
kafka-ml
Kafka-ML: connecting the data stream with ML/AI frameworks (now TensorFlow and PyTorch!)
Stars: 163

Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.
README:
Kafka-ML is a framework to manage the pipeline of Tensorflow/Keras and PyTorch (Ignite) machine learning (ML) models on Kubernetes. The pipeline allows the design, training, and inference of ML models. The training and inference datasets for the ML models can be fed through Apache Kafka, thus they can be directly connected to data streams like the ones provided by the IoT.
ML models can be easily defined in the Web UI with no need for external libraries and executions, providing an accessible tool for both experts and non-experts on ML/AI.

You can find more information about Kafka-ML and its architecture in the open-access publication below:
C. Martín, P. Langendoerfer, P. Zarrin, M. Díaz and B. Rubio
> Kafka-ML: connecting the data stream with ML/AI frameworks
Future Generation Computer Systems, 2022, vol. 126, p. 15-33
> 10.1016/j.future.2021.07.037
If you wish to reuse Kafka-ML, please properly cite the above mentioned paper. Below you can find a BibTex reference:
@article{martin2022kafka,
title={Kafka-ML: connecting the data stream with ML/AI frameworks},
author={Mart{\'\i}n, Cristian and Langendoerfer, Peter and Zarrin, Pouya Soltani and D{\'\i}az, Manuel and Rubio, Bartolom{\'e}},
journal={Future Generation Computer Systems},
volume={126},
pages={15--33},
year={2022},
publisher={Elsevier}
}
Kafka-ML article has been selected as Spring 2022 Editor’s Choice Paper at Future Generation Computer Systems! :blush: :book: :rocket:
- [29/04/2021] Integration of distributed models.
- [05/11/2021] Automation of data types and reshapes for the training module.
- [20/01/2022] Added GPU support. ML Code has been taken out of backend.
- [04/03/2022] Added PyTorch ML Framework support!
- [08/04/2022] Added support for learning curves visualization, confusion matrix generation and small changes on metrics visualization. Now datasets can be splitted into training, validation and test.
- [26/05/2022] Included support for visualization of prediction data. Now you can easily prototype and visualize your ML/AI application. You can train models, deploy them for inference, and visualize your prediction data just with data streams.
- [14/07/2022] Added incremental training support and configuration of training parameters for the deployment of distributed models.
- [02/09/2022] Added real-time display of training parameters.
- [26/12/2022] Added indefinite incremental training support.
- [07/07/2023] Added federated training support (currently only for Tensorflow/Keras models).
- [28/09/2023] Federated learning enabled for distributed neural networks and incremental training.
- [05/07/2024] Added semi-supervised learning support.
For a basic local installation, we recommend using Docker Desktop with Kubernetes enabled. Please follow the installation guide on Docker's website. To enable Kubernetes, refer to Enable Kubernetes
Once Kubernetes is running, open a terminal and run the following command:
# Uncomment only if you are running Kafka-ML on Apple Silicon
# export DOCKER_DEFAULT_PLATFORM=linux/amd64
kubectl apply -k "github.com/ertis-research/kafka-ml/kustomize/local?ref=v1.2"This will install all the required components of Kafka-ML, plus Kafka on the
namespace kafkaml. The UI will be available at http://localhost/ . You can
continue with the Usage section to see how you can use Kafka-ML!
For a more advanced installation on Kubernetes, please refer to the kustomization guide
To follow this tutorial, please deploy Kafka-ML as indicated in Deploy Kafka-ML in a fast way or Installation and development.
Create a model in the Models tab with just a TF/Keras model source code and some imports/functions if needed. Maybe this model for the MNIST dataset is a simple way to start:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)Something similar should be done in case you wish to use PyTorch:
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 10),
nn.Softmax()
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
def loss_fn(self):
return nn.CrossEntropyLoss()
def optimizer(self):
return torch.optim.Adam(model.parameters(), lr=0.001)
def metrics(self):
val_metrics = {
"accuracy": Accuracy(),
"loss": Loss(self.loss_fn())
}
return val_metrics
model = NeuralNetwork()Note that functions 'loss_fn', 'optimizer', and 'metrics' must necessarily be defined.
Insert the ML code into the Kafka-ML UI.


A configuration is a set of models that can be grouped for training. This can be useful when you want to evaluate and compare the metrics (e.g, loss and accuracy) of a set of models or just to define a group of them that can be trained with the same data stream in parallel. A configuration can also contain a single ML model.


