
minbpe
Minimal, clean code for the Byte Pair Encoding (BPE) algorithm commonly used in LLM tokenization.
Stars: 8514

This repository contains a minimal, clean code implementation of the Byte Pair Encoding (BPE) algorithm, commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings. This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers. There are two Tokenizers in this repository, both of which can perform the 3 primary functions of a Tokenizer: 1) train the tokenizer vocabulary and merges on a given text, 2) encode from text to tokens, 3) decode from tokens to text. The files of the repo are as follows: 1. minbpe/base.py: Implements the `Tokenizer` class, which is the base class. It contains the `train`, `encode`, and `decode` stubs, save/load functionality, and there are also a few common utility functions. This class is not meant to be used directly, but rather to be inherited from. 2. minbpe/basic.py: Implements the `BasicTokenizer`, the simplest implementation of the BPE algorithm that runs directly on text. 3. minbpe/regex.py: Implements the `RegexTokenizer` that further splits the input text by a regex pattern, which is a preprocessing stage that splits up the input text by categories (think: letters, numbers, punctuation) before tokenization. This ensures that no merges will happen across category boundaries. This was introduced in the GPT-2 paper and continues to be in use as of GPT-4. This class also handles special tokens, if any. 4. minbpe/gpt4.py: Implements the `GPT4Tokenizer`. This class is a light wrapper around the `RegexTokenizer` (2, above) that exactly reproduces the tokenization of GPT-4 in the tiktoken library. The wrapping handles some details around recovering the exact merges in the tokenizer, and the handling of some unfortunate (and likely historical?) 1-byte token permutations. Finally, the script train.py trains the two major tokenizers on the input text tests/taylorswift.txt (this is the Wikipedia entry for her kek) and saves the vocab to disk for visualization. This script runs in about 25 seconds on my (M1) MacBook. All of the files above are very short and thoroughly commented, and also contain a usage example on the bottom of the file.
README:
Minimal, clean code for the (byte-level) Byte Pair Encoding (BPE) algorithm commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings.
This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers.
There are two Tokenizers in this repository, both of which can perform the 3 primary functions of a Tokenizer: 1) train the tokenizer vocabulary and merges on a given text, 2) encode from text to tokens, 3) decode from tokens to text. The files of the repo are as follows:
-
minbpe/base.py: Implements the
Tokenizerclass, which is the base class. It contains thetrain,encode, anddecodestubs, save/load functionality, and there are also a few common utility functions. This class is not meant to be used directly, but rather to be inherited from. -
minbpe/basic.py: Implements the
BasicTokenizer, the simplest implementation of the BPE algorithm that runs directly on text. -
minbpe/regex.py: Implements the
RegexTokenizerthat further splits the input text by a regex pattern, which is a preprocessing stage that splits up the input text by categories (think: letters, numbers, punctuation) before tokenization. This ensures that no merges will happen across category boundaries. This was introduced in the GPT-2 paper and continues to be in use as of GPT-4. This class also handles special tokens, if any. -
minbpe/gpt4.py: Implements the
GPT4Tokenizer. This class is a light wrapper around theRegexTokenizer(2, above) that exactly reproduces the tokenization of GPT-4 in the tiktoken library. The wrapping handles some details around recovering the exact merges in the tokenizer, and the handling of some unfortunate (and likely historical?) 1-byte token permutations.
Finally, the script train.py trains the two major tokenizers on the input text tests/taylorswift.txt (this is the Wikipedia entry for her kek) and saves the vocab to disk for visualization. This script runs in about 25 seconds on my (M1) MacBook.
All of the files above are very short and thoroughly commented, and also contain a usage example on the bottom of the file.
As the simplest example, we can reproduce the Wikipedia article on BPE as follows:
from minbpe import BasicTokenizer
tokenizer = BasicTokenizer()
text = "aaabdaaabac"
tokenizer.train(text, 256 + 3) # 256 are the byte tokens, then do 3 merges
print(tokenizer.encode(text))
# [258, 100, 258, 97, 99]
print(tokenizer.decode([258, 100, 258, 97, 99]))
