
LLM-Tuning
Tuning LLMs with no tears💦; Sample Design Engineering (SDE) for more efficient downstream-tuning.
Stars: 897
LLM-Tuning is a collection of tools and resources for fine-tuning large language models (LLMs). It includes a library of pre-trained LoRA models, a set of tutorials and examples, and a community forum for discussion and support. LLM-Tuning makes it easy to fine-tune LLMs for a variety of tasks, including text classification, question answering, and dialogue generation. With LLM-Tuning, you can quickly and easily improve the performance of your LLMs on downstream tasks.
README:
We introduce the idea of Sample Design Engineering (SDE) for LLMs' Downstream Fine-Tuning. 我们提出了针对大模型下游任务微调的「样本设计工程」。
- Paper: Sample Design Engineering: An Empirical Study of What Makes Good Downstream Fine-Tuning Samples for LLMs
- Code at the SDE directory.
- Abs: We introduce SDE as an effective method to enhance the downstream-tuning performances of LLMs. Through comprehensive ID and OOD experiments involving six LLMs, we demonstrate the effects of various sample design strategies, uncovering some interesting patterns that are consistent across different LLMs. Building on these findings, we develop the ES-SDE approach, which integrates the most effective options. Our experiments on three new tasks with two additional LLMs consistently show ES-SDE's superiority over baseline methods. Further analysis of the relationship between PE and SDE suggests that effective prompt designs do not necessarily translate to successful sample designs. This observation opens up avenues for more detailed investigations into the mechanisms of SDE in future research.
- 简介:提示工程(Prompt Engineering)已经成为提升大模型的零样本、少样本推理能力的基本操作。然而,在大模型实际落地解决下游业务问题的时候,我们往往还需要一些针对性的样本对模型进行微调训练。我们在大模型实际落地研发中发现:虽然大模型已经足够强大,但是微调样本的不同设计,依然会显著影响大模型微调后的效果。因此,如何设计更好的微调样本,成为了一个新的问题。对此,本文首次提出了样本设计工程(Sample Design Engineering, SDE)的概念,系统性地探究了影响大模型下游任务微调的多种设计选项,发现了诸多有趣且引人深思的结论,并提出了一种在多个复杂下游任务上均稳定优异设计方案。本研究表明,细致地考虑大模型微调样本的设计,可以使用更少的样本训练出在下游任务上表现更好的模型。
💻 可复现的小项目:
- baichuan-RLHF:基于 LoRA 的 RLHF 教程,让 baichaun 活泼如网友!(New!🔥)
- ChatBaichuan:基于 HC3 数据集让 百川大模型(baichuan-7B)有对话能力!
- 【娱乐向】RulaiGPT:如来~诶,它真来了吗?如~来~(拍桌!)
💬 相关讨论区:
🤖 目前支持:
- Meta LLaMA2 的 LoRA 微调
- 通义千问大模型 Qwen1.5 的 LoRA 微调
- 中文羊驼大模型 Chinese-LLaMA-Alpaca 的 LoRA 微调
- 上海 AILab 书生大模型 InternLM-7B 的 LoRA 微调
- 百川智能 Baichaun-7B, Baichuan2-7B 的 LoRA 微调和 RLHF 全流程
- 清华 ChatGLM2-6B 的 LoRA 微调
- 清华 ChatGLM-6B 的 LoRA 微调
🎯 两行代码开启 LoRA 训练:
- 数据集分词预处理:
sh tokenize.sh,对比不同的 LLM,需在 tokenize.sh 文件里切换 model_checkpoint 参数 - 开启 LoRA 微调:
sh train.sh,对于不同的 LLM,需切换不同的 python 文件来执行:- ChatGLM-6B 应使用
chatglm_lora_tuning.py - ChatGLM2-6B 应使用
chatglm2_lora_tuning.py - baichuan-7B 应使用
baichuan_lora_tuning.py - baichuan2-7B 应使用
baichuan2_lora_tuning.py - internlm-chat/base-7b 应使用
intermlm_lora_tuning.py - chinese-llama2/alpaca2-7b 应使用
chinese_llama2_alpaca2_lora_tuning.py
- ChatGLM-6B 应使用
🎯 手把手的 RLHF 教程:见 LoRA-based-RLHF
环境准备:
pip install transformers datasets accelerate sentencepiece tensorboard peft
目前测试的环境为:
- Python 3.9.16
- torch, Version: 2.0.1
- transformers, Version: 4.29.1
- datasets, Version: 2.12.0
- accelerate, Version: 0.19.0
- peft, Version: 0.3.0
- sentencepiece, Version: 0.1.99
- tensorboard, Version: 2.13.0
下面的教程以及代码使用 ChatGLM-6B 作为例子,如果更换其他模型,可能需要略微修改具体文件代码。
原始文件的准备
指令微调数据一般有输入和输出两部分,输入是特定的content加上instruction,这里我们将二者直接拼在一起,不单独区分;输出则是希望模型的回答。
我们统一使用json的格式在整理数据,可以自定义输出输出的字段名,例如下面的例子中我使用的是q和a代表模型的输入和输出:
{"q": "请计算:39 * 0 = 什么?", "a": "这是简单的乘法运算,39乘以0得到的是0"}
{"q": "题目:51/186的答案是什么?", "a": "这是简单的除法运算,51除以186大概为0.274"}
{"q": "鹿妈妈买了24个苹果,她想平均分给她的3只小鹿吃,每只小鹿可以分到几个苹果?", "a": "鹿妈妈买了24个苹果,平均分给3只小鹿吃,那么每只小鹿可以分到的苹果数就是总苹果数除以小鹿的只数。\n24÷3=8\n每只小鹿可以分到8个苹果。所以,答案是每只小鹿可以分到8个苹果。"}
...整理好数据后,保存为.json或者.jsonl文件,然后放入目录中的data/文件夹中。
对数据集进行分词
为了避免每次训练的时候都要重新对数据集分词,我们先分好词形成特征后保存成可直接用于训练的数据集。
例如,
