
cappr
Completion After Prompt Probability. Make your LLM make a choice
Stars: 64
CAPPr is a tool for text classification that does not require training or post-processing. It allows users to have their language models pick from a list of choices or compute the probability of a completion given a prompt. The tool aims to help users get more out of open source language models by simplifying the text classification process. CAPPr can be used with GGUF models, Hugging Face models, models from the OpenAI API, and for tasks like caching instructions, extracting final answers from step-by-step completions, and running predictions in batches with different sets of completions.
README:



CAPPr performs text classification. No training or post-processing needed.
Just have your LLM pick from a list of choices.
Or compute the probability of a completion given a prompt.
Squeeze more out
of open source LLMs.
Use a GGUF model
from llama_cpp import Llama
from cappr.llama_cpp.classify import predict
# Load model
model = Llama("./TinyLLama-v0.Q8_0.gguf", verbose=False)
prompt = """Gary told Spongebob a story:
There once was a man from Peru; who dreamed he was eating his shoe. He
woke with a fright, in the middle of the night, to find that his dream
had come true.
The moral of the story is to"""
completions = (
"look at the bright side",
"use your imagination",
"eat shoes",
)
pred = predict(prompt, completions, model)
print(pred)
# use your imaginationSee this page of the documentation for more info on using GGUF models.
Use a Hugging Face model
from transformers import AutoModelForCausalLM, AutoTokenizer
from cappr.huggingface.classify import predict
# Load a model and its tokenizer
model_name = "gpt2"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Which planet is closer to the Sun: Mercury or Earth?"
completions = ("Mercury", "Earth")
pred = predict(prompt, completions, model_and_tokenizer=(model, tokenizer))
print(pred)
# MercurySee this page of the
documentation
for more info on using transformers models.
Cache instructions to save time
Many prompts start with the same set of instructions, e.g., a system prompt plus a handful of example input-output pairs. Instead of repeatedly running the model on common instructions, cache them so that future computations are faster.
Here's an
example using
cappr.huggingface.classify.cache_model.
from transformers import AutoModelForCausalLM, AutoTokenizer
from cappr.huggingface.classify import cache_model, predict
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained("gpt2")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model_and_tokenizer = (model, tokenizer)
# Create data
prompt_prefix = '''Instructions: complete the sequence.
Here are examples:
A, B, C => D
1, 2, 3 => 4
Complete this sequence:'''
prompts = ["a, b, c =>", "X, Y =>"]
completions = ["d", "Z", "Hi"]
# Cache prompt_prefix because it's used for all prompts
cached_model_and_tokenizer = cache_model(
model_and_tokenizer, prompt_prefix
)
# Compute
preds = predict(
prompts, completions, cached_model_and_tokenizer
)
print(preds)
# ['d', 'Z']Use a model from the OpenAI API
This model must be compatible with the
/v1/completions
endpoint
(excluding
gpt-3.5-turbo-instruct).
from cappr.openai.classify import predict
prompt = """
Tweet about a movie: "Oppenheimer was pretty good. But 3 hrs...cmon Nolan."
This tweet contains the following criticism:
""".strip("\n")
completions = ("bad message", "too long", "unfunny")
pred = predict(prompt, completions, model="text-ada-001")
print(pred)
# too longSee this page of the documentation for more info on using OpenAI models.
Extract the final answer from a step-by-step completion
Step-by-step and chain-of-thought prompts are highly effective ways to get an LLM to "reason" about more complex tasks. But if you need a structured output, a step-by-step completion is unwieldy. Use CAPPr to extract the final answer from these types of completions, given a list of possible answers.
See this idea in action here in the documentation.
Run in batches
Also, let's predict probabilities instead of the class.
