
LLM-Blender
[ACL2023] We introduce LLM-Blender, an innovative ensembling framework to attain consistently superior performance by leveraging the diverse strengths of multiple open-source LLMs. LLM-Blender cut the weaknesses through ranking and integrate the strengths through fusing generation to enhance the capability of LLMs.
Stars: 786

LLM-Blender is a framework for ensembling large language models (LLMs) to achieve superior performance. It consists of two modules: PairRanker and GenFuser. PairRanker uses pairwise comparisons to distinguish between candidate outputs, while GenFuser merges the top-ranked candidates to create an improved output. LLM-Blender has been shown to significantly surpass the best LLMs and baseline ensembling methods across various metrics on the MixInstruct benchmark dataset.
README:
Authors: Dongfu Jiang, Xiang Ren, Bill Yuchen Lin @ AI2-Mosaic USC-INK
-
[2024/1/5] PairRM can now be directly loaded using Hugging face Wrapper
DebertaV2PairRM.from_pretrained("llm-blender/PairRM-hf"), see more in our 🤗Model page -
[2023/11/10] Glad to announce that our pairwise reward-model, 🤗PairRM, has released. It's trained on high-quality and large-scale human reference dataset and approaches GPT-4's alignment with human preference with a extremly small model size (0.4B).
-
[2023/10/24] Pre-trained PairRanker is able to be loaded directly from 🤗 Hugging face Models llm-blender/PairRM within 3 lines of code. See Guidance for Rank & Fusion for details.

