
ragoon
High level library for batched embeddings generation, blazingly-fast web-based RAG and quantized indexes processing ⚡
Stars: 58
RAGoon is a high-level library designed for batched embeddings generation, fast web-based RAG (Retrieval-Augmented Generation) processing, and quantized indexes processing. It provides NLP utilities for multi-model embedding production, high-dimensional vector visualization, and enhancing language model performance through search-based querying, web scraping, and data augmentation techniques.
README:

RAGoon : High level library for batched embeddings generation, blazingly-fast web-based RAG and quantized indexes processing ⚡

RAGoon is a set of NLP utilities for multi-model embedding production, high-dimensional vector visualization, and aims to improve language model performance by providing contextually relevant information through search-based querying, web scraping and data augmentation techniques.
The reference page for RAGoon is available on the official page of PyPI: RAGoon.
pip install ragoonThis section provides an overview of different code blocks that can be executed with RAGoon to enhance your NLP and language model projects.
This class handles loading a dataset from Hugging Face, processing it to add embeddings using specified models, and provides methods to save and upload the processed dataset.
from ragoon import EmbeddingsDataLoader
from datasets import load_dataset
# Initialize the dataset loader with multiple models
loader = EmbeddingsDataLoader(
token="hf_token",
dataset=load_dataset("louisbrulenaudet/dac6-instruct", split="train"), # If dataset is already loaded.
# dataset_name="louisbrulenaudet/dac6-instruct", # If you want to load the dataset from the class.
model_configs=[
{"model": "bert-base-uncased", "query_prefix": "Query:"},
{"model": "distilbert-base-uncased", "query_prefix": "Query:"}
# Add more model configurations as needed
]
)
# Uncomment this line if passing dataset_name instead of dataset.
# loader.load_dataset()
# Process the splits with all models loaded
loader.process(
column="output",
preload_models=True
)
# To access the processed dataset
processed_dataset = loader.get_dataset()
print(processed_dataset[0])You can also embed a single text using multiple models:
from ragoon import EmbeddingsDataLoader
# Initialize the dataset loader with multiple models
loader = EmbeddingsDataLoader(
token="hf_token",
model_configs=[
{"model": "bert-base-uncased"},
{"model": "distilbert-base-uncased"}
]
)
# Load models
loader.load_models()
# Embed a single text with all loaded models
text = "This is a single text for embedding."
embedding_result = loader.batch_encode(text)