Change the batch size, training and validation parameters in the Deployment form. Use the same format and parameters than TensorFlow methods fit and evaluate respectively. Validation parameters are optional (they are only used if validation_rate>0 or test_rate>0 in the stream data received).
Note: If you do not have the GPU(s) properly tuned, set the "GPU Memory usage
estimation" parameter to 0. Otherwise, the training component will be
deployed, but in a pending state waiting to allocate GPU memory. If the pod is
described, it will show a aliyun.com/gpu-mem related warning. If you wish, you
can mark the last field for the creation of the confusion matrix at the end of
the training.

Once the configuration is deployed, you will see one training result per model in the configuration. Models are now ready to be trained and receive stream data.

Now, it is time to ingest the model(s) with your data stream for training and maybe evaluation.
If you have used the MNIST model you can use the example
mnist_dataset_training_example.py. You only need to configure the
deployment_id attribute to the one generated in Kafka-ML, maybe it is still 1.
This is the way to match data streams with configurations and models during
training. You may need to install the Python libraries listed in
datasources/requirements.txt.
If so, please execute the MNIST example for training:
python examples/MNIST_RAW_format/mnist_dataset_training_example.py
You can use your own example using the AvroSink (for Apache Avro types) and RawSink (for simple types) sink libraries to send training and evaluation data to Kafka. Remember, you always have to configure the deployment_id attribute to the one generated in Kafka-ML.
Once sent the data stream, and deployed and trained the models, you will see the models metrics and results in Kafka-ML. You can download now the trained models, or just continue the ML pipeline to deploy a model for inference.

If you wish to visualise the generated confusion matrix (in case it has been indicated) or to visualise some training and validation metrics (if any) per epoch, you can access for each training result to the following view.

In addition, from this view you can access to this data in a more generic way in JSON, allowing you to generate new plots and other information for your reports.
When deploying a model for inference, the parameters for the input data stream will be automatically configured based on previous data streams received, you might also change this. Mostly you will have to configure the number of replicas you want to deploy for inference and the Kafka topics for input data (values to predict) and output data (predictions).
Note: If you do not have the GPU(s) properly tuned, set the "GPU Memory usage
estimation" parameter to 0. Otherwise, the inference component will be
deployed, but in a pending state waiting to allocate GPU memory. If the pod is
described, it will show a aliyun.com/gpu-mem related warning.

Finally, test the inference deployed using the MNIST example for inference in the topics deployed:
python examples/MNIST_RAW_format/mnist_dataset_inference_example.py
In the visualization tab, you can easily visualize your deployed models. First thing, you need to configure how your model prediction data will be visualized. Here is the example for the MNIST dataset:
{
"average_updated": false,
"average_window": 10000,
"type": "classification",
"labels": [
{
"id": 0,
"color": "#fff100",
"label": "Zero"
},
{
"id": 1,
"color": "#ff8c00",
"label": "One"
},
{
"id": 2,
"color": "#e81123",
"label": "Two"
},
{
"id": 3,
"color": "#ec008c",
"label": "Three"
},
{
"id": 4,
"color": "#68217a",
"label": "Four"
},
{
"id": 5,
"color": "#00188f",
"label": "Five"
},
{
"id": 6,
"color": "#00bcf2",
"label": "Six"
},
{
"id": 7,
"color": "#00b294",
"label": "Seven"
},
{
"id": 8,
"color": "#009e49",
"label": "Eight"
},
{
"id": 9,
"color": "#bad80a",
"label": "Nine"
}
]
}You can specify the two types of visualization: 'regression' and 'classification'. In classification mode, 'average_update' determines if you want to have the current status displayed based on the higher average status, and 'average_window' determines the windows for calculating the average.
For each output of your model, you have to define a label. 'id' represents the position of the param in the model output (e.g., suppose you have a temperature output as the second parameter of your model), and with 'color' and 'label' you can set a color and label to display for the param.
Once you set the configuration, you must also set the output topic where the model is deployed, 'mnist-out' in our last example. After this, visualization displays your data.
Here is an example in classification mode:

And in regression mode:

Create a distributed model with just a TF/Keras model source code and some imports/functions if needed. Maybe this distributed model consisting of three sub-models for the MNIST dataset is a simple way to start:
edge_input = keras.Input(shape=(28,28,1), name='input_img')
x = tf.keras.layers.Conv2D(28, kernel_size=(3,3), name='conv2d')(edge_input)
x = tf.keras.layers.MaxPooling2D(pool_size=(2,2), name='maxpooling')(x)
x = tf.keras.layers.Flatten(name='flatten')(x)
output_to_fog = tf.keras.layers.Dense(64, activation=tf.nn.relu, name='output_to_fog')(x)
edge_output = tf.keras.layers.Dense(10, activation=tf.nn.softmax, name='edge_output')(output_to_fog)
edge_model = keras.Model(inputs=[edge_input], outputs=[output_to_fog, edge_output], name='edge_model')
fog_input = keras.Input(shape=64, name='fog_input')
output_to_cloud = tf.keras.layers.Dense(64, activation=tf.nn.relu, name='output_to_cloud')(fog_input)
fog_output = tf.keras.layers.Dense(10, activation=tf.nn.softmax, name='fog_output')(output_to_cloud)
fog_model = keras.Model(inputs=[fog_input], outputs=[output_to_cloud, fog_output], name='fog_model')
cloud_input = keras.Input(shape=64, name='cloud_input')
x = tf.keras.layers.Dense(64, activation=tf.nn.relu, name='relu1')(cloud_input)
x = tf.keras.layers.Dense(128, activation=tf.nn.relu, name='relu2')(x)
x = tf.keras.layers.Dropout(0.2)(x)
cloud_output = tf.keras.layers.Dense(10, activation=tf.nn.softmax, name='cloud_output')(x)
cloud_model = keras.Model(inputs=cloud_input, outputs=[cloud_output], name='cloud_model')Insert the ML code of each sub-model into the Kafka-ML UI separately. You will have to specify the hierarchical relationships between the sub-models through the "Upper model" field of the form (before you will have to check the distributed box). In the example case proposed it has to be defined the following relationships: the upper model of the Edge sub-model is the Fog and the upper model of the Fog sub-model is the Cloud (Cloud sub-model is placed at the top of the distributed chain so it does not have any upper model).

Kafka-ML will only show those sub-models which are on the top of the distributed chain. Choosing one of them will add its corresponding full distributed model to the configuration.

Deploy the configuration of distributed sub-models in Kubernetes for training.

Change the optimizer, learning rate, loss function, metrics, batch size, training and validation parameters in the Deployment form. Use the same format and parameters than TensorFlow methods fit and evaluate respectively. Optimizer, learning rate, loss function and metrics parameters are optional, so if not specified, default values are taken, which are: adam, 0.001, sparse_categorical_crossentropy and sparse_categorical_accuracy, respectively. Validation parameters are also optional (they are only used if validation_rate>0 or test_rate>0 in the stream data received).

Once the configuration is deployed, you will see one training result per sub-model in the configuration. Full distributed model is now ready to be trained and receive stream data.

Now, it is time to ingest the distributed model with your data stream for training and maybe evaluation.
If you have used the MNIST distributed model you can use the example
mnist_dataset_training_example.py. You only need to configure the
deployment_id attribute to the one generated in Kafka-ML, maybe it is still 1.
This is the way to match data streams with configurations and models during
training. You may need to install the Python libraries listed in
datasources/requirements.txt.
If so, please execute the MNIST example for training:
python examples/MNIST_RAW_format/mnist_dataset_training_example.py
Once sent the data stream, and deployed and trained the full distributed model, you will see the sub-models metrics and results in Kafka-ML. You can download now the trained sub-models, or just continue the ML pipeline to deploy a model for inference.

When deploying a sub-model for inference, the parameters for the input data stream will be automatically configured based on previous data streams received, you might also change this. Mostly you will have to configure the number of replicas you want to deploy for inference and the Kafka topics for input data (values to predict) and output data (predictions). Lastly, in case you are deploying a sub-model for inference which is not the last one in the distributed chain, you will also have to specify one more topic for upper data (partial predictions) and a limit number (between 0 and 1). These two fields work as follows: on the one hand, if your deployed inference gets lower predictions values than the limit it will send partial predictions to its upper model using the upper data topic in order to continue the data processing there; on the other hand, if your deployed inference gets higher predictions values than the limit it will send these final results to the output topic.

Finally, test the inference deployed using the MNIST example for inference in the topics deployed:
python examples/MNIST_RAW_format/mnist_dataset_inference_example.py
Semi-supervised learning is a type of machine learning that falls between supervised and unsupervised learning. In supervised learning, the model is trained on a labeled dataset, where each example is associated with a correct output or label. In unsupervised learning, the model is trained on an unlabeled dataset, and it must learn to identify patterns or structure in the data without any explicit guidance. Semi-supervised learning, on the other hand, involves training a machine learning model on a dataset that contains both labeled and unlabeled examples. The idea behind semi-supervised learning is to use the small amount of labeled data to guide the learning process, while also leveraging the much larger amount of unlabeled data to improve the model's performance.
Currently, the only framework that supports semi-supervised training is TensorFlow. In this case, the usage example will be the same as the one presented for the single models, only the configuration deployment form will change and will now contain more fields.
As before, change the fields as desired. The new semi-supervised fields are: unsupervised_rounds and confidence. Unsupervised rounds are used to define the number of rounds to iterate through the so far unlabelled data. Confidence is used to specify the minimum reliance that the model has to have in a prediction of an unlabelled data in order to subsequently assign that label to it. They are not required, so if not specified, default values are taken, which are: 5 and 0.9, respectively.