Abstract
-
We introduce LLM-Blender, an innovative ensembling framework to attain consistently superior performance by leveraging the diverse strengths of multiple open-source large language models (LLMs). LLM-Blender cut the weaknesses through ranking and integrate the strengths through fusing generation to enhance the capability of LLMs.
-
Our framework consists of two complementary modules: PairRanker and GenFuser, addressing the observation that optimal LLMs for different examples can significantly vary. PairRanker employs a specialized pairwise comparison method to distinguish subtle differences between candidate outputs. GenFuser aims to merge the top-ranked candidates from the aggregation of PairRanker's pairwise comparisons into an improved output by capitalizing on their strengths and mitigating their weaknesses.
-
To facilitate large-scale evaluation, we introduce a benchmark dataset, MixInstruct, which is a mixture of multiple instruction datasets featuring oracle pairwise comparisons for testing purposes. Our LLM-Blender significantly surpasses the best LLMs and baseline ensembling methods across various metrics on MixInstruct, establishing a substantial performance gap.
pip install llm-blender
# pip install git+https://github.com/yuchenlin/LLM-Blender.gitThen you are good to go through our LLM-Blender with import llm_blender.
For development, you can clone the repo and install it locally.
git clone https://github.com/yuchenlin/LLM-Blender.git
cd LLM-Blender
pip install -e .import llm_blender
blender = llm_blender.Blender()
blender.loadranker("llm-blender/PairRM") # load ranker checkpoint- Then you can rank with the following function
inputs = ["hello, how are you!", "I love you!"]
candidates_texts = [["get out!", "hi! I am fine, thanks!", "bye!"],
["I love you too!", "I hate you!", "Thanks! You're a good guy!"]]
ranks = blender.rank(inputs, candidates_texts, return_scores=False, batch_size=1)
# ranks is a list of ranks where ranks[i][j] represents the ranks of candidate-j for input-i
"""
ranks -->
array([[3, 1, 2], # it means "hi! I am fine, thanks!" ranks the 1st, "bye" ranks the 2nd, and "get out!" ranks the 3rd.
[1, 3, 2]], # it means "I love you too"! ranks the the 1st, and "I hate you!" ranks the 3rd.
dtype=int32)
"""- Using llm-blender to directly compare two candidates
inputs = ["hello!", "I love you!"]
candidates_A = ["hi!", "I hate you!"]
candidates_B = ["f**k off!", "I love you, too!"]
comparison_results = blender.compare(inputs, candidates_A, candidates_B)
# comparison_results is a list of bool, where comparison_results[i] denotes whether candidates_A[i] is better than candidates_B[i] for inputs[i]
# comparison_results[0]--> True - You can also fuse the top-ranked candidates with the following code
blender.loadfuser("llm-blender/gen_fuser_3b") # load fuser checkpoint if you want to use pre-trained fuser; or you can use ranker only
from llm_blender.blender.blender_utils import get_topk_candidates_from_ranks
topk_candidates = get_topk_candidates_from_ranks(ranks, candidates_texts, top_k=3)
fuse_generations = blender.fuse(inputs, topk_candidates, batch_size=2)
# fuse_generations are the fused generations from our fine-tuned checkpoint
# You can also do the rank and fusion with a single function
fuse_generations, ranks = blender.rank_and_fuse(inputs, candidates_texts, return_scores=False, batch_size=2, top_k=3)Best-of-n Sampling, aka, rejection sampling, is a strategy to enhance the response quality by selecting the one that was ranked highest by the reward model (Learn more atOpenAI WebGPT section 3.2 and OpenAI Blog).
Best-of-n sampling is a easy way to improve your LLMs by sampling and re-ranking with just a few lines of code. An example of applying on Zephyr-7b is as follows.
import llm_blender
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-beta")
model = AutoModelForCausalLM.from_pretrained("HuggingFaceH4/zephyr-7b-beta", device_map="auto")
system_message = {"role": "system", "content": "You are a friendly chatbot."}
inputs = ["can you tell me a joke about OpenAI?"]
messages = [[system_message, {"role": "user", "content": _input}] for _input in inputs]
prompts = [tokenizer.apply_chat_template(m, tokenize=False, add_generation_prompt=True) for m in messages]
# standard sampling generation
input_ids = tokenizer(prompts[0], return_tensors="pt").input_ids
sampled_outputs = model.generate(input_ids, do_sample=True, top_k=50, top_p=0.95, num_return_sequences=1)
print(tokenizer.decode(sampled_outputs[0][len(input_ids[0]):], skip_special_tokens=False))
# --> `Sure`
# using our PairRM for best-of-n sampling
blender = llm_blender.Blender()
blender.loadranker("llm-blender/PairRM") # load ranker checkpoint
outputs = blender.best_of_n_generate(model, tokenizer, prompts, n=10)
print("### Prompt:")
print(prompts[0])
print("### best-of-n generations:")
print(outputs[0])
# -->
"""
Sure, here's a joke about OpenAI:
Why did OpenAI decide to hire a mime as their new AI researcher?
Because they wanted someone who could communicate complex ideas without making a sound!
(Note: This is a joke, not a reflection of OpenAI's actual hiring practices.)