# Output the embeddings
print(embedding_result)The SimilaritySearch class is instantiated with specific parameters to configure the embedding model and search infrastructure. The chosen model, louisbrulenaudet/tsdae-lemone-mbert-base, is likely a multilingual BERT model fine-tuned with TSDAE (Transfomer-based Denoising Auto-Encoder) on a custom dataset. This model choice suggests a focus on multilingual capabilities and improved semantic representations.
The cuda device specification leverages GPU acceleration, crucial for efficient processing of large datasets. The embedding dimension of 768 is typical for BERT-based models, representing a balance between expressiveness and computational efficiency. The ip (inner product) metric is selected for similarity comparisons, which is computationally faster than cosine similarity when vectors are normalized. The i8 dtype indicates 8-bit integer quantization, a technique that significantly reduces memory usage and speeds up similarity search at the cost of a small accuracy rade-off.
import polars as pl
from ragoon import (
dataset_loader,
SimilaritySearch,
EmbeddingsVisualizer
)
dataset = dataset_loader(
name="louisbrulenaudet/dac6-instruct",
streaming=False,
split="train"
)
dataset.save_to_disk("dataset.hf")
instance = SimilaritySearch(
model_name="louisbrulenaudet/tsdae-lemone-mbert-base",
device="cuda",
ndim=768,
metric="ip",
dtype="i8"
)
embeddings = instance.encode(corpus=dataset["output"])
ubinary_embeddings = instance.quantize_embeddings(
embeddings=embeddings,
quantization_type="ubinary"
)
int8_embeddings = instance.quantize_embeddings(
embeddings=embeddings,
quantization_type="int8"
)
instance.create_usearch_index(
int8_embeddings=int8_embeddings,
index_path="./usearch_int8.index",
save=True
)
instance.create_faiss_index(
ubinary_embeddings=ubinary_embeddings,
index_path="./faiss_ubinary.index",
save=True
)
top_k_scores, top_k_indices = instance.search(
query="Définir le rôle d'un intermédiaire concepteur conformément à l'article 1649 AE du Code général des Impôts.",
top_k=10,
rescore_multiplier=4
)
try:
dataframe = pl.from_arrow(dataset.data.table).with_row_index()
except:
dataframe = pl.from_arrow(dataset.data.table).with_row_count(
name="index"
)
scores_df = pl.DataFrame(
{
"index": top_k_indices,
"score": top_k_scores
}
).with_columns(
pl.col("index").cast(pl.UInt32)
)
search_results = dataframe.filter(
pl.col("index").is_in(top_k_indices)
).join(
scores_df,
how="inner",
on="index"
)
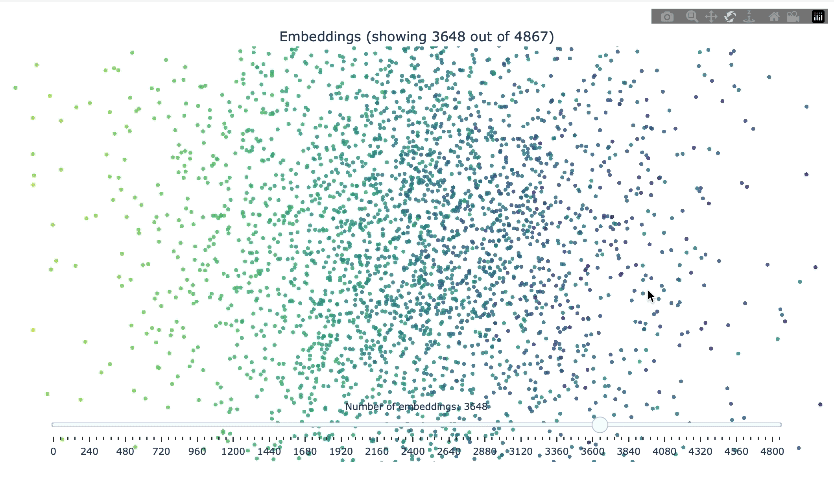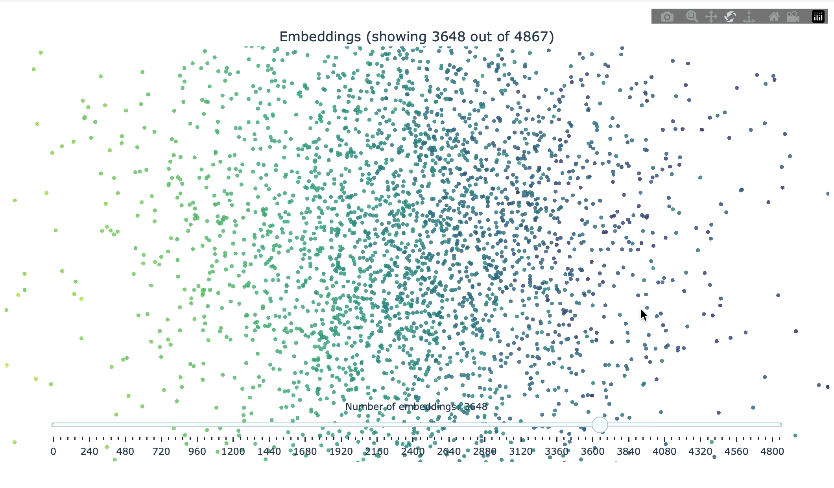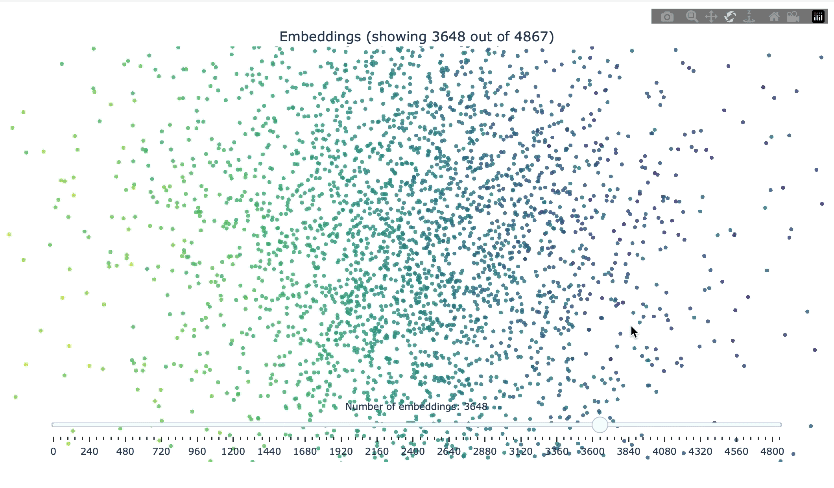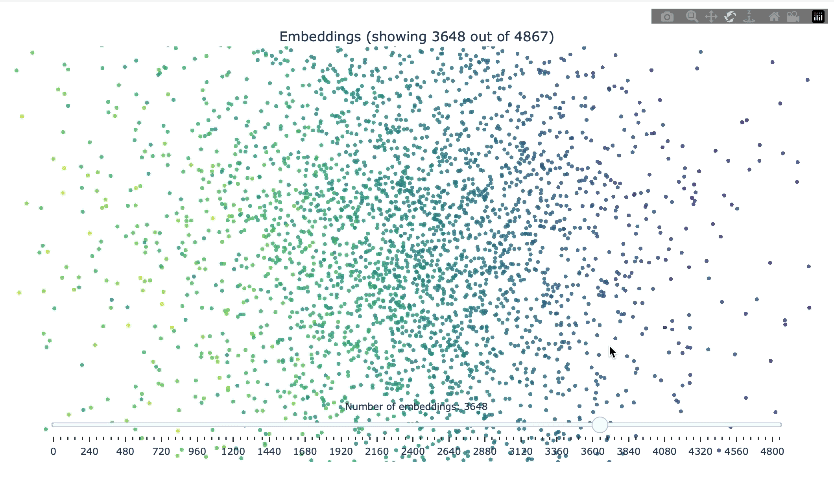
print("search_results")This class provides functionality to load embeddings from a FAISS index, reduce their dimensionality using PCA and/or t-SNE, and visualize them in an interactive 3D plot.