Once the configuration is deployed, you will see one training result per model in the configuration. Models are now ready to be trained and receive stream data. Now, it is time to ingest the model(s) with your data stream for training.
If you have used the MNIST model you can use the example
mnist_dataset_unsupervised_training_example.py. You may need to install the Python
libraries listed in datasources/requirements.txt.
If so, please execute the incremental MNIST example for training:
python examples/MNIST_RAW_format/mnist_dataset_unsupervised_training_example.py
Incremental training is a machine learning method in which input data is continuously used to extend the existing model's knowledge i.e. to further train the model. It represents a dynamic learning technique that can be applied when training data becomes available gradually over time or its size is out of system memory limits.
Currently, the only framework that supports incremental training is TensorFlow. In this case, the usage example will be the same as the one presented for the single models, only the configuration deployment form will change and will now contain more fields.
As before, change the fields as desired. For this case, there are two types of deployments: time-limited and indefinite. The new time-limited incremental field is: stream timeout. The stream timeout parameter is used to configure the duration for which the dataset will block for new messages before timing out. It is not required, so if not specified, default value is taken, which is: 60000.

The new indefinite incremental fields are: monitoring metric, direction, and improvement. The monitoring metric is used to keep track of a specific parameter (of the user's choice) within the validation phase of the model's training. The direction is used to let Kafka-ML know in which direction the monitoring metric is improving (as it is configurable). Finally, the improvement serves to establish a range from which an automatic deployment of the model for inference should be carried out, since this training is indefinite in time. Monitoring metric and direction must be specified. Improvement is not required, so if not specified, default value is taken, which is: 0.05.

Once the configuration is deployed, you will see one training result per model in the configuration. Models are now ready to be trained and receive stream data. Now, it is time to ingest the model(s) with your data stream for training.
If you have used the MNIST model you can use the example
mnist_dataset_online_training_example.py. You may need to install the Python
libraries listed in datasources/requirements.txt.
If so, please execute the incremental MNIST example for training:
python examples/MNIST_RAW_format/mnist_dataset_online_training_example.py
Federated learning is a privacy-preserving machine learning approach that enables collaborative model training across multiple decentralized devices without the need to transfer sensitive data to a central location. In federated learning, instead of sending raw data to a central server for training, local devices perform the training on their own data and only share model updates or gradients with the central server. These updates are then aggregated to create an improved global model, which is sent back to the devices for further training. This distributed learning approach allows for the benefits of collective intelligence while ensuring data privacy and reducing the need for large-scale data transfers. Federated learning has gained popularity in scenarios where data is sensitive or resides in diverse locations, such as mobile devices, healthcare systems, and IoT networks.
Currently, the only framework that supports federated learning is TensorFlow. In this case, the usage example will be the same as the one presented for the single models, only the configuration deployment form will change and will now contain more fields.
As before, change the fields as desired. The new incremental fields are: aggregation_rounds, minimun_data, data_restriction and aggregation strategy. The aggregation_rounds parameter is used to configure the number of rounds that the model will be aggregated (an aggregation round is a round in which the model is trained with the data of the devices and then aggregated with the other models). The minimun_data parameter is the minimum number of data that a device must have to be able to participate in the training. The data_restriction parameter is the data pattern (such as input shape, labels, etc.) that the data must have to be able to participate. Finally, the aggregation strategy parameter is the strategy that will be used to aggregate the models. Currently, the only strategy available is the average strategy, which consists of averaging the weights of the models.