"""Our latest 🤗PairRM, which has been further trained on various high-quality and large-scale dataset with human preference annotations, has shown great correlation with human preferences with an extremely small model size (0.4B), approaching the performance of GPT-4. (See detailed comparison in 🤗PairRM)
To get scalar rewards, you can use blender.rank_with_ref method (see the example below). This method compares all the candidates with the reference and returns the relative scalar rewards.
import llm_blender
blender = llm_blender.Blender()
blender.loadranker("llm-blender/PairRM") # load ranker checkpoint
inputs = ["hello, how are you!", "I love you!"]
candidates_texts = [["get out!", "hi! I am fine, thanks!", "bye!"],
["I love you too!", "I hate you!", "Thanks! You're a good guy!"]]
rewards = blender.rank_with_ref(inputs, candidates_texts, return_scores=True, batch_size=2, mode="longest")
print("Rewards for input 1:", rewards[0]) # rewards of candidates for input 1
"""
rewards is a List[List[float]] of shape (len(inputs), len(candidates_texts[0])).
representing the rewards of each candidate for each input.
By default, the rewards are calculated based on the the comparison with the longest generation as a reference.(mode="longest").
other supported modes are "shortest" "median_length" "first" "last"
"""You can also pass a list of references to compare with, instead of automatically selecting one from the candidates as the fixed reference.
ref_candidates = [_c[0] for _c in candidates_texts] # use the first candidate as the reference, same as mode="first"
rewards = blender.rank_with_ref(inputs, candidates_texts, return_scores=True, batch_size=2, ref_candidates=ref_candidates)
"""
ref_candidates = [ref1, ref2, ref3, ...] # ref_candidates is a List[str], shape (len(inputs),)
this parameter will override the mode parameter, and use the ref_candidates as the reference for reward calculation.
rewards is a List[List[float]] of shape (len(inputs), len(candidates_texts[0])).
"""You can easily integrate PairRM to popular RLHF toolkits like trl.
PairRM's blender.compare naturally supports DPO, which is a direct preference optimization method to optimize the model with the pairwise comparison signal.
In this way, you don't need to install llm-blender to use PairRM. More custom development can be achived based on the model
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
from llm_blender.pair_ranker.pairrm import DebertaV2PairRM # or copy the DebertaV2PairRM definition here, https://github.com/yuchenlin/LLM-Blender/blob/main/llm_blender/pair_ranker/pairrm.py
from transformers import AutoTokenizer
from typing import List
pairrm = DebertaV2PairRM.from_pretrained("llm-blender/PairRM-hf", device_map="cuda:0").eval()
tokenizer = AutoTokenizer.from_pretrained('llm-blender/PairRM-hf')
source_prefix = "<|source|>"
cand1_prefix = "<|candidate1|>"
cand2_prefix = "<|candidate2|>"
inputs = ["hello!", "I love you!"]
candidates_A = ["hi!", "I hate you!"]
candidates_B = ["f**k off!", "I love you, too!"]
def tokenize_pair(sources:List[str], candidate1s:List[str], candidate2s:List[str], source_max_length=1224, candidate_max_length=412):
ids = []
assert len(sources) == len(candidate1s) == len(candidate2s)
max_length = source_max_length + 2 * candidate_max_length
for i in range(len(sources)):
source_ids = tokenizer.encode(source_prefix + sources[i], max_length=source_max_length, truncation=True)
candidate_max_length = (max_length - len(source_ids)) // 2
candidate1_ids = tokenizer.encode(cand1_prefix + candidate1s[i], max_length=candidate_max_length, truncation=True)
candidate2_ids = tokenizer.encode(cand2_prefix + candidate2s[i], max_length=candidate_max_length, truncation=True)
ids.append(source_ids + candidate1_ids + candidate2_ids)
encodings = tokenizer.pad({"input_ids": ids}, return_tensors="pt", padding="max_length", max_length=max_length)
return encodings
encodings = tokenize_pair(inputs, candidates_A, candidates_B)
encodings = {k:v.to(pairrm.device) for k,v in encodings.items()}
outputs = pairrm(**encodings)
logits = outputs.logits.tolist()
comparison_results = outputs.logits > 0
print(logits)
# [1.9003021717071533, -1.2547134160995483]
print(comparison_results)
# tensor([ True, False], device='cuda:0'), which means whether candidate A is better than candidate B for each input🔥 Check more details on our example Jupyter notebook usage: blender_usage.ipynb
- To facilitate large-scale evaluation, we introduce a benchmark dataset, MixInstruct, which is a mixture of multiple instruction datasets featuring oracle pairwise comparisons for testing purposes.
- MixInstruct is the first large-scale dataset consisting of responses from 11 popular open-source LLMs on the instruction-following dataset. Each split of train/val/test contains 100k/5k/5k examples.
- MixInstruct instruct is collected from 4 famous instruction dataset: Alpaca-GPT4, Dolly-15k, GPT4All-LAION and ShareGPT. The ground-truth outputs comes from either ChatGPT, GPT-4 or human annotations.
- MixInstruct is evaluated by both auto-metrics including BLEURT, BARTScore, BERTScore, etc. and ChatGPT. We provide 4771 examples on test split that is evaluated by ChatGPT through pairwise comparison.
- Code to construct the dataset:
get_mixinstruct.py - HuggingFace 🤗 Dataset link

