
ollama-grid-search
A multi-platform desktop application to evaluate and compare LLM models, written in Rust and React.
Stars: 564

A Rust based tool to evaluate LLM models, prompts and model params. It automates the process of selecting the best model parameters, given an LLM model and a prompt, iterating over the possible combinations and letting the user visually inspect the results. The tool assumes the user has Ollama installed and serving endpoints, either in `localhost` or in a remote server. Key features include: * Automatically fetches models from local or remote Ollama servers * Iterates over different models and params to generate inferences * A/B test prompts on different models simultaneously * Allows multiple iterations for each combination of parameters * Makes synchronous inference calls to avoid spamming servers * Optionally outputs inference parameters and response metadata (inference time, tokens and tokens/s) * Refetching of individual inference calls * Model selection can be filtered by name * List experiments which can be downloaded in JSON format * Configurable inference timeout * Custom default parameters and system prompts can be defined in settings
README:
This project automates the process of selecting the best models, prompts, or inference parameters for a given use-case, allowing you to iterate over their combinations and to visually inspect the results.
It assumes Ollama is installed and serving endpoints, either in localhost or in a remote server.
Here's what an experiment for a simple prompt, tested on 3 different models, looks like:

(For a more in-depth look at an evaluation process assisted by this tool, please check https://dezoito.github.io/2023/12/27/rust-ollama-grid-search.html).
- Installation
- Features
- Grid Search Concept
- A/B Testing
- Prompt Archive
- Experiment Logs
- Future Features
- Contributing
- Development
- Citations
- Acknowledgements
Check the releases page for the project, or on the sidebar.
- Automatically fetches models from local or remote Ollama servers;
- Iterates over multiple different models, prompts and parameters to generate inferences;
- A/B test different prompts on several models simultaneously;
- Allows multiple iterations for each combination of parameters;
- Allows limited concurrency or synchronous inference calls (to prevent spamming servers);
- Optionally outputs inference parameters and response metadata (inference time, tokens and tokens/s);
- Refetching of individual inference calls;
- Model selection can be filtered by name;
- List experiments which can be downloaded in JSON format;
- Experiments can be inspected in readable views;
- Re-run past experiments, cloning or modifying the parameters used in the past;
- Configurable inference timeout;
- Custom default parameters and system prompts can be defined in settings
- Fully functional prompt database with examples;
- Prompts can be selected and "autocompleted" by typing "/" in the inputs
Technically, the term "grid search" refers to iterating over a series of different model hyperparams to optimize model performance, but that usually means parameters like batch_size, learning_rate, or number_of_epochs, more commonly used in training.
But the concept here is similar:
Lets define a selection of models, a prompt and some parameter combinations:

The prompt will be submitted once for each parameter value, for each one of the selected models, generating a set of responses.
Similarly, you can perform A/B tests by selecting different models and compare results for the same prompt/parameter combination, or test different prompts under similar configurations:

Comparing the results of different prompts for the same model
You can save and manage your prompts (we want to make prompts compatible with Open WebUI)

You can autocomplete prompts by typing "/" (inspired by Open WebUI, as well):

You can list, inspect, or download your experiments:

- Grading results and filtering by grade
- Importing, exporting and sharing prompt lists and experiment files.
-
For obvious bugs and spelling mistakes, please go ahead and submit a PR.
-
If you want to propose a new feature, change existing functionality, or propose anything more complex, please open an issue for discussion, before getting work done on a PR.
The development notes provide setup instructions, sequence diagrams, and workflow charts that should make it easier to understand the project and get started.
The following works and theses have cited this repository:
Inouye, D & Lindo, L, & Lee, R & Allen, E; Computer Science and Engineering Senior Theses: Applied Auto-tuning on LoRA Hyperparameters Santa Clara University, 2024 https://scholarcommons.scu.edu/cgi/viewcontent.cgi?article=1271&context=cseng_senior
Huge thanks to @FabianLars, @peperroni21 and @TomReidNZ.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ollama-grid-search
Similar Open Source Tools
ollama-grid-search
A Rust based tool to evaluate LLM models, prompts and model params. It automates the process of selecting the best model parameters, given an LLM model and a prompt, iterating over the possible combinations and letting the user visually inspect the results. The tool assumes the user has Ollama installed and serving endpoints, either in `localhost` or in a remote server. Key features include: * Automatically fetches models from local or remote Ollama servers * Iterates over different models and params to generate inferences * A/B test prompts on different models simultaneously * Allows multiple iterations for each combination of parameters * Makes synchronous inference calls to avoid spamming servers * Optionally outputs inference parameters and response metadata (inference time, tokens and tokens/s) * Refetching of individual inference calls * Model selection can be filtered by name * List experiments which can be downloaded in JSON format * Configurable inference timeout * Custom default parameters and system prompts can be defined in settings

