
eval-scope
A streamlined and customizable framework for efficient large model evaluation and performance benchmarking
Stars: 120
Eval-Scope is a framework for evaluating and improving large language models (LLMs). It provides a set of commonly used test datasets, metrics, and a unified model interface for generating and evaluating LLM responses. Eval-Scope also includes an automatic evaluator that can score objective questions and use expert models to evaluate complex tasks. Additionally, it offers a visual report generator, an arena mode for comparing multiple models, and a variety of other features to support LLM evaluation and development.
README:
English | 简体中文

- Introduction
- News
- Installation
- Quick Start
- Dataset List
- Leaderboard
- Experiments and Results
- Model Serving Performance Evaluation
Large Language Model (LLMs) evaluation has become a critical process for assessing and improving LLMs. To better support the evaluation of large models, we propose the Eval-Scope framework, which includes the following components and features:
- Pre-configured common benchmark datasets, including: MMLU, CMMLU, C-Eval, GSM8K, ARC, HellaSwag, TruthfulQA, MATH, HumanEval, etc.
- Implementation of common evaluation metrics
- Unified model integration, compatible with the generate and chat interfaces of multiple model series
- Automatic evaluation (evaluator):
- Automatic evaluation for objective questions
- Implementation of complex task evaluation using expert models
- Reports of evaluation generating
- Arena mode
- Visualization tools
- Model Inference Performance Evaluation Tutorial
- Support for OpenCompass as an Evaluation Backend, featuring advanced encapsulation and task simplification to easily submit tasks to OpenCompass for evaluation.
- Supports VLMEvalKit as the evaluation backend. It initiates VLMEvalKit's multimodal evaluation tasks through Eval-Scope, supporting various multimodal models and datasets.
- Full pipeline support: Seamlessly integrate with SWIFT to easily train and deploy model services, initiate evaluation tasks, view evaluation reports, and achieve an end-to-end large model development process.
Features
- Lightweight, minimizing unnecessary abstractions and configurations
- Easy to customize
- New datasets can be integrated by simply implementing a single class
- Models can be hosted on ModelScope, and evaluations can be initiated with just a model id
- Supports deployment of locally hosted models
- Visualization of evaluation reports
- Rich evaluation metrics
- Model-based automatic evaluation process, supporting multiple evaluation modes
- Single mode: Expert models score individual models
- Pairwise-baseline mode: Comparison with baseline models
- Pairwise (all) mode: Pairwise comparison of all models
- [2024.07.26]: Supports VLMEvalKit as a third-party evaluation framework, initiating multimodal model evaluation tasks. User Guide 🔥🔥🔥
- [2024.06.29]: Supports OpenCompass as a third-party evaluation framework. We have provided a high-level wrapper, supporting installation via pip and simplifying the evaluation task configuration. User Guide 🔥🔥🔥
- [2024.06.13] Eval-Scope has been updated to version 0.3.x, which supports the ModelScope SWIFT framework for LLMs evaluation. 🚀🚀🚀
- [2024.06.13] We have supported the ToolBench as a third-party evaluation backend for Agents evaluation. 🚀🚀🚀
- create conda environment
conda create -n eval-scope python=3.10
conda activate eval-scope- Install Eval-Scope
pip install llmuses- Download source code
git clone https://github.com/modelscope/eval-scope.git- Install dependencies
cd eval-scope/
pip install -e .command line with pip installation:
python -m llmuses.run --model ZhipuAI/chatglm3-6b --template-type chatglm3 --datasets arc --limit 100command line with source code:
python llmuses/run.py --model ZhipuAI/chatglm3-6b --template-type chatglm3 --datasets mmlu ceval --limit 10Parameters:
- --model: ModelScope model id, model link: ZhipuAI/chatglm3-6b
python llmuses/run.py --model ZhipuAI/chatglm3-6b --template-type chatglm3 --model-args revision=v1.0.2,precision=torch.float16,device_map=auto --datasets mmlu ceval --use-cache true --limit 10python llmuses/run.py --model qwen/Qwen-1_8B --generation-config do_sample=false,temperature=0.0 --datasets ceval --dataset-args '{"ceval": {"few_shot_num": 0, "few_shot_random": false}}' --limit 10Parameters:
- --model-args: Parameters of model: revision, precision, device_map, in format of key=value,key=value
- --datasets: datasets list, separated by space
- --use-cache:
trueorfalse, whether to use cache, default isfalse - --dataset-args: evaluation settings,json format,key is the dataset name,value should be args for the dataset
- --few_shot_num: few-shot data number
- --few_shot_random: whether to use random few-shot data, default is
true - --local_path: local dataset path
- --limit: maximum number of samples to evaluate for each sub-dataset
- --template-type: model template type, see Template Type List
Note: you can use following command to check the template type list of the model:
from llmuses.models.template import TemplateType
print(TemplateType.get_template_name_list())Eval-Scope supports using third-party evaluation frameworks to initiate evaluation tasks, which we call Evaluation Backend. Currently supported Evaluation Backend includes:
- Native: Eval-Scope's own default evaluation framework, supporting various evaluation modes including single model evaluation, arena mode, and baseline model comparison mode.
