
MINI_LLM
This is a repository used by individuals to experiment and reproduce the pre-training process of LLM.
Stars: 413
This project is a personal implementation and reproduction of a small-parameter Chinese LLM. It mainly refers to these two open source projects: https://github.com/charent/Phi2-mini-Chinese and https://github.com/DLLXW/baby-llama2-chinese. It includes the complete process of pre-training, SFT instruction fine-tuning, DPO, and PPO (to be done). I hope to share it with everyone and hope that everyone can work together to improve it!
README:
Created by Lil2J
本项目是我个人关于一个小参数量的中文大模型的一个实践复现。
主要参考这两个开源项目:
1.https://github.com/charent/Phi2-mini-Chinese
2.https://github.com/DLLXW/baby-llama2-chinese
3.https://github.com/charent/ChatLM-mini-Chinese
包含:预训练、SFT指令微调、DPO、PPO(待做)完整流程。
希望分享给大家,也希望大家一起来完善!
- 训练一个参数量1.4b预训练模型,基座模型选的是QWEN,训练的token数量为8b左右
- 构建包含预训练、SFT指令微调、DPO整个完整流程的LLM代码仓库,包含DeepSpeed分布式训练技术
# 1. 在“Baby-llama2-chinese Corpus”的百度网盘中下载维基百科和百度百科的预训练语料和aplca数据。
# 在https://huggingface.co/datasets/Skywork/SkyPile-150B/tree/main 上下载数据
# 在https://huggingface.co/BelleGroup 上下载train_2M_CN,train_1M_CN和train_0.5M_CN
# 因为算力资源有限,我只下载了前20个数据文件
# 将所有数据tokenize之后,token数量大概为8b
# 2. 将下载好的数据放到你想要的目录下
# 3. 切换到dataset_utils目录下运行generate_data.py,运行前修改py文件,将处理数据的函数的注释去掉,才能运行起来
# 4. 运行generate_data.py.py,在./datasets/目录下生成parquet文件
cd dataset_utils
python3 generate_data.py
#5. 修改train.sh 文件 如果是单卡运行的话 把--multi_gpu 去掉,然后--config_file 后面接accelerate_one_gpu.yaml 如果是多卡的话,就把 accelerate_multi_gpu.yaml中 num_processes: 4
#改为自己的卡数
#开启预训练
sh train.sh pre_train.py
# 多机多卡训练
# 使用文件 accelerate_multi_gpus_on_multi_nodes.yaml, 其中:
# 采用了deepspeed standard任务提交模式,num_machines为节点数量,num_processes为全部可用GPUs的数量
# 使用多机多卡训练时需要保证以下几个步骤:
#1. 多节点免密登录,且节点登录用户名一致,同时将节点的访问用户名写入各节点host文件
#2. 多节点环境一致,主要是cuda版本,nccl版本,pytorch版本等,三者之间的版本也有相对应的依赖关系。
#3. 各节点运行命令行,accelerate launch --config_file accelerate_multi_gpus_on_multi_nodes.yaml --machine_rank {rank} --main_process_ip {MasterIP} --main_process_port {MasterPort} pre_train.py
# 其中,rank为用户自定义的机器排序,主节点为0,MasterIP为主节点IP,MasterPort为主节点Port,在提交命令行时,各节点命令行仅需要修改rank。
accelerate launch --config_file accelerate_multi_gpus_on_multi_nodes.yaml --machine_rank {rank} --main_process_ip {MasterIP} --main_process_port {MasterPort} pre_train.py
#6.预训练完之后,修改sft.py中的模型权重加载路径
#开启sft微调
sh train.sh sft.py
#7.修改test.py的权重路径,就能进行测试了
python3 test.py
-
模型底座:模型的底座使用了qwen的模型,选择它的原因是:1.它是一个很成熟的中文大模型开源项目 2.我懒得自己构建tokenizer了,我看到qwen的tokenizer的压缩率挺好的,就直接拿来用了,既然tokenizer都拿了,就也直接用它的模型了
-
预训练语料(Corpus for pre-training ): 这次预训练用了以下几个经典数据集:
Wiki中文百科:wikipedia-cn-20230720-filtered
BaiduBaiKe:百度网盘 提取码: bwvb
天工数据集:https://huggingface.co/datasets/Skywork/SkyPile-150B/tree/main/data
数据预处理采取QWEN的通用做法,在末尾加上一个结束符号<|im_end|>,与下一个文章区分开。
如果文章超过规定的长度,将其截断,截断部分作为下个样本
LLM微调的目的是将预训练模型中的知识引导出来的一种手段,通俗的讲就是教会模型说人话。
-
微调方法:自然语言处理目前存在一个重要的范式:一般领域数据的大规模预训练,对特定任务或领域的适应。因此,为了让预训练模型在特定任务或领域有不错的表现,需要对模型进行微调。
-
SFT微调数据:LLM在垂直领域的适应已经是2023年的主格调,因此各个领域的SFT语料和微调模型层出不穷。目前已经有大佬整理并持续更新这方面的最新进展,大家有需要可以自己访问。
本项目主要针对两类SFT语料进行模型微调,如下:
日常问答SFT数据:
SFT语料 描述 alpaca-zh:alpaca-zh 该数据集是参考Alpaca方法基于GPT4得到的self-instruct数据,约5万条。 bell:bell 源自BelleGroup的一部分SFT数据。包含约300万条由BELLE项目生成的中文指令数据。
因为SFT语料一般较小,我们没必要提前分词,而是在构建Dataloader的时候进行分词构建batch送给模型。所以自行参考sft.py即可!
