
ChainForge
An open-source visual programming environment for battle-testing prompts to LLMs.
Stars: 2763

ChainForge is a visual programming environment for battle-testing prompts to LLMs. It is geared towards early-stage, quick-and-dirty exploration of prompts, chat responses, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can: * Query multiple LLMs at once to test prompt ideas and variations quickly and effectively. * Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case. * Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings. * Hold multiple conversations at once across template parameters and chat models. Template not just prompts, but follow-up chat messages, and inspect and evaluate outputs at each turn of a chat conversation. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals. This is an open beta of Chainforge. We support model providers OpenAI, HuggingFace, Anthropic, Google PaLM2, Azure OpenAI endpoints, and Dalai-hosted models Alpaca and Llama. You can change the exact model and individual model settings. Visualization nodes support numeric and boolean evaluation metrics. ChainForge is built on ReactFlow and Flask.
README:
An open-source visual environment for battle-testing prompts to LLMs.

ChainForge is a data flow prompt engineering environment for analyzing and evaluating LLM responses. It enables rapid-fire, quick-and-dirty comparison of prompts, models, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can:
- Query multiple LLMs at once to test prompt ideas and variations quickly and effectively.
- Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case.
- Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings.
- Use AI to streamline this entire process: Create synthetic tables and input examples with built-in genAI features, or supercharge writing evals by prompting a model to give you starter code.
Read the docs to learn more. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals.
ChainForge is built on ReactFlow and Flask.
For user-curated resources and learning materials, check out the 🌟Awesome ChainForge repo!
- 👉 Documentation 📖
- Installation
- Example Experiments
- Share with Others
- Features (see the docs for more comprehensive info)
- Development and How to Cite
You can install ChainForge locally, or try it out on the web at https://chainforge.ai/play/. The web version of ChainForge has a limited feature set. In a locally installed version you can load API keys automatically from environment variables, write Python code to evaluate LLM responses, or query locally-run models hosted via Ollama.
To install Chainforge on your machine, make sure you have Python 3.8 or higher, then run
pip install chainforgeOnce installed, do
chainforge serveOpen localhost:8000 in a Google Chrome, Firefox, Microsoft Edge, or Brave browser.
You can set your API keys by clicking the Settings icon in the top-right corner. If you prefer to not worry about this everytime you open ChainForge, we highly recommend that save your OpenAI, Anthropic, Google, etc API keys and/or Amazon AWS credentials to your local environment. For more details, see the How to Install.
You can use our Dockerfile to run ChainForge locally using Docker Desktop:
-
Build the
Dockerfile:docker build -t chainforge . -
Run the image:
docker run -p 8000:8000 chainforge
Now you can open the browser of your choice and open http://127.0.0.1:8000.
- OpenAI
- Anthropic
- Google (Gemini, PaLM2)
- DeepSeek
- HuggingFace (Inference and Endpoints)
- Together.ai
- Ollama API (locally-hosted models)
- Microsoft Azure OpenAI Endpoints
- Aleph Alpha
- Amazon Bedrock-hosted on-demand inference, including Anthropic Claude 3
- ...and any other provider through custom provider scripts!
We've prepared many example flows to give you a sense of what's possible with Chainforge.
Click the "Example Flows" button on the top-right corner and select one. Here is a basic comparison example, plotting the length of responses across different models and arguments for the prompt parameter {game}:
You can also conduct ground truth evaluations using Tabular Data nodes. For instance, we can compare each LLM's ability to answer math problems by comparing each response to the expected answer:
Just import a dataset, hook it up to a template variable in a Prompt Node, and press run.
Compare across models and prompt variables with an interactive response inspector, including a formatted table and exportable data:
The key power of ChainForge lies in combinatorial power: ChainForge takes the cross product of inputs to prompt templates, meaning you can produce every combination of input values. This is incredibly effective at sending off hundreds of queries at once to verify model behavior more robustly than one-off prompting.
Here's a tutorial to get started comparing across prompt templates.
The web version of ChainForge (https://chainforge.ai/play/) includes a Share button.
Simply click Share to generate a unique link for your flow and copy it to your clipboard:
For instance, here's a experiment I made that tries to get an LLM to reveal a secret key: https://chainforge.ai/play/?f=28puvwc788bog
Note To prevent abuse, you can only share up to 10 flows at a time, and each flow must be <5MB after compression. If you share more than 10 flows, the oldest link will break, so make sure to always Export important flows to
cforgefiles, and use Share to only pass data ephemerally.
For finer details about the features of specific nodes, check out the List of Nodes.
A key goal of ChainForge is facilitating comparison and evaluation of prompts and models. Overall, you can:
- Compare across prompts and prompt parameters: Find the best set of prompts that maximizes your eval target metrics (e.g., lowest code error rate). Or, see how changing parameters in a prompt template affects the quality of responses.
- Compare across models: Compare responses for every prompt across models and different model settings, to find the best model for your use case.
The features that enable this area:
