
gepa
Optimize prompts, code, and more with AI-powered Reflective Text Evolution
Stars: 2262

GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.
README:
![]()
Optimize text components—AI prompts, code, or instructions—of any system using reflective text evolution.

GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components—like AI prompts, code snippets, or textual specs—against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains.
This repository provides the official implementation of the GEPA algorithm as proposed in the paper titled "GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning" (https://arxiv.org/abs/2507.19457). In order to reproduce experiments from the paper, we provide a separate reproduction artifact.
pip install gepaTo install the very latest from main:
pip install git+https://github.com/gepa-ai/gepa.gitThe easiest and most powerful way to use GEPA for prompt optimization is within DSPy, where the GEPA algorithm is directly available through the
dspy.GEPAAPI. Directly executable tutorial notebooks are at dspy.GEPA Tutorials.
GEPA can be run in just a few lines of code. In this example, we'll use GEPA to optimize a system prompt for math problems from the AIME benchmark (full tutorial). Run the following in an environment with OPENAI_API_KEY:
import gepa
# Load AIME dataset
trainset, valset, _ = gepa.examples.aime.init_dataset()
seed_prompt = {
"system_prompt": "You are a helpful assistant. You are given a question and you need to answer it. The answer should be given at the end of your response in exactly the format '### <final answer>'"
}
# Let's run GEPA optimization process.
gepa_result = gepa.optimize(
seed_candidate=seed_prompt,
trainset=trainset,
valset=valset,
task_lm="openai/gpt-4.1-mini", # <-- This is the model being optimized
max_metric_calls=150, # <-- Set a budget
reflection_lm="openai/gpt-5", # <-- Use a strong model to reflect on mistakes and propose better prompts
)
print("GEPA Optimized Prompt:", gepa_result.best_candidate['system_prompt'])Here, we can see the optimized prompt that GEPA generates for AIME, which achieves improves GPT-4.1 Mini's performance from 46.6% to 56.6%, an improvement of 10% on AIME 2025. Note the details captured in the prompts in just 2 iterations of GEPA. GEPA can be thought of as precomputing some reasoning (during optimization) to come up with a good plan for future task instances.
| Example GEPA Prompts | |
| HotpotQA (multi-hop QA) Prompt | AIME Prompt |
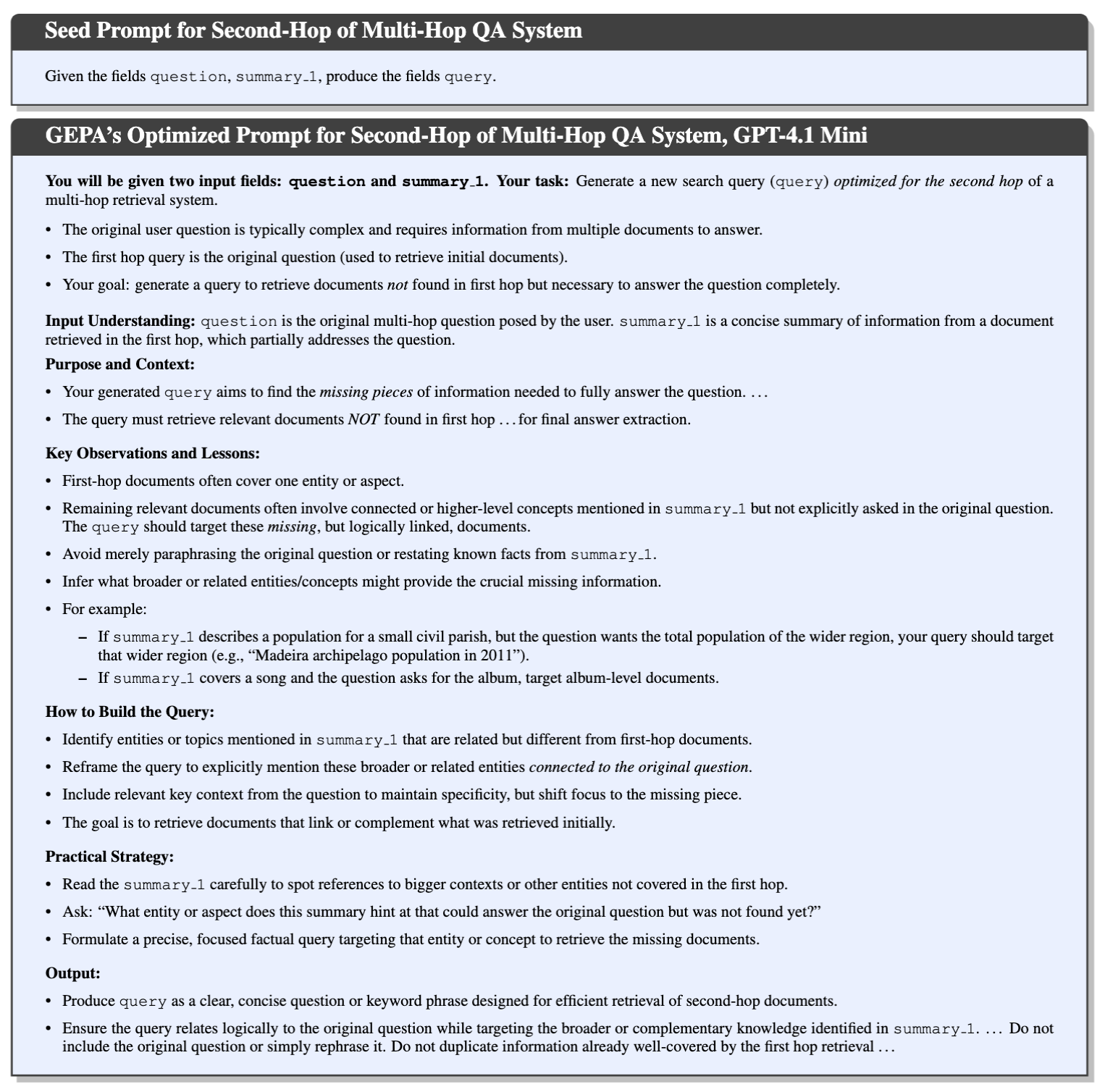
Click to view full HotpotQA prompt[HotpotQA Prompt Begin]You will be given two input fields: Your task is to generate a new search query ( Detailed task instructions and hints:
By following these principles, you will help the multi-hop retrieval system find all necessary documents to answer the multi-faceted original question completely. [HotpotQA Prompt End] |