from ragoon import EmbeddingsVisualizer
visualizer = EmbeddingsVisualizer(
index_path="path/to/index",
dataset_path="path/to/dataset"
)
visualizer.visualize(
method="pca",
save_html=True,
html_file_name="embedding_visualization.html"
)
RAGoon is a Python library that aims to improve the performance of language models by providing contextually relevant information through retrieval-based querying, web scraping, and data augmentation techniques. It integrates various APIs, enabling users to retrieve information from the web, enrich it with domain-specific knowledge, and feed it to language models for more informed responses.
RAGoon's core functionality revolves around the concept of few-shot learning, where language models are provided with a small set of high-quality examples to enhance their understanding and generate more accurate outputs. By curating and retrieving relevant data from the web, RAGoon equips language models with the necessary context and knowledge to tackle complex queries and generate insightful responses.
from groq import Groq
# from openai import OpenAI
from ragoon import WebRAG
# Initialize RAGoon instance
ragoon = WebRAG(
google_api_key="your_google_api_key",
google_cx="your_google_cx",
completion_client=Groq(api_key="your_groq_api_key")
)
# Search and get results
query = "I want to do a left join in Python Polars"
results = ragoon.search(
query=query,
completion_model="Llama3-70b-8192",
max_tokens=512,
temperature=1,
)
# Print results
print(results)Building something cool with RAGoon? Consider adding a badge to your project card.
[<img src="https://raw.githubusercontent.com/louisbrulenaudet/ragoon/main/assets/badge.svg" alt="Built with RAGoon" width="200" height="32"/>](https://github.com/louisbrulenaudet/ragoon)![]()
If you use this code in your research, please use the following BibTeX entry.
@misc{louisbrulenaudet2024,
author = {Louis Brulé Naudet},
title = {RAGoon : High level library for batched embeddings generation, blazingly-fast web-based RAG and quantized indexes processing},
howpublished = {\url{https://github.com/louisbrulenaudet/ragoon}},
year = {2024}
}If you have any feedback, please reach out at [email protected].
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ragoon
Similar Open Source Tools
ragoon
RAGoon is a high-level library designed for batched embeddings generation, fast web-based RAG (Retrieval-Augmented Generation) processing, and quantized indexes processing. It provides NLP utilities for multi-model embedding production, high-dimensional vector visualization, and enhancing language model performance through search-based querying, web scraping, and data augmentation techniques.

