Best AI tools for< Encode Text >
6 - AI tool Sites
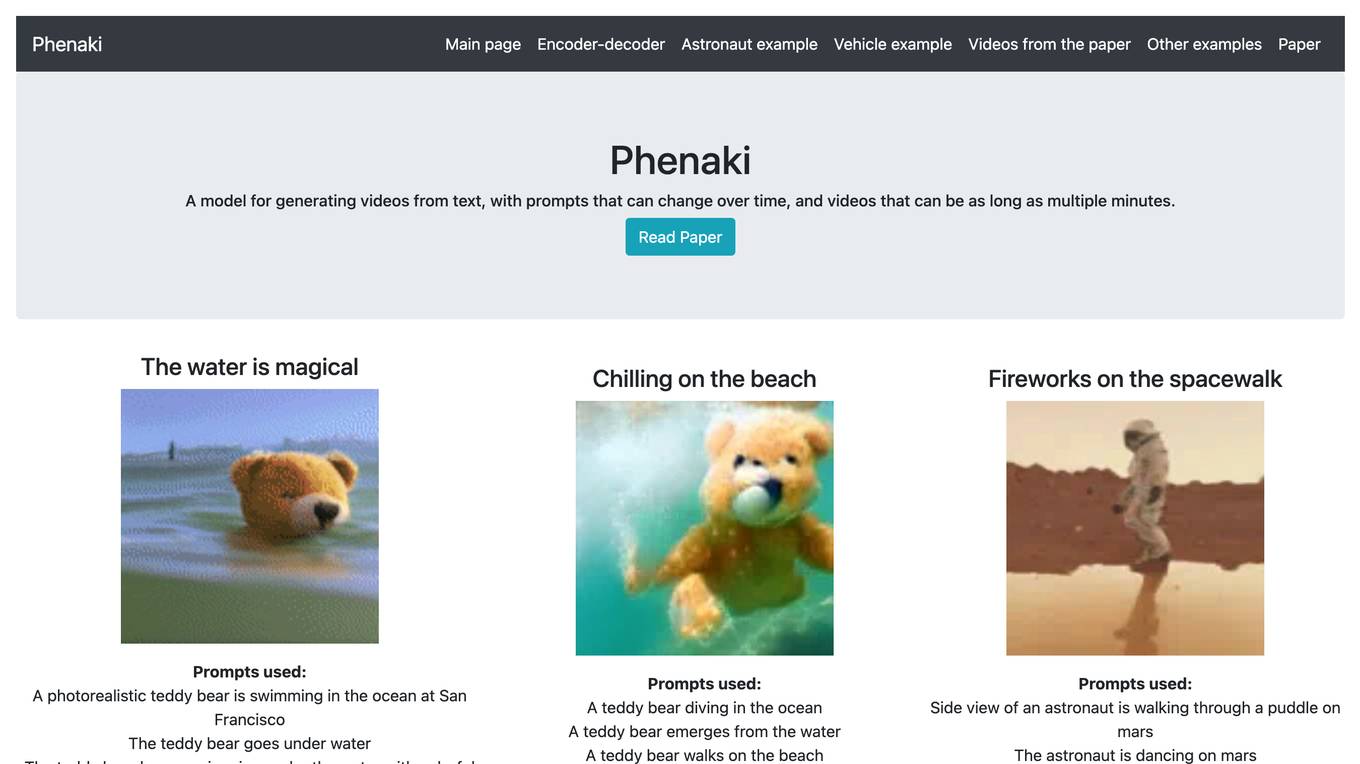
Phenaki
Phenaki is a model capable of generating realistic videos from a sequence of textual prompts. It is particularly challenging to generate videos from text due to the computational cost, limited quantities of high-quality text-video data, and variable length of videos. To address these issues, Phenaki introduces a new causal model for learning video representation, which compresses the video to a small representation of discrete tokens. This tokenizer uses causal attention in time, which allows it to work with variable-length videos. To generate video tokens from text, Phenaki uses a bidirectional masked transformer conditioned on pre-computed text tokens. The generated video tokens are subsequently de-tokenized to create the actual video. To address data issues, Phenaki demonstrates how joint training on a large corpus of image-text pairs as well as a smaller number of video-text examples can result in generalization beyond what is available in the video datasets. Compared to previous video generation methods, Phenaki can generate arbitrarily long videos conditioned on a sequence of prompts (i.e., time-variable text or a story) in an open domain. To the best of our knowledge, this is the first time a paper studies generating videos from time-variable prompts. In addition, the proposed video encoder-decoder outperforms all per-frame baselines currently used in the literature in terms of spatio-temporal quality and the number of tokens per video.