from transformers import AutoModelForCausalLM, AutoTokenizer
from cappr.huggingface.classify import predict_proba
# Load a model and its tokenizer
model_name = "gpt2"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompts = [
"Stephen Curry is a",
"Martina Navratilova was a",
"Dexter, from the TV Series Dexter's Laboratory, is a",
"LeBron James is a",
]
# Each of the prompts could be completed with one of these:
class_names = ("basketball player", "tennis player", "scientist")
prior = ( 1/6, 1/6, 2/3 )
# Say I expect most of my data to have scientists
# Run CAPPr
pred_probs = predict_proba(
prompts=prompts,
completions=class_names,
model_and_tokenizer=(model, tokenizer),
batch_size=32, # whatever fits on your CPU/GPU
prior=prior,
)
# pred_probs[i,j] = probability that prompts[i] is classified as class_names[j]
print(pred_probs.round(1))
# [[0.5 0.3 0.2]
# [0.3 0.6 0.2]
# [0.1 0.1 0.8]
# [0.8 0.2 0. ]]
# For each prompt, which completion is most likely?
pred_class_idxs = pred_probs.argmax(axis=-1)
preds = [class_names[pred_class_idx] for pred_class_idx in pred_class_idxs]
print(preds)
# ['basketball player',
# 'tennis player',
# 'scientist',
# 'basketball player']Run in batches, where each prompt has a different set of possible completions
Again, let's predict probabilities.
from transformers import AutoModelForCausalLM, AutoTokenizer
from cappr.huggingface.classify import predict_proba_examples
from cappr import Example
# Load a model and its tokenizer
model_name = "gpt2"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Create a sequence of Example objects representing your classification tasks
examples = [
Example(
prompt="Jodie Foster played",
completions=("Clarice Starling", "Trinity in The Matrix"),
),
Example(
prompt="Batman, from Batman: The Animated Series, was played by",
completions=("Pete Holmes", "Kevin Conroy", "Spongebob!"),
prior= ( 1/3 , 2/3 , 0 ),
),
]
# Run CAPPr
pred_probs = predict_proba_examples(
examples, model_and_tokenizer=(model, tokenizer)
)
# pred_probs[i][j] = probability that examples[i].prompt is classified as
# examples[i].completions[j]
print([example_pred_probs.round(2) for example_pred_probs in pred_probs])
# [array([0.7, 0.3]),
# array([0.03, 0.97, 0. ])]
# For each example, which completion is most likely?
pred_class_idxs = [
example_pred_probs.argmax() for example_pred_probs in pred_probs
]
preds = [
example.completions[pred_class_idx]
for example, pred_class_idx in zip(examples, pred_class_idxs)
]
print(preds)
# ['Clarice Starling',
# 'Kevin Conroy']See the demos for demonstrations
of slightly harder classification tasks.
For CAPPr, GPTQ models are the most computationally performant. These models are
compatible with cappr.huggingface.classify. See this page of the
documentation
for more info on using these models.
See this page of the documentation.
Reduce engineering complexity.
See this page of the documentation for more info.
You input a prompt string, a end_of_prompt string (a whitespace or empty) and a set
of candidate completion strings such that the string—
{prompt}{end_of_prompt}{completion}—is a naturally flowing thought. CAPPr picks the completion which is mostly likely to
follow prompt by computing the:
Completion
After
Prompt
Probability
The method is fleshed out in my question on Cross Validated.
See this page of the documentation.
See this page of the documentation.
I'm dumping todos here:
Feel free to raise issues ofc
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for cappr
Similar Open Source Tools
cappr
CAPPr is a tool for text classification that does not require training or post-processing. It allows users to have their language models pick from a list of choices or compute the probability of a completion given a prompt. The tool aims to help users get more out of open source language models by simplifying the text classification process. CAPPr can be used with GGUF models, Hugging Face models, models from the OpenAI API, and for tasks like caching instructions, extracting final answers from step-by-step completions, and running predictions in batches with different sets of completions.