# aaabdaaabac
tokenizer.save("toy")
# writes two files: toy.model (for loading) and toy.vocab (for viewing)According to Wikipedia, running bpe on the input string: "aaabdaaabac" for 3 merges results in the string: "XdXac" where X=ZY, Y=ab, and Z=aa. The tricky thing to note is that minbpe always allocates the 256 individual bytes as tokens, and then merges bytes as needed from there. So for us a=97, b=98, c=99, d=100 (their ASCII values). Then when (a,a) is merged to Z, Z will become 256. Likewise Y will become 257 and X 258. So we start with the 256 bytes, and do 3 merges to get to the result above, with the expected output of [258, 100, 258, 97, 99].
We can verify that the RegexTokenizer has feature parity with the GPT-4 tokenizer from tiktoken as follows:
text = "hello123!!!? (안녕하세요!) 😉"
# tiktoken
import tiktoken
enc = tiktoken.get_encoding("cl100k_base")
print(enc.encode(text))
# [15339, 4513, 12340, 30, 320, 31495, 230, 75265, 243, 92245, 16715, 57037]
# ours
from minbpe import GPT4Tokenizer
tokenizer = GPT4Tokenizer()
print(tokenizer.encode(text))
# [15339, 4513, 12340, 30, 320, 31495, 230, 75265, 243, 92245, 16715, 57037](you'll have to pip install tiktoken to run). Under the hood, the GPT4Tokenizer is just a light wrapper around RegexTokenizer, passing in the merges and the special tokens of GPT-4. We can also ensure the special tokens are handled correctly:
text = "<|endoftext|>hello world"
# tiktoken
import tiktoken
enc = tiktoken.get_encoding("cl100k_base")
print(enc.encode(text, allowed_special="all"))
# [100257, 15339, 1917]
# ours
from minbpe import GPT4Tokenizer
tokenizer = GPT4Tokenizer()
print(tokenizer.encode(text, allowed_special="all"))
# [100257, 15339, 1917]Note that just like tiktoken, we have to explicitly declare our intent to use and parse special tokens in the call to encode. Otherwise this can become a major footgun, unintentionally tokenizing attacker-controlled data (e.g. user prompts) with special tokens. The allowed_special parameter can be set to "all", "none", or a list of special tokens to allow.
Unlike tiktoken, this code allows you to train your own tokenizer. In principle and to my knowledge, if you train the RegexTokenizer on a large dataset with a vocabulary size of 100K, you would reproduce the GPT-4 tokenizer.
There are two paths you can follow. First, you can decide that you don't want the complexity of splitting and preprocessing text with regex patterns, and you also don't care for special tokens. In that case, reach for the BasicTokenizer. You can train it, and then encode and decode for example as follows:
from minbpe import BasicTokenizer
tokenizer = BasicTokenizer()
tokenizer.train(very_long_training_string, vocab_size=4096)
tokenizer.encode("hello world") # string -> tokens
tokenizer.decode([1000, 2000, 3000]) # tokens -> string
tokenizer.save("mymodel") # writes mymodel.model and mymodel.vocab
tokenizer.load("mymodel.model") # loads the model back, the vocab is just for visIf you instead want to follow along with OpenAI did for their text tokenizer, it's a good idea to adopt their approach of using regex pattern to split the text by categories. The GPT-4 pattern is a default with the RegexTokenizer, so you'd simple do something like:
from minbpe import RegexTokenizer
tokenizer = RegexTokenizer()
tokenizer.train(very_long_training_string, vocab_size=32768)
tokenizer.encode("hello world") # string -> tokens
tokenizer.decode([1000, 2000, 3000]) # tokens -> string
tokenizer.save("tok32k") # writes tok32k.model and tok32k.vocab
tokenizer.load("tok32k.model") # loads the model back from diskWhere, of course, you'd want to change around the vocabulary size depending on the size of your dataset.
Special tokens. Finally, you might wish to add special tokens to your tokenizer. Register these using the register_special_tokens function. For example if you train with vocab_size of 32768, then the first 256 tokens are raw byte tokens, the next 32768-256 are merge tokens, and after those you can add the special tokens. The last "real" merge token will have id of 32767 (vocab_size - 1), so your first special token should come right after that, with an id of exactly 32768. So:
from minbpe import RegexTokenizer
tokenizer = RegexTokenizer()
tokenizer.train(very_long_training_string, vocab_size=32768)
tokenizer.register_special_tokens({"<|endoftext|>": 32768})
tokenizer.encode("<|endoftext|>hello world", allowed_special="all")You can of course add more tokens after that as well, as you like. Finally, I'd like to stress that I tried hard to keep the code itself clean, readable and hackable. You should not have feel scared to read the code and understand how it works. The tests are also a nice place to look for more usage examples. That reminds me:
We use the pytest library for tests. All of them are located in the tests/ directory. First pip install pytest if you haven't already, then:
$ pytest -v .to run the tests. (-v is verbose, slightly prettier).
-
gnp/minbpe-rs: A Rust implementation of
minbpeproviding (near) one-to-one correspondence with the Python version
For those trying to study BPE, here is the advised progression exercise for how you can build your own minbpe step by step. See exercise.md.
I built the code in this repository in this YouTube video. You can also find this lecture in text form in lecture.md.
- write a more optimized Python version that could run over large files and big vocabs
- write an even more optimized C or Rust version (think through)
- rename GPT4Tokenizer to GPTTokenizer and support GPT-2/GPT-3/GPT-3.5 as well?
- write a LlamaTokenizer similar to GPT4Tokenizer (i.e. attempt sentencepiece equivalent)
MIT
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for minbpe
Similar Open Source Tools
minbpe
This repository contains a minimal, clean code implementation of the Byte Pair Encoding (BPE) algorithm, commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings. This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers. There are two Tokenizers in this repository, both of which can perform the 3 primary functions of a Tokenizer: 1) train the tokenizer vocabulary and merges on a given text, 2) encode from text to tokens, 3) decode from tokens to text. The files of the repo are as follows: 1. minbpe/base.py: Implements the `Tokenizer` class, which is the base class. It contains the `train`, `encode`, and `decode` stubs, save/load functionality, and there are also a few common utility functions. This class is not meant to be used directly, but rather to be inherited from. 2. minbpe/basic.py: Implements the `BasicTokenizer`, the simplest implementation of the BPE algorithm that runs directly on text. 3. minbpe/regex.py: Implements the `RegexTokenizer` that further splits the input text by a regex pattern, which is a preprocessing stage that splits up the input text by categories (think: letters, numbers, punctuation) before tokenization. This ensures that no merges will happen across category boundaries. This was introduced in the GPT-2 paper and continues to be in use as of GPT-4. This class also handles special tokens, if any. 4. minbpe/gpt4.py: Implements the `GPT4Tokenizer`. This class is a light wrapper around the `RegexTokenizer` (2, above) that exactly reproduces the tokenization of GPT-4 in the tiktoken library. The wrapping handles some details around recovering the exact merges in the tokenizer, and the handling of some unfortunate (and likely historical?) 1-byte token permutations. Finally, the script train.py trains the two major tokenizers on the input text tests/taylorswift.txt (this is the Wikipedia entry for her kek) and saves the vocab to disk for visualization. This script runs in about 25 seconds on my (M1) MacBook. All of the files above are very short and thoroughly commented, and also contain a usage example on the bottom of the file.
llama3-tokenizer-js
JavaScript tokenizer for LLaMA 3 designed for client-side use in the browser and Node, with TypeScript support. It accurately calculates token count, has 0 dependencies, optimized running time, and somewhat optimized bundle size. Compatible with most LLaMA 3 models. Can encode and decode text, but training is not supported. Pollutes global namespace with `llama3Tokenizer` in the browser. Mostly compatible with LLaMA 3 models released by Facebook in April 2024. Can be adapted for incompatible models by passing custom vocab and merge data. Handles special tokens and fine tunes. Developed by belladore.ai with contributions from xenova, blaze2004, imoneoi, and ConProgramming.
abliterator
abliterator.py is a simple Python library/structure designed to ablate features in large language models (LLMs) supported by TransformerLens. It provides capabilities to enter temporary contexts, cache activations with N samples, calculate refusal directions, and includes tokenizer utilities. The library aims to streamline the process of experimenting with ablation direction turns by encapsulating useful logic and minimizing code complexity. While currently basic and lacking comprehensive documentation, the library serves well for personal workflows and aims to expand beyond feature ablation to augmentation and additional features over time with community support.