- Prompt permutations: Setup a prompt template and feed it variations of input variables. ChainForge will prompt all selected LLMs with all possible permutations of the input prompt, so that you can get a better sense of prompt quality. You can also chain prompt templates at arbitrary depth (e.g., to compare templates).
- Model settings: Change the settings of supported models, and compare across settings. For instance, you can measure the impact of a system message on ChatGPT by adding several ChatGPT models, changing individual settings, and nicknaming each one. ChainForge will send out queries to each version of the model.
- Evaluation nodes: Probe LLM responses in a chain and test them (classically) for some desired behavior. At a basic level, this is Python script based. We plan to add preset evaluator nodes for common use cases in the near future (e.g., name-entity recognition). Note that you can also chain LLM responses into prompt templates to help evaluate outputs cheaply before more extensive evaluation methods.
- Visualization nodes: Visualize evaluation results on plots like grouped box-and-whisker (for numeric metrics) and histograms (for boolean metrics). Currently we only support numeric and boolean metrics. We aim to provide users more control and options for plotting in the future.
- Chat turns: Go beyond prompts and template follow-up chat messages, just like prompts. You can test how the wording of the user's query might change an LLM's output, or compare quality of later responses across multiple chat models (or the same chat model with different settings!).
Alongside built-in gen AI features 🪄💫 like synthetic data generation, prompt engineering is accelerated: you can compare prompts and model performance sometimes without needing to write a single line of code, speeding up the process of iteration and discovery tenfold.
We've also found that some users simply want to use ChainForge to make tons of parametrized queries to LLMs (e.g., chaining prompt templates into prompt templates), possibly score them, and then output the results to a spreadsheet (Excel xlsx). To do this, attach an Inspect node to the output of a Prompt node and click Export Data.
For more specific details, see our documentation.
ChainForge was created by Ian Arawjo, a postdoctoral scholar in Harvard HCI's Glassman Lab with support from the Harvard HCI community. Collaborators include PhD students Priyan Vaithilingam and Chelse Swoopes, Harvard undergraduate Sean Yang, and faculty members Elena Glassman and Martin Wattenberg. Additional collaborators include UC Berkeley PhD student Shreya Shankar and Université de Montréal undergraduate Cassandre Hamel.
This work was partially funded by the NSF grants IIS-2107391, IIS-2040880, and IIS-1955699. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
We provide ongoing releases of this tool in the hopes that others find it useful for their projects.
ChainForge is meant to be general-purpose, and is not developed for a specific API or LLM back-end. Our ultimate goal is integration into other tools for the systematic evaluation and auditing of LLMs. We hope to help others who are developing prompt-analysis flows in LLMs, or otherwise auditing LLM outputs. This project was inspired by own our use case, but also shares some comraderie with two related (closed-source) research projects, both led by Sherry Wu:
- "PromptChainer: Chaining Large Language Model Prompts through Visual Programming" (Wu et al., CHI ’22 LBW) Video
- "AI Chains: Transparent and Controllable Human-AI Interaction by Chaining Large Language Model Prompts" (Wu et al., CHI ’22)
Unlike these projects, we are focusing on supporting evaluation across prompts, prompt parameters, and models.
We welcome open-source collaborators. If you want to report a bug or request a feature, open an Issue. We also encourage users to implement the requested feature / bug fix and submit a Pull Request.
If you use ChainForge for research purposes, whether by building upon the source code or investigating LLM behavior using the tool, we ask that you cite our CHI research paper in any related publications. The BibTeX you can use is:
@inproceedings{arawjo2024chainforge,
title={ChainForge: A Visual Toolkit for Prompt Engineering and LLM Hypothesis Testing},
author={Arawjo, Ian and Swoopes, Chelse and Vaithilingam, Priyan and Wattenberg, Martin and Glassman, Elena L},
booktitle={Proceedings of the CHI Conference on Human Factors in Computing Systems},
pages={1--18},
year={2024}
}ChainForge is released under the MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ChainForge
Similar Open Source Tools
ChainForge
ChainForge is a visual programming environment for battle-testing prompts to LLMs. It is geared towards early-stage, quick-and-dirty exploration of prompts, chat responses, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can: * Query multiple LLMs at once to test prompt ideas and variations quickly and effectively. * Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case. * Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings. * Hold multiple conversations at once across template parameters and chat models. Template not just prompts, but follow-up chat messages, and inspect and evaluate outputs at each turn of a chat conversation. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals. This is an open beta of Chainforge. We support model providers OpenAI, HuggingFace, Anthropic, Google PaLM2, Azure OpenAI endpoints, and Dalai-hosted models Alpaca and Llama. You can change the exact model and individual model settings. Visualization nodes support numeric and boolean evaluation metrics. ChainForge is built on ReactFlow and Flask.
ask-astro
Ask Astro is an open-source reference implementation of Andreessen Horowitz's LLM Application Architecture built by Astronomer. It provides an end-to-end example of a Q&A LLM application used to answer questions about Apache Airflow® and Astronomer. Ask Astro includes Airflow DAGs for data ingestion, an API for business logic, a Slack bot, a public UI, and DAGs for processing user feedback. The tool is divided into data retrieval & embedding, prompt orchestration, and feedback loops.