- OpenCompass: Initiate OpenCompass evaluation tasks through Eval-Scope. Lightweight, easy to customize, supports seamless integration with the LLM fine-tuning framework ModelScope Swift.
- VLMEvalKit: Initiate VLMEvalKit multimodal evaluation tasks through Eval-Scope. Supports various multimodal models and datasets, and offers seamless integration with the LLM fine-tuning framework ModelScope Swift.
- ThirdParty: The third-party task, e.g. ToolBench, you can contribute your own evaluation task to Eval-Scope as third-party backend.
To facilitate the use of the OpenCompass evaluation backend, we have customized the OpenCompass source code and named it ms-opencompass. This version includes optimizations for evaluation task configuration and execution based on the original version, and it supports installation via PyPI. This allows users to initiate lightweight OpenCompass evaluation tasks through Eval-Scope. Additionally, we have initially opened up API-based evaluation tasks in the OpenAI API format. You can deploy model services using ModelScope Swift, where swift deploy supports using vLLM to launch model inference services.
# Install with extra option
pip install llmuses[opencompass]Available datasets from OpenCompass backend:
'obqa', 'AX_b', 'siqa', 'nq', 'mbpp', 'winogrande', 'mmlu', 'BoolQ', 'cluewsc', 'ocnli', 'lambada', 'CMRC', 'ceval', 'csl', 'cmnli', 'bbh', 'ReCoRD', 'math', 'humaneval', 'eprstmt', 'WSC', 'storycloze', 'MultiRC', 'RTE', 'chid', 'gsm8k', 'AX_g', 'bustm', 'afqmc', 'piqa', 'lcsts', 'strategyqa', 'Xsum', 'agieval', 'ocnli_fc', 'C3', 'tnews', 'race', 'triviaqa', 'CB', 'WiC', 'hellaswag', 'summedits', 'GaokaoBench', 'ARC_e', 'COPA', 'ARC_c', 'DRCD'
Refer to OpenCompass datasets
You can use the following code to list all available datasets:
from llmuses.backend.opencompass import OpenCompassBackendManager
print(f'** All datasets from OpenCompass backend: {OpenCompassBackendManager.list_datasets()}')Dataset download:
-
Option1: Download from ModelScope
git clone https://www.modelscope.cn/datasets/swift/evalscope_resource.git
-
Option2: Download from OpenCompass GitHub
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-complete-20240207.zip
Unzip the file and set the path to the data directory in current work directory.
We use ModelScope swift to deploy model services, see: ModelScope Swift
# Install ms-swift
pip install ms-swift
# Deploy model
CUDA_VISIBLE_DEVICES=0 swift deploy --model_type llama3-8b-instruct --port 8000Refer to example: example_eval_swift_openai_api to configure and execute the evaluation task:
python examples/example_eval_swift_openai_api.pyTo facilitate the use of the VLMEvalKit evaluation backend, we have customized the VLMEvalKit source code and named it ms-vlmeval. This version encapsulates the configuration and execution of evaluation tasks based on the original version and supports installation via PyPI, allowing users to initiate lightweight VLMEvalKit evaluation tasks through Eval-Scope. Additionally, we support API-based evaluation tasks in the OpenAI API format. You can deploy multimodal model services using ModelScope swift.