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and follows a process of embedding docs and queries, searching for top passages, creating summaries, scoring and selecting relevant summaries, putting summaries into prompt, and generating answers. Users can customize prompts and use various models for embeddings and LLMs. The tool can be used asynchronously and supports adding documents from paths, files, or URLs.

MultiPL-E
MultiPL-E is a system for translating unit test-driven neural code generation benchmarks to new languages. It is part of the BigCode Code Generation LM Harness and allows for evaluating Code LLMs using various benchmarks. The tool supports multiple versions with improvements and new language additions, providing a scalable and polyglot approach to benchmarking neural code generation. Users can access a tutorial for direct usage and explore the dataset of translated prompts on the Hugging Face Hub.

llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!
x-lstm
This repository contains an unofficial implementation of the xLSTM model introduced in Beck et al. (2024). It serves as a didactic tool to explain the details of a modern Long-Short Term Memory model with competitive performance against Transformers or State-Space models. The repository also includes a Lightning-based implementation of a basic LLM for multi-GPU training. It provides modules for scalar-LSTM and matrix-LSTM, as well as an xLSTM LLM built using Pytorch Lightning for easy training on multi-GPUs.

llama-on-lambda
This project provides a proof of concept for deploying a scalable, serverless LLM Generative AI inference engine on AWS Lambda. It leverages the llama.cpp project to enable the usage of more accessible CPU and RAM configurations instead of limited and expensive GPU capabilities. By deploying a container with the llama.cpp converted models onto AWS Lambda, this project offers the advantages of scale, minimizing cost, and maximizing compute availability. The project includes AWS CDK code to create and deploy a Lambda function leveraging your model of choice, with a FastAPI frontend accessible from a Lambda URL. It is important to note that you will need ggml quantized versions of your model and model sizes under 6GB, as your inference RAM requirements cannot exceed 9GB or your Lambda function will fail.
cameratrapai