AIlice
AIlice is a fully autonomous, general-purpose AI agent that aims to create a standalone artificial intelligence assistant, similar to JARVIS, based on the open-source LLM. AIlice achieves this goal by building a "text computer" that uses a Large Language Model (LLM) as its core processor. Currently, AIlice demonstrates proficiency in a range of tasks, including thematic research, coding, system management, literature reviews, and complex hybrid tasks that go beyond these basic capabilities. AIlice has reached near-perfect performance in everyday tasks using GPT-4 and is making strides towards practical application with the latest open-source models. We will ultimately achieve self-evolution of AI agents. That is, AI agents will autonomously build their own feature expansions and new types of agents, unleashing LLM's knowledge and reasoning capabilities into the real world seamlessly.

PromptAgent
PromptAgent is a repository for a novel automatic prompt optimization method that crafts expert-level prompts using language models. It provides a principled framework for prompt optimization by unifying prompt sampling and rewarding using MCTS algorithm. The tool supports different models like openai, palm, and huggingface models. Users can run PromptAgent to optimize prompts for specific tasks by strategically sampling model errors, generating error feedbacks, simulating future rewards, and searching for high-reward paths leading to expert prompts.

TinyTroupe
TinyTroupe is an experimental Python library that leverages Large Language Models (LLMs) to simulate artificial agents called TinyPersons with specific personalities, interests, and goals in simulated environments. The focus is on understanding human behavior through convincing interactions and customizable personas for various applications like advertisement evaluation, software testing, data generation, project management, and brainstorming. The tool aims to enhance human imagination and provide insights for better decision-making in business and productivity scenarios.
Instruct2Act
Instruct2Act is a framework that utilizes Large Language Models to map multi-modal instructions to sequential actions for robotic manipulation tasks. It generates Python programs using the LLM model for perception, planning, and action. The framework leverages foundation models like SAM and CLIP to convert high-level instructions into policy codes, accommodating various instruction modalities and task demands. Instruct2Act has been validated on robotic tasks in tabletop manipulation domains, outperforming learning-based policies in several tasks.

Robyn
Robyn is an experimental, semi-automated and open-sourced Marketing Mix Modeling (MMM) package from Meta Marketing Science. It uses various machine learning techniques to define media channel efficiency and effectivity, explore adstock rates and saturation curves. Built for granular datasets with many independent variables, especially suitable for digital and direct response advertisers with rich data sources. Aiming to democratize MMM, make it accessible for advertisers of all sizes, and contribute to the measurement landscape.

WilmerAI
WilmerAI is a middleware system designed to process prompts before sending them to Large Language Models (LLMs). It categorizes prompts, routes them to appropriate workflows, and generates manageable prompts for local models. It acts as an intermediary between the user interface and LLM APIs, supporting multiple backend LLMs simultaneously. WilmerAI provides API endpoints compatible with OpenAI API, supports prompt templates, and offers flexible connections to various LLM APIs. The project is under heavy development and may contain bugs or incomplete code.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.
AutoGroq