Once the configuration is deployed, you will see one training result per model in the configuration. Models are now ready to be aggregated and they are sent to the devices for training. Now, if the devices have data that meets the requirements, they will train the model and send the weights to the server for aggregation. Once the aggregation is finished, the new model will be sent to the devices for training again. This process will be repeated until the number of rounds specified in the configuration is reached.
If you have used the MNIST model you can use the example
mnist_dataset_federated_training_example.py. You only need to configure the
deployment_id attribute to the one generated in Kafka-ML, maybe it is still 1.
This is the way to match data streams with configurations and models during
training. You may need to install the Python libraries listed in
datasources/requirements.txt.
If so, please execute the incremental MNIST example for training:
python examples/FEDERATED_MNIST_RAW_format/mnist_dataset_federated_training_example.py
In this repository you can find files to build Kafka-ML in case you want to contribute.
In case you want to build Kafka-ML in a fast way, you should set the variable
LOCAL_BUILD to true in build scripts and modify the deployments files to use
the local images. Once that is done, you can run the build scripts.
By default, Kafka-ML will be built using CPU-only images. If you desire to build
Kafka-ML with images enabled for GPU acceleration, the Dockerfile and
requirements.txt files of mlcode_executor, model_inference and
model_training modules must be modified as indicated in those files.
In case you want to build Kafka-ML step-by-step, then follow the following steps:
-
You may need to deploy a local register to upload your Docker images. You can deploy it in the port 5000:
docker run -d -p 5000:5000 --restart=always --name registry registry:2
-
Build the backend and push the image into the local register:
cd backend docker build --tag localhost:5000/backend . docker push localhost:5000/backend
-
Build ML Code Executors and push images into the local register:
3.1. Build the TensorFlow Code Executor and push the image into the local register:
cd mlcode_executor/tfexecutor docker build --tag localhost:5000/tfexecutor . docker push localhost:5000/tfexecutor
3.2. Build the PyTorch Code Executor and push the image into the local register:
cd mlcode_executor/pthexecutor docker build --tag localhost:5000/pthexecutor . docker push localhost:5000/pthexecutor
-
Build the model_training components and push the images into the local register:
cd model_training/tensorflow docker build --tag localhost:5000/tensorflow_model_training . docker push localhost:5000/tensorflow_model_training cd ../pytorch docker build --tag localhost:5000/pytorch_model_training . docker push localhost:5000/pytorch_model_training
-
Build the kafka_control_logger component and push the image into the local register:
cd kafka_control_logger docker build --tag localhost:5000/kafka_control_logger . docker push localhost:5000/kafka_control_logger
-
Build the model_inference component and push the image into the local register:
cd model_inference/tensorflow docker build --tag localhost:5000/tensorflow_model_inference . docker push localhost:5000/tensorflow_model_inference cd ../pytorch docker build --tag localhost:5000/pytorch_model_inference . docker push localhost:5000/pytorch_model_inference
-
Install the libraries and execute the frontend:
cd frontend npm install # nvm install 10 & nvm use 10.24.1 npm i -g @angular/[email protected] ng build -c production docker build --tag localhost:5000/frontend . docker push localhost:5000/frontend
Once built the images, you can deploy the system components in Kubernetes following this order:
kubectl apply -f zookeeper-pod.yaml
kubectl apply -f zookeeper-service.yaml
kubectl apply -f kafka-pod.yaml
kubectl apply -f kafka-service.yaml
kubectl apply -f backend-deployment.yaml
kubectl apply -f backend-service.yaml
kubectl apply -f frontend-deployment.yaml
kubectl apply -f frontend-service.yaml
kubectl apply -f tf-executor-deployment.yaml
kubectl apply -f tf-executor-service.yaml
kubectl apply -f pth-executor-deployment.yaml
kubectl apply -f pth-executor-service.yaml
kubectl apply -f kafka-control-logger-deployment.yaml
Finally, you will be able to access the Kafka-ML Web UI: http://localhost/
The first thing to keep in mind is that the images we compiled earlier were intended for a single node cluster (localhost) and will not be able to be downloaded from a distributed Kubernetes cluster. Therefore, assuming that we are going to upload them into a registry as before and on a node with IP x.x.x.x.x, we would have to do the same for all the images as for the following backend example:
cd backend
docker build --tag x.x.x.x:5000/backend .
docker push x.x.x.x:5000/backendNow, we have to update the location of these images (tr) in the
backend-deployment.yaml file:
containers:
- - image: localhost:5000/backend
+ - image: x.x.x.x:5000/backend
- name: BOOTSTRAP_SERVERS
