
celery-aio-pool
Celery worker pool with support for asyncio coroutines as tasks
Stars: 53
Celery AsyncIO Pool is a free software tool licensed under GNU Affero General Public License v3+. It provides an AsyncIO worker pool for Celery, enabling users to leverage the power of AsyncIO in their Celery applications. The tool allows for easy installation using Poetry, pip, or directly from GitHub. Users can configure Celery to use the AsyncIO pool provided by celery-aio-pool, or they can wait for the upcoming support for out-of-tree worker pools in Celery 5.3. The tool is actively maintained and welcomes contributions from the community.
README:




![]()
Free software: GNU Affero General Public License v3+
poetry add celery-aio-pool
Using pip & PyPI.org
pip install celery-aio-pool
Using pip & GitHub
pip install git+https://github.com/the-wondersmith/celery-aio-pool.git
git clone https://github.com/the-wondersmith/celery-aio-pool.git
cd celery-aio-pool
pip install -e "$(pwd)"
- Import
celery_aio_poolin the same module where your Celery "app" is defined - Ensure that the
patch_celery_tracerutility is called before any other Celery code is called
"""My super awesome Celery app."""
# ...
from celery import Celery
# add the following import
import celery_aio_pool as aio_pool
# ensure the patcher is called *before*
# your Celery app is defined
assert aio_pool.patch_celery_tracer() is True
app = Celery(
"my-super-awesome-celery-app",
broker="amqp://guest@localhost//",
# add the following keyword argument
worker_pool=aio_pool.pool.AsyncIOPool,
)At the time of writing, Celery does not have
built-in support for out-of-tree pools like celery-aio-pool, but support should
be included starting with the first non-beta release of Celery 5.3. (note: PR #7880 was merged on 2022-11-15).
The official release of Celery 5.3 enables the configuration of custom worker pool classes thusly:
-
Set the environment variable
CELERY_CUSTOM_WORKER_POOLto the name of your desired worker pool implementation implementation.-
NOTE: The value of the environment variable must be formatted in
the standard Python/Celery format of
package:class -
% export CELERY_CUSTOM_WORKER_POOL='celery_aio_pool.pool:AsyncIOPool'
-
NOTE: The value of the environment variable must be formatted in
the standard Python/Celery format of
-
Tell Celery to use your desired pool by specifying
--pool=customwhen running your worker instance(s)-
% celery worker --pool=custom --loglevel=INFO --logfile="$(pwd)/worker.log"
-
To verify the pool implementation, examine the output of the celery inspect stats
command:
% celery --app=your_celery_project inspect stats
-> celery@freenas: OK
{
...
"pool": {
...
"implementation": "celery_aio_pool.pool:AsyncIOPool",
...NOTE: Our preferred packaging and dependency manager is Poetry. Installation instructions can be found here.
Clone the repo and install the dependencies
$ git clone https://github.com/the-wondersmith/celery-aio-pool.git \
&& cd celery-aio-pool \
&& poetry install --syncOptionally, if you do not have or prefer not to use Poetry, celery-aio-pool is
fully PEP-517 compliant and can be installed directly by any PEP-517-compliant package
manager.
$ cd celery-aio-pool \
&& pip install -e "$(pwd)"TODO: Coming Soon™
To run the test suite:
$ poetry run pytest tests/TODO: Coming Soon™
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for celery-aio-pool
Similar Open Source Tools
celery-aio-pool
Celery AsyncIO Pool is a free software tool licensed under GNU Affero General Public License v3+. It provides an AsyncIO worker pool for Celery, enabling users to leverage the power of AsyncIO in their Celery applications. The tool allows for easy installation using Poetry, pip, or directly from GitHub. Users can configure Celery to use the AsyncIO pool provided by celery-aio-pool, or they can wait for the upcoming support for out-of-tree worker pools in Celery 5.3. The tool is actively maintained and welcomes contributions from the community.
starknet-agent-kit
starknet-agent-kit is a NestJS-based toolkit for creating AI agents that can interact with the Starknet blockchain. It allows users to perform various actions such as retrieving account information, creating accounts, transferring assets, playing with DeFi, interacting with dApps, and executing RPC read methods. The toolkit provides a secure environment for developing AI agents while emphasizing caution when handling sensitive information. Users can make requests to the Starknet agent via API endpoints and utilize tools from Langchain directly.