AutoGroq is a revolutionary tool that dynamically generates tailored teams of AI agents based on project requirements, eliminating manual configuration. It enables users to effortlessly tackle questions, problems, and projects by creating expert agents, workflows, and skillsets with ease and efficiency. With features like natural conversation flow, code snippet extraction, and support for multiple language models, AutoGroq offers a seamless and intuitive AI assistant experience for developers and users.

serena
Serena is a powerful coding agent that integrates with existing LLMs to provide essential semantic code retrieval and editing tools. It is free to use and does not require API keys or subscriptions. Serena can be used for coding tasks such as analyzing, planning, and editing code directly on your codebase. It supports various programming languages and offers semantic code analysis capabilities through language servers. Serena can be integrated with different LLMs using the model context protocol (MCP) or Agno framework. The tool provides a range of functionalities for code retrieval, editing, and execution, making it a versatile coding assistant for developers.
feedgen
FeedGen is an open-source tool that uses Google Cloud's state-of-the-art Large Language Models (LLMs) to improve product titles, generate more comprehensive descriptions, and fill missing attributes in product feeds. It helps merchants and advertisers surface and fix quality issues in their feeds using Generative AI in a simple and configurable way. The tool relies on GCP's Vertex AI API to provide both zero-shot and few-shot inference capabilities on GCP's foundational LLMs. With few-shot prompting, users can customize the model's responses towards their own data, achieving higher quality and more consistent output. FeedGen is an Apps Script based application that runs as an HTML sidebar in Google Sheets, allowing users to optimize their feeds with ease.

pydantic-ai
PydanticAI is a Python agent framework designed to make it less painful to build production grade applications with Generative AI. It is built by the Pydantic Team and supports various AI models like OpenAI, Anthropic, Gemini, Ollama, Groq, and Mistral. PydanticAI seamlessly integrates with Pydantic Logfire for real-time debugging, performance monitoring, and behavior tracking of LLM-powered applications. It is type-safe, Python-centric, and offers structured responses, dependency injection system, and streamed responses. PydanticAI is in early beta, offering a Python-centric design to apply standard Python best practices in AI-driven projects.
materialize
Materialize is a real-time data integration platform that creates and continually updates consistent views of transactional data from across your organization. Its SQL interface democratizes the ability to serve and access live data. Materialize can be deployed anywhere your infrastructure runs. Use Materialize to deliver fresh context for AI/RAG pipelines, power operational dashboards, and create more dynamic customer experiences without building time-consuming custom data pipelines. Materialize focuses on providing correct and consistent answers with minimal latency, and does not ask you to accept either approximate answers or eventual consistency. Materialize answers a query with the correct result on a specific version of your data. Materialize recasts SQL queries as dataflows, which can react efficiently to changes in your data as they happen. Materialize supports a large fraction of PostgreSQL features and is actively expanding support for more built-in PostgreSQL functions. Materialize can read data directly from PostgreSQL or MySQL replication stream, from Kafka, or from SaaS applications via webhooks. Once data is in, define views and perform reads via the PostgreSQL protocol. Materialize supports a comprehensive variety of SQL features, all using the PostgreSQL dialect and protocol. Materialize can incrementally maintain views in the presence of arbitrary inserts, updates, and deletes. Materialize supports recursion that enables incrementally updating tree and graph structures. Materialize is primarily written in Rust.