ChatRex
ChatRex is a Multimodal Large Language Model (MLLM) designed to seamlessly integrate fine-grained object perception and robust language understanding. By adopting a decoupled architecture with a retrieval-based approach for object detection and leveraging high-resolution visual inputs, ChatRex addresses key challenges in perception tasks. It is powered by the Rexverse-2M dataset with diverse image-region-text annotations. ChatRex can be applied to various scenarios requiring fine-grained perception, such as object detection, grounded conversation, grounded image captioning, and region understanding.

LLM-Blender
LLM-Blender is a framework for ensembling large language models (LLMs) to achieve superior performance. It consists of two modules: PairRanker and GenFuser. PairRanker uses pairwise comparisons to distinguish between candidate outputs, while GenFuser merges the top-ranked candidates to create an improved output. LLM-Blender has been shown to significantly surpass the best LLMs and baseline ensembling methods across various metrics on the MixInstruct benchmark dataset.
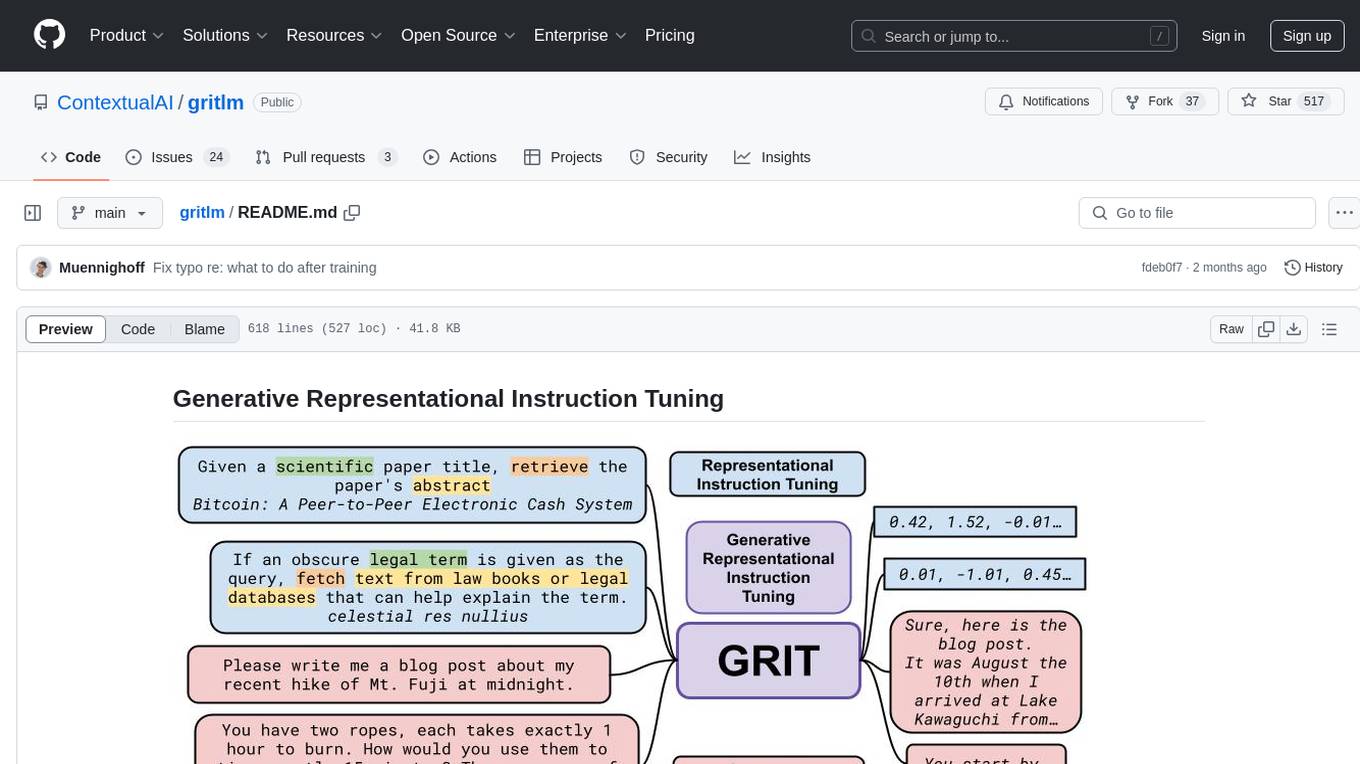
gritlm
The 'gritlm' repository provides all materials for the paper Generative Representational Instruction Tuning. It includes code for inference, training, evaluation, and known issues related to the GritLM model. The repository also offers models for embedding and generation tasks, along with instructions on how to train and evaluate the models. Additionally, it contains visualizations, acknowledgements, and a citation for referencing the work.

kor
Kor is a prototype tool designed to help users extract structured data from text using Language Models (LLMs). It generates prompts, sends them to specified LLMs, and parses the output. The tool works with the parsing approach and is integrated with the LangChain framework. Kor is compatible with pydantic v2 and v1, and schema is typed checked using pydantic. It is primarily used for extracting information from text based on provided reference examples and schema documentation. Kor is designed to work with all good-enough LLMs regardless of their support for function/tool calling or JSON modes.