- 我们的原始指令微调文件为:
data/文件夹下的simple_math_4op.json文件 - 输入字段为
q,输出字段为a - 希望经过 tokenize 之后保存到
data/tokenized_data/下名为simple_math_4op的文件夹中 - 设定文本最大程度为 2000
则我们可以直接使用下面这段命令(即tokenize.sh文件)进行处理:
CUDA_VISIBLE_DEVICES=0,1 python tokenize_dataset_rows.py \
--model_checkpoint THUDM/chatglm-6b \
--input_file simple_math_4op.json \
--prompt_key q \
--target_key a \
--save_name simple_math_4op \
--max_seq_length 2000 \
--skip_overlength False处理完毕之后,我们会在 data/tokenized_data/ 下发现名为 simple_math_4op 的文件夹,这就是下一步中我们可以直接用于训练的数据。
得到 tokenize 之后的数据集,就可以直接运行 chatglm_lora_tuning.py 来训练 LoRA 模型了,具体可设置的主要参数包括:
-
tokenized_dataset, 分词后的数据集,即在 data/tokenized_data/ 地址下的文件夹名称 -
lora_rank, 设置 LoRA 的秩,推荐为4或8,显存够的话使用8 -
per_device_train_batch_size, 每块 GPU 上的 batch size -
gradient_accumulation_steps, 梯度累加,可以在不提升显存占用的情况下增大 batch size -
max_steps, 训练步数 -
save_steps, 多少步保存一次 -
save_total_limit, 保存多少个checkpoint -
logging_steps, 多少步打印一次训练情况(loss, lr, etc.) -
output_dir, 模型文件保存地址
例如我们的数据集为 simple_math_4op,希望保存到 weights/simple_math_4op ,则执行下面命令(即train.sh文件):
CUDA_VISIBLE_DEVICES=2,3 python chatglm_lora_tuning.py \
--tokenized_dataset simple_math_4op \
--lora_rank 8 \
--per_device_train_batch_size 10 \
--gradient_accumulation_steps 1 \
--max_steps 100000 \
--save_steps 200 \
--save_total_limit 2 \
--learning_rate 1e-4 \
--fp16 \
--remove_unused_columns false \
--logging_steps 50 \
--output_dir weights/simple_math_4op训练完之后,可以在 output_dir 中找到 LoRA 的相关模型权重,主要是adapter_model.bin和adapter_config.json两个文件。
如何查看 tensorboard:
- 在 output_dir 中找到 runs 文件夹,复制其中日期最大的文件夹的地址,假设为
your_log_path - 执行
tensorboard --logdir your_log_path命令,就会在 http://localhost:6006/ 上开启tensorboard - 如果是在服务器上开启,则还需要做端口映射到本地。推荐使用 VSCode 在服务器上写代码,可以自动帮你进行端口映射。
- 如果要自己手动进行端口映射,具体方式是在使用 ssh 登录时,后面加上
-L 6006:127.0.0.1:6006参数,将服务器端的6006端口映射到本地的6006端口。
我们可以把上面的 output_dir 打包带走,假设文件夹为 weights/simple_math_4op, 其中(至少)包含 adapter_model.bin 和 adapter_config.json 两个文件,则我们可以用下面的方式直接加载,并推理
from peft import PeftModel
from transformers import AutoTokenizer, AutoModel
import torch
device = torch.device(1)
# 加载原始 LLM
model_path = "THUDM/chatglm-6b"
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().to(device)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model.chat(tokenizer, "你好", history=[])
# 给原始 LLM 安装上你的 LoRA tool
model = PeftModel.from_pretrained(model, "weights/simple_math_4op").half()
model.chat(tokenizer, "你好", history=[])理论上,可以通过多次执行 model = PeftModel.from_pretrained(model, "weights/simple_math_4op").half() 的方式,加载多个 LoRA 模型,从而混合不同Tool的能力,但实际测试的时候,由于暂时还不支持设置不同 LoRA weights的权重,往往效果不太好,存在覆盖或者遗忘的情况。
- 首先最感谢的是 🤗Huggingface 团队开源的 peft 工具包,懂的都懂!
- ChatGLM 的 LoRA 微调代码主要基于 ChatGLM-Tuning 项目中的 LoRA 微调部分修改而来;
- baichuan-7B 微调部分,参考了 LLaMA-Efficient-Tuning 项目中的解决方案;
对这些优秀开源项目表示感谢!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM-Tuning
Similar Open Source Tools
LLM-Tuning
LLM-Tuning is a collection of tools and resources for fine-tuning large language models (LLMs). It includes a library of pre-trained LoRA models, a set of tutorials and examples, and a community forum for discussion and support. LLM-Tuning makes it easy to fine-tune LLMs for a variety of tasks, including text classification, question answering, and dialogue generation. With LLM-Tuning, you can quickly and easily improve the performance of your LLMs on downstream tasks.
LLMTSCS
LLMLight is a novel framework that employs Large Language Models (LLMs) as decision-making agents for Traffic Signal Control (TSC). The framework leverages the advanced generalization capabilities of LLMs to engage in a reasoning and decision-making process akin to human intuition for effective traffic control. LLMLight has been demonstrated to be remarkably effective, generalizable, and interpretable against various transportation-based and RL-based baselines on nine real-world and synthetic datasets.