# Install with additional options
pip install llmuses[vlmeval]Currently supported datasets include:
'COCO_VAL', 'MME', 'HallusionBench', 'POPE', 'MMBench_DEV_EN', 'MMBench_TEST_EN', 'MMBench_DEV_CN', 'MMBench_TEST_CN', 'MMBench', 'MMBench_CN', 'MMBench_DEV_EN_V11', 'MMBench_TEST_EN_V11', 'MMBench_DEV_CN_V11', 'MMBench_TEST_CN_V11', 'MMBench_V11', 'MMBench_CN_V11', 'SEEDBench_IMG', 'SEEDBench2', 'SEEDBench2_Plus', 'ScienceQA_VAL', 'ScienceQA_TEST', 'MMT-Bench_ALL_MI', 'MMT-Bench_ALL', 'MMT-Bench_VAL_MI', 'MMT-Bench_VAL', 'AesBench_VAL', 'AesBench_TEST', 'CCBench', 'AI2D_TEST', 'MMStar', 'RealWorldQA', 'MLLMGuard_DS', 'BLINK', 'OCRVQA_TEST', 'OCRVQA_TESTCORE', 'TextVQA_VAL', 'DocVQA_VAL', 'DocVQA_TEST', 'InfoVQA_ VAL', 'InfoVQA_TEST', 'ChartQA_VAL', 'ChartQA_TEST', 'MathVision', 'MathVision_MINI', 'MMMU_DEV_VAL', 'MMMU_TEST', 'OCRBench', 'MathVista_MINI', 'LLaVABench', 'MMVet', 'MTVQA_TEST', 'MMLongBench_DOC', 'VCR_EN_EASY_500', 'VCR_EN_EASY_100', 'VCR_EN_EASY_ALL', 'VCR_EN_HARD_500', 'VCR_EN_HARD_100', 'VCR_EN_HARD_ALL', 'VCR_ZH_EASY_500', 'VCR_ZH_EASY_100', 'VCR_Z H_EASY_ALL', 'VCR_ZH_HARD_500', 'VCR_ZH_HARD_100', 'VCR_ZH_HARD_ALL', 'MMBench-Video', 'Video-MME', 'MMBench_DEV_EN', 'MMBench_TEST_EN', 'MMBench_DEV_CN', 'MMBench_TEST_CN', 'MMBench', 'MMBench_CN', 'MMBench_DEV_EN_V11', 'MMBench_TEST_EN_V11', 'MMBench_DEV_CN_V11', 'MMBench_TEST_CN_V11', 'MM Bench_V11', 'MMBench_CN_V11', 'SEEDBench_IMG', 'SEEDBench2', 'SEEDBench2_Plus', 'ScienceQA_VAL', 'ScienceQA_TEST', 'MMT-Bench_ALL_MI', 'MMT-Bench_ALL', 'MMT-Bench_VAL_MI', 'MMT-Bench_VAL', 'AesBench_VAL', 'AesBench_TEST', 'CCBench', 'AI2D_TEST', 'MMStar', 'RealWorldQA', 'MLLMGuard_DS', 'BLINK'
For detailed information about the datasets, please refer to VLMEvalKit Supported Multimodal Evaluation Sets.
You can use the following to view the list of dataset names:
from llmuses.backend.vlm_eval_kit import VLMEvalKitBackendManager
print(f'** All models from VLMEvalKit backend: {VLMEvalKitBackendManager.list(list_supported_VLMs().keys())}')If the dataset file does not exist locally when loading the dataset, it will be automatically downloaded to the ~/LMUData/ directory.