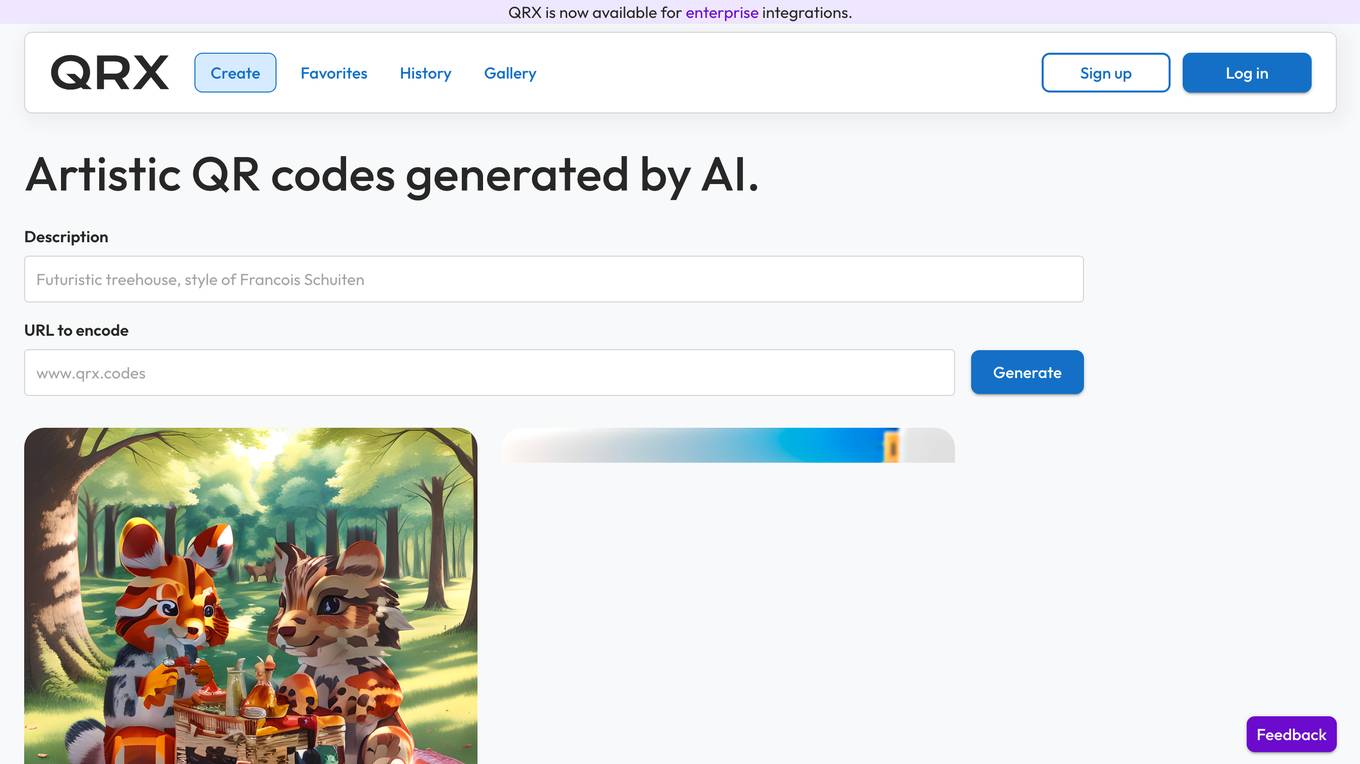
QRX Codes
QRX Codes is an AI tool that generates artistic QR codes. Users can create unique QR codes with images of woodland animals, floating castles, desert scenes, and more. The tool allows for customization of QR codes with premium designs like a dark blue Porsche, Iron Man inspired art, and underground cave themes. QRX is now available for enterprise integrations, offering a creative way to encode URLs and enhance user engagement. The tool is designed to provide a visually appealing and innovative approach to QR code generation.