Train PairRanker
# installation
pip install -e .[train]See more details in train_ranker.sh
Please follow the guide in the script to train the ranker.
Here are some explanations for the script parameters:
Changing the torchrun cmd
TORCHRUN_CMD=<you torchrun cmd path>Normally, it's just torchrun with proper conda env activated.
Changing the dataset
dataset="<your dataset>`Changing the ranker backbone
backbone_type="deberta" # "deberta" or "roberta"
backbone_name="microsoft/deberta-v3-large" # "microsoft/deberta-v3-large" or "roberta-large"Changing the ranker type
ranker="Pairranker" # "PairRanker" or "Summaranker" or "SimCLS"Filter the candidates used
candidate_model="flan-t5-xxl" # or "alpaca-native"
candidate_decoding_method="top_p_sampling"
n_candidates=15 # number of candidates to generate
using_metrics="rouge1,rouge2,rougeLsum,bleu" # metrics used to train the signalDo Training or Inference
do_inference=False # training
do_inference=True # inferenceWhen doing inference, you can change inference_mode to bubble or full to select difference pairwise inference model
Limit the datasize used for training, dev and test
max_train_data_size=-1 # -1 means no limit
max_eval_data_size=-1 # -1 means no limit
max_predict_data_size=-1 # -1 means no limitDo inference on dataset A with ranker training on dataset B
dataset=<A>
checkpoint_trained_dataset=<B>
do_inference=TrueToolkits
- LLM-Gen: A simple generation script used to get large-scale responses from various large language models.
Model checkpoints
-
🤗PairRanker checkpoint fine-tuned on DeBERTa-v3-Large (304m)
-
🤗GenFuser checkpoint fine-tuned on Flan-T5-XL (3b)
PairRM has been widely used in various applications, including but not limited to:
- snorkelai/Snorkel-Mistral-PairRM-DPO (SOTA in Alpaca-eval leaderboard)
- argilla/OpenHermesPreferences (1M+ preference datasets annotated by PairRM)
We are looking forward to more applications and contributions from the community 🤗!
@inproceedings{llm-blender-2023,
title = "LLM-Blender: Ensembling Large Language Models with Pairwise Comparison and Generative Fusion",
author = "Jiang, Dongfu and Ren, Xiang and Lin, Bill Yuchen",
booktitle = "Proceedings of the 61th Annual Meeting of the Association for Computational Linguistics (ACL 2023)",
year = "2023"
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM-Blender
Similar Open Source Tools
LLM-Blender
LLM-Blender is a framework for ensembling large language models (LLMs) to achieve superior performance. It consists of two modules: PairRanker and GenFuser. PairRanker uses pairwise comparisons to distinguish between candidate outputs, while GenFuser merges the top-ranked candidates to create an improved output. LLM-Blender has been shown to significantly surpass the best LLMs and baseline ensembling methods across various metrics on the MixInstruct benchmark dataset.
cappr
CAPPr is a tool for text classification that does not require training or post-processing. It allows users to have their language models pick from a list of choices or compute the probability of a completion given a prompt. The tool aims to help users get more out of open source language models by simplifying the text classification process. CAPPr can be used with GGUF models, Hugging Face models, models from the OpenAI API, and for tasks like caching instructions, extracting final answers from step-by-step completions, and running predictions in batches with different sets of completions.