ragflow
RAGFlow is an open-source Retrieval-Augmented Generation (RAG) engine that combines deep document understanding with Large Language Models (LLMs) to provide accurate question-answering capabilities. It offers a streamlined RAG workflow for businesses of all sizes, enabling them to extract knowledge from unstructured data in various formats, including Word documents, slides, Excel files, images, and more. RAGFlow's key features include deep document understanding, template-based chunking, grounded citations with reduced hallucinations, compatibility with heterogeneous data sources, and an automated and effortless RAG workflow. It supports multiple recall paired with fused re-ranking, configurable LLMs and embedding models, and intuitive APIs for seamless integration with business applications.

llama.vim
llama.vim is a plugin that provides local LLM-assisted text completion for Vim users. It offers features such as auto-suggest on cursor movement, manual suggestion toggling, suggestion acceptance with Tab and Shift+Tab, control over text generation time, context configuration, ring context with chunks from open and edited files, and performance stats display. The plugin requires a llama.cpp server instance to be running and supports FIM-compatible models. It aims to be simple, lightweight, and provide high-quality and performant local FIM completions even on consumer-grade hardware.
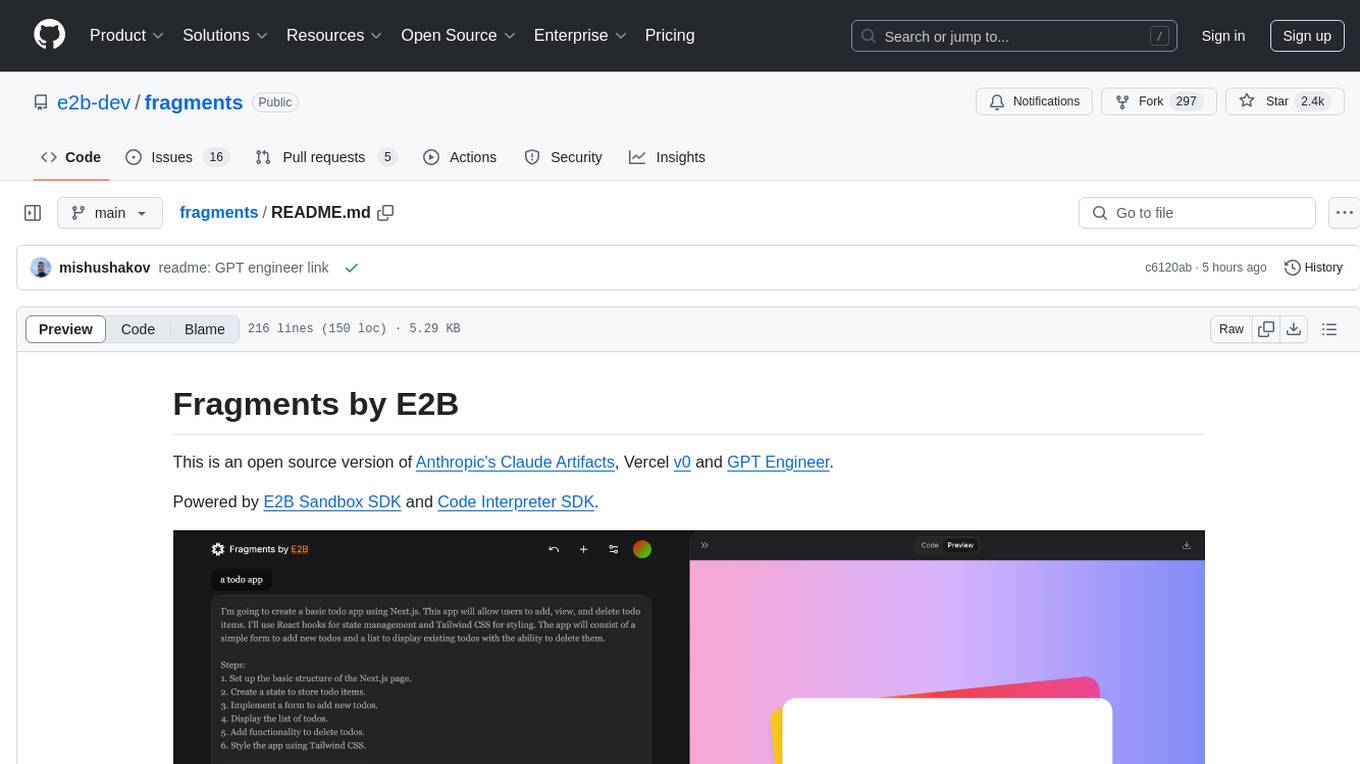
fragments
Fragments is an open-source tool that leverages Anthropic's Claude Artifacts, Vercel v0, and GPT Engineer. It is powered by E2B Sandbox SDK and Code Interpreter SDK, allowing secure execution of AI-generated code. The tool is based on Next.js 14, shadcn/ui, TailwindCSS, and Vercel