graphrag-local-ollama
GraphRAG Local Ollama is a repository that offers an adaptation of Microsoft's GraphRAG, customized to support local models downloaded using Ollama. It enables users to leverage local models with Ollama for large language models (LLMs) and embeddings, eliminating the need for costly OpenAPI models. The repository provides a simple setup process and allows users to perform question answering over private text corpora by building a graph-based text index and generating community summaries for closely-related entities. GraphRAG Local Ollama aims to improve the comprehensiveness and diversity of generated answers for global sensemaking questions over datasets.

BambooAI
BambooAI is a lightweight library utilizing Large Language Models (LLMs) to provide natural language interaction capabilities, much like a research and data analysis assistant enabling conversation with your data. You can either provide your own data sets, or allow the library to locate and fetch data for you. It supports Internet searches and external API interactions.

AntSK
AntSK is an AI knowledge base/agent built with .Net8+Blazor+SemanticKernel. It features a semantic kernel for accurate natural language processing, a memory kernel for continuous learning and knowledge storage, a knowledge base for importing and querying knowledge from various document formats, a text-to-image generator integrated with StableDiffusion, GPTs generation for creating personalized GPT models, API interfaces for integrating AntSK into other applications, an open API plugin system for extending functionality, a .Net plugin system for integrating business functions, real-time information retrieval from the internet, model management for adapting and managing different models from different vendors, support for domestic models and databases for operation in a trusted environment, and planned model fine-tuning based on llamafactory.

fuse-med-ml
FuseMedML is a Python framework designed to accelerate machine learning-based discovery in the medical field by promoting code reuse. It provides a flexible design concept where data is stored in a nested dictionary, allowing easy handling of multi-modality information. The framework includes components for creating custom models, loss functions, metrics, and data processing operators. Additionally, FuseMedML offers 'batteries included' key components such as fuse.data for data processing, fuse.eval for model evaluation, and fuse.dl for reusable deep learning components. It supports PyTorch and PyTorch Lightning libraries and encourages the creation of domain extensions for specific medical domains.

project_alice
Alice is an agentic workflow framework that integrates task execution and intelligent chat capabilities. It provides a flexible environment for creating, managing, and deploying AI agents for various purposes, leveraging a microservices architecture with MongoDB for data persistence. The framework consists of components like APIs, agents, tasks, and chats that interact to produce outputs through files, messages, task results, and URL references. Users can create, test, and deploy agentic solutions in a human-language framework, making it easy to engage with by both users and agents. The tool offers an open-source option, user management, flexible model deployment, and programmatic access to tasks and chats.

llm_client
llm_client is a Rust interface designed for Local Large Language Models (LLMs) that offers automated build support for CPU, CUDA, MacOS, easy model presets, and a novel cascading prompt workflow for controlled generation. It provides a breadth of configuration options and API support for various OpenAI compatible APIs. The tool is primarily focused on deterministic signals from probabilistic LLM vibes, enabling specialized workflows for specific tasks and reproducible outcomes.

CoLLM
CoLLM is a novel method that integrates collaborative information into Large Language Models (LLMs) for recommendation. It converts recommendation data into language prompts, encodes them with both textual and collaborative information, and uses a two-step tuning method to train the model. The method incorporates user/item ID fields in prompts and employs a conventional collaborative model to generate user/item representations. CoLLM is built upon MiniGPT-4 and utilizes pretrained Vicuna weights for training.

merlin
Merlin is a groundbreaking model capable of generating natural language responses intricately linked with object trajectories of multiple images. It excels in predicting and reasoning about future events based on initial observations, showcasing unprecedented capability in future prediction and reasoning. Merlin achieves state-of-the-art performance on the Future Reasoning Benchmark and multiple existing multimodal language models benchmarks, demonstrating powerful multi-modal general ability and foresight minds.