evalplus
EvalPlus is a rigorous evaluation framework for LLM4Code, providing HumanEval+ and MBPP+ tests to evaluate large language models on code generation tasks. It offers precise evaluation and ranking, coding rigorousness analysis, and pre-generated code samples. Users can use EvalPlus to generate code solutions, post-process code, and evaluate code quality. The tool includes tools for code generation and test input generation using various backends.
jido_ai
Jido.AI is an AI integration layer for the Jido ecosystem, providing a toolkit for building intelligent agents with LLMs. It implements reasoning strategies for tool use, multi-step reasoning, and complex planning to enhance results from language models.

candle-vllm
Candle-vllm is an efficient and easy-to-use platform designed for inference and serving local LLMs, featuring an OpenAI compatible API server. It offers a highly extensible trait-based system for rapid implementation of new module pipelines, streaming support in generation, efficient management of key-value cache with PagedAttention, and continuous batching. The tool supports chat serving for various models and provides a seamless experience for users to interact with LLMs through different interfaces.

MR-Models
MR-Models is a repository dedicated to the research and development of language models tailored for Traditional Chinese users. It offers advanced multi-modal language models like Breeze 2 and Model 7, designed to enhance Traditional Chinese language representation. The models incorporate vision-aware capabilities, function-calling features, and are available for academic or industrial use under licensing terms.

VLM-R1
VLM-R1 is a stable and generalizable R1-style Large Vision-Language Model proposed for Referring Expression Comprehension (REC) task. It compares R1 and SFT approaches, showing R1 model's steady improvement on out-of-domain test data. The project includes setup instructions, training steps for GRPO and SFT models, support for user data loading, and evaluation process. Acknowledgements to various open-source projects and resources are mentioned. The project aims to provide a reliable and versatile solution for vision-language tasks.