ChatRex
ChatRex is a Multimodal Large Language Model (MLLM) designed to seamlessly integrate fine-grained object perception and robust language understanding. By adopting a decoupled architecture with a retrieval-based approach for object detection and leveraging high-resolution visual inputs, ChatRex addresses key challenges in perception tasks. It is powered by the Rexverse-2M dataset with diverse image-region-text annotations. ChatRex can be applied to various scenarios requiring fine-grained perception, such as object detection, grounded conversation, grounded image captioning, and region understanding.

LightRAG
LightRAG is a PyTorch library designed for building and optimizing Retriever-Agent-Generator (RAG) pipelines. It follows principles of simplicity, quality, and optimization, offering developers maximum customizability with minimal abstraction. The library includes components for model interaction, output parsing, and structured data generation. LightRAG facilitates tasks like providing explanations and examples for concepts through a question-answering pipeline.
LLM-Microscope
LLM-Microscope is a toolkit designed for quantifying and visualizing language model internals. It provides functions for calculating anisotropy, intrinsic dimension, and linearity score. The toolkit also includes a Logit Lens feature for analyzing model predictions and losses. Users can easily install the toolkit using pip and explore the functionalities through provided examples.
cappr
CAPPr is a tool for text classification that does not require training or post-processing. It allows users to have their language models pick from a list of choices or compute the probability of a completion given a prompt. The tool aims to help users get more out of open source language models by simplifying the text classification process. CAPPr can be used with GGUF models, Hugging Face models, models from the OpenAI API, and for tasks like caching instructions, extracting final answers from step-by-step completions, and running predictions in batches with different sets of completions.

GraphRAG-SDK
Build fast and accurate GenAI applications with GraphRAG SDK, a specialized toolkit for building Graph Retrieval-Augmented Generation (GraphRAG) systems. It integrates knowledge graphs, ontology management, and state-of-the-art LLMs to deliver accurate, efficient, and customizable RAG workflows. The SDK simplifies the development process by automating ontology creation, knowledge graph agent creation, and query handling, enabling users to interact and query their knowledge graphs effectively. It supports multi-agent systems and orchestrates agents specialized in different domains. The SDK is optimized for FalkorDB, ensuring high performance and scalability for large-scale applications. By leveraging knowledge graphs, it enables semantic relationships and ontology-driven queries that go beyond standard vector similarity, enhancing retrieval-augmented generation capabilities.
gritlm
The 'gritlm' repository provides all materials for the paper Generative Representational Instruction Tuning. It includes code for inference, training, evaluation, and known issues related to the GritLM model. The repository also offers models for embedding and generation tasks, along with instructions on how to train and evaluate the models. Additionally, it contains visualizations, acknowledgements, and a citation for referencing the work.
unitxt
Unitxt is a customizable library for textual data preparation and evaluation tailored to generative language models. It natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively.