magpie
This is the official repository for 'Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing'. Magpie is a tool designed to synthesize high-quality instruction data at scale by extracting it directly from an aligned Large Language Models (LLMs). It aims to democratize AI by generating large-scale alignment data and enhancing the transparency of model alignment processes. Magpie has been tested on various model families and can be used to fine-tune models for improved performance on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.
ROSGPT_Vision
ROSGPT_Vision is a new robotic framework designed to command robots using only two prompts: a Visual Prompt for visual semantic features and an LLM Prompt to regulate robotic reactions. It is based on the Prompting Robotic Modalities (PRM) design pattern and is used to develop CarMate, a robotic application for monitoring driver distractions and providing real-time vocal notifications. The framework leverages state-of-the-art language models to facilitate advanced reasoning about image data and offers a unified platform for robots to perceive, interpret, and interact with visual data through natural language. LangChain is used for easy customization of prompts, and the implementation includes the CarMate application for driver monitoring and assistance.

gepa
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.

RAG-FiT
RAG-FiT is a library designed to improve Language Models' ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library assists in creating training data, training models using parameter-efficient finetuning (PEFT), and evaluating performance using RAG-specific metrics. It is modular, customizable via configuration files, and facilitates fast prototyping and experimentation with various RAG settings and configurations.

guidellm
GuideLLM is a powerful tool for evaluating and optimizing the deployment of large language models (LLMs). By simulating real-world inference workloads, GuideLLM helps users gauge the performance, resource needs, and cost implications of deploying LLMs on various hardware configurations. This approach ensures efficient, scalable, and cost-effective LLM inference serving while maintaining high service quality. Key features include performance evaluation, resource optimization, cost estimation, and scalability testing.

RAGFoundry
RAG Foundry is a library designed to enhance Large Language Models (LLMs) by fine-tuning models on RAG-augmented datasets. It helps create training data, train models using parameter-efficient finetuning (PEFT), and measure performance using RAG-specific metrics. The library is modular, customizable using configuration files, and facilitates prototyping with various RAG settings and configurations for tasks like data processing, retrieval, training, inference, and evaluation.
wandbot
Wandbot is a question-answering bot designed for Weights & Biases documentation. It employs Retrieval Augmented Generation with a ChromaDB backend for efficient responses. The bot features periodic data ingestion, integration with Discord and Slack, and performance monitoring through logging. It has a fallback mechanism for model selection and is evaluated based on retrieval accuracy and model-generated responses. The implementation includes creating document embeddings, constructing the Q&A RAGPipeline, model selection, deployment on FastAPI, Discord, and Slack, logging and analysis with Weights & Biases Tables, and performance evaluation.
For similar tasks