SpeciesNet is an ensemble of AI models designed for classifying wildlife in camera trap images. It consists of an object detector that finds objects of interest in wildlife camera images and an image classifier that classifies those objects to the species level. The ensemble combines these two models using heuristics and geographic information to assign each image to a single category. The models have been trained on a large dataset of camera trap images and are used for species recognition in the Wildlife Insights platform.
forust
Forust is a lightweight package for building gradient boosted decision tree ensembles. The algorithm code is written in Rust with a Python wrapper. It implements the same algorithm as XGBoost and provides nearly identical results. The package was developed to better understand XGBoost, as a fun project in Rust, and to experiment with adding new features to the algorithm in a simpler codebase. Forust allows training gradient boosted decision tree ensembles with multiple objective functions, predicting on datasets, inspecting model structures, calculating feature importance, and saving/loading trained boosters.
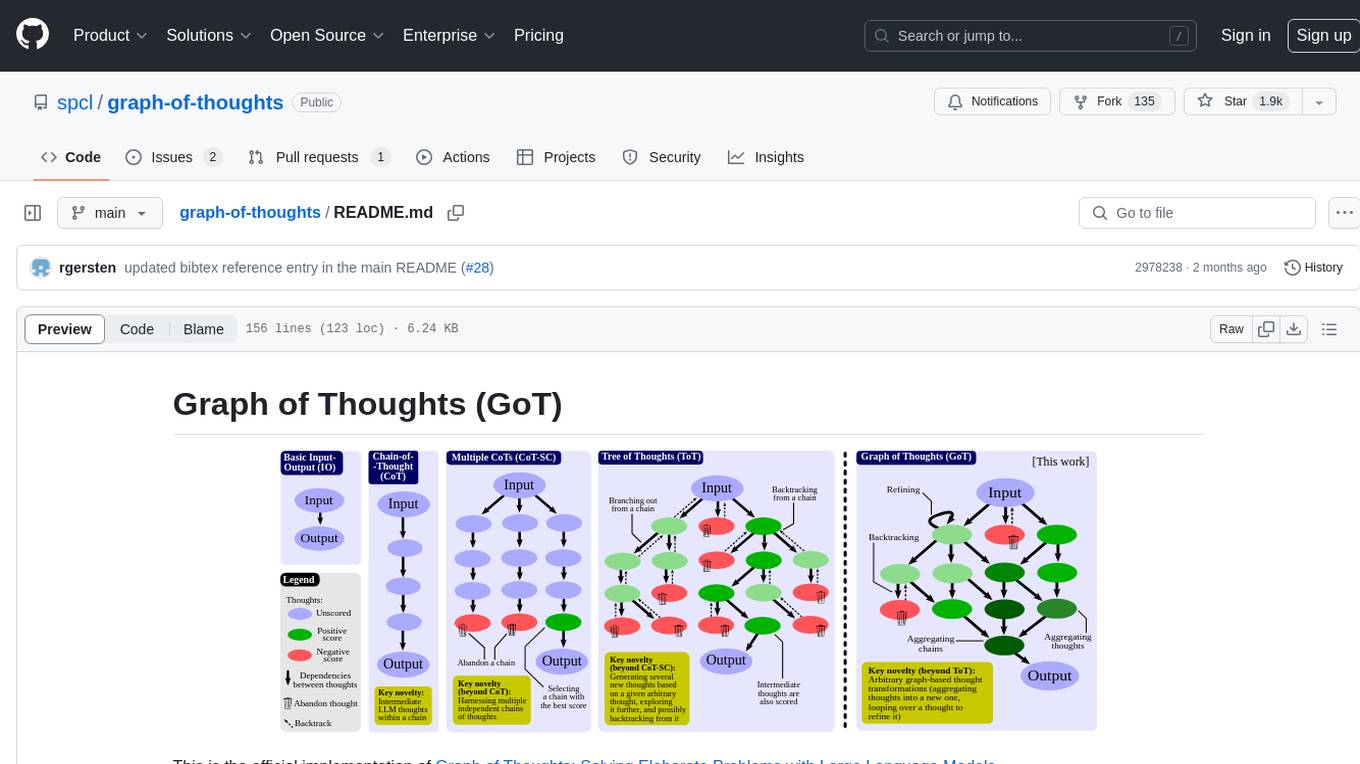
graph-of-thoughts
Graph of Thoughts (GoT) is an official implementation framework designed to solve complex problems by modeling them as a Graph of Operations (GoO) executed with a Large Language Model (LLM) engine. It offers flexibility to implement various approaches like CoT or ToT, allowing users to solve problems using the new GoT approach. The framework includes setup guides, quick start examples, documentation, and examples for users to understand and utilize the tool effectively.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and includes a process of embedding docs, queries, searching for top passages, creating summaries, using an LLM to re-score and select relevant summaries, putting summaries into prompt, and generating answers. The tool can be used to answer specific questions related to scientific research by leveraging citations and relevant passages from documents.

llamabot
LlamaBot is a Pythonic bot interface to Large Language Models (LLMs), providing an easy way to experiment with LLMs in Jupyter notebooks and build Python apps utilizing LLMs. It supports all models available in LiteLLM. Users can access LLMs either through local models with Ollama or by using API providers like OpenAI and Mistral. LlamaBot offers different bot interfaces like SimpleBot, ChatBot, QueryBot, and ImageBot for various tasks such as rephrasing text, maintaining chat history, querying documents, and generating images. The tool also includes CLI demos showcasing its capabilities and supports contributions for new features and bug reports from the community.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.