value: kafka-cluster:9092 # You can specify all the Kafka Bootstrap Servers that you have. e.g.: kafka-cluster-2:9092,kafka-cluster-3:9092,kafka-cluster-4:9092,kafka-cluster-5:9092,kafka-cluster-6:9092,kafka-cluster-7:9092
- name: TRAINING_MODEL_IMAGE
- value: localhost:5000/model_training
+ value: x.x.x.x:5000/model_training
- name: INFERENCE_MODEL_IMAGE
- value: localhost:5000/model_inference
+ value: x.x.x.x:5000/model_inference
- name: FRONTEND_URL
- value: http://localhost
+ value: http://x.x.x.xThe same should be done at frontend-deployment.yaml file:
containers:
- - image: localhost:5000/backend
+ - image: x.x.x.x:5000/backend
- name: BACKEND_URL
- value: http://localhost:8000
+ value: http://x.x.x.x:8000To be able to deploy components in a Kubernetes cluster, we need to create a service account, give access to that account and generate a token:
$ sudo kubectl create serviceaccount k8sadmin -n kube-system
$ sudo kubectl create clusterrolebinding k8sadmin --clusterrole=cluster-admin --serviceaccount=kube-system:k8sadmin
$ sudo kubectl -n kube-system describe secret $(sudo kubectl -n kube-system get secret | (grep k8sadmin || echo "$_") | awk '{print $1}') | grep token: | awk '{print $2}'With the obtained token in the last step, we have to change the KUBE_TOKEN
env var to include it, and the KUBE_HOST var to include the URL of the
Kubernetes master (e.g., https://IP_MASTER:6443) in the
backend-deployment.yaml file:
- name: KUBE_TOKEN
value: # include token here (and remove #)
- name: KUBE_HOST
value: # include kubernetes master URL here
Finally, to allow access to the back-end from outside Kubernetes, we can do this
by assigning a node cluster IP available to the back-end service in Kubernetes.
For example, given the IP y.y.y.y.y of a node in the cluster, we could include
it in the backend-service.yaml file:
type: LoadBalancer
+ externalIPs:
+ - y.y.y.y.y.y
Add this IP also to the ALLOWED_HOSTS env var in the
backend-deployment.yaml file:
- name: ALLOWED_HOSTS
value: y.y.y.y, localhost
The following steps are required in order to use GPU acceleration in Kafka-ML and Kubernetes. These steps are required to be performed in all the Kubernetes nodes.
- GPU Driver installation
# SSH into the worker machine with GPU
$ ssh USERNAME@EXTERNAL_IP
# Verify ubuntu driver
$ sudo apt install ubuntu-drivers-common
$ ubuntu-drivers devices
# Install the recommended driver
$ sudo ubuntu-drivers autoinstall
# Reboot the machine
$ sudo reboot
# After the reboot, test if the driver is installed correctly
$ nvidia-smi- Nvidia Docker installation
# SSH into the worker machine with GPU
$ ssh USERNAME@EXTERNAL_IP
# Add the package repositories
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
$ sudo apt-get update && sudo apt-get install -y nvidia-docker2
$ sudo systemctl restart docker- Modify the following file
# SSH into the worker machine with GPU
$ ssh USERNAME@EXTERNAL_IP
$ sudo tee /etc/docker/daemon.json <<EOF
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
EOF
$ sudo pkill -SIGHUP docker
$ sudo reboot- Kubernetes GPU Sharing extension installation
# From your local machine that has access to the Kubernetes API
$ curl -O https://raw.githubusercontent.com/AliyunContainerService/gpushare-scheduler-extender/master/config/gpushare-schd-extender.yaml
$ kubectl create -f gpushare-schd-extender.yaml
$ wget https://raw.githubusercontent.com/AliyunContainerService/gpushare-device-plugin/master/device-plugin-rbac.yaml
$ kubectl create -f device-plugin-rbac.yaml
$ wget https://raw.githubusercontent.com/AliyunContainerService/gpushare-device-plugin/master/device-plugin-ds.yaml
# update the local file so the first line is 'apiVersion: apps/v1'
$ kubectl create -f device-plugin-ds.yaml
# From your local machine that has access to the Kubernetes API
$ kubectl label node worker-gpu-0 gpushare=trueThanks to Sven Degroote from ML6team for the GPU and Kubernetes setup documentation.
-
Carnero, A., Martín, C., Torres, D. R., Garrido, D., Díaz, M., & Rubio, B. (2021). Managing and Deploying Distributed and Deep Neural Models through Kafka-ML in the Cloud-to-Things Continuum. IEEE Access, 9, 125478-125495.
-
Martín, C., Langendoerfer, P., Zarrin, P. S., Díaz, M., & Rubio, B. (2022). Kafka-ML: connecting the data stream with ML/AI frameworks. Future Generation Computer Systems, 126, 15-33.
-
Torres, D. R., Martín, C., Rubio, B., & Díaz, M. (2021). An open source framework based on Kafka-ML for DDNN inference over the Cloud-to-Things continuum. Journal of Systems Architecture, 102214.
-
Chaves, A. J., Martín, C., & Díaz, M. (2023). The orchestration of Machine Learning frameworks with data streams and GPU acceleration in Kafka‐ML: A deep‐learning performance comparative. Expert Systems, e13287.
-
Chaves, A. J., Martín, C., & Díaz, M. (2024). Towards flexible data stream collaboration: Federated Learning in Kafka-ML. Internet of Things, 101036.
MIT
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for kafka-ml
Similar Open Source Tools
kafka-ml
Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.