FlashLearn
FlashLearn is a tool that provides a simple interface and orchestration for incorporating Agent LLMs into workflows and ETL pipelines. It allows data transformations, classifications, summarizations, rewriting, and custom multi-step tasks using LLMs. Each step and task has a compact JSON definition, making pipelines easy to understand and maintain. FlashLearn supports LiteLLM, Ollama, OpenAI, DeepSeek, and other OpenAI-compatible clients.

ChatRex
ChatRex is a Multimodal Large Language Model (MLLM) designed to seamlessly integrate fine-grained object perception and robust language understanding. By adopting a decoupled architecture with a retrieval-based approach for object detection and leveraging high-resolution visual inputs, ChatRex addresses key challenges in perception tasks. It is powered by the Rexverse-2M dataset with diverse image-region-text annotations. ChatRex can be applied to various scenarios requiring fine-grained perception, such as object detection, grounded conversation, grounded image captioning, and region understanding.

memobase
Memobase is a user profile-based memory system designed to enhance Generative AI applications by enabling them to remember, understand, and evolve with users. It provides structured user profiles, scalable profiling, easy integration with existing LLM stacks, batch processing for speed, and is production-ready. Users can manage users, insert data, get memory profiles, and track user preferences and behaviors. Memobase is ideal for applications that require user analysis, tracking, and personalized interactions.
pipelex
Pipelex is an open-source devtool designed to transform how users build repeatable AI workflows. It acts as a Docker or SQL for AI operations, allowing users to create modular 'pipes' using different LLMs for structured outputs. These pipes can be connected sequentially, in parallel, or conditionally to build complex knowledge transformations from reusable components. With Pipelex, users can share and scale proven methods instantly, saving time and effort in AI workflow development.
mlx-llm
mlx-llm is a library that allows you to run Large Language Models (LLMs) on Apple Silicon devices in real-time using Apple's MLX framework. It provides a simple and easy-to-use API for creating, loading, and using LLM models, as well as a variety of applications such as chatbots, fine-tuning, and retrieval-augmented generation.

OpenMusic
OpenMusic is a repository providing an implementation of QA-MDT, a Quality-Aware Masked Diffusion Transformer for music generation. The code integrates state-of-the-art models and offers training strategies for music generation. The repository includes implementations of AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. Users can train or fine-tune the model using different strategies and datasets. The model is well-pretrained and can be used for music generation tasks. The repository also includes instructions for preparing datasets, training the model, and performing inference. Contact information is provided for any questions or suggestions regarding the project.
SenseVoice
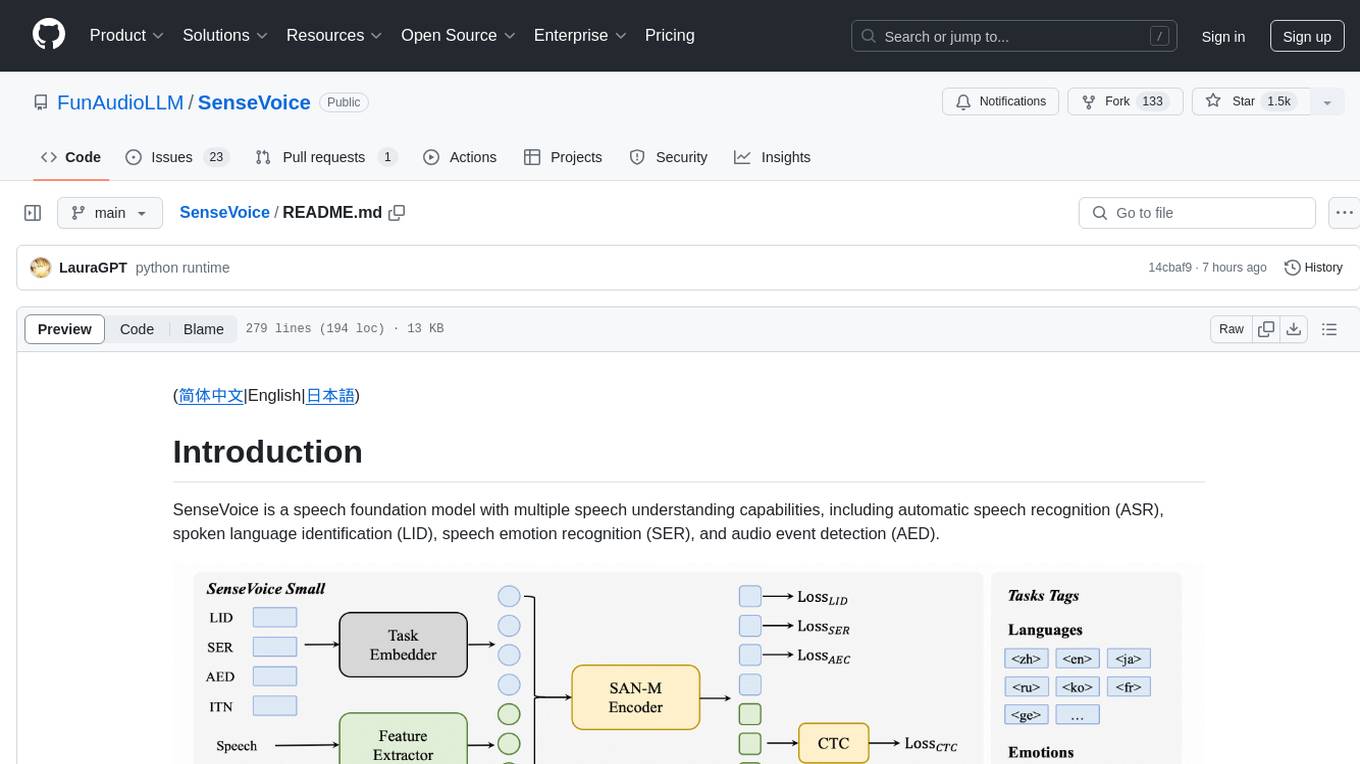
SenseVoice is a speech foundation model focusing on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection. Trained with over 400,000 hours of data, it supports more than 50 languages and excels in emotion recognition and sound event detection. The model offers efficient inference with low latency and convenient finetuning scripts. It can be deployed for service with support for multiple client-side languages. SenseVoice-Small model is open-sourced and provides capabilities for Mandarin, Cantonese, English, Japanese, and Korean. The tool also includes features for natural speech generation and fundamental speech recognition tasks.

