tasks, including thematic research, coding, system management, literature reviews, and complex hybrid tasks that go beyond these basic capabilities. AIlice has reached near-perfect performance in everyday tasks using GPT-4 and is making strides towards practical application with the latest open-source models. We will ultimately achieve self-evolution of AI agents. That is, AI agents will autonomously build their own feature expansions and new types of agents, unleashing LLM's knowledge and reasoning capabilities into the real world seamlessly.

ChainForge
ChainForge is a visual programming environment for battle-testing prompts to LLMs. It is geared towards early-stage, quick-and-dirty exploration of prompts, chat responses, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can: * Query multiple LLMs at once to test prompt ideas and variations quickly and effectively. * Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case. * Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings. * Hold multiple conversations at once across template parameters and chat models. Template not just prompts, but follow-up chat messages, and inspect and evaluate outputs at each turn of a chat conversation. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals. This is an open beta of Chainforge. We support model providers OpenAI, HuggingFace, Anthropic, Google PaLM2, Azure OpenAI endpoints, and Dalai-hosted models Alpaca and Llama. You can change the exact model and individual model settings. Visualization nodes support numeric and boolean evaluation metrics. ChainForge is built on ReactFlow and Flask.

modelbench
ModelBench is a tool for running safety benchmarks against AI models and generating detailed reports. It is part of the MLCommons project and is designed as a proof of concept to aggregate measures, relate them to specific harms, create benchmarks, and produce reports. The tool requires LlamaGuard for evaluating responses and a TogetherAI account for running benchmarks. Users can install ModelBench from GitHub or PyPI, run tests using Poetry, and create benchmarks by providing necessary API keys. The tool generates static HTML pages displaying benchmark scores and allows users to dump raw scores and manage cache for faster runs. ModelBench is aimed at enabling users to test their own models and create tests and benchmarks.
LLM-RGB
LLM-RGB is a repository containing a collection of detailed test cases designed to evaluate the reasoning and generation capabilities of Language Learning Models (LLMs) in complex scenarios. The benchmark assesses LLMs' performance in understanding context, complying with instructions, and handling challenges like long context lengths, multi-step reasoning, and specific response formats. Each test case evaluates an LLM's output based on context length difficulty, reasoning depth difficulty, and instruction compliance difficulty, with a final score calculated for each test case. The repository provides a score table, evaluation details, and quick start guide for running evaluations using promptfoo testing tools.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.

TinyTroupe
TinyTroupe is an experimental Python library that leverages Large Language Models (LLMs) to simulate artificial agents called TinyPersons with specific personalities, interests, and goals in simulated environments. The focus is on understanding human behavior through convincing interactions and customizable personas for various applications like advertisement evaluation, software testing, data generation, project management, and brainstorming. The tool aims to enhance human imagination and provide insights for better decision-making in business and productivity scenarios.

llama3_interpretability_sae
This project focuses on implementing Sparse Autoencoders (SAEs) for mechanistic interpretability in Large Language Models (LLMs) like Llama 3.2-3B. The SAEs aim to untangle superimposed representations in LLMs into separate, interpretable features for each neuron activation. The project provides an end-to-end pipeline for capturing training data, training the SAEs, analyzing learned features, and verifying results experimentally. It includes comprehensive logging, visualization, and checkpointing of SAE training, interpretability analysis tools, and a pure PyTorch implementation of Llama 3.1/3.2 chat and text completion. The project is designed for scalability, efficiency, and maintainability.

LLMonFHIR
LLMonFHIR is an iOS application that utilizes large language models (LLMs) to interpret and provide context around patient data in the Fast Healthcare Interoperability Resources (FHIR) format. It connects to the OpenAI GPT API to analyze FHIR resources, supports multiple languages, and allows users to interact with their health data stored in the Apple Health app. The app aims to simplify complex health records, provide insights, and facilitate deeper understanding through a conversational interface. However, it is an experimental app for informational purposes only and should not be used as a substitute for professional medical advice. Users are advised to verify information provided by AI models and consult healthcare professionals for personalized advice.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.
For similar tasks
ShieldLM
ShieldLM is a bilingual safety detector designed to detect safety issues in LLMs' generations. It aligns with human safety standards, supports customizable detection rules, and provides explanations for decisions. Outperforming strong baselines, ShieldLM is impressive across 4 test sets.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.