
audioseal
Localized watermarking for AI-generated speech audios, with SOTA on robustness and very fast detector
Stars: 238
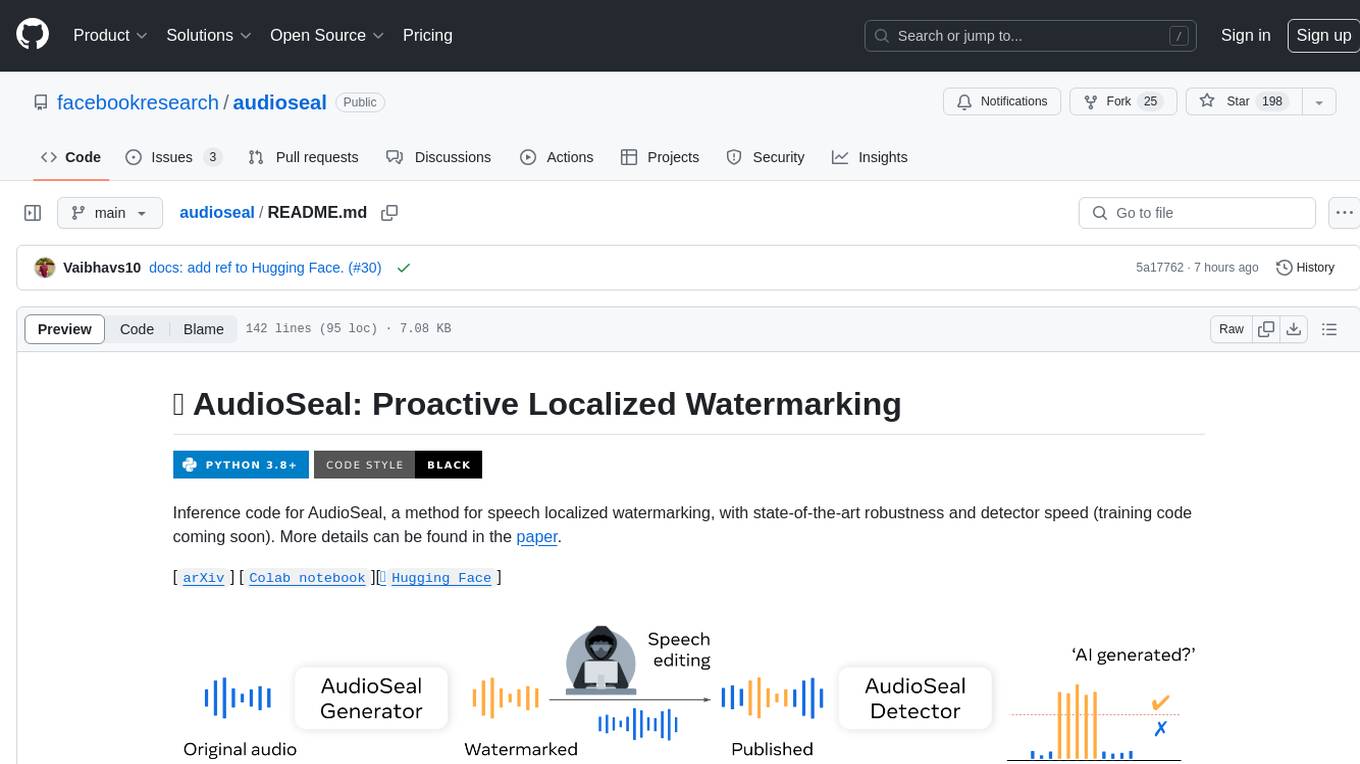
AudioSeal is a method for speech localized watermarking, designed with state-of-the-art robustness and detector speed. It jointly trains a generator to embed a watermark in audio and a detector to detect watermarked fragments in longer audios, even in the presence of editing. The tool achieves top-notch detection performance at the sample level, generates minimal alteration of signal quality, and is robust to various audio editing types. With a fast, single-pass detector, AudioSeal surpasses existing models in speed, making it ideal for large-scale and real-time applications.
README:
Inference code for AudioSeal, a method for speech localized watermarking, with state-of-the-art robustness and detector speed (training code coming soon). More details can be found in the paper.
[arXiv]
[Colab notebook][🤗Hugging Face]
- 2024-06-17: Training code is now available. Check the instruction !!!
- 2024-05-31: Our paper gets accepted at ICML'24 :)
- 2024-04-02: We have updated our license to full MIT license (including the license for the model weights) ! Now you can use AudioSeal in commercial application too !
- 2024-02-29: AudioSeal 0.1.2 is out, with more bug fixes for resampled audios and updated notebooks
We introduce AudioSeal, a method for speech localized watermarking, with state-of-the-art robustness and detector speed. It jointly trains a generator that embeds a watermark in the audio, and a detector that detects the watermarked fragments in longer audios, even in the presence of editing. Audioseal achieves state-of-the-art detection performance of both natural and synthetic speech at the sample level (1/16k second resolution), it generates limited alteration of signal quality and is robust to many types of audio editing. Audioseal is designed with a fast, single-pass detector, that significantly surpasses existing models in speed — achieving detection up to two orders of magnitude faster, making it ideal for large-scale and real-time applications.
AudioSeal requires Python >=3.8, Pytorch >= 1.13.0, omegaconf, julius, and numpy. To install from PyPI:
pip install audioseal
To install from source: Clone this repo and install in editable mode:
git clone https://github.com/facebookresearch/audioseal
cd audioseal
pip install -e .
You can find all the model checkpoints on the Hugging Face Hub. We provide the checkpoints for the following models:
- AudioSeal Generator. It takes as input an audio signal (as a waveform), and outputs a watermark of the same size as the input, that can be added to the input to watermark it. Optionally, it can also take as input a secret message of 16-bits that will be encoded in the watermark.