There are two ways to evaluate the model:
Model Deployment Deploy the model service using ModelScope Swift. For detailed instructions, refer to: ModelScope Swift MLLM Deployment Guide
# Install ms-swift
pip install ms-swift
# Deploy the qwen-vl-chat multi-modal model service
CUDA_VISIBLE_DEVICES=0 swift deploy --model_type qwen-vl-chat --model_id_or_path models/Qwen-VL-ChatModel Evaluation Refer to the example file: example_eval_vlm_swift to configure the evaluation task. Execute the evaluation task:
python examples/example_eval_vlm_swift.pyModel Inference Evaluation Skip the model service deployment and perform inference directly on the local machine. Refer to the example file: example_eval_vlm_local to configure the evaluation task. Execute the evaluation task:
python examples/example_eval_vlm_local.pyDeploy the local language model as a judge/extractor using ModelScope swift. For details, refer to: ModelScope Swift LLM Deployment Guide. If no judge model is deployed, exact matching will be used.
# Deploy qwen2-7b as a judge
CUDA_VISIBLE_DEVICES=1 swift deploy --model_type qwen2-7b-instruct --model_id_or_path models/Qwen2-7B-Instruct --port 8866You must configure the following environment variables for the judge model to be correctly invoked:
OPENAI_API_KEY=EMPTY
OPENAI_API_BASE=http://127.0.0.1:8866/v1/chat/completions # api_base for the judge model
LOCAL_LLM=qwen2-7b-instruct # model_id for the judge model
Refer to the example file: example_eval_vlm_swift to configure the evaluation task.
Execute the evaluation task:
python examples/example_eval_vlm_swift.pyYou can use local dataset to evaluate the model without internet connection.
# set path to /path/to/workdir
wget https://modelscope.oss-cn-beijing.aliyuncs.com/open_data/benchmark/data.zip
unzip data.zippython llmuses/run.py --model ZhipuAI/chatglm3-6b --template-type chatglm3 --datasets arc --dataset-hub Local --dataset-args '{"arc": {"local_path": "/path/to/workdir/data/arc"}}' --limit 10
# Parameters:
# --dataset-hub: dataset sources: `ModelScope`, `Local`, `HuggingFace` (TO-DO) default to `ModelScope`
# --dataset-args: json format, key is the dataset name, value should be args for the dataset# 1. Prepare the model local folder, the folder structure refers to chatglm3-6b, link: https://modelscope.cn/models/ZhipuAI/chatglm3-6b/files
# For example, download the model folder to the local path /path/to/ZhipuAI/chatglm3-6b
# 2. Execute the offline evaluation task
python llmuses/run.py --model /path/to/ZhipuAI/chatglm3-6b --template-type chatglm3 --datasets arc --dataset-hub Local --dataset-args '{"arc": {"local_path": "/path/to/workdir/data/arc"}}' --limit 10import torch
from llmuses.constants import DEFAULT_ROOT_CACHE_DIR
# Example configuration
your_task_cfg = {
'model_args': {'revision': None, 'precision': torch.float16, 'device_map': 'auto'},
'generation_config': {'do_sample': False, 'repetition_penalty': 1.0, 'max_new_tokens': 512},
'dataset_args': {},
'dry_run': False,
'model': 'ZhipuAI/chatglm3-6b',
'template_type': 'chatglm3',
'datasets': ['arc', 'hellaswag'],
'work_dir': DEFAULT_ROOT_CACHE_DIR,
'outputs': DEFAULT_ROOT_CACHE_DIR,
'mem_cache': False,
'dataset_hub': 'ModelScope',
'dataset_dir': DEFAULT_ROOT_CACHE_DIR,
'stage': 'all',
'limit': 10,
'debug': False
}from llmuses.run import run_task
run_task(task_cfg=your_task_cfg)The Arena mode allows multiple candidate models to be evaluated through pairwise battles, and can choose to use the AI Enhanced Auto-Reviewer (AAR) automatic evaluation process or manual evaluation to obtain the evaluation report. The process is as follows:
a. Data preparation, the question data format refers to: llmuses/registry/data/question.jsonl
b. If you need to use the automatic evaluation process (AAR), you need to configure the relevant environment variables. Taking the GPT-4 based auto-reviewer process as an example, you need to configure the following environment variables:
> export OPENAI_API_KEY=YOUR_OPENAI_API_KEY
Refer to : llmuses/registry/config/cfg_arena.yaml
Parameters:
questions_file: question data path
answers_gen: candidate model prediction result generation, supports multiple models, can control whether to enable the model through the enable parameter
reviews_gen: evaluation result generation, currently defaults to using GPT-4 as the Auto-reviewer, can control whether to enable this step through the enable parameter
elo_rating: ELO rating algorithm, can control whether to enable this step through the enable parameter, note that this step depends on the review_file must exist
#Usage:
cd llmuses
# dry-run mode
python llmuses/run_arena.py -c registry/config/cfg_arena.yaml --dry-run
# Execute the script
python llmuses/run_arena.py --c registry/config/cfg_arena.yaml# Usage:
streamlit run viz.py -- --review-file llmuses/registry/data/qa_browser/battle.jsonl --category-file llmuses/registry/data/qa_browser/category_mapping.yamlIn this mode, we only score the output of a single model, without pairwise comparison.