LongRAG
This repository contains the code for LongRAG, a framework that enhances retrieval-augmented generation with long-context LLMs. LongRAG introduces a 'long retriever' and a 'long reader' to improve performance by using a 4K-token retrieval unit, offering insights into combining RAG with long-context LLMs. The repo provides instructions for installation, quick start, corpus preparation, long retriever, and long reader.
For similar tasks
minbpe
This repository contains a minimal, clean code implementation of the Byte Pair Encoding (BPE) algorithm, commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings. This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers. There are two Tokenizers in this repository, both of which can perform the 3 primary functions of a Tokenizer: 1) train the tokenizer vocabulary and merges on a given text, 2) encode from text to tokens, 3) decode from tokens to text. The files of the repo are as follows: 1. minbpe/base.py: Implements the `Tokenizer` class, which is the base class. It contains the `train`, `encode`, and `decode` stubs, save/load functionality, and there are also a few common utility functions. This class is not meant to be used directly, but rather to be inherited from. 2. minbpe/basic.py: Implements the `BasicTokenizer`, the simplest implementation of the BPE algorithm that runs directly on text. 3. minbpe/regex.py: Implements the `RegexTokenizer` that further splits the input text by a regex pattern, which is a preprocessing stage that splits up the input text by categories (think: letters, numbers, punctuation) before tokenization. This ensures that no merges will happen across category boundaries. This was introduced in the GPT-2 paper and continues to be in use as of GPT-4. This class also handles special tokens, if any. 4. minbpe/gpt4.py: Implements the `GPT4Tokenizer`. This class is a light wrapper around the `RegexTokenizer` (2, above) that exactly reproduces the tokenization of GPT-4 in the tiktoken library. The wrapping handles some details around recovering the exact merges in the tokenizer, and the handling of some unfortunate (and likely historical?) 1-byte token permutations. Finally, the script train.py trains the two major tokenizers on the input text tests/taylorswift.txt (this is the Wikipedia entry for her kek) and saves the vocab to disk for visualization. This script runs in about 25 seconds on my (M1) MacBook. All of the files above are very short and thoroughly commented, and also contain a usage example on the bottom of the file.

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.
llama3-tokenizer-js
JavaScript tokenizer for LLaMA 3 designed for client-side use in the browser and Node, with TypeScript support. It accurately calculates token count, has 0 dependencies, optimized running time, and somewhat optimized bundle size. Compatible with most LLaMA 3 models. Can encode and decode text, but training is not supported. Pollutes global namespace with `llama3Tokenizer` in the browser. Mostly compatible with LLaMA 3 models released by Facebook in April 2024. Can be adapted for incompatible models by passing custom vocab and merge data. Handles special tokens and fine tunes. Developed by belladore.ai with contributions from xenova, blaze2004, imoneoi, and ConProgramming.

Tiktoken
Tiktoken is a high-performance implementation focused on token count operations. It provides various encodings like o200k_base, cl100k_base, r50k_base, p50k_base, and p50k_edit. Users can easily encode and decode text using the provided API. The repository also includes a benchmark console app for performance tracking. Contributions in the form of PRs are welcome.
CTFCrackTools
CTFCrackTools X is the next generation of CTFCrackTools, featuring extreme performance and experience, extensible node-based architecture, and future-oriented technology stack. It offers a visual node-based workflow for encoding and decoding processes, with 43+ built-in algorithms covering common CTF needs like encoding, classical ciphers, modern encryption, hashing, and text processing. The tool is lightweight (< 15MB), high-performance, and cross-platform, supporting Windows, macOS, and Linux without the need for a runtime environment. It aims to provide a beginner-friendly tool for CTF enthusiasts to easily work on challenges and improve their skills.
SmallLanguageModel-project
This repository provides all the necessary items to build a Language Model from scratch, inspired by Karpathy's nanoGPT and Shakespeare generator. It includes data collection tools, data processing scripts, various models like BERT, GPT, and Seq-2-Seq, along with tokenizer and training files.