LLMonFHIR
LLMonFHIR is an iOS application that utilizes large language models (LLMs) to interpret and provide context around patient data in the Fast Healthcare Interoperability Resources (FHIR) format. It connects to the OpenAI GPT API to analyze FHIR resources, supports multiple languages, and allows users to interact with their health data stored in the Apple Health app. The app aims to simplify complex health records, provide insights, and facilitate deeper understanding through a conversational interface. However, it is an experimental app for informational purposes only and should not be used as a substitute for professional medical advice. Users are advised to verify information provided by AI models and consult healthcare professionals for personalized advice.
Smart-Connections-Visualizer
The Smart Connections Visualizer Plugin is a tool designed to enhance note-taking and information visualization by creating dynamic force-directed graphs that represent connections between notes or excerpts. Users can customize visualization settings, preview notes, and interact with the graph to explore relationships and insights within their notes. The plugin aims to revolutionize communication with AI and improve decision-making processes by visualizing complex information in a more intuitive and context-driven manner.
For similar tasks

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!
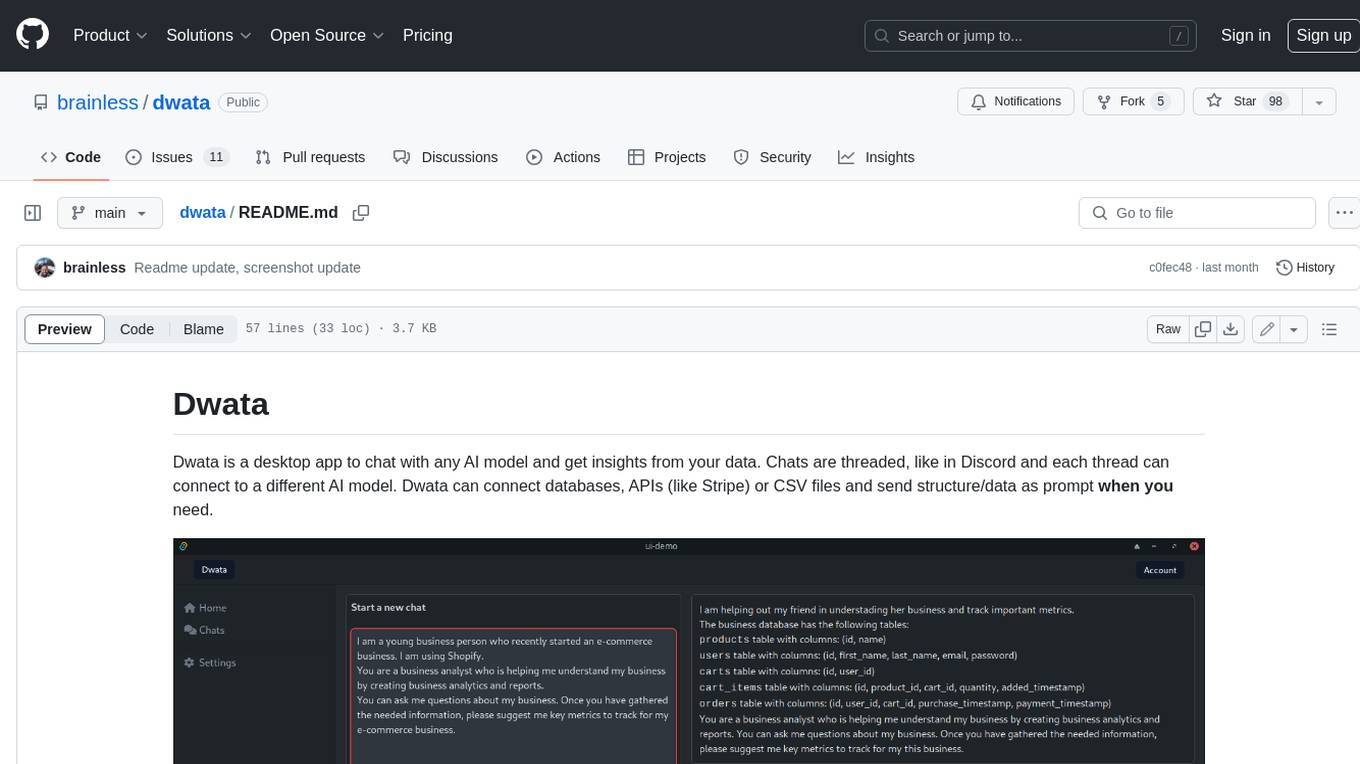
dwata
Dwata is a desktop application that allows users to chat with any AI model and gain insights from their data. Chats are organized into threads, similar to Discord, with each thread connecting to a different AI model. Dwata can connect to databases, APIs (such as Stripe), or CSV files and send structured data as prompts when needed. The AI's response will often include SQL or Python code, which can be used to extract the desired insights. Dwata can validate AI-generated SQL to ensure that the tables and columns referenced are correct and can execute queries against the database from within the application. Python code (typically using Pandas) can also be executed from within Dwata, although this feature is still in development. Dwata supports a range of AI models, including OpenAI's GPT-4, GPT-4 Turbo, and