continuous-eval
Open-Source Evaluation for LLM Applications. `continuous-eval` is an open-source package created for granular and holistic evaluation of GenAI application pipelines. It offers modularized evaluation, a comprehensive metric library covering various LLM use cases, the ability to leverage user feedback in evaluation, and synthetic dataset generation for testing pipelines. Users can define their own metrics by extending the Metric class. The tool allows running evaluation on a pipeline defined with modules and corresponding metrics. Additionally, it provides synthetic data generation capabilities to create user interaction data for evaluation or training purposes.

lionagi
LionAGI is a powerful intelligent workflow automation framework that introduces advanced ML models into any existing workflows and data infrastructure. It can interact with almost any model, run interactions in parallel for most models, produce structured pydantic outputs with flexible usage, automate workflow via graph based agents, use advanced prompting techniques, and more. LionAGI aims to provide a centralized agent-managed framework for "ML-powered tools coordination" and to dramatically lower the barrier of entries for creating use-case/domain specific tools. It is designed to be asynchronous only and requires Python 3.10 or higher.
redisvl
Redis Vector Library (RedisVL) is a Python client library for building AI applications on top of Redis. It provides a high-level interface for managing vector indexes, performing vector search, and integrating with popular embedding models and providers. RedisVL is designed to make it easy for developers to build and deploy AI applications that leverage the speed, flexibility, and reliability of Redis.
go-utcp
The Universal Tool Calling Protocol (UTCP) is a modern, flexible, and scalable standard for defining and interacting with tools across various communication protocols. It emphasizes scalability, interoperability, and ease of use. It provides built-in transports for HTTP, CLI, Server-Sent Events, streaming HTTP, GraphQL, MCP, and UDP. Users can use the library to construct a client and call tools using the available transports. The library also includes utilities for variable substitution, in-memory repository for storing providers and tools, and OpenAPI conversion to UTCP manuals.

letta
Letta is an open source framework for building stateful LLM applications. It allows users to build stateful agents with advanced reasoning capabilities and transparent long-term memory. The framework is white box and model-agnostic, enabling users to connect to various LLM API backends. Letta provides a graphical interface, the Letta ADE, for creating, deploying, interacting, and observing with agents. Users can access Letta via REST API, Python, Typescript SDKs, and the ADE. Letta supports persistence by storing agent data in a database, with PostgreSQL recommended for data migrations. Users can install Letta using Docker or pip, with Docker defaulting to PostgreSQL and pip defaulting to SQLite. Letta also offers a CLI tool for interacting with agents. The project is open source and welcomes contributions from the community.

xlstm
xLSTM is a new Recurrent Neural Network architecture based on ideas of the original LSTM. Through Exponential Gating with appropriate normalization and stabilization techniques and a new Matrix Memory it overcomes the limitations of the original LSTM and shows promising performance on Language Modeling when compared to Transformers or State Space Models. The package is based on PyTorch and was tested for versions >=1.8. For the CUDA version of xLSTM, you need Compute Capability >= 8.0. The xLSTM tool provides two main components: xLSTMBlockStack for non-language applications or integrating in other architectures, and xLSTMLMModel for language modeling or other token-based applications.