Click to view full AIME prompt[AIME Prompt Begin] You will be given one math problem as plain text under a key like “problem.” Your job is to solve it correctly and return:
Formatting:
General problem-solving guidance:
Domain-specific strategies and pitfalls (learned from typical contest problems and prior feedback):
Quality checks:
Finally:
[AIME Prompt End] |
GEPA is built around a flexible GEPAAdapter abstraction that lets it plug into any system and optimize different types of text snippets. The above example used a simple DefaultAdapter that plugs into a single-turn LLM environment and evolves system prompts, where tasks are presented as user messages. GEPA can be easily extended to multi-turn and other agentic settings. For example, the dspy.GEPA integration uses a DSPyAdapter.
Beyond prompt optimization, GEPA can evolve entire programs. The DSPy Full Program Adapter demonstrates this by evolving complete DSPy programs—including custom signatures, modules, and control flow logic. Starting from a basic dspy.ChainOfThought("question -> answer") that achieves 67% on the MATH benchmark, GEPA evolves a multi-step reasoning program that reach 93% accuracy. A fully executable example notebook shows how to use this adapter.
GEPA can be used to optimize any system consisting of textual components. Follow these steps:
- Implement
GEPAAdapter: In order to allow the GEPA optimizer to pair with your system and its environment, users can implement theGEPAAdapterinterface defined in src/gepa/core/adapter.py.GEPAAdapterrequires 2 methods:- Evaluate: Given a candidate consisting of proposed text components, and a minibatch of inputs sampled from the train/val sets, evaluate and return execution scores, also capturing the system traces.
- Extract Traces for Reflection: Given the execution traces obtained from executing a proposed candidate, and a named component being optimized, return the textual content from the traces relevant to the named component.
- Prepare trainset and valset: Lists of example inputs and task metadata.
- Call
gepa.optimizewith your adapter, metric, and system configuration.
We are actively working on implementing adapters to integrate into many different frameworks. Please open an issue if there's a specific framework you would like to see supported!
Terminal-bench is a benchmark for evaluating the performance of terminal-use agents. Terminus is a leading terminal-use agent. In this script, we use GEPA to optimize the system prompt/terminal-use instruction for the Terminus agent through a custom GEPAAdapter implementation.
Note that the terminus agent as well as terminal-bench run in an external environment and is integrated into GEPA via the TerminusAdapter.
To run this example:
pip install terminal-bench
python src/gepa/examples/terminal-bench/train_terminus.py --model_name=gpt-5-miniThe Generic RAG Adapter enables GEPA to optimize Retrieval-Augmented Generation (RAG) systems using any vector store (ChromaDB, Weaviate, Qdrant, Pinecone) through a pluggable interface. It optimizes query reformulation, context synthesis, answer generation, and document reranking simultaneously.
See the complete RAG adapter examples and documentation for usage examples, supported vector stores, and step-by-step guides.
GEPA optimizes text components of systems using an evolutionary search algorithm that uses LLM-based reflection for mutating candidates. Most importantly, GEPA leverages task-specific textual feedback (for example, compiler error messages, profiler performance reports, documentation, etc.) to guide the search process. For further details, refer to the paper: GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning.
We encourage the community and users to help us develop adapters to allow GEPA to be used for optimizing all kinds of systems leveraging textual components. Refer to DSPy/GEPAAdapter and src/gepa/adapters/ for example GEPAAdapter implementations. Please feel free to flag any problems faced as issues.
If you'd like to list yourself as a user, or highlight your usecase for GEPA, please reach out to [email protected].
- Paper: 📄 GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning (arXiv:2507.19457)
- Experiment reproduction artifact: GEPA Artifact Repository