AnglE
AnglE is a library for training state-of-the-art BERT/LLM-based sentence embeddings with just a few lines of code. It also serves as a general sentence embedding inference framework, allowing for inferring a variety of transformer-based sentence embeddings. The library supports various loss functions such as AnglE loss, Contrastive loss, CoSENT loss, and Espresso loss. It provides backbones like BERT-based models, LLM-based models, and Bi-directional LLM-based models for training on single or multi-GPU setups. AnglE has achieved significant performance on various benchmarks and offers official pretrained models for both BERT-based and LLM-based models.

auto-round
AutoRound is an advanced weight-only quantization algorithm for low-bits LLM inference. It competes impressively against recent methods without introducing any additional inference overhead. The method adopts sign gradient descent to fine-tune rounding values and minmax values of weights in just 200 steps, often significantly outperforming SignRound with the cost of more tuning time for quantization. AutoRound is tailored for a wide range of models and consistently delivers noticeable improvements.
dspy.rb
DSPy.rb is a Ruby framework for building reliable LLM applications using composable, type-safe modules. It enables developers to define typed signatures and compose them into pipelines, offering a more structured approach compared to traditional prompting. The framework embraces Ruby conventions and adds innovations like CodeAct agents and enhanced production instrumentation, resulting in scalable LLM applications that are robust and efficient. DSPy.rb is actively developed, with a focus on stability and real-world feedback through the 0.x series before reaching a stable v1.0 API.

MHA2MLA
This repository contains the code for the paper 'Towards Economical Inference: Enabling DeepSeek's Multi-Head Latent Attention in Any Transformer-based LLMs'. It provides tools for fine-tuning and evaluating Llama models, converting models between different frameworks, processing datasets, and performing specific model training tasks like Partial-RoPE Fine-Tuning and Multiple-Head Latent Attention Fine-Tuning. The repository also includes commands for model evaluation using Lighteval and LongBench, along with necessary environment setup instructions.
unity-mcp
MCP for Unity is a tool that acts as a bridge, enabling AI assistants to interact with the Unity Editor via a local MCP Client. Users can instruct their LLM to manage assets, scenes, scripts, and automate tasks within Unity. The tool offers natural language control, powerful tools for asset management, scene manipulation, and automation of workflows. It is extensible and designed to work with various MCP Clients, providing a range of functions for precise text edits, script management, GameObject operations, and more.

FDAbench
FDABench is a benchmark tool designed for evaluating data agents' reasoning ability over heterogeneous data in analytical scenarios. It offers 2,007 tasks across various data sources, domains, difficulty levels, and task types. The tool provides ready-to-use data agent implementations, a DAG-based evaluation system, and a framework for agent-expert collaboration in dataset generation. Key features include data agent implementations, comprehensive evaluation metrics, multi-database support, different task types, extensible framework for custom agent integration, and cost tracking. Users can set up the environment using Python 3.10+ on Linux, macOS, or Windows. FDABench can be installed with a one-command setup or manually. The tool supports API configuration for LLM access and offers quick start guides for database download, dataset loading, and running examples. It also includes features like dataset generation using the PUDDING framework, custom agent integration, evaluation metrics like accuracy and rubric score, and a directory structure for easy navigation.
rust-genai
genai is a multi-AI providers library for Rust that aims to provide a common and ergonomic single API to various generative AI providers such as OpenAI, Anthropic, Cohere, Ollama, and Gemini. It focuses on standardizing chat completion APIs across major AI services, prioritizing ergonomics and commonality. The library initially focuses on text chat APIs and plans to expand to support images, function calling, and more in the future versions. Version 0.1.x will have breaking changes in patches, while version 0.2.x will follow semver more strictly. genai does not provide a full representation of a given AI provider but aims to simplify the differences at a lower layer for ease of use.

cellseg_models.pytorch
cellseg-models.pytorch is a Python library built upon PyTorch for 2D cell/nuclei instance segmentation models. It provides multi-task encoder-decoder architectures and post-processing methods for segmenting cell/nuclei instances. The library offers high-level API to define segmentation models, open-source datasets for training, flexibility to modify model components, sliding window inference, multi-GPU inference, benchmarking utilities, regularization techniques, and example notebooks for training and finetuning models with different backbones.
npcpy
npcpy is a core library of the NPC Toolkit that enhances natural language processing pipelines and agent tooling. It provides a flexible framework for building applications and conducting research with LLMs. The tool supports various functionalities such as getting responses for agents, setting up agent teams, orchestrating jinx workflows, obtaining LLM responses, generating images, videos, audio, and more. It also includes a Flask server for deploying NPC teams, supports LiteLLM integration, and simplifies the development of NLP-based applications. The tool is versatile, supporting multiple models and providers, and offers a graphical user interface through NPC Studio and a command-line interface via NPC Shell.
For similar tasks
LLM-Finetune-Guide
This project provides a comprehensive guide to fine-tuning large language models (LLMs) with efficient methods like LoRA and P-tuning V2. It includes detailed instructions, code examples, and performance benchmarks for various LLMs and fine-tuning techniques. The guide also covers data preparation, evaluation, prediction, and running inference on CPU environments. By leveraging this guide, users can effectively fine-tune LLMs for specific tasks and applications.