DPO算法称为直接偏好优化(Direct Preference Optimization),DPO的代码参考了中文对话0.2B小模型 ChatLM-Chinese-0.2B
整个构建分为四步:
- 第一步,针对sft阶段不太合适的指令,构建待优化的指令数据集(也可以直接是上面提到的SFT语料数据集alpaca和bell),数据结构如下:
{
"instruction": "描述原子的结构。",
"input": "",
"output": "原子是物质的基本单位,它由三种基本粒子组成:质子、中子和电子。质子和中子形成原子核,位于原子中心,核外的电子围绕着原子核运动。\n\n原子结构具有层次性。原子核中,质子带正电,中子不带电(中性)。原子核非常小且致密,占据了原子总质量的绝大部分。电子带负电,通常围绕核运动,形成若干层次,称为壳层或电子层。电子数量与质子数量相等,使原子呈电中性。\n\n电子在每个壳层中都呈规律分布,并且不同壳层所能容纳的电子数也不同。在最里面的壳层一般只能容纳2个电子,其次一层最多可容纳8个电子,再往外的壳层可容纳的电子数逐层递增。\n\n原子核主要受到两种相互作用力的影响:强力和电磁力。强力的作用范围非常小,主要限制在原子核内,具有极强的吸引作用,使核子(质子和中子)紧密结合在一起。电磁力的作用范围较大,主要通过核外的电子与原子核相互作用,发挥作用。\n\n这就是原子的基本结构。原子内部结构复杂多样,不同元素的原子核中质子、中子数量不同,核外电子排布分布也不同,形成了丰富多彩的化学世界。"
}
- 第二步,合并输入部分,生成目标数据集chosen,数据结构如下:
{
"prompt": "描述原子的结构。",
"chosen": "原子是物质的基本单位,它由三种基本粒子组成:质子、中子和电子。质子和中子形成原子核,位于原子中心,核外的电子围绕着原子核运动。\n\n原子结构具有层次性。原子核中,质子带正电,中子不带电(中性)。原子核非常小且致密,占据了原子总质量的绝大部分。电子带负电,通常围绕核运动,形成若干层次,称为壳层或电子层。电子数量与质子数量相等,使原子呈电中性。\n\n电子在每个壳层中都呈规律分布,并且不同壳层所能容纳的电子数也不同。在最里面的壳层一般只能容纳2个电子,其次一层最多可容纳8个电子,再往外的壳层可容纳的电子数逐层递增。\n\n原子核主要受到两种相互作用力的影响:强力和电磁力。强力的作用范围非常小,主要限制在原子核内,具有极强的吸引作用,使核子(质子和中子)紧密结合在一起。电磁力的作用范围较大,主要通过核外的电子与原子核相互作用,发挥作用。\n\n这就是原子的基本结构。原子内部结构复杂多样,不同元素的原子核中质子、中子数量不同,核外电子排布分布也不同,形成了丰富多彩的化学世界。"
},
- 第三步,通过第二步的SFT模型,输入prompt,如这里的“描述原子结构。”,得到结果“一个原子由质子、中子和电子组成,它们以特定的方式排列成一个原子核。”,从而构建rejected数据集,数据结构如下:
{
'prompt': '描述原子的结构。',
'reject': '一个原子由质子、中子和电子组成,它们以特定的方式排列成一个原子核。'
}
- 第四步,合并第二步和第三步的输入结果,数据结构如下:
{
"prompt": "描述原子的结构。",
"chosen": "原子是物质的基本单位,它由三种基本粒子组成:质子、中子和电子。质子和中子形成原子核,位于原子中心,核外的电子围绕着原子核运动。\n\n原子结构具有层次性。原子核中,质子带正电,中子不带电(中性)。原子核非常小且致密,占据了原子总质量的绝大部分。电子带负电,通常围绕核运动,形成若干层次,称为壳层或电子层。电子数量与质子数量相等,使原子呈电中性。\n\n电子在每个壳层中都呈规律分布,并且不同壳层所能容纳的电子数也不同。在最里面的壳层一般只能容纳2个电子,其次一层最多可容纳8个电子,再往外的壳层可容纳的电子数逐层递增。\n\n原子核主要受到两种相互作用力的影响:强力和电磁力。强力的作用范围非常小,主要限制在原子核内,具有极强的吸引作用,使核子(质子和中子)紧密结合在一起。电磁力的作用范围较大,主要通过核外的电子与原子核相互作用,发挥作用。\n\n这就是原子的基本结构。原子内部结构复杂多样,不同元素的原子核中质子、中子数量不同,核外电子排布分布也不同,形成了丰富多彩的化学世界。",
"reject": "一个原子由质子、中子和电子组成,它们以特定的方式排列成一个原子核。"
},
- 第一步,使用dpo_train文件,修改其中的DpoConfig类,设置好对应的SFT路径和训练数据集路径即可
class DpoConfig:
max_seq_len: int = 1024 + 8 # 8 for eos token
sft_model_file: str = '/MINI_LLM/model_save/checkpoint_sftmodel' # SFT后的模型路径
tokenizer_dir: str = '/MINI_LLM/model_save/checkpoint_sftmodel' # tokenizer一般和model权重放在同一个文件夹
dpo_train_file: str = r'/MINILLM\MINI_LLM/datasets/my_dpo_train.json' # dpo的训练集