- AudioSeal Detector. It takes as input an audio signal (as a waveform), and outputs a probability that the input contains a watermark at each sample of the audio (every 1/16k s). Optionally, it may also output the secret message encoded in the watermark.
Note that the message is optional and has no influence on the detection output. It may be used to identify a model version for instance (up to $2**16=65536$ possible choices).
Note: We are working to release the training code for anyone wants to build their own watermarker. Stay tuned !
Audioseal provides a simple API to watermark and detect the watermarks from an audio sample. Example usage:
from audioseal import AudioSeal
# model name corresponds to the YAML card file name found in audioseal/cards
model = AudioSeal.load_generator("audioseal_wm_16bits")
# Other way is to load directly from the checkpoint
# model = Watermarker.from_pretrained(checkpoint_path, device = wav.device)
# a torch tensor of shape (batch, channels, samples) and a sample rate
# It is important to process the audio to the same sample rate as the model
# expectes. In our case, we support 16khz audio
wav, sr = ..., 16000
watermark = model.get_watermark(wav, sr)
# Optional: you can add a 16-bit message to embed in the watermark
# msg = torch.randint(0, 2, (wav.shape(0), model.msg_processor.nbits), device=wav.device)
# watermark = model.get_watermark(wav, message = msg)
watermarked_audio = wav + watermark
detector = AudioSeal.load_detector("audioseal_detector_16bits")
# To detect the messages in the high-level.
result, message = detector.detect_watermark(watermarked_audio, sr)
print(result) # result is a float number indicating the probability of the audio being watermarked,
print(message) # message is a binary vector of 16 bits
# To detect the messages in the low-level.
result, message = detector(watermarked_audio, sr)
# result is a tensor of size batch x 2 x frames, indicating the probability (positive and negative) of watermarking for each frame
# A watermarked audio should have result[:, 1, :] > 0.5
print(result[:, 1 , :])
# Message is a tensor of size batch x 16, indicating of the probability of each bit to be 1.
# message will be a random tensor if the detector detects no watermarking from the audio
print(message) See here for details on how to train your own Watermarking model.
We welcome Pull Requests with improvements or suggestions. If you want to flag an issue or propose an improvement, but dont' know how to realize it, create a GitHub Issue.
-
If you encounter the error
ValueError: not enough values to unpack (expected 3, got 2), this is because we expect a batch of audio tensors as inputs. Add one dummy batch dimension to your input (e.g.wav.unsqueeze(0), see example notebook for getting started). -
In Windows machines, if you encounter the error
KeyError raised while resolving interpolation: "Environmen variable 'USER' not found": This is due to an old checkpoint uploaded to the model hub, which is not compatible in Windows. Try to invalidate the cache by removing the files inC:\Users\<USER>\.cache\audiosealand re-run again. -