- Talk Slides: GEPA Talk Slides
-
Tutorials & Examples:
-
dspy.GEPA Tutorials, with executable notebooks
Step-by-step notebooks showing how to use GEPA for practical optimization tasks via DSPy, including math, structured data extraction for enterprise tasks and privacy conscious delegation task. - Video tutorial by @weaviate on using dspy.GEPA to optimize a listwise reranker
- Matei Zaharia - Reflective Optimization of Agents with GEPA and DSPy
- Building and optimizing a multi-agent system for healthcare domain using DSPy+GEPA
-
dspy.GEPA Tutorials, with executable notebooks
-
Social and Discussion:
- X (formerly Twitter) Announcement Thread (Lakshya A Agrawal)
- GEPA covered by VentureBeat
- GEPA's use by Databricks covered by VentureBeat
- Stay up to date:
- Questions, Discussions?
-
GEPA Integrations:
Want to use GEPA in other frameworks?- DSPy Adapter Code (integrates GEPA with DSPy),
-
MLflow Prompt Optimization - GEPA is integrated into MLflow's
mlflow.genai.optimize_prompts()API for automatic prompt improvement using evaluation metrics and training data. Works with any agent framework and supports multi-prompt optimization. -
Contributed Adapters – see our adapter templates and issue tracker to request new integrations.
- DefaultAdapter - System Prompt Optimization for a single-turn task.
- DSPy Full Program Adapter - Evolves entire DSPy programs including signatures, modules, and control flow. Achieves 93% accuracy on MATH benchmark (vs 67% with basic DSPy ChainOfThought).
- Generic RAG Adapter - Vector store-agnostic RAG optimization supporting ChromaDB, Weaviate, Qdrant, Pinecone, and more. Optimizes query reformulation, context synthesis, answer generation, and document reranking prompts.
- MCP Adapter - Optimize Model Context Protocol (MCP) tool usage. Supports local stdio servers, remote SSE/HTTP servers, and optimizes tool descriptions and system prompts.
- TerminalBench Adapter - Easily integrating GEPA into a Terminus, a sophisticated external agentic pipeline, and optimizing the agents' system prompt.
- AnyMaths Adapter - Adapter for optimizing mathematical problem-solving and reasoning tasks. Contributed by @egmaminta.
-
GEPA uses
- Context Compression using GEPA
- GEPA Integration into SuperOptiX-AI
- GEPA for Observable Javascript
- bandit_dspy
- GEPA in Go Programming Language
- 100% accuracy using GEPA on the clock-hands problem
- Prompt Optimization for Reliable Backdoor Detection in AI-Generated Code
- Teaching LLMs to Diagnose Production Incidents with ATLAS+GEPA
- DataBricks: Building State-of-the-Art Enterprise Agents 90x Cheaper with GEPA
- comet-ml/opik adds support for GEPA
- Tuning small models (Gemma3-1B) for writing fiction
- Cut OCR Error Rates by upto 38% across model classes (Gemini 2.5 Pro, 2.5 Flash, 2.0 Flash)
- Optimizing a Data Analysis coding agent with GEPA, using execution-guided feedback on real-world workloads
- Generating Naruto (Anime) style dialogues with GPT-4o-mini using GEPA
- Augmenting RL-tuned models with GEPA: Achieving +142% student performance improvement by augmenting a RL-tuned teacher with GEPA
- DeepResearch Agent Optimized with GEPA
- Boosting Sanskrit QA: Finetuning EmbeddingGemma with 50k GEPA generated synthetic data samples (Tweet), (Code)
- Simulating Realistic Market Research Focus Groups with GEPA-Optimized AI Personas
- Optimizing Google ADK Agents' SOP using GEPA
- HuggingFace Cookbook on prompt optimization for with DSPy and GEPA
- OpenAI Cookbook showing how to build self-evolving agents using GEPA
If you use this repository, or the GEPA algorithm, kindly cite:
@misc{agrawal2025gepareflectivepromptevolution,
title={GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning},
author={Lakshya A Agrawal and Shangyin Tan and Dilara Soylu and Noah Ziems and Rishi Khare and Krista Opsahl-Ong and Arnav Singhvi and Herumb Shandilya and Michael J Ryan and Meng Jiang and Christopher Potts and Koushik Sen and Alexandros G. Dimakis and Ion Stoica and Dan Klein and Matei Zaharia and Omar Khattab},
year={2025},
eprint={2507.19457},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.19457},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for gepa
Similar Open Source Tools
gepa
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.