dpo_eval_file: str = r'/MINILLM\MINI_LLM/datasets/my_dpo_eval.json' # dpo的测试集
adapter_file: str = '/MINILLM\MINI_LLM//dpo/adapter_model.safetensors'
log_dir: str = '/MINILLM\MINI_LLM/logs'
...
output_dir: str = '/MINILLM\MINI_LLM//dpo' # dpo模型输出路径
...- 第二步,执行dpo_train
可以通过SwanLab方便的查看训练日志变化,使用如下命令开启本地看板
swanlab watch因需要配合sft模型才能看差别,因为其本质是让sft的模型更好的对齐你的目标数据而已,min(Π,Π*);可以在下面的链接中下载对应dpo数据,和待优化的sft模型,链接如下: 链接:https://pan.baidu.com/s/1GYeR6qrUhjsmpgh8-ABDpQ 提取码:dba9
如果希望将训练过程保存在云端上查看,可以在callback调用处将swanlab_callback = SwanLabCallback(...,mode="local")的mode变量设置为"cloud"即可。
权重下载
预训练权重:https://huggingface.co/Lil2J/mini_llm/tree/main
sft模型权重:https://huggingface.co/Lil2J/mini_llm_sft/tree/main
dpo模型权重:https://huggingface.co/wtxfrancise/mini_llm_dpo/tree/main
- 预训练模型
我首先先跑了Wiki中文百科 + BaiduBaiKe
 预训练语料: Wiki中文百科 + BaiduBaiKe
预训练语料: Wiki中文百科 + BaiduBaiKe
然后再跑天工的数据
 预训练语料: 天工数据集前20个文件
预训练语料: 天工数据集前20个文件
- sft模型
 微调语料: aplca数据+bell:train_2M_CN,train_1M_CN和train_0.5M_CN
微调语料: aplca数据+bell:train_2M_CN,train_1M_CN和train_0.5M_CN
- sft模型效果
#SFT微调模型的推理:test.py。
python3 test.py








-
dpo模型
 dpo语料: alpaca数据+bell:train_1M_CN
dpo语料: alpaca数据+bell:train_1M_CN -
dpo模型效果




有什么问题和想一起搞大模型的可以加wx:ForeverM1LAn 进行交流
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MINI_LLM
Similar Open Source Tools
MINI_LLM
This project is a personal implementation and reproduction of a small-parameter Chinese LLM. It mainly refers to these two open source projects: https://github.com/charent/Phi2-mini-Chinese and https://github.com/DLLXW/baby-llama2-chinese. It includes the complete process of pre-training, SFT instruction fine-tuning, DPO, and PPO (to be done). I hope to share it with everyone and hope that everyone can work together to improve it!
meet-libai
The 'meet-libai' project aims to promote and popularize the cultural heritage of the Chinese poet Li Bai by constructing a knowledge graph of Li Bai and training a professional AI intelligent body using large models. The project includes features such as data preprocessing, knowledge graph construction, question-answering system development, and visualization exploration of the graph structure. It also provides code implementations for large models and RAG retrieval enhancement.