If you use torchaudio to handle your audios and encounter the error
Couldn't find appropriate backend to handle uri ..., this is due to newer version of torchaudio does not handle the default backend well. Either downgrade your torchaudio to2.1.0or earlier, or installsoundfileas your audio backend.
- The code in this repository is released under the MIT license as found in the LICENSE file.
If you find this repository useful, please consider giving a star ⭐ and please cite as:
@article{sanroman2024proactive,
title={Proactive Detection of Voice Cloning with Localized Watermarking},
author={San Roman, Robin and Fernandez, Pierre and Elsahar, Hady and D´efossez, Alexandre and Furon, Teddy and Tran, Tuan},
journal={ICML},
year={2024}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for audioseal
Similar Open Source Tools
audioseal
AudioSeal is a method for speech localized watermarking, designed with state-of-the-art robustness and detector speed. It jointly trains a generator to embed a watermark in audio and a detector to detect watermarked fragments in longer audios, even in the presence of editing. The tool achieves top-notch detection performance at the sample level, generates minimal alteration of signal quality, and is robust to various audio editing types. With a fast, single-pass detector, AudioSeal surpasses existing models in speed, making it ideal for large-scale and real-time applications.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.
RAVE
RAVE is a variational autoencoder for fast and high-quality neural audio synthesis. It can be used to generate new audio samples from a given dataset, or to modify the style of existing audio samples. RAVE is easy to use and can be trained on a variety of audio datasets. It is also computationally efficient, making it suitable for real-time applications.
neutone_sdk
The Neutone SDK is a tool designed for researchers to wrap their own audio models and run them in a DAW using the Neutone Plugin. It simplifies the process by allowing models to be built using PyTorch and minimal Python code, eliminating the need for extensive C++ knowledge. The SDK provides support for buffering inputs and outputs, sample rate conversion, and profiling tools for model performance testing. It also offers examples, notebooks, and a submission process for sharing models with the community.
vector_companion
Vector Companion is an AI tool designed to act as a virtual companion on your computer. It consists of two personalities, Axiom and Axis, who can engage in conversations based on what is happening on the screen. The tool can transcribe audio output and user microphone input, take screenshots, and read text via OCR to create lifelike interactions. It requires specific prerequisites to run on Windows and uses VB Cable to capture audio. Users can interact with Axiom and Axis by running the main script after installation and configuration.