AI SDK. Users can stream in the UI, install packages from npm and pip, and add custom stacks and LLM providers. Fragments enables users to build web apps with Python interpreter, Next.js, Vue.js, Streamlit, and Gradio, utilizing providers like OpenAI, Anthropic, Google AI, and more.
client-python
The Mistral Python Client is a tool inspired by cohere-python that allows users to interact with the Mistral AI API. It provides functionalities to access and utilize the AI capabilities offered by Mistral. Users can easily install the client using pip and manage dependencies using poetry. The client includes examples demonstrating how to use the API for various tasks, such as chat interactions. To get started, users need to obtain a Mistral API Key and set it as an environment variable. Overall, the Mistral Python Client simplifies the integration of Mistral AI services into Python applications.

raglite
RAGLite is a Python toolkit for Retrieval-Augmented Generation (RAG) with PostgreSQL or SQLite. It offers configurable options for choosing LLM providers, database types, and rerankers. The toolkit is fast and permissive, utilizing lightweight dependencies and hardware acceleration. RAGLite provides features like PDF to Markdown conversion, multi-vector chunk embedding, optimal semantic chunking, hybrid search capabilities, adaptive retrieval, and improved output quality. It is extensible with a built-in Model Context Protocol server, customizable ChatGPT-like frontend, document conversion to Markdown, and evaluation tools. Users can configure RAGLite for various tasks like configuring, inserting documents, running RAG pipelines, computing query adapters, evaluating performance, running MCP servers, and serving frontends.