MemoryLLM
MemoryLLM is a large language model designed for self-updating capabilities. It offers pretrained models with different memory capacities and features, such as chat models. The repository provides training code, evaluation scripts, and datasets for custom experiments. MemoryLLM aims to enhance knowledge retention and performance on various natural language processing tasks.
Phi-3-Vision-MLX
Phi-3-MLX is a versatile AI framework that leverages both the Phi-3-Vision multimodal model and the Phi-3-Mini-128K language model optimized for Apple Silicon using the MLX framework. It provides an easy-to-use interface for a wide range of AI tasks, from advanced text generation to visual question answering and code execution. The project features support for batched generation, flexible agent system, custom toolchains, model quantization, LoRA fine-tuning capabilities, and API integration for extended functionality.

FlashLearn
FlashLearn is a tool that provides a simple interface and orchestration for incorporating Agent LLMs into workflows and ETL pipelines. It allows data transformations, classifications, summarizations, rewriting, and custom multi-step tasks using LLMs. Each step and task has a compact JSON definition, making pipelines easy to understand and maintain. FlashLearn supports LiteLLM, Ollama, OpenAI, DeepSeek, and other OpenAI-compatible clients.
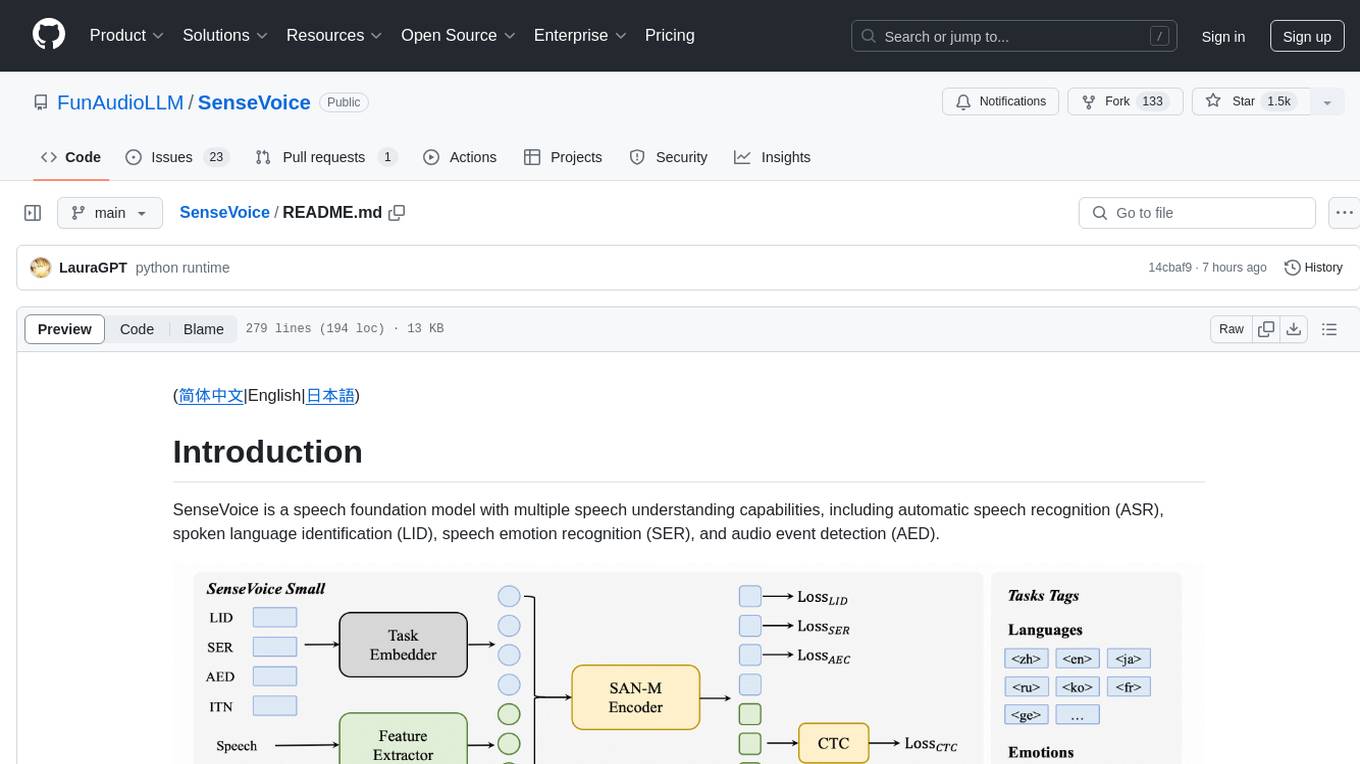
SenseVoice
SenseVoice is a speech foundation model focusing on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection. Trained with over 400,000 hours of data, it supports more than 50 languages and excels in emotion recognition and sound event detection. The model offers efficient inference with low latency and convenient finetuning scripts. It can be deployed for service with support for multiple client-side languages. SenseVoice-Small model is open-sourced and provides capabilities for Mandarin, Cantonese, English, Japanese, and Korean. The tool also includes features for natural speech generation and fundamental speech recognition tasks.