LLM-Blender
LLM-Blender is a framework for ensembling large language models (LLMs) to achieve superior performance. It consists of two modules: PairRanker and GenFuser. PairRanker uses pairwise comparisons to distinguish between candidate outputs, while GenFuser merges the top-ranked candidates to create an improved output. LLM-Blender has been shown to significantly surpass the best LLMs and baseline ensembling methods across various metrics on the MixInstruct benchmark dataset.
MINI_LLM
This project is a personal implementation and reproduction of a small-parameter Chinese LLM. It mainly refers to these two open source projects: https://github.com/charent/Phi2-mini-Chinese and https://github.com/DLLXW/baby-llama2-chinese. It includes the complete process of pre-training, SFT instruction fine-tuning, DPO, and PPO (to be done). I hope to share it with everyone and hope that everyone can work together to improve it!
LLM-Tuning
LLM-Tuning is a collection of tools and resources for fine-tuning large language models (LLMs). It includes a library of pre-trained LoRA models, a set of tutorials and examples, and a community forum for discussion and support. LLM-Tuning makes it easy to fine-tune LLMs for a variety of tasks, including text classification, question answering, and dialogue generation. With LLM-Tuning, you can quickly and easily improve the performance of your LLMs on downstream tasks.

LLM-FineTuning-Large-Language-Models
This repository contains projects and notes on common practical techniques for fine-tuning Large Language Models (LLMs). It includes fine-tuning LLM notebooks, Colab links, LLM techniques and utils, and other smaller language models. The repository also provides links to YouTube videos explaining the concepts and techniques discussed in the notebooks.
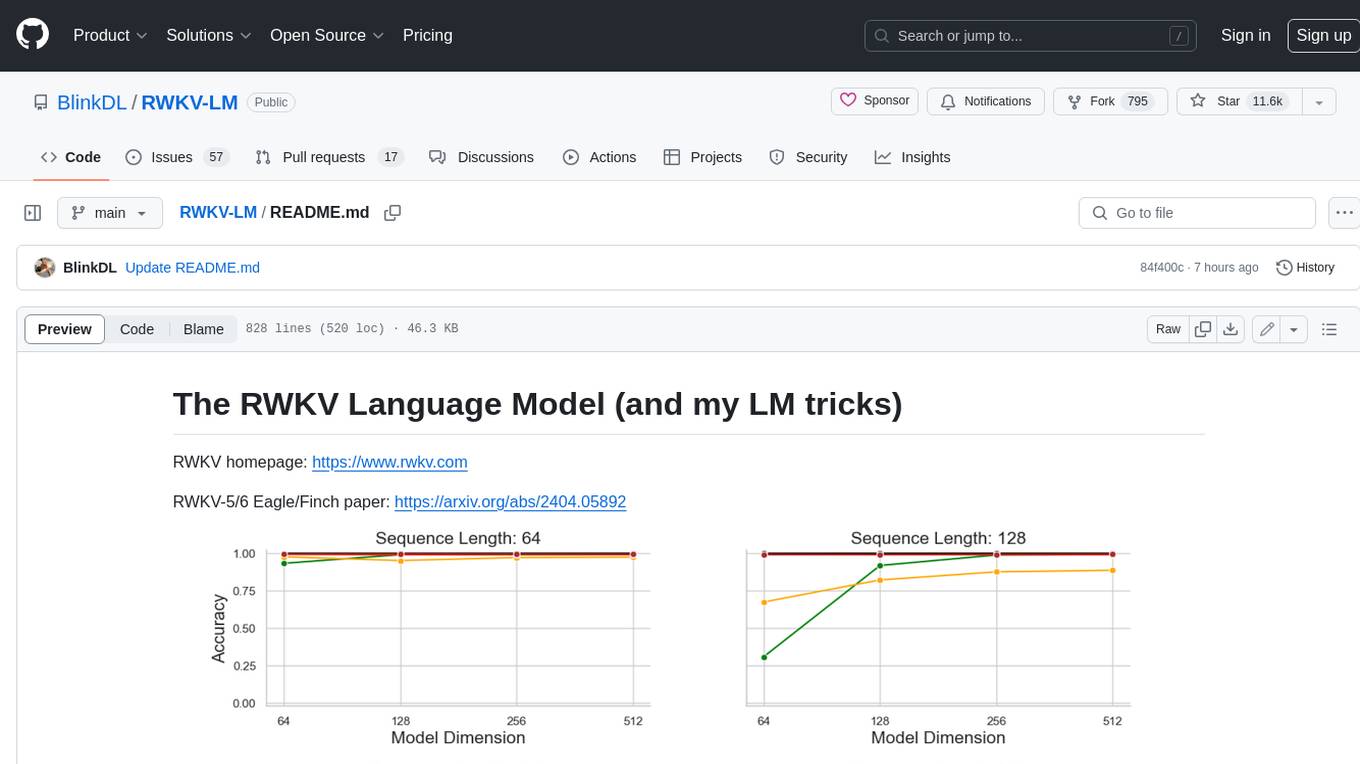
RWKV-LM
RWKV is an RNN with Transformer-level LLM performance, which can also be directly trained like a GPT transformer (parallelizable). And it's 100% attention-free. You only need the hidden state at position t to compute the state at position t+1. You can use the "GPT" mode to quickly compute the hidden state for the "RNN" mode. So it's combining the best of RNN and transformer - **great performance, fast inference, saves VRAM, fast training, "infinite" ctx_len, and free sentence embedding** (using the final hidden state).