tiny-llm-zh
Tiny LLM zh is a project aimed at building a small-parameter Chinese language large model for quick entry into learning large model-related knowledge. The project implements a two-stage training process for large models and subsequent human alignment, including tokenization, pre-training, instruction fine-tuning, human alignment, evaluation, and deployment. It is deployed on ModeScope Tiny LLM website and features open access to all data and code, including pre-training data and tokenizer. The project trains a tokenizer using 10GB of Chinese encyclopedia text to build a Tiny LLM vocabulary. It supports training with Transformers deepspeed, multiple machine and card support, and Zero optimization techniques. The project has three main branches: llama2_torch, main tiny_llm, and tiny_llm_moe, each with specific modifications and features.
For similar jobs
minbpe
This repository contains a minimal, clean code implementation of the Byte Pair Encoding (BPE) algorithm, commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings. This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers. There are two Tokenizers in this repository, both of which can perform the 3 primary functions of a Tokenizer: 1) train the tokenizer vocabulary and merges on a given text, 2) encode from text to tokens, 3) decode from tokens to text. The files of the repo are as follows: 1. minbpe/base.py: Implements the `Tokenizer` class, which is the base class. It contains the `train`, `encode`, and `decode` stubs, save/load functionality, and there are also a few common utility functions. This class is not meant to be used directly, but rather to be inherited from. 2. minbpe/basic.py: Implements the `BasicTokenizer`, the simplest implementation of the BPE algorithm that runs directly on text. 3. minbpe/regex.py: Implements the `RegexTokenizer` that further splits the input text by a regex pattern, which is a preprocessing stage that splits up the input text by categories (think: letters, numbers, punctuation) before tokenization. This ensures that no merges will happen across category boundaries. This was introduced in the GPT-2 paper and continues to be in use as of GPT-4. This class also handles special tokens, if any. 4. minbpe/gpt4.py: Implements the `GPT4Tokenizer`. This class is a light wrapper around the `RegexTokenizer` (2, above) that exactly reproduces the tokenization of GPT-4 in the tiktoken library. The wrapping handles some details around recovering the exact merges in the tokenizer, and the handling of some unfortunate (and likely historical?) 1-byte token permutations. Finally, the script train.py trains the two major tokenizers on the input text tests/taylorswift.txt (this is the Wikipedia entry for her kek) and saves the vocab to disk for visualization. This script runs in about 25 seconds on my (M1) MacBook. All of the files above are very short and thoroughly commented, and also contain a usage example on the bottom of the file.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

dolma
Dolma is a dataset and toolkit for curating large datasets for (pre)-training ML models. The dataset consists of 3 trillion tokens from a diverse mix of web content, academic publications, code, books, and encyclopedic materials. The toolkit provides high-performance, portable, and extensible tools for processing, tagging, and deduplicating documents. Key features of the toolkit include built-in taggers, fast deduplication, and cloud support.
unitxt
Unitxt is a customizable library for textual data preparation and evaluation tailored to generative language models. It natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively.

syncode
SynCode is a novel framework for the grammar-guided generation of Large Language Models (LLMs) that ensures syntactically valid output with respect to defined Context-Free Grammar (CFG) rules. It supports general-purpose programming languages like Python, Go, SQL, JSON, and more, allowing users to define custom grammars using EBNF syntax. The tool compares favorably to other constrained decoders and offers features like fast grammar-guided generation, compatibility with HuggingFace Language Models, and the ability to work with various decoding strategies.

Awesome-LLM-Large-Language-Models-Notes
Awesome-LLM-Large-Language-Models-Notes is a repository that provides a comprehensive collection of information on various Large Language Models (LLMs) classified by year, size, and name. It includes details on known LLM models, their papers, implementations, and specific characteristics. The repository also covers LLM models classified by architecture, must-read papers, blog articles, tutorials, and implementations from scratch. It serves as a valuable resource for individuals interested in understanding and working with LLMs in the field of Natural Language Processing (NLP).
multimodal_cognitive_ai
The multimodal cognitive AI repository focuses on research work related to multimodal cognitive artificial intelligence. It explores the integration of multiple modes of data such as text, images, and audio to enhance AI systems' cognitive capabilities. The repository likely contains code, datasets, and research papers related to multimodal AI applications, including natural language processing, computer vision, and audio processing. Researchers and developers interested in advancing AI systems' understanding of multimodal data can find valuable resources and insights in this repository.

Awesome-LLM-Constrained-Decoding
Awesome-LLM-Constrained-Decoding is a curated list of papers, code, and resources related to constrained decoding of Large Language Models (LLMs). The repository aims to facilitate reliable, controllable, and efficient generation with LLMs by providing a comprehensive collection of materials in this domain.