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!
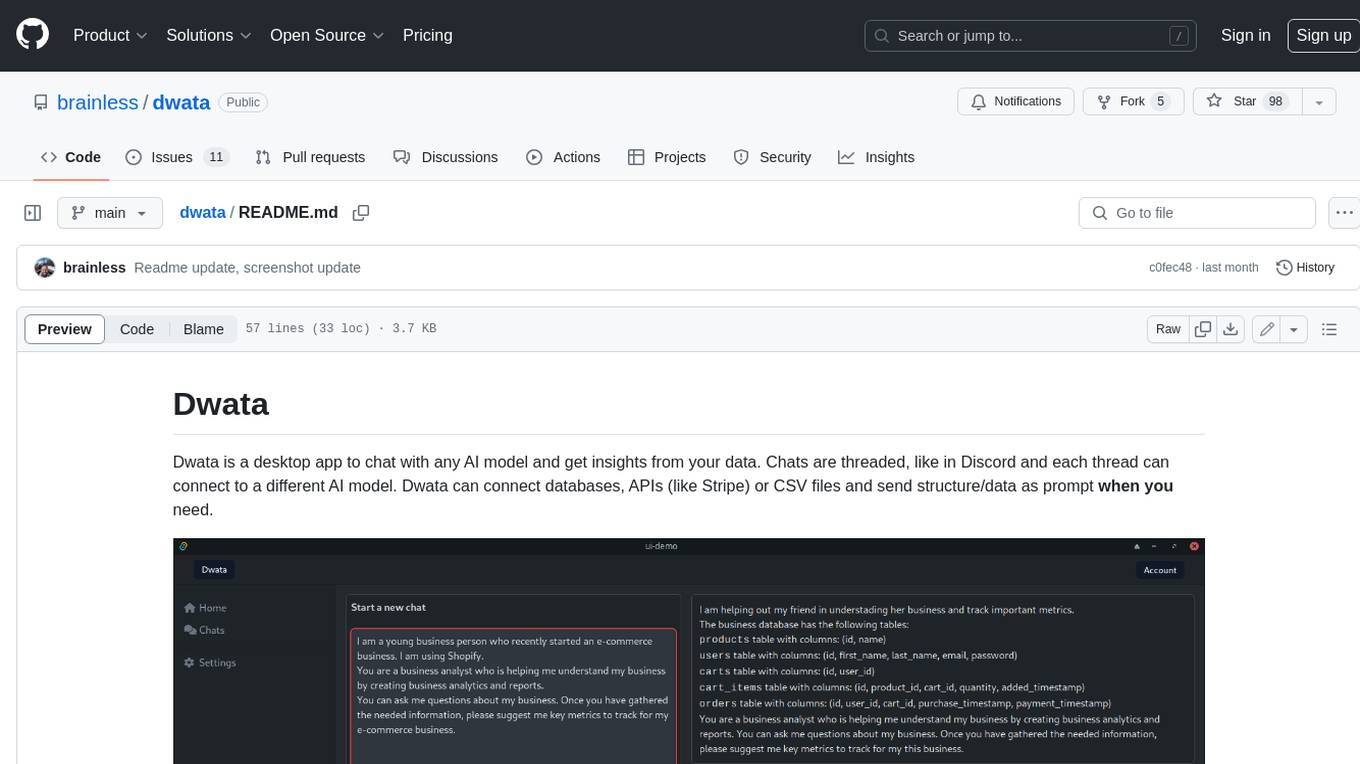
dwata
Dwata is a desktop application that allows users to chat with any AI model and gain insights from their data. Chats are organized into threads, similar to Discord, with each thread connecting to a different AI model. Dwata can connect to databases, APIs (such as Stripe), or CSV files and send structured data as prompts when needed. The AI's response will often include SQL or Python code, which can be used to extract the desired insights. Dwata can validate AI-generated SQL to ensure that the tables and columns referenced are correct and can execute queries against the database from within the application. Python code (typically using Pandas) can also be executed from within Dwata, although this feature is still in development. Dwata supports a range of AI models, including OpenAI's GPT-4, GPT-4 Turbo, and GPT-3.5 Turbo; Groq's LLaMA2-70b and Mixtral-8x7b; Phind's Phind-34B and Phind-70B; Anthropic's Claude; and Ollama's Llama 2, Mistral, and Phi-2 Gemma. Dwata can compare chats from different models, allowing users to see the responses of multiple models to the same prompts. Dwata can connect to various data sources, including databases (PostgreSQL, MySQL, MongoDB), SaaS products (Stripe, Shopify), CSV files/folders, and email (IMAP). The desktop application does not collect any private or business data without the user's explicit consent.
ollama-grid-search
A Rust based tool to evaluate LLM models, prompts and model params. It automates the process of selecting the best model parameters, given an LLM model and a prompt, iterating over the possible combinations and letting the user visually inspect the results. The tool assumes the user has Ollama installed and serving endpoints, either in `localhost` or in a remote server. Key features include: * Automatically fetches models from local or remote Ollama servers * Iterates over different models and params to generate inferences * A/B test prompts on different models simultaneously * Allows multiple iterations for each combination of parameters * Makes synchronous inference calls to avoid spamming servers * Optionally outputs inference parameters and response metadata (inference time, tokens and tokens/s) * Refetching of individual inference calls * Model selection can be filtered by name * List experiments which can be downloaded in JSON format * Configurable inference timeout * Custom default parameters and system prompts can be defined in settings
eval-scope
Eval-Scope is a framework for evaluating and improving large language models (LLMs). It provides a set of commonly used test datasets, metrics, and a unified model interface for generating and evaluating LLM responses. Eval-Scope also includes an automatic evaluator that can score objective questions and use expert models to evaluate complex tasks. Additionally, it offers a visual report generator, an arena mode for comparing multiple models, and a variety of other features to support LLM evaluation and development.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.
PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.