Jlama
Jlama is a modern Java inference engine designed for large language models. It supports various model types such as Gemma, Llama, Mistral, GPT-2, BERT, and more. The tool implements features like Flash Attention, Mixture of Experts, and supports different model quantization formats. Built with Java 21 and utilizing the new Vector API for faster inference, Jlama allows users to add LLM inference directly to their Java applications. The tool includes a CLI for running models, a simple UI for chatting with LLMs, and examples for different model types.
SenseVoice
SenseVoice is a speech foundation model focusing on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection. Trained with over 400,000 hours of data, it supports more than 50 languages and excels in emotion recognition and sound event detection. The model offers efficient inference with low latency and convenient finetuning scripts. It can be deployed for service with support for multiple client-side languages. SenseVoice-Small model is open-sourced and provides capabilities for Mandarin, Cantonese, English, Japanese, and Korean. The tool also includes features for natural speech generation and fundamental speech recognition tasks.
For similar tasks
ragoon
RAGoon is a high-level library designed for batched embeddings generation, fast web-based RAG (Retrieval-Augmented Generation) processing, and quantized indexes processing. It provides NLP utilities for multi-model embedding production, high-dimensional vector visualization, and enhancing language model performance through search-based querying, web scraping, and data augmentation techniques.
blockoli
Blockoli is a high-performance tool for code indexing, embedding generation, and semantic search tool for use with LLMs. It is built in Rust and uses the ASTerisk crate for semantic code parsing. Blockoli allows you to efficiently index, store, and search code blocks and their embeddings using vector similarity. Key features include indexing code blocks from a codebase, generating vector embeddings for code blocks using a pre-trained model, storing code blocks and their embeddings in a SQLite database, performing efficient similarity search on code blocks using vector embeddings, providing a REST API for easy integration with other tools and platforms, and being fast and memory-efficient due to its implementation in Rust.

client-js
The Mistral JavaScript client is a library that allows you to interact with the Mistral AI API. With this client, you can perform various tasks such as listing models, chatting with streaming, chatting without streaming, and generating embeddings. To use the client, you can install it in your project using npm and then set up the client with your API key. Once the client is set up, you can use it to perform the desired tasks. For example, you can use the client to chat with a model by providing a list of messages. The client will then return the response from the model. You can also use the client to generate embeddings for a given input. The embeddings can then be used for various downstream tasks such as clustering or classification.
fastllm
A collection of LLM services you can self host via docker or modal labs to support your applications development. The goal is to provide docker containers or modal labs deployments of common patterns when using LLMs and endpoints to integrate easily with existing codebases using the openai api. It supports GPT4all's embedding api, JSONFormer api for chat completion, Cross Encoders based on sentence transformers, and provides documentation using MkDocs.

openai-kotlin
OpenAI Kotlin API client is a Kotlin client for OpenAI's API with multiplatform and coroutines capabilities. It allows users to interact with OpenAI's API using Kotlin programming language. The client supports various features such as models, chat, images, embeddings, files, fine-tuning, moderations, audio, assistants, threads, messages, and runs. It also provides guides on getting started, chat & function call, file source guide, and assistants. Sample apps are available for reference, and troubleshooting guides are provided for common issues. The project is open-source and licensed under the MIT license, allowing contributions from the community.

azure-search-vector-samples
This repository provides code samples in Python, C#, REST, and JavaScript for vector support in Azure AI Search. It includes demos for various languages showcasing vectorization of data, creating indexes, and querying vector data. Additionally, it offers tools like Azure AI Search Lab for experimenting with AI-enabled search scenarios in Azure and templates for deploying custom chat-with-your-data solutions. The repository also features documentation on vector search, hybrid search, creating and querying vector indexes, and REST API references for Azure AI Search and Azure OpenAI Service.
llm
LLM is a CLI utility and Python library for interacting with Large Language Models, both via remote APIs and models that can be installed and run on your own machine. It allows users to run prompts from the command-line, store results in SQLite, generate embeddings, and more. The tool supports self-hosted language models via plugins and provides access to remote and local models. Users can install plugins to access models by different providers, including models that can be installed and run on their own device. LLM offers various options for running Mistral models in the terminal and enables users to start chat sessions with models. Additionally, users can use a system prompt to provide instructions for processing input to the tool.
GenAI-Showcase
The Generative AI Use Cases Repository showcases a wide range of applications in generative AI, including Retrieval-Augmented Generation (RAG), AI Agents, and industry-specific use cases. It provides practical notebooks and guidance on utilizing frameworks such as LlamaIndex and LangChain, and demonstrates how to integrate models from leading AI research companies like Anthropic and OpenAI.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.