GPT-3.5 Turbo; Groq's LLaMA2-70b and Mixtral-8x7b; Phind's Phind-34B and Phind-70B; Anthropic's Claude; and Ollama's Llama 2, Mistral, and Phi-2 Gemma. Dwata can compare chats from different models, allowing users to see the responses of multiple models to the same prompts. Dwata can connect to various data sources, including databases (PostgreSQL, MySQL, MongoDB), SaaS products (Stripe, Shopify), CSV files/folders, and email (IMAP). The desktop application does not collect any private or business data without the user's explicit consent.

ollama-grid-search
A Rust based tool to evaluate LLM models, prompts and model params. It automates the process of selecting the best model parameters, given an LLM model and a prompt, iterating over the possible combinations and letting the user visually inspect the results. The tool assumes the user has Ollama installed and serving endpoints, either in `localhost` or in a remote server. Key features include: * Automatically fetches models from local or remote Ollama servers * Iterates over different models and params to generate inferences * A/B test prompts on different models simultaneously * Allows multiple iterations for each combination of parameters * Makes synchronous inference calls to avoid spamming servers * Optionally outputs inference parameters and response metadata (inference time, tokens and tokens/s) * Refetching of individual inference calls * Model selection can be filtered by name * List experiments which can be downloaded in JSON format * Configurable inference timeout * Custom default parameters and system prompts can be defined in settings
eval-scope
Eval-Scope is a framework for evaluating and improving large language models (LLMs). It provides a set of commonly used test datasets, metrics, and a unified model interface for generating and evaluating LLM responses. Eval-Scope also includes an automatic evaluator that can score objective questions and use expert models to evaluate complex tasks. Additionally, it offers a visual report generator, an arena mode for comparing multiple models, and a variety of other features to support LLM evaluation and development.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.
PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.