Refer to: llmuses/registry/config/cfg_single.yaml
Parameters:
questions_file: question data path
answers_gen: candidate model prediction result generation, supports multiple models, can control whether to enable the model through the enable parameter
reviews_gen: evaluation result generation, currently defaults to using GPT-4 as the Auto-reviewer, can control whether to enable this step through the enable parameter
rating_gen: rating algorithm, can control whether to enable this step through the enable parameter, note that this step depends on the review_file must exist
#Example:
python llmuses/run_arena.py --c registry/config/cfg_single.yamlIn this mode, we select the baseline model, and compare other models with the baseline model for scoring. This mode can easily add new models to the Leaderboard (just need to run the scoring with the new model and the baseline model).
Refer to: llmuses/registry/config/cfg_pairwise_baseline.yaml
Parameters:
questions_file: question data path
answers_gen: candidate model prediction result generation, supports multiple models, can control whether to enable the model through the enable parameter
reviews_gen: evaluation result generation, currently defaults to using GPT-4 as the Auto-reviewer, can control whether to enable this step through the enable parameter
rating_gen: rating algorithm, can control whether to enable this step through the enable parameter, note that this step depends on the review_file must exist
# Example:
python llmuses/run_arena.py --c registry/config/cfg_pairwise_baseline.yaml| DatasetName | Link | Status | Note |
|---|---|---|---|
mmlu |
mmlu | Active | |
ceval |
ceval | Active | |
gsm8k |
gsm8k | Active | |
arc |
arc | Active | |
hellaswag |
hellaswag | Active | |
truthful_qa |
truthful_qa | Active | |
competition_math |
competition_math | Active | |
humaneval |
humaneval | Active | |
bbh |
bbh | Active | |
race |
race | Active | |
trivia_qa |
trivia_qa | To be intergrated |
The LLM Leaderboard aims to provide an objective and comprehensive evaluation standard and platform to help researchers and developers understand and compare the performance of models on various tasks on ModelScope.
- ✅Agents evaluation
- [ ] vLLM
- [ ] Distributed evaluating
- [ ] Multi-modal evaluation
- [ ] Benchmarks
- [ ] GAIA
- [ ] GPQA
- [ ] MBPP
- [ ] Auto-reviewer
- [ ] Qwen-max
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for eval-scope
Similar Open Source Tools
eval-scope
Eval-Scope is a framework for evaluating and improving large language models (LLMs). It provides a set of commonly used test datasets, metrics, and a unified model interface for generating and evaluating LLM responses. Eval-Scope also includes an automatic evaluator that can score objective questions and use expert models to evaluate complex tasks. Additionally, it offers a visual report generator, an arena mode for comparing multiple models, and a variety of other features to support LLM evaluation and development.

hezar
Hezar is an all-in-one AI library designed specifically for the Persian community. It brings together various AI models and tools, making it easy to use AI with just a few lines of code. The library seamlessly integrates with Hugging Face Hub, offering a developer-friendly interface and task-based model interface. In addition to models, Hezar provides tools like word embeddings, tokenizers, feature extractors, and more. It also includes supplementary ML tools for deployment, benchmarking, and optimization.