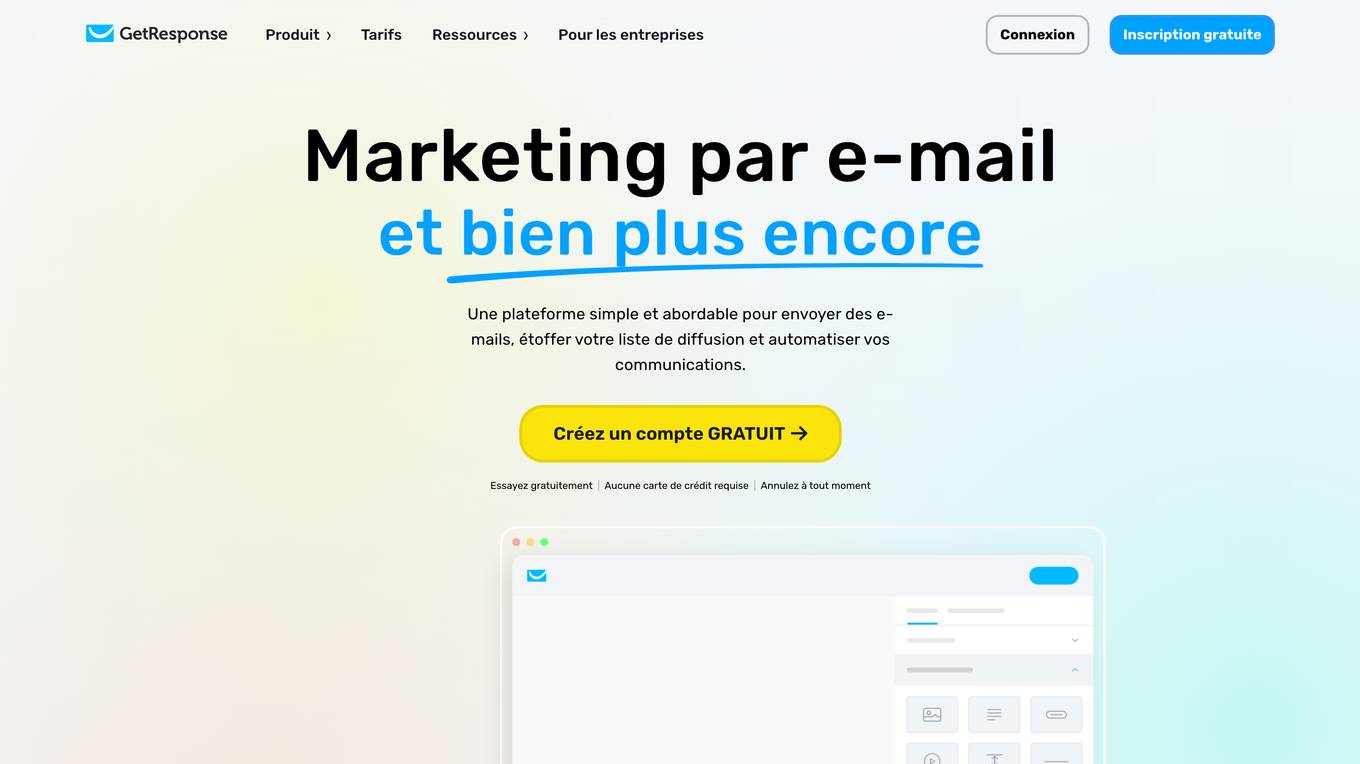
GetResponse
GetResponse is an email marketing and marketing automation platform that helps businesses of all sizes grow their audience, engage with customers, and drive sales. With a suite of powerful tools, including email marketing, landing pages, forms, and automation, GetResponse makes it easy to create and execute effective marketing campaigns. GetResponse also offers a range of integrations with other business tools, making it easy to connect your marketing efforts with your CRM, e-commerce platform, and more.