MegatronApp
MegatronApp is a toolchain built around the Megatron-LM training framework, offering performance tuning, slow-node detection, and training-process visualization. It includes modules like MegaScan for anomaly detection, MegaFBD for forward-backward decoupling, MegaDPP for dynamic pipeline planning, and MegaScope for visualization. The tool aims to enhance large-scale distributed training by providing valuable capabilities and insights.

hi-ml
The Microsoft Health Intelligence Machine Learning Toolbox is a repository that provides low-level and high-level building blocks for Machine Learning / AI researchers and practitioners. It simplifies and streamlines work on deep learning models for healthcare and life sciences by offering tested components such as data loaders, pre-processing tools, deep learning models, and cloud integration utilities. The repository includes two Python packages, 'hi-ml-azure' for helper functions in AzureML, 'hi-ml' for ML components, and 'hi-ml-cpath' for models and workflows related to histopathology images.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.

rag-experiment-accelerator
The RAG Experiment Accelerator is a versatile tool that helps you conduct experiments and evaluations using Azure AI Search and RAG pattern. It offers a rich set of features, including experiment setup, integration with Azure AI Search, Azure Machine Learning, MLFlow, and Azure OpenAI, multiple document chunking strategies, query generation, multiple search types, sub-querying, re-ranking, metrics and evaluation, report generation, and multi-lingual support. The tool is designed to make it easier and faster to run experiments and evaluations of search queries and quality of response from OpenAI, and is useful for researchers, data scientists, and developers who want to test the performance of different search and OpenAI related hyperparameters, compare the effectiveness of various search strategies, fine-tune and optimize parameters, find the best combination of hyperparameters, and generate detailed reports and visualizations from experiment results.

RLHF-Reward-Modeling
This repository contains code for training reward models for Deep Reinforcement Learning-based Reward-modulated Hierarchical Fine-tuning (DRL-based RLHF), Iterative Selection Fine-tuning (Rejection sampling fine-tuning), and iterative Decision Policy Optimization (DPO). The reward models are trained using a Bradley-Terry model based on the Gemma and Mistral language models. The resulting reward models achieve state-of-the-art performance on the RewardBench leaderboard for reward models with base models of up to 13B parameters.

fuse-med-ml
FuseMedML is a Python framework designed to accelerate machine learning-based discovery in the medical field by promoting code reuse. It provides a flexible design concept where data is stored in a nested dictionary, allowing easy handling of multi-modality information. The framework includes components for creating custom models, loss functions, metrics, and data processing operators. Additionally, FuseMedML offers 'batteries included' key components such as fuse.data for data processing, fuse.eval for model evaluation, and fuse.dl for reusable deep learning components. It supports PyTorch and PyTorch Lightning libraries and encourages the creation of domain extensions for specific medical domains.

CogAgent
CogAgent is an advanced intelligent agent model designed for automating operations on graphical interfaces across various computing devices. It supports platforms like Windows, macOS, and Android, enabling users to issue commands, capture device screenshots, and perform automated operations. The model requires a minimum of 29GB of GPU memory for inference at BF16 precision and offers capabilities for executing tasks like sending Christmas greetings and sending emails. Users can interact with the model by providing task descriptions, platform specifications, and desired output formats.

MiniCheck
MiniCheck is an efficient fact-checking tool designed to verify claims against grounding documents using large language models. It provides a sentence-level fact-checking model that can be used to evaluate the consistency of claims with the provided documents. MiniCheck offers different models, including Bespoke-MiniCheck-7B, which is the state-of-the-art and commercially usable. The tool enables users to fact-check multi-sentence claims by breaking them down into individual sentences for optimal performance. It also supports automatic prefix caching for faster inference when repeatedly fact-checking the same document with different claims.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

physical-AI-interpretability
Physical AI Interpretability is a toolkit for transformer-based Physical AI and robotics models, providing tools for attention mapping, feature extraction, and out-of-distribution detection. It includes methods for post-hoc attention analysis, applying Dictionary Learning into robotics, and training sparse autoencoders. The toolkit aims to enhance interpretability and understanding of AI models in physical environments.
AIW
AIW is a code base for experiments and raw data related to Alice in Wonderland, showcasing complete reasoning breakdown in state-of-the-art large language models. Users can collect experiments data using LiteLLM and TogetherAI, and plot the data using provided scripts. The tool allows for executing experiments over LiteLLM and lmsys, with options for different prompt types and AIW variations. The project also includes acknowledgments and a citation for reference.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.