AnglE
AnglE is a library for training state-of-the-art BERT/LLM-based sentence embeddings with just a few lines of code. It also serves as a general sentence embedding inference framework, allowing for inferring a variety of transformer-based sentence embeddings. The library supports various loss functions such as AnglE loss, Contrastive loss, CoSENT loss, and Espresso loss. It provides backbones like BERT-based models, LLM-based models, and Bi-directional LLM-based models for training on single or multi-GPU setups. AnglE has achieved significant performance on various benchmarks and offers official pretrained models for both BERT-based and LLM-based models.
python-genai
The Google Gen AI SDK is a Python library that provides access to Google AI and Vertex AI services. It allows users to create clients for different services, work with parameter types, models, generate content, call functions, handle JSON response schemas, stream text and image content, perform async operations, count and compute tokens, embed content, generate and upscale images, edit images, work with files, create and get cached content, tune models, distill models, perform batch predictions, and more. The SDK supports various features like automatic function support, manual function declaration, JSON response schema support, streaming for text and image content, async methods, tuning job APIs, distillation, batch prediction, and more.
starknet-agent-kit
starknet-agent-kit is a NestJS-based toolkit for creating AI agents that can interact with the Starknet blockchain. It allows users to perform various actions such as retrieving account information, creating accounts, transferring assets, playing with DeFi, interacting with dApps, and executing RPC read methods. The toolkit provides a secure environment for developing AI agents while emphasizing caution when handling sensitive information. Users can make requests to the Starknet agent via API endpoints and utilize tools from Langchain directly.
omniai
OmniAI provides a unified Ruby API for integrating with multiple AI providers, streamlining AI development by offering a consistent interface for features such as chat, text-to-speech, speech-to-text, and embeddings. It ensures seamless interoperability across platforms and effortless switching between providers, making integrations more flexible and reliable.

ai00_server
AI00 RWKV Server is an inference API server for the RWKV language model based upon the web-rwkv inference engine. It supports VULKAN parallel and concurrent batched inference and can run on all GPUs that support VULKAN. No need for Nvidia cards!!! AMD cards and even integrated graphics can be accelerated!!! No need for bulky pytorch, CUDA and other runtime environments, it's compact and ready to use out of the box! Compatible with OpenAI's ChatGPT API interface. 100% open source and commercially usable, under the MIT license. If you are looking for a fast, efficient, and easy-to-use LLM API server, then AI00 RWKV Server is your best choice. It can be used for various tasks, including chatbots, text generation, translation, and Q&A.
mcp-ui
mcp-ui is a collection of SDKs that bring interactive web components to the Model Context Protocol (MCP). It allows servers to define reusable UI snippets, render them securely in the client, and react to their actions in the MCP host environment. The SDKs include @mcp-ui/server (TypeScript) for generating UI resources on the server, @mcp-ui/client (TypeScript) for rendering UI components on the client, and mcp_ui_server (Ruby) for generating UI resources in a Ruby environment. The project is an experimental community playground for MCP UI ideas, with rapid iteration and enhancements.
ax
Ax is a Typescript library that allows users to build intelligent agents inspired by agentic workflows and the Stanford DSP paper. It seamlessly integrates with multiple Large Language Models (LLMs) and VectorDBs to create RAG pipelines or collaborative agents capable of solving complex problems. The library offers advanced features such as streaming validation, multi-modal DSP, and automatic prompt tuning using optimizers. Users can easily convert documents of any format to text, perform smart chunking, embedding, and querying, and ensure output validation while streaming. Ax is production-ready, written in Typescript, and has zero dependencies.
ai-gateway
LangDB AI Gateway is an open-source enterprise AI gateway built in Rust. It provides a unified interface to all LLMs using the OpenAI API format, focusing on high performance, enterprise readiness, and data control. The gateway offers features like comprehensive usage analytics, cost tracking, rate limiting, data ownership, and detailed logging. It supports various LLM providers and provides OpenAI-compatible endpoints for chat completions, model listing, embeddings generation, and image generation. Users can configure advanced settings, such as rate limiting, cost control, dynamic model routing, and observability with OpenTelemetry tracing. The gateway can be run with Docker Compose and integrated with MCP tools for server communication.