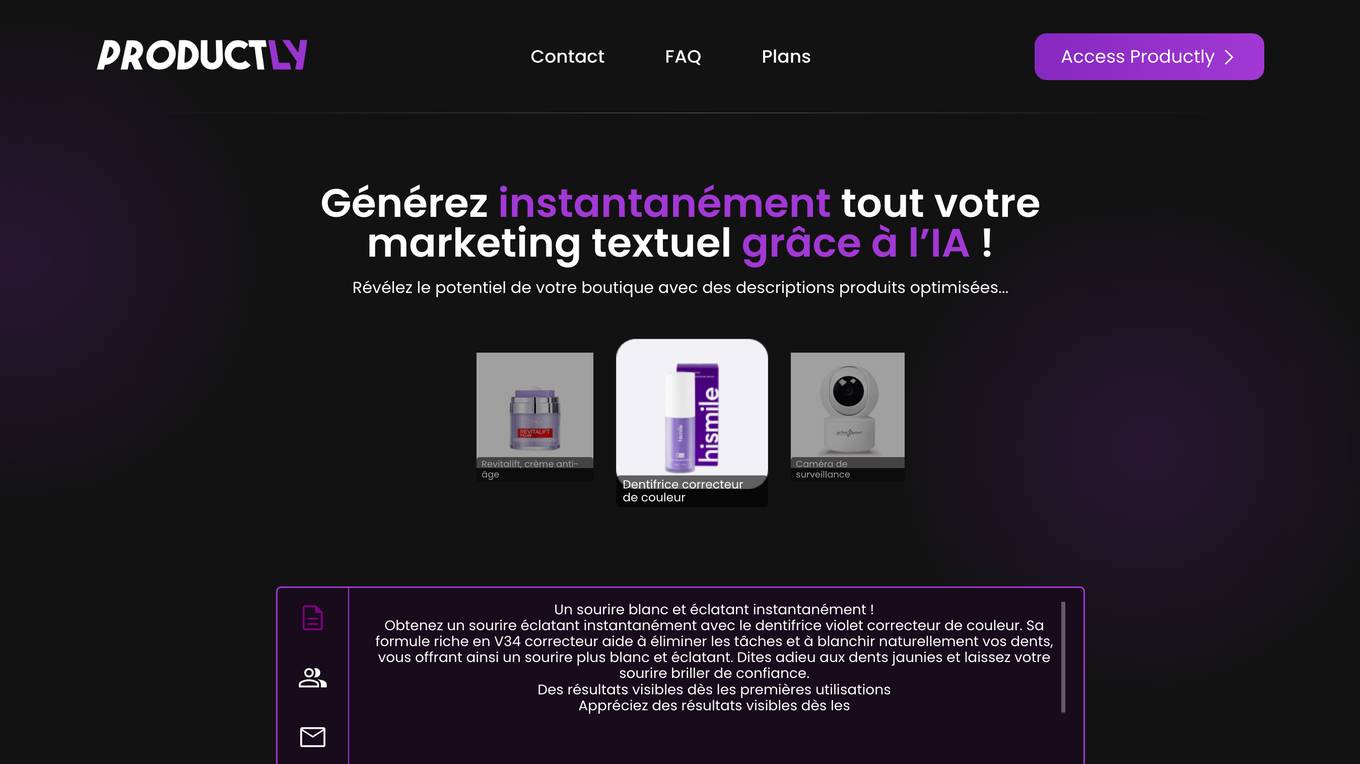
Productly
Productly is an AI-powered sales tool that helps businesses boost their sales performance. It uses machine learning to analyze customer data and identify opportunities for growth. Productly provides personalized recommendations for each customer, helping sales teams close more deals and increase revenue.
notionsmith.ai
The website notionsmith.ai appears to be experiencing a privacy error related to its security certificate. The error message indicates that the connection is not private and warns of potential information theft. The site's security certificate is issued by Microsoft Azure RSA TLS Issuing CA 08, with the subject *.azurewebsites.net. The error message suggests that the site's security certificate common name is invalid, potentially due to a misconfiguration or an attacker intercepting the connection. Users are advised to proceed to the site at their own risk, as it is flagged as unsafe.