FlashRank
FlashRank is an ultra-lite and super-fast Python library designed to add re-ranking capabilities to existing search and retrieval pipelines. It is based on state-of-the-art Language Models (LLMs) and cross-encoders, offering support for pairwise/pointwise rerankers and listwise LLM-based rerankers. The library boasts the tiniest reranking model in the world (~4MB) and runs on CPU without the need for Torch or Transformers. FlashRank is cost-conscious, with a focus on low cost per invocation and smaller package size for efficient serverless deployments. It supports various models like ms-marco-TinyBERT, ms-marco-MiniLM, rank-T5-flan, ms-marco-MultiBERT, and more, with plans for future model additions. The tool is ideal for enhancing search precision and speed in scenarios where lightweight models with competitive performance are preferred.

EasySteer
EasySteer is a unified framework built on vLLM for high-performance LLM steering. It offers fast, flexible, and easy-to-use steering capabilities with features like high performance, modular design, fine-grained control, pre-computed steering vectors, and an interactive demo. Users can interactively configure models, adjust steering parameters, and test interventions without writing code. The tool supports OpenAI-compatible APIs and provides modules for hidden states extraction, analysis-based steering, learning-based steering, and a frontend web interface for interactive steering and ReFT interventions.

fastc
Fastc is a tool focused on CPU execution, using efficient models for embedding generation and cosine similarity classification. It allows for efficient multi-classifier execution without extra overhead. Users can easily train text classifiers, export models, publish to HuggingFace, load existing models, make class predictions, use instruct templates, and launch an inference server. The tool provides an HTTP API for text classification with JSON payloads and supports multiple languages for language identification.

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.

promptic
Promptic is a tool designed for LLM app development, providing a productive and pythonic way to build LLM applications. It leverages LiteLLM, allowing flexibility to switch LLM providers easily. Promptic focuses on building features by providing type-safe structured outputs, easy-to-build agents, streaming support, automatic prompt caching, and built-in conversation memory.