aioaws
Aioaws is an asyncio SDK for some AWS services, providing clean, secure, and easily debuggable access to services like S3, SES, and SNS. It is written from scratch without dependencies on boto or boto3, formatted with black, and includes complete type hints. The library supports various functionalities such as listing, deleting, and generating signed URLs for S3 files, sending emails with attachments and multipart content via SES, and receiving notifications about mail delivery from SES. It also offers AWS Signature Version 4 authentication and has minimal dependencies like aiofiles, cryptography, httpx, and pydantic.
aiohttp-jinja2
aiohttp_jinja2 is a Jinja2 template renderer for aiohttp.web, allowing users to render templates in web applications built with aiohttp. It provides a convenient way to set up Jinja2 environment, use template engine in web handlers, and perform complex processing like setting response headers. The tool simplifies the process of rendering HTML text based on templates and passing context data to templates for dynamic content generation.

pinecone-ts-client
The official Node.js client for Pinecone, written in TypeScript. This client library provides a high-level interface for interacting with the Pinecone vector database service. With this client, you can create and manage indexes, upsert and query vector data, and perform other operations related to vector search and retrieval. The client is designed to be easy to use and provides a consistent and idiomatic experience for Node.js developers. It supports all the features and functionality of the Pinecone API, making it a comprehensive solution for building vector-powered applications in Node.js.
ai-nodejs
This repository serves as a companion to the Build AI-Powered Apps with OpenAI and Node.js course on Frontend Masters. It includes course notes and provides alternative approaches for deprecated Langchain methods by installing the Langchain community module and importing loaders for document processing from PDFs and YouTube videos.
ruby-nano-bots
Ruby Nano Bots is an implementation of the Nano Bots specification supporting various AI providers like Cohere Command, Google Gemini, Maritaca AI MariTalk, Mistral AI, Ollama, OpenAI ChatGPT, and others. It allows calling tools (functions) and provides a helpful assistant for interacting with AI language models. The tool can be used both from the command line and as a library in Ruby projects, offering features like REPL, debugging, and encryption for data privacy.
For similar tasks

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!
dwata
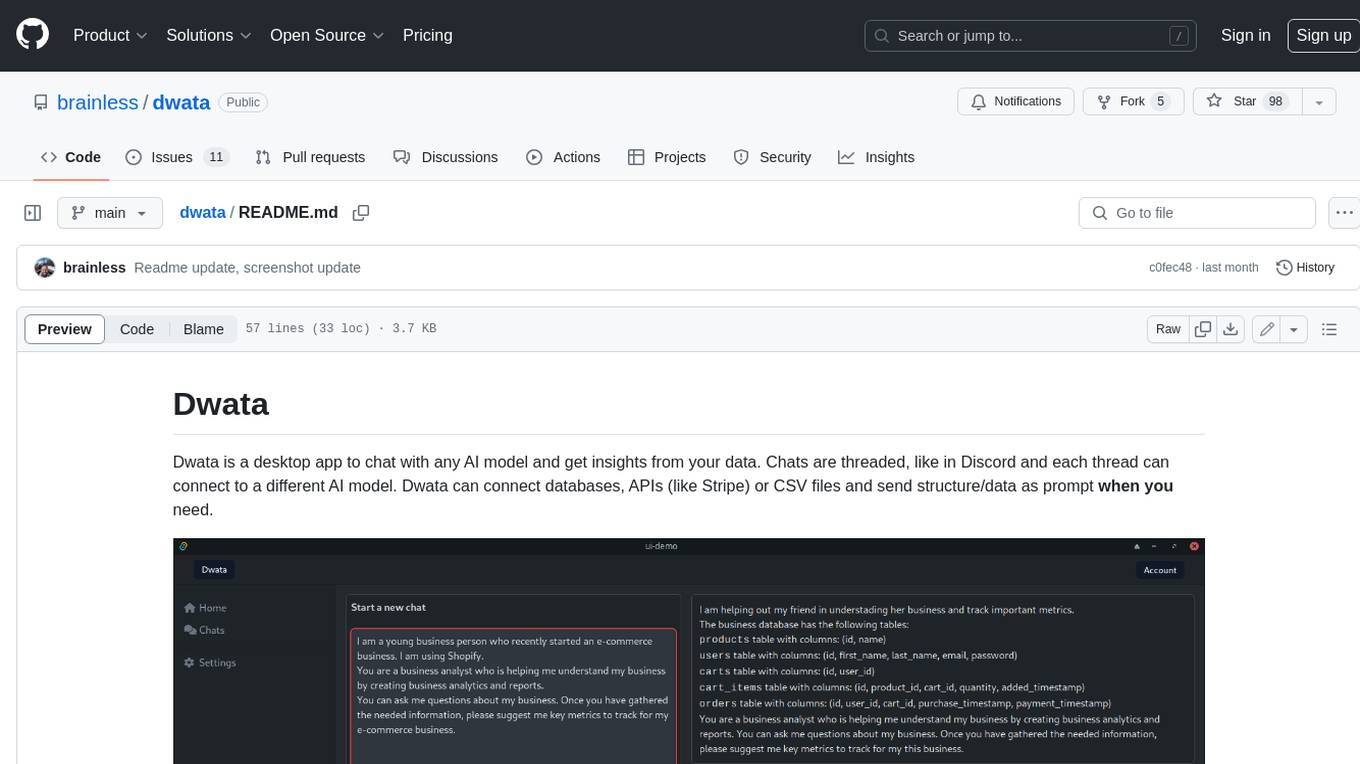