memobase
Memobase is a user profile-based memory system designed to enhance Generative AI applications by enabling them to remember, understand, and evolve with users. It provides structured user profiles, scalable profiling, easy integration with existing LLM stacks, batch processing for speed, and is production-ready. Users can manage users, insert data, get memory profiles, and track user preferences and behaviors. Memobase is ideal for applications that require user analysis, tracking, and personalized interactions.

LightRAG
LightRAG is a PyTorch library designed for building and optimizing Retriever-Agent-Generator (RAG) pipelines. It follows principles of simplicity, quality, and optimization, offering developers maximum customizability with minimal abstraction. The library includes components for model interaction, output parsing, and structured data generation. LightRAG facilitates tasks like providing explanations and examples for concepts through a question-answering pipeline.

vinagent
Vinagent is a lightweight and flexible library designed for building smart agent assistants across various industries. It provides a simple yet powerful foundation for creating AI-powered customer service bots, data analysis assistants, or domain-specific automation agents. With its modular tool system, users can easily extend their agent's capabilities by integrating a wide range of tools that are self-contained, well-documented, and can be registered dynamically. Vinagent allows users to scale and adapt their agents to new tasks or environments effortlessly.

EasySteer
EasySteer is a unified framework built on vLLM for high-performance LLM steering. It offers fast, flexible, and easy-to-use steering capabilities with features like high performance, modular design, fine-grained control, pre-computed steering vectors, and an interactive demo. Users can interactively configure models, adjust steering parameters, and test interventions without writing code. The tool supports OpenAI-compatible APIs and provides modules for hidden states extraction, analysis-based steering, learning-based steering, and a frontend web interface for interactive steering and ReFT interventions.
mlx-llm
mlx-llm is a library that allows you to run Large Language Models (LLMs) on Apple Silicon devices in real-time using Apple's MLX framework. It provides a simple and easy-to-use API for creating, loading, and using LLM models, as well as a variety of applications such as chatbots, fine-tuning, and retrieval-augmented generation.

continuous-eval
Open-Source Evaluation for LLM Applications. `continuous-eval` is an open-source package created for granular and holistic evaluation of GenAI application pipelines. It offers modularized evaluation, a comprehensive metric library covering various LLM use cases, the ability to leverage user feedback in evaluation, and synthetic dataset generation for testing pipelines. Users can define their own metrics by extending the Metric class. The tool allows running evaluation on a pipeline defined with modules and corresponding metrics. Additionally, it provides synthetic data generation capabilities to create user interaction data for evaluation or training purposes.
For similar tasks
cappr
CAPPr is a tool for text classification that does not require training or post-processing. It allows users to have their language models pick from a list of choices or compute the probability of a completion given a prompt. The tool aims to help users get more out of open source language models by simplifying the text classification process. CAPPr can be used with GGUF models, Hugging Face models, models from the OpenAI API, and for tasks like caching instructions, extracting final answers from step-by-step completions, and running predictions in batches with different sets of completions.

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.

marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.

txtai
Txtai is an all-in-one embeddings database for semantic search, LLM orchestration, and language model workflows. It combines vector indexes, graph networks, and relational databases to enable vector search with SQL, topic modeling, retrieval augmented generation, and more. Txtai can stand alone or serve as a knowledge source for large language models (LLMs). Key features include vector search with SQL, object storage, topic modeling, graph analysis, multimodal indexing, embedding creation for various data types, pipelines powered by language models, workflows to connect pipelines, and support for Python, JavaScript, Java, Rust, and Go. Txtai is open-source under the Apache 2.0 license.