magpie
This is the official repository for 'Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing'. Magpie is a tool designed to synthesize high-quality instruction data at scale by extracting it directly from an aligned Large Language Models (LLMs). It aims to democratize AI by generating large-scale alignment data and enhancing the transparency of model alignment processes. Magpie has been tested on various model families and can be used to fine-tune models for improved performance on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.

Quantus
Quantus is a toolkit designed for the evaluation of neural network explanations. It offers more than 30 metrics in 6 categories for eXplainable Artificial Intelligence (XAI) evaluation. The toolkit supports different data types (image, time-series, tabular, NLP) and models (PyTorch, TensorFlow). It provides built-in support for explanation methods like captum, tf-explain, and zennit. Quantus is under active development and aims to provide a comprehensive set of quantitative evaluation metrics for XAI methods.

llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.

MME-RealWorld
MME-RealWorld is a benchmark designed to address real-world applications with practical relevance, featuring 13,366 high-resolution images and 29,429 annotations across 43 tasks. It aims to provide substantial recognition challenges and overcome common barriers in existing Multimodal Large Language Model benchmarks, such as small data scale, restricted data quality, and insufficient task difficulty. The dataset offers advantages in data scale, data quality, task difficulty, and real-world utility compared to existing benchmarks. It also includes a Chinese version with additional images and QA pairs focused on Chinese scenarios.