Streamer-Sales
Streamer-Sales is a large model for live streamers that can explain products based on their characteristics and inspire users to make purchases. It is designed to enhance sales efficiency and user experience, whether for online live sales or offline store promotions. The model can deeply understand product features and create tailored explanations in vivid and precise language, sparking user's desire to purchase. It aims to revolutionize the shopping experience by providing detailed and unique product descriptions to engage users effectively.
YesImBot
YesImBot, also known as Athena, is a Koishi plugin designed to allow large AI models to participate in group chat discussions. It offers easy customization of the bot's name, personality, emotions, and other messages. The plugin supports load balancing multiple API interfaces for large models, provides immersive context awareness, blocks potentially harmful messages, and automatically fetches high-quality prompts. Users can adjust various settings for the bot and customize system prompt words. The ultimate goal is to seamlessly integrate the bot into group chats without detection, with ongoing improvements and features like message recognition, emoji sending, multimodal image support, and more.
GalTransl
GalTransl is an automated translation tool for Galgames that combines minor innovations in several basic functions with deep utilization of GPT prompt engineering. It is used to create embedded translation patches. The core of GalTransl is a set of automated translation scripts that solve most known issues when using ChatGPT for Galgame translation and improve overall translation quality. It also integrates with other projects to streamline the patch creation process, reducing the learning curve to some extent. Interested users can more easily build machine-translated patches of a certain quality through this project and may try to efficiently build higher-quality localization patches based on this framework.
EduChat
EduChat is a large-scale language model-based chatbot system designed for intelligent education by the EduNLP team at East China Normal University. The project focuses on developing a dialogue-based language model for the education vertical domain, integrating diverse education vertical domain data, and providing functions such as automatic question generation, homework correction, emotional support, course guidance, and college entrance examination consultation. The tool aims to serve teachers, students, and parents to achieve personalized, fair, and warm intelligent education.
GitHubSentinel
GitHub Sentinel is an intelligent information retrieval and high-value content mining AI Agent designed for the era of large models (LLMs). It is aimed at users who need frequent and large-scale information retrieval, especially open source enthusiasts, individual developers, and investors. The main features include subscription management, update retrieval, notification system, report generation, multi-model support, scheduled tasks, graphical interface, containerization, continuous integration, and the ability to track and analyze the latest dynamics of GitHub open source projects and expand to other information channels like Hacker News for comprehensive information mining and analysis capabilities.
ZcChat
ZcChat is an AI desktop pet suitable for Galgame characters, featuring long-term memory, expressive actions, control over the computer, and voice functions. It utilizes Letta for AI long-term memory, Galgame-style character illustrations for more actions and expressions, and voice interaction with support for various voice synthesis tools like Vits. Users can configure characters, install Letta, set up voice synthesis and input, and control the pet to interact with the computer. The tool enhances visual and auditory experiences for users interested in AI desktop pets.
Senparc.AI
Senparc.AI is an AI extension package for the Senparc ecosystem, focusing on LLM (Large Language Models) interaction. It provides modules for standard interfaces and basic functionalities, as well as interfaces using SemanticKernel for plug-and-play capabilities. The package also includes a library for supporting the 'PromptRange' ecosystem, compatible with various systems and frameworks. Users can configure different AI platforms and models, define AI interface parameters, and run AI functions easily. The package offers examples and commands for dialogue, embedding, and DallE drawing operations.
metaso-free-api
Metaso AI Free service supports high-speed streaming output, secret tower AI super network search (full network or academic as well as concise, in-depth, research three modes), zero-configuration deployment, multi-token support. Fully compatible with ChatGPT interface. It also has seven other free APIs available for use. The tool provides various deployment options such as Docker, Docker-compose, Render, Vercel, and native deployment. Users can access the tool for chat completions and token live checks. Note: Reverse API is unstable, it is recommended to use the official Metaso AI website to avoid the risk of banning. This project is for research and learning purposes only, not for commercial use.