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.

llama-on-lambda
This project provides a proof of concept for deploying a scalable, serverless LLM Generative AI inference engine on AWS Lambda. It leverages the llama.cpp project to enable the usage of more accessible CPU and RAM configurations instead of limited and expensive GPU capabilities. By deploying a container with the llama.cpp converted models onto AWS Lambda, this project offers the advantages of scale, minimizing cost, and maximizing compute availability. The project includes AWS CDK code to create and deploy a Lambda function leveraging your model of choice, with a FastAPI frontend accessible from a Lambda URL. It is important to note that you will need ggml quantized versions of your model and model sizes under 6GB, as your inference RAM requirements cannot exceed 9GB or your Lambda function will fail.

sdkit
sdkit (stable diffusion kit) is an easy-to-use library for utilizing Stable Diffusion in AI Art projects. It includes features like ControlNets, LoRAs, Textual Inversion Embeddings, GFPGAN, CodeFormer for face restoration, RealESRGAN for upscaling, k-samplers, support for custom VAEs, NSFW filter, model-downloader, parallel GPU support, and more. It offers a model database, auto-scanning for malicious models, and various optimizations. The API consists of modules for loading models, generating images, filters, model merging, and utilities, all managed through the sdkit.Context object.
local-talking-llm
The 'local-talking-llm' repository provides a tutorial on building a voice assistant similar to Jarvis or Friday from Iron Man movies, capable of offline operation on a computer. The tutorial covers setting up a Python environment, installing necessary libraries like rich, openai-whisper, suno-bark, langchain, sounddevice, pyaudio, and speechrecognition. It utilizes Ollama for Large Language Model (LLM) serving and includes components for speech recognition, conversational chain, and speech synthesis. The implementation involves creating a TextToSpeechService class for Bark, defining functions for audio recording, transcription, LLM response generation, and audio playback. The main application loop guides users through interactive voice-based conversations with the assistant.

kafka-ml
Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.

MegatronApp
MegatronApp is a toolchain built around the Megatron-LM training framework, offering performance tuning, slow-node detection, and training-process visualization. It includes modules like MegaScan for anomaly detection, MegaFBD for forward-backward decoupling, MegaDPP for dynamic pipeline planning, and MegaScope for visualization. The tool aims to enhance large-scale distributed training by providing valuable capabilities and insights.

aici
The Artificial Intelligence Controller Interface (AICI) lets you build Controllers that constrain and direct output of a Large Language Model (LLM) in real time. Controllers are flexible programs capable of implementing constrained decoding, dynamic editing of prompts and generated text, and coordinating execution across multiple, parallel generations. Controllers incorporate custom logic during the token-by-token decoding and maintain state during an LLM request. This allows diverse Controller strategies, from programmatic or query-based decoding to multi-agent conversations to execute efficiently in tight integration with the LLM itself.

Mapperatorinator
Mapperatorinator is a multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The project aims to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability. The tool is built upon osuT5 and osu-diffusion, utilizing GPU compute and instances on vast.ai for development. Users can responsibly use AI in their beatmaps with this tool, ensuring disclosure of AI usage. Installation instructions include cloning the repository, creating a virtual environment, and installing dependencies. The tool offers a Web GUI for user-friendly experience and a Command-Line Inference option for advanced configurations. Additionally, an Interactive CLI script is available for terminal-based workflow with guided setup. The tool provides generation tips and features MaiMod, an AI-driven modding tool for osu! beatmaps. Mapperatorinator tokenizes beatmaps, utilizes a model architecture based on HF Transformers Whisper model, and offers multitask training format for conditional generation. The tool ensures seamless long generation, refines coordinates with diffusion, and performs post-processing for improved beatmap quality. Super timing generator enhances timing accuracy, and LoRA fine-tuning allows adaptation to specific styles or gamemodes. The project acknowledges credits and related works in the osu! community.
blurt
Blurt is a Gnome shell extension that enables accurate speech-to-text input in Linux. It is based on the command line utility NoteWhispers and supports Gnome shell version 48. Users can transcribe speech using a local whisper.cpp installation or a whisper.cpp server. The extension allows for easy setup, start/stop of speech-to-text input with key bindings or icon click, and provides visual indicators during operation. It offers convenience by enabling speech input into any window that allows text input, with the transcribed text sent to the clipboard for easy pasting.