awesome-transformer-nlp
This repository contains a hand-curated list of great machine (deep) learning resources for Natural Language Processing (NLP) with a focus on Generative Pre-trained Transformer (GPT), Bidirectional Encoder Representations from Transformers (BERT), attention mechanism, Transformer architectures/networks, Chatbot, and transfer learning in NLP.
self-llm
This project is a Chinese tutorial for domestic beginners based on the AutoDL platform, providing full-process guidance for various open-source large models, including environment configuration, local deployment, and efficient fine-tuning. It simplifies the deployment, use, and application process of open-source large models, enabling more ordinary students and researchers to better use open-source large models and helping open and free large models integrate into the lives of ordinary learners faster.
For similar jobs
LLM-FineTuning-Large-Language-Models
This repository contains projects and notes on common practical techniques for fine-tuning Large Language Models (LLMs). It includes fine-tuning LLM notebooks, Colab links, LLM techniques and utils, and other smaller language models. The repository also provides links to YouTube videos explaining the concepts and techniques discussed in the notebooks.

lloco
LLoCO is a technique that learns documents offline through context compression and in-domain parameter-efficient finetuning using LoRA, which enables LLMs to handle long context efficiently.

camel
CAMEL is an open-source library designed for the study of autonomous and communicative agents. We believe that studying these agents on a large scale offers valuable insights into their behaviors, capabilities, and potential risks. To facilitate research in this field, we implement and support various types of agents, tasks, prompts, models, and simulated environments.
llm-baselines
LLM-baselines is a modular codebase to experiment with transformers, inspired from NanoGPT. It provides a quick and easy way to train and evaluate transformer models on a variety of datasets. The codebase is well-documented and easy to use, making it a great resource for researchers and practitioners alike.
python-tutorial-notebooks
This repository contains Jupyter-based tutorials for NLP, ML, AI in Python for classes in Computational Linguistics, Natural Language Processing (NLP), Machine Learning (ML), and Artificial Intelligence (AI) at Indiana University.
EvalAI
EvalAI is an open-source platform for evaluating and comparing machine learning (ML) and artificial intelligence (AI) algorithms at scale. It provides a central leaderboard and submission interface, making it easier for researchers to reproduce results mentioned in papers and perform reliable & accurate quantitative analysis. EvalAI also offers features such as custom evaluation protocols and phases, remote evaluation, evaluation inside environments, CLI support, portability, and faster evaluation.
Weekly-Top-LLM-Papers
This repository provides a curated list of weekly published Large Language Model (LLM) papers. It includes top important LLM papers for each week, organized by month and year. The papers are categorized into different time periods, making it easy to find the most recent and relevant research in the field of LLM.
self-llm
This project is a Chinese tutorial for domestic beginners based on the AutoDL platform, providing full-process guidance for various open-source large models, including environment configuration, local deployment, and efficient fine-tuning. It simplifies the deployment, use, and application process of open-source large models, enabling more ordinary students and researchers to better use open-source large models and helping open and free large models integrate into the lives of ordinary learners faster.