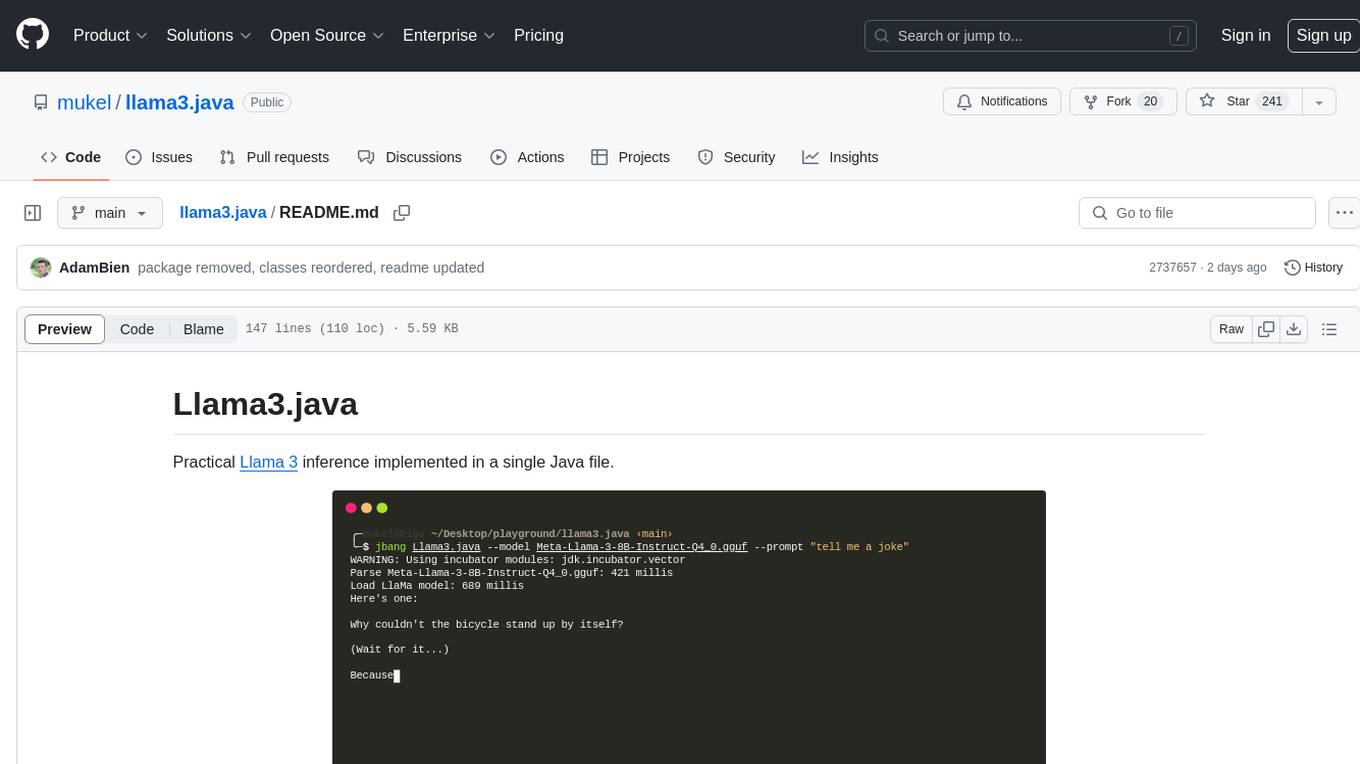
llama3.java
Llama3.java is a practical Llama 3 inference tool implemented in a single Java file. It serves as the successor of llama2.java and is designed for testing and tuning compiler optimizations and features on the JVM, especially for the Graal compiler. The tool features a GGUF format parser, Llama 3 tokenizer, Grouped-Query Attention inference, support for Q8_0 and Q4_0 quantizations, fast matrix-vector multiplication routines using Java's Vector API, and a simple CLI with 'chat' and 'instruct' modes. Users can download quantized .gguf files from huggingface.co for model usage and can also manually quantize to pure 'Q4_0'. The tool requires Java 21+ and supports running from source or building a JAR file for execution. Performance benchmarks show varying tokens/s rates for different models and implementations on different hardware setups.

TalkWithGemini
Talk With Gemini is a web application that allows users to deploy their private Gemini application for free with one click. It supports Gemini Pro and Gemini Pro Vision models. The application features talk mode for direct communication with Gemini, visual recognition for understanding picture content, full Markdown support, automatic compression of chat records, privacy and security with local data storage, well-designed UI with responsive design, fast loading speed, and multi-language support. The tool is designed to be user-friendly and versatile for various deployment options and language preferences.