magpie
This is the official repository for 'Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing'. Magpie is a tool designed to synthesize high-quality instruction data at scale by extracting it directly from an aligned Large Language Models (LLMs). It aims to democratize AI by generating large-scale alignment data and enhancing the transparency of model alignment processes. Magpie has been tested on various model families and can be used to fine-tune models for improved performance on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.
talking-avatar-with-ai
The 'talking-avatar-with-ai' project is a digital human system that utilizes OpenAI's GPT-3 for generating responses, Whisper for audio transcription, Eleven Labs for voice generation, and Rhubarb Lip Sync for lip synchronization. The system allows users to interact with a digital avatar that responds with text, facial expressions, and animations, creating a realistic conversational experience. The project includes setup for environment variables, chat prompt templates, chat model configuration, and structured output parsing to enhance the interaction with the digital human.
For similar tasks

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio
audioseal
AudioSeal is a method for speech localized watermarking, designed with state-of-the-art robustness and detector speed. It jointly trains a generator to embed a watermark in audio and a detector to detect watermarked fragments in longer audios, even in the presence of editing. The tool achieves top-notch detection performance at the sample level, generates minimal alteration of signal quality, and is robust to various audio editing types. With a fast, single-pass detector, AudioSeal surpasses existing models in speed, making it ideal for large-scale and real-time applications.
SLAM-LLM
SLAM-LLM is a deep learning toolkit designed for researchers and developers to train custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). SLAM-LLM features easy extension to new models and tasks, mixed precision training for faster training with less GPU memory, multi-GPU training with data and model parallelism, and flexible configuration based on Hydra and dataclass.
freegenius
FreeGenius AI is an ambitious project offering a comprehensive suite of AI solutions that mirror the capabilities of LetMeDoIt AI. It is designed to engage in intuitive conversations, execute codes, provide up-to-date information, and perform various tasks. The tool is free, customizable, and provides access to real-time data and device information. It aims to support offline and online backends, open-source large language models, and optional API keys. Users can use FreeGenius AI for tasks like generating tweets, analyzing audio, searching financial data, checking weather, and creating maps.

RVC_CLI
RVC_CLI is a command line interface tool for retrieval-based voice conversion. It provides functionalities for installation, getting started, inference, training, UVR, additional features, and API integration. Users can perform tasks like single inference, batch inference, TTS inference, preprocess dataset, extract features, start training, generate index file, model extract, model information, model blender, launch TensorBoard, download models, audio analyzer, and prerequisites download. The tool is built on various projects like ContentVec, HIFIGAN, audio-slicer, python-audio-separator, RMVPE, FCPE, VITS, So-Vits-SVC, Harmonify, and others.

towhee
Towhee is a cutting-edge framework designed to streamline the processing of unstructured data through the use of Large Language Model (LLM) based pipeline orchestration. It can extract insights from diverse data types like text, images, audio, and video files using generative AI and deep learning models. Towhee offers rich operators, prebuilt ETL pipelines, and a high-performance backend for efficient data processing. With a Pythonic API, users can build custom data processing pipelines easily. Towhee is suitable for tasks like sentence embedding, image embedding, video deduplication, question answering with documents, and cross-modal retrieval based on CLIP.
chatwise-releases
ChatWise is an offline tool that supports various AI models such as OpenAI, Anthropic, Google AI, Groq, and Ollama. It is multi-modal, allowing text-to-speech powered by OpenAI and ElevenLabs. The tool supports text files, PDFs, audio, and images across different models. ChatWise is currently available for macOS (Apple Silicon & Intel) with Windows support coming soon.
AudioMuse-AI
AudioMuse-AI is a deep learning-based tool for audio analysis and music generation. It provides a user-friendly interface for processing audio data and generating music compositions. The tool utilizes state-of-the-art machine learning algorithms to analyze audio signals and extract meaningful features for music generation. With AudioMuse-AI, users can explore the possibilities of AI in music creation and experiment with different styles and genres. Whether you are a music enthusiast, a researcher, or a developer, AudioMuse-AI offers a versatile platform for audio analysis and music generation.
For similar jobs

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.

NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.
RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.