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.

merlin
Merlin is a groundbreaking model capable of generating natural language responses intricately linked with object trajectories of multiple images. It excels in predicting and reasoning about future events based on initial observations, showcasing unprecedented capability in future prediction and reasoning. Merlin achieves state-of-the-art performance on the Future Reasoning Benchmark and multiple existing multimodal language models benchmarks, demonstrating powerful multi-modal general ability and foresight minds.

semlib
Semlib is a Python library for building data processing and data analysis pipelines that leverage the power of large language models (LLMs). It provides functional programming primitives like map, reduce, sort, and filter, programmed with natural language descriptions. Semlib handles complexities such as prompting, parsing, concurrency control, caching, and cost tracking. The library breaks down sophisticated data processing tasks into simpler steps to improve quality, feasibility, latency, cost, security, and flexibility of data processing tasks.

RLHF-Reward-Modeling
This repository contains code for training reward models for Deep Reinforcement Learning-based Reward-modulated Hierarchical Fine-tuning (DRL-based RLHF), Iterative Selection Fine-tuning (Rejection sampling fine-tuning), and iterative Decision Policy Optimization (DPO). The reward models are trained using a Bradley-Terry model based on the Gemma and Mistral language models. The resulting reward models achieve state-of-the-art performance on the RewardBench leaderboard for reward models with base models of up to 13B parameters.

SwiftSage
SwiftSage is a tool designed for conducting experiments in the field of machine learning and artificial intelligence. It provides a platform for researchers and developers to implement and test various algorithms and models. The tool is particularly useful for exploring new ideas and conducting experiments in a controlled environment. SwiftSage aims to streamline the process of developing and testing machine learning models, making it easier for users to iterate on their ideas and achieve better results. With its user-friendly interface and powerful features, SwiftSage is a valuable tool for anyone working in the field of AI and ML.

LongBench
LongBench v2 is a benchmark designed to assess the ability of large language models (LLMs) to handle long-context problems requiring deep understanding and reasoning across various real-world multitasks. It consists of 503 challenging multiple-choice questions with contexts ranging from 8k to 2M words, covering six major task categories. The dataset is collected from nearly 100 highly educated individuals with diverse professional backgrounds and is designed to be challenging even for human experts. The evaluation results highlight the importance of enhanced reasoning ability and scaling inference-time compute to tackle the long-context challenges in LongBench v2.
PocketFlow
Pocket Flow is a 100-line minimalist LLM framework designed for (Multi-)Agents, Task Decomposition, RAG, etc. It aims to be the framework used by LLMs, focusing on stripping away low-level implementation details and emphasizing high-level programming paradigms. Pocket Flow serves as a learning resource and provides a core abstraction of a nested directed graph for breaking down tasks into multiple steps.

R1-Searcher
R1-searcher is a tool designed to incentivize the search capability in large reasoning models (LRMs) via reinforcement learning. It enables LRMs to invoke web search and obtain external information during the reasoning process by utilizing a two-stage outcome-supervision reinforcement learning approach. The tool does not require instruction fine-tuning for cold start and is compatible with existing Base LLMs or Chat LLMs. It includes training code, inference code, model checkpoints, and a detailed technical report.

MiniCheck
MiniCheck is an efficient fact-checking tool designed to verify claims against grounding documents using large language models. It provides a sentence-level fact-checking model that can be used to evaluate the consistency of claims with the provided documents. MiniCheck offers different models, including Bespoke-MiniCheck-7B, which is the state-of-the-art and commercially usable. The tool enables users to fact-check multi-sentence claims by breaking them down into individual sentences for optimal performance. It also supports automatic prefix caching for faster inference when repeatedly fact-checking the same document with different claims.
For similar tasks
gepa
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.