MiniGPT-4
MiniGPT-4 is a powerful AI tool that combines a vision encoder with a large language model (LLM) to enhance vision-language understanding. It can generate detailed image descriptions, create websites from handwritten drafts, write stories and poems inspired by images, provide solutions to problems shown in images, and teach users how to cook based on food photos. MiniGPT-4 is highly computationally efficient and easy to use, making it a valuable tool for a wide range of applications.
5 - Open Source AI Tools

minbpe
This repository contains a minimal, clean code implementation of the Byte Pair Encoding (BPE) algorithm, commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings. This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers. There are two Tokenizers in this repository, both of which can perform the 3 primary functions of a Tokenizer: 1) train the tokenizer vocabulary and merges on a given text, 2) encode from text to tokens, 3) decode from tokens to text. The files of the repo are as follows: 1. minbpe/base.py: Implements the `Tokenizer` class, which is the base class. It contains the `train`, `encode`, and `decode` stubs, save/load functionality, and there are also a few common utility functions. This class is not meant to be used directly, but rather to be inherited from. 2. minbpe/basic.py: Implements the `BasicTokenizer`, the simplest implementation of the BPE algorithm that runs directly on text. 3. minbpe/regex.py: Implements the `RegexTokenizer` that further splits the input text by a regex pattern, which is a preprocessing stage that splits up the input text by categories (think: letters, numbers, punctuation) before tokenization. This ensures that no merges will happen across category boundaries. This was introduced in the GPT-2 paper and continues to be in use as of GPT-4. This class also handles special tokens, if any. 4. minbpe/gpt4.py: Implements the `GPT4Tokenizer`. This class is a light wrapper around the `RegexTokenizer` (2, above) that exactly reproduces the tokenization of GPT-4 in the tiktoken library. The wrapping handles some details around recovering the exact merges in the tokenizer, and the handling of some unfortunate (and likely historical?) 1-byte token permutations. Finally, the script train.py trains the two major tokenizers on the input text tests/taylorswift.txt (this is the Wikipedia entry for her kek) and saves the vocab to disk for visualization. This script runs in about 25 seconds on my (M1) MacBook. All of the files above are very short and thoroughly commented, and also contain a usage example on the bottom of the file.

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.
llama3-tokenizer-js
JavaScript tokenizer for LLaMA 3 designed for client-side use in the browser and Node, with TypeScript support. It accurately calculates token count, has 0 dependencies, optimized running time, and somewhat optimized bundle size. Compatible with most LLaMA 3 models. Can encode and decode text, but training is not supported. Pollutes global namespace with `llama3Tokenizer` in the browser. Mostly compatible with LLaMA 3 models released by Facebook in April 2024. Can be adapted for incompatible models by passing custom vocab and merge data. Handles special tokens and fine tunes. Developed by belladore.ai with contributions from xenova, blaze2004, imoneoi, and ConProgramming.

Tiktoken
Tiktoken is a high-performance implementation focused on token count operations. It provides various encodings like o200k_base, cl100k_base, r50k_base, p50k_base, and p50k_edit. Users can easily encode and decode text using the provided API. The repository also includes a benchmark console app for performance tracking. Contributions in the form of PRs are welcome.
CTFCrackTools
CTFCrackTools X is the next generation of CTFCrackTools, featuring extreme performance and experience, extensible node-based architecture, and future-oriented technology stack. It offers a visual node-based workflow for encoding and decoding processes, with 43+ built-in algorithms covering common CTF needs like encoding, classical ciphers, modern encryption, hashing, and text processing. The tool is lightweight (< 15MB), high-performance, and cross-platform, supporting Windows, macOS, and Linux without the need for a runtime environment. It aims to provide a beginner-friendly tool for CTF enthusiasts to easily work on challenges and improve their skills.
7 - OpenAI Gpts