Tianji
Tianji is a free, non-commercial artificial intelligence system developed by SocialAI for tasks involving worldly wisdom, such as etiquette, hospitality, gifting, wishes, communication, awkwardness resolution, and conflict handling. It includes four main technical routes: pure prompt, Agent architecture, knowledge base, and model training. Users can find corresponding source code for these routes in the tianji directory to replicate their own vertical domain AI applications. The project aims to accelerate the penetration of AI into various fields and enhance AI's core competencies.
ophel
Ophel Atlas is a tool that transforms AI conversations into readable, navigable, and reusable documents. It organizes conversations into a structured workflow, allowing users to easily navigate and reuse valuable insights. It offers features such as intelligent outlining, conversation management, prompt libraries, theme customization, interface optimization, reading experience enhancements, efficiency tools, and privacy-focused data storage. Ophel Atlas is designed for various use cases including learning and research, daily work tasks, development and technical writing, content creation, and frequent AI users seeking structured and reusable capabilities.
CareGPT
CareGPT is a medical large language model (LLM) that explores medical data, training, and deployment related research work. It integrates resources, open-source models, rich data, and efficient deployment methods. It supports various medical tasks, including patient diagnosis, medical dialogue, and medical knowledge integration. The model has been fine-tuned on diverse medical datasets to enhance its performance in the healthcare domain.
langchain4j-aideepin-web
The langchain4j-aideepin-web repository is the frontend project of langchain4j-aideepin, an open-source, offline deployable retrieval enhancement generation (RAG) project based on large language models such as ChatGPT and application frameworks such as Langchain4j. It includes features like registration & login, multi-sessions (multi-roles), image generation (text-to-image, image editing, image-to-image), suggestions, quota control, knowledge base (RAG) based on large models, model switching, and search engine switching.
new-api
New API is an open-source project based on One API with additional features and improvements. It offers a new UI interface, supports Midjourney-Proxy(Plus) interface, online recharge functionality, model-based charging, channel weight randomization, data dashboard, token-controlled models, Telegram authorization login, Suno API support, Rerank model integration, and various third-party models. Users can customize models, retry channels, and configure caching settings. The deployment can be done using Docker with SQLite or MySQL databases. The project provides documentation for Midjourney and Suno interfaces, and it is suitable for AI enthusiasts and developers looking to enhance AI capabilities.

For similar tasks
LLM-Finetune-Guide
This project provides a comprehensive guide to fine-tuning large language models (LLMs) with efficient methods like LoRA and P-tuning V2. It includes detailed instructions, code examples, and performance benchmarks for various LLMs and fine-tuning techniques. The guide also covers data preparation, evaluation, prediction, and running inference on CPU environments. By leveraging this guide, users can effectively fine-tune LLMs for specific tasks and applications.

LLM-Blender
LLM-Blender is a framework for ensembling large language models (LLMs) to achieve superior performance. It consists of two modules: PairRanker and GenFuser. PairRanker uses pairwise comparisons to distinguish between candidate outputs, while GenFuser merges the top-ranked candidates to create an improved output. LLM-Blender has been shown to significantly surpass the best LLMs and baseline ensembling methods across various metrics on the MixInstruct benchmark dataset.
MINI_LLM
This project is a personal implementation and reproduction of a small-parameter Chinese LLM. It mainly refers to these two open source projects: https://github.com/charent/Phi2-mini-Chinese and https://github.com/DLLXW/baby-llama2-chinese. It includes the complete process of pre-training, SFT instruction fine-tuning, DPO, and PPO (to be done). I hope to share it with everyone and hope that everyone can work together to improve it!
LLM-Tuning
LLM-Tuning is a collection of tools and resources for fine-tuning large language models (LLMs). It includes a library of pre-trained LoRA models, a set of tutorials and examples, and a community forum for discussion and support. LLM-Tuning makes it easy to fine-tune LLMs for a variety of tasks, including text classification, question answering, and dialogue generation. With LLM-Tuning, you can quickly and easily improve the performance of your LLMs on downstream tasks.

LLM-FineTuning-Large-Language-Models
This repository contains projects and notes on common practical techniques for fine-tuning Large Language Models (LLMs). It includes fine-tuning LLM notebooks, Colab links, LLM techniques and utils, and other smaller language models. The repository also provides links to YouTube videos explaining the concepts and techniques discussed in the notebooks.