obsei
Obsei is an open-source, low-code, AI powered automation tool that consists of an Observer to collect unstructured data from various sources, an Analyzer to analyze the collected data with various AI tasks, and an Informer to send analyzed data to various destinations. The tool is suitable for scheduled jobs or serverless applications as all Observers can store their state in databases. Obsei is still in alpha stage, so caution is advised when using it in production. The tool can be used for social listening, alerting/notification, automatic customer issue creation, extraction of deeper insights from feedbacks, market research, dataset creation for various AI tasks, and more based on creativity.

metis
Metis is an open-source, AI-driven tool for deep security code review, created by Arm's Product Security Team. It helps engineers detect subtle vulnerabilities, improve secure coding practices, and reduce review fatigue. Metis uses LLMs for semantic understanding and reasoning, RAG for context-aware reviews, and supports multiple languages and vector store backends. It provides a plugin-friendly and extensible architecture, named after the Greek goddess of wisdom, Metis. The tool is designed for large, complex, or legacy codebases where traditional tooling falls short.

swe-rl
SWE-RL is the official codebase for the paper 'SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution'. It is the first approach to scale reinforcement learning based LLM reasoning for real-world software engineering, leveraging open-source software evolution data and rule-based rewards. The code provides prompt templates and the implementation of the reward function based on sequence similarity. Agentless Mini, a part of SWE-RL, builds on top of Agentless with improvements like fast async inference, code refactoring for scalability, and support for using multiple reproduction tests for reranking. The tool can be used for localization, repair, and reproduction test generation in software engineering tasks.
AutoRAG
AutoRAG is an AutoML tool designed to automatically find the optimal RAG pipeline for your data. It simplifies the process of evaluating various RAG modules to identify the best pipeline for your specific use-case. The tool supports easy evaluation of different module combinations, making it efficient to find the most suitable RAG pipeline for your needs. AutoRAG also offers a cloud beta version to assist users in running and optimizing the tool, along with building RAG evaluation datasets for a starting price of $9.99 per optimization.

LEANN
LEANN is an innovative vector database that democratizes personal AI, transforming your laptop into a powerful RAG system that can index and search through millions of documents using 97% less storage than traditional solutions without accuracy loss. It achieves this through graph-based selective recomputation and high-degree preserving pruning, computing embeddings on-demand instead of storing them all. LEANN allows semantic search of file system, emails, browser history, chat history, codebase, or external knowledge bases on your laptop with zero cloud costs and complete privacy. It is a drop-in semantic search MCP service fully compatible with Claude Code, enabling intelligent retrieval without changing your workflow.
mcpdoc
The MCP LLMS-TXT Documentation Server is an open-source server that provides developers full control over tools used by applications like Cursor, Windsurf, and Claude Code/Desktop. It allows users to create a user-defined list of `llms.txt` files and use a `fetch_docs` tool to read URLs within these files, enabling auditing of tool calls and context returned. The server supports various applications and provides a way to connect to them, configure rules, and test tool calls for tasks related to documentation retrieval and processing.
NextChat
NextChat is a well-designed cross-platform ChatGPT web UI tool that supports Claude, GPT4, and Gemini Pro. It offers a compact client for Linux, Windows, and MacOS, with features like self-deployed LLMs compatibility, privacy-first data storage, markdown support, responsive design, and fast loading speed. Users can create, share, and debug chat tools with prompt templates, access various prompts, compress chat history, and use multiple languages. The tool also supports enterprise-level privatization and customization deployment, with features like brand customization, resource integration, permission control, knowledge integration, security auditing, private deployment, and continuous updates.