Dwata is a desktop application that allows users to chat with any AI model and gain insights from their data. Chats are organized into threads, similar to Discord, with each thread connecting to a different AI model. Dwata can connect to databases, APIs (such as Stripe), or CSV files and send structured data as prompts when needed. The AI's response will often include SQL or Python code, which can be used to extract the desired insights. Dwata can validate AI-generated SQL to ensure that the tables and columns referenced are correct and can execute queries against the database from within the application. Python code (typically using Pandas) can also be executed from within Dwata, although this feature is still in development. Dwata supports a range of AI models, including OpenAI's GPT-4, GPT-4 Turbo, and GPT-3.5 Turbo; Groq's LLaMA2-70b and Mixtral-8x7b; Phind's Phind-34B and Phind-70B; Anthropic's Claude; and Ollama's Llama 2, Mistral, and Phi-2 Gemma. Dwata can compare chats from different models, allowing users to see the responses of multiple models to the same prompts. Dwata can connect to various data sources, including databases (PostgreSQL, MySQL, MongoDB), SaaS products (Stripe, Shopify), CSV files/folders, and email (IMAP). The desktop application does not collect any private or business data without the user's explicit consent.

ollama-grid-search
A Rust based tool to evaluate LLM models, prompts and model params. It automates the process of selecting the best model parameters, given an LLM model and a prompt, iterating over the possible combinations and letting the user visually inspect the results. The tool assumes the user has Ollama installed and serving endpoints, either in `localhost` or in a remote server. Key features include: * Automatically fetches models from local or remote Ollama servers * Iterates over different models and params to generate inferences * A/B test prompts on different models simultaneously * Allows multiple iterations for each combination of parameters * Makes synchronous inference calls to avoid spamming servers * Optionally outputs inference parameters and response metadata (inference time, tokens and tokens/s) * Refetching of individual inference calls * Model selection can be filtered by name * List experiments which can be downloaded in JSON format * Configurable inference timeout * Custom default parameters and system prompts can be defined in settings
eval-scope
Eval-Scope is a framework for evaluating and improving large language models (LLMs). It provides a set of commonly used test datasets, metrics, and a unified model interface for generating and evaluating LLM responses. Eval-Scope also includes an automatic evaluator that can score objective questions and use expert models to evaluate complex tasks. Additionally, it offers a visual report generator, an arena mode for comparing multiple models, and a variety of other features to support LLM evaluation and development.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.