monitors4codegen
This repository hosts the official code and data artifact for the paper 'Monitor-Guided Decoding of Code LMs with Static Analysis of Repository Context'. It introduces Monitor-Guided Decoding (MGD) for code generation using Language Models, where a monitor uses static analysis to guide the decoding. The repository contains datasets, evaluation scripts, inference results, a language server client 'multilspy' for static analyses, and implementation of various monitors monitoring for different properties in 3 programming languages. The monitors guide Language Models to adhere to properties like valid identifier dereferences, correct number of arguments to method calls, typestate validity of method call sequences, and more.
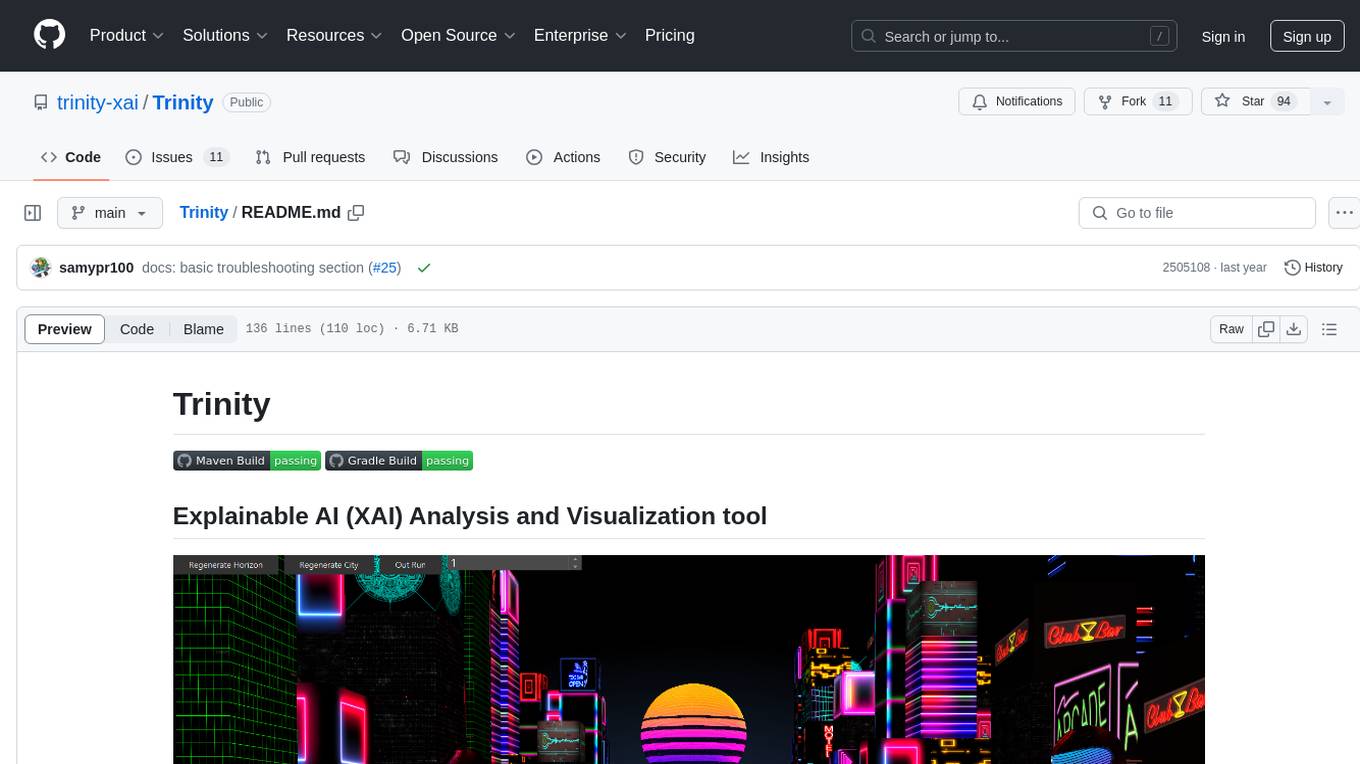
Trinity
Trinity is an Explainable AI (XAI) Analysis and Visualization tool designed for Deep Learning systems or other models performing complex classification or decoding. It provides performance analysis through interactive 3D projections that are hyper-dimensional aware, allowing users to explore hyperspace, hypersurface, projections, and manifolds. Trinity primarily works with JSON data formats and supports the visualization of FeatureVector objects. Users can analyze and visualize data points, correlate inputs with classification results, and create custom color maps for better data interpretation. Trinity has been successfully applied to various use cases including Deep Learning Object detection models, COVID gene/tissue classification, Brain Computer Interface decoders, and Large Language Model (ChatGPT) Embeddings Analysis.
For similar tasks

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.