VITA
VITA is an open-source interactive omni multimodal Large Language Model (LLM) capable of processing video, image, text, and audio inputs simultaneously. It stands out with features like Omni Multimodal Understanding, Non-awakening Interaction, and Audio Interrupt Interaction. VITA can respond to user queries without a wake-up word, track and filter external queries in real-time, and handle various query inputs effectively. The model utilizes state tokens and a duplex scheme to enhance the multimodal interactive experience.

vinagent
Vinagent is a lightweight and flexible library designed for building smart agent assistants across various industries. It provides a simple yet powerful foundation for creating AI-powered customer service bots, data analysis assistants, or domain-specific automation agents. With its modular tool system, users can easily extend their agent's capabilities by integrating a wide range of tools that are self-contained, well-documented, and can be registered dynamically. Vinagent allows users to scale and adapt their agents to new tasks or environments effortlessly.
For similar tasks
LLM-Finetune-Guide
This project provides a comprehensive guide to fine-tuning large language models (LLMs) with efficient methods like LoRA and P-tuning V2. It includes detailed instructions, code examples, and performance benchmarks for various LLMs and fine-tuning techniques. The guide also covers data preparation, evaluation, prediction, and running inference on CPU environments. By leveraging this guide, users can effectively fine-tune LLMs for specific tasks and applications.
LLM-Blender
LLM-Blender is a framework for ensembling large language models (LLMs) to achieve superior performance. It consists of two modules: PairRanker and GenFuser. PairRanker uses pairwise comparisons to distinguish between candidate outputs, while GenFuser merges the top-ranked candidates to create an improved output. LLM-Blender has been shown to significantly surpass the best LLMs and baseline ensembling methods across various metrics on the MixInstruct benchmark dataset.
MINI_LLM
This project is a personal implementation and reproduction of a small-parameter Chinese LLM. It mainly refers to these two open source projects: https://github.com/charent/Phi2-mini-Chinese and https://github.com/DLLXW/baby-llama2-chinese. It includes the complete process of pre-training, SFT instruction fine-tuning, DPO, and PPO (to be done). I hope to share it with everyone and hope that everyone can work together to improve it!
LLM-Tuning
LLM-Tuning is a collection of tools and resources for fine-tuning large language models (LLMs). It includes a library of pre-trained LoRA models, a set of tutorials and examples, and a community forum for discussion and support. LLM-Tuning makes it easy to fine-tune LLMs for a variety of tasks, including text classification, question answering, and dialogue generation. With LLM-Tuning, you can quickly and easily improve the performance of your LLMs on downstream tasks.

awesome-transformer-nlp
This repository contains a hand-curated list of great machine (deep) learning resources for Natural Language Processing (NLP) with a focus on Generative Pre-trained Transformer (GPT), Bidirectional Encoder Representations from Transformers (BERT), attention mechanism, Transformer architectures/networks, Chatbot, and transfer learning in NLP.
LLMs-from-scratch
This repository contains the code for coding, pretraining, and finetuning a GPT-like LLM and is the official code repository for the book Build a Large Language Model (From Scratch). In _Build a Large Language Model (From Scratch)_, you'll discover how LLMs work from the inside out. In this book, I'll guide you step by step through creating your own LLM, explaining each stage with clear text, diagrams, and examples. The method described in this book for training and developing your own small-but-functional model for educational purposes mirrors the approach used in creating large-scale foundational models such as those behind ChatGPT.

PaddleNLP
PaddleNLP is an easy-to-use and high-performance NLP library. It aggregates high-quality pre-trained models in the industry and provides out-of-the-box development experience, covering a model library for multiple NLP scenarios with industry practice examples to meet developers' flexible customization needs.
Tutorial
The Bookworm·Puyu large model training camp aims to promote the implementation of large models in more industries and provide developers with a more efficient platform for learning the development and application of large models. Within two weeks, you will learn the entire process of fine-tuning, deploying, and evaluating large models.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.