bert4torch
**bert4torch** is a high-level framework for training and deploying transformer models in PyTorch. It provides a simple and efficient API for building, training, and evaluating transformer models, and supports a wide range of pre-trained models, including BERT, RoBERTa, ALBERT, XLNet, and GPT-2. bert4torch also includes a number of useful features, such as data loading, tokenization, and model evaluation. It is a powerful and versatile tool for natural language processing tasks.
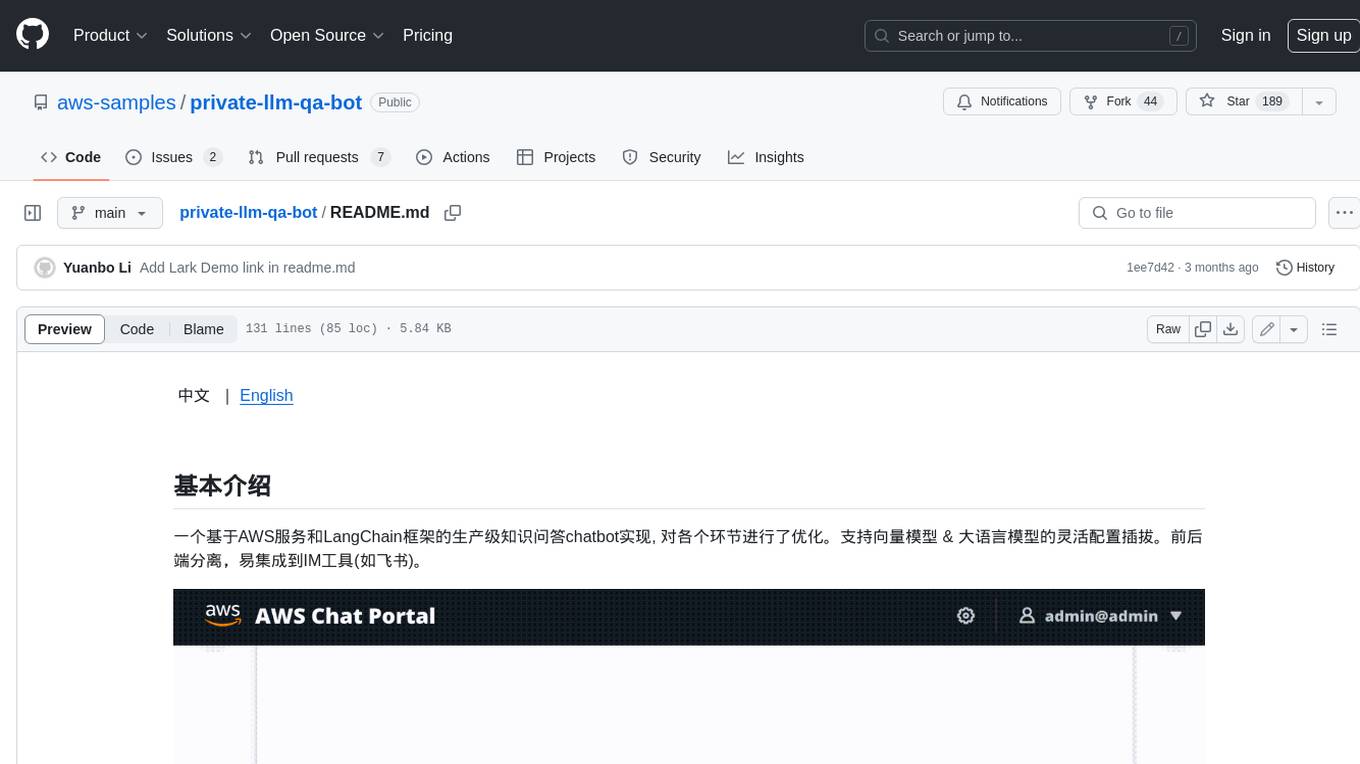
private-llm-qa-bot
This is a production-grade knowledge Q&A chatbot implementation based on AWS services and the LangChain framework, with optimizations at various stages. It supports flexible configuration and plugging of vector models and large language models. The front and back ends are separated, making it easy to integrate with IM tools (such as Feishu).

openai-cf-workers-ai
OpenAI for Workers AI is a simple, quick, and dirty implementation of OpenAI's API on Cloudflare's new Workers AI platform. It allows developers to use the OpenAI SDKs with the new LLMs without having to rewrite all of their code. The API currently supports completions, chat completions, audio transcription, embeddings, audio translation, and image generation. It is not production ready but will be semi-regularly updated with new features as they roll out to Workers AI.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.