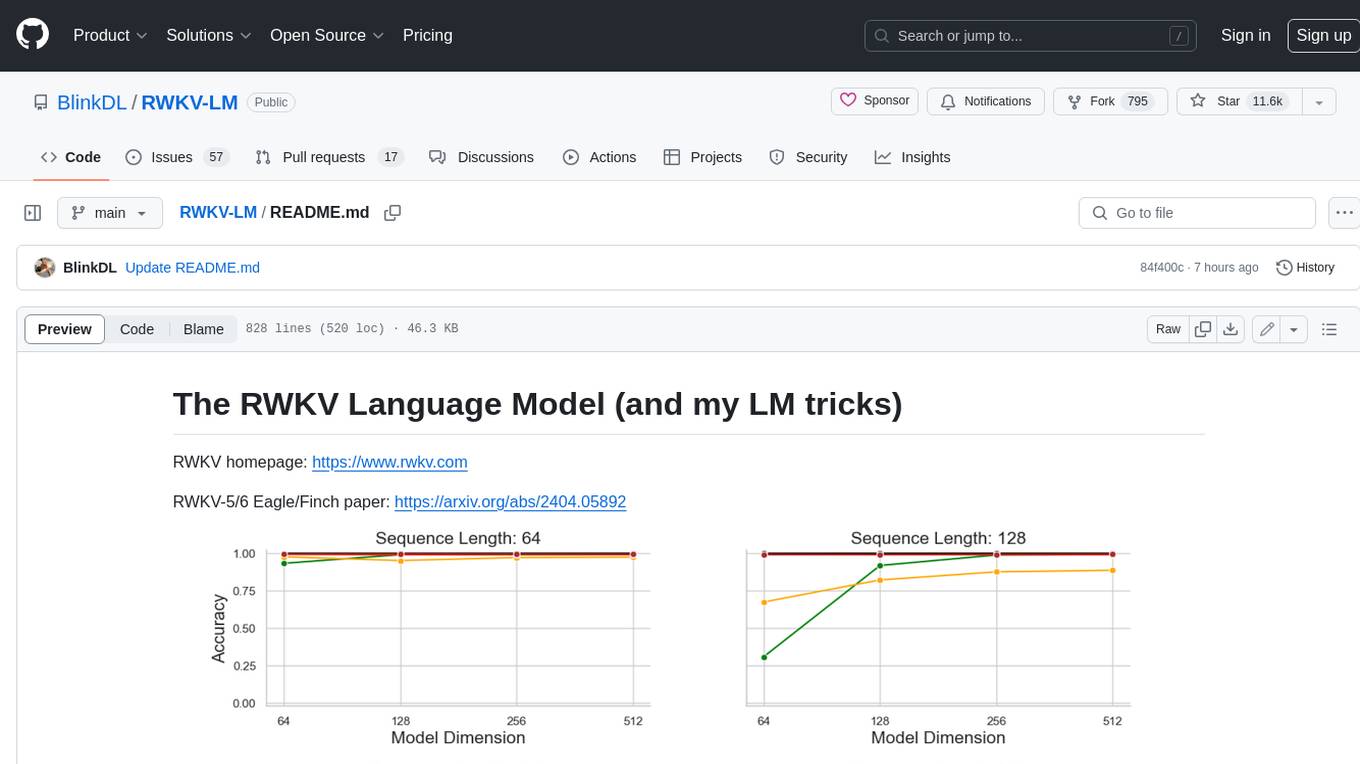
RWKV-LM
RWKV is an RNN with Transformer-level LLM performance, which can also be directly trained like a GPT transformer (parallelizable). And it's 100% attention-free. You only need the hidden state at position t to compute the state at position t+1. You can use the "GPT" mode to quickly compute the hidden state for the "RNN" mode. So it's combining the best of RNN and transformer - **great performance, fast inference, saves VRAM, fast training, "infinite" ctx_len, and free sentence embedding** (using the final hidden state).

awesome-transformer-nlp
This repository contains a hand-curated list of great machine (deep) learning resources for Natural Language Processing (NLP) with a focus on Generative Pre-trained Transformer (GPT), Bidirectional Encoder Representations from Transformers (BERT), attention mechanism, Transformer architectures/networks, Chatbot, and transfer learning in NLP.
self-llm
This project is a Chinese tutorial for domestic beginners based on the AutoDL platform, providing full-process guidance for various open-source large models, including environment configuration, local deployment, and efficient fine-tuning. It simplifies the deployment, use, and application process of open-source large models, enabling more ordinary students and researchers to better use open-source large models and helping open and free large models integrate into the lives of ordinary learners faster.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.