For similar tasks
celery-aio-pool
Celery AsyncIO Pool is a free software tool licensed under GNU Affero General Public License v3+. It provides an AsyncIO worker pool for Celery, enabling users to leverage the power of AsyncIO in their Celery applications. The tool allows for easy installation using Poetry, pip, or directly from GitHub. Users can configure Celery to use the AsyncIO pool provided by celery-aio-pool, or they can wait for the upcoming support for out-of-tree worker pools in Celery 5.3. The tool is actively maintained and welcomes contributions from the community.
perplexity-ai
Perplexity is a module that utilizes emailnator to generate new accounts, providing users with 5 pro queries per account creation. It enables the creation of new Gmail accounts with emailnator, ensuring unlimited pro queries. The tool requires specific Python libraries for installation and offers both a web interface and an API for different usage scenarios. Users can interact with the tool to perform various tasks such as account creation, query searches, and utilizing different modes for research purposes. Perplexity also supports asynchronous operations and provides guidance on obtaining cookies for account usage and account generation from emailnator.
ragna
Ragna is a RAG orchestration framework designed for managing workflows and orchestrating tasks. It provides a comprehensive set of features for users to streamline their processes and automate repetitive tasks. With Ragna, users can easily create, schedule, and monitor workflows, making it an ideal tool for teams and individuals looking to improve their productivity and efficiency. The framework offers extensive documentation, community support, and a user-friendly interface, making it accessible to users of all skill levels. Whether you are a developer, data scientist, or project manager, Ragna can help you simplify your workflow management and boost your overall performance.
tegon
Tegon is an open-source AI-First issue tracking tool designed for engineering teams. It aims to simplify task management by leveraging AI and integrations to automate task creation, prioritize tasks, and enhance bug resolution. Tegon offers features like issues tracking, automatic title generation, AI-generated labels and assignees, custom views, and upcoming features like sprints and task prioritization. It integrates with GitHub, Slack, and Sentry to streamline issue tracking processes. Tegon also plans to introduce AI Agents like PR Agent and Bug Agent to enhance product management and bug resolution. Contributions are welcome, and the product is licensed under the MIT License.
Advanced-GPTs
Nerority's Advanced GPT Suite is a collection of 33 GPTs that can be controlled with natural language prompts. The suite includes tools for various tasks such as strategic consulting, business analysis, career profile building, content creation, educational purposes, image-based tasks, knowledge engineering, marketing, persona creation, programming, prompt engineering, role-playing, simulations, and task management. Users can access links, usage instructions, and guides for each GPT on their respective pages. The suite is designed for public demonstration and usage, offering features like meta-sequence optimization, AI priming, prompt classification, and optimization. It also provides tools for generating articles, analyzing contracts, visualizing data, distilling knowledge, creating educational content, exploring topics, generating marketing copy, simulating scenarios, managing tasks, and more.
aioclock
An asyncio-based scheduling framework designed for execution of periodic tasks with integrated support for dependency injection, enabling efficient and flexible task management. Aioclock is 100% async, light, fast, and resource-friendly. It offers features like task scheduling, grouping, trigger definition, easy syntax, Pydantic v2 validation, and upcoming support for running the task dispatcher on a different process and backend support for horizontal scaling.
airavata
Apache Airavata is a software framework for executing and managing computational jobs on distributed computing resources. It supports local clusters, supercomputers, national grids, academic and commercial clouds. Airavata utilizes service-oriented computing, distributed messaging, and workflow composition. It includes a server package with an API, client SDKs, and a general-purpose UI implementation called Apache Airavata Django Portal.
CrewAI-Studio
CrewAI Studio is an application with a user-friendly interface for interacting with CrewAI, offering support for multiple platforms and various backend providers. It allows users to run crews in the background, export single-page apps, and use custom tools for APIs and file writing. The roadmap includes features like better import/export, human input, chat functionality, automatic crew creation, and multiuser environment support.
For similar jobs
aiomcache
aiomcache is a Python library that provides an asyncio (PEP 3156) interface to work with memcached. It allows users to interact with memcached servers asynchronously, making it suitable for high-performance applications that require non-blocking I/O operations. The library offers similar functionality to other memcache clients and includes features like setting and getting values, multi-get operations, and deleting keys. Version 0.8 introduces the `FlagClient` class, which enables users to register callbacks for setting or processing flags, providing additional flexibility and customization options for working with memcached servers.
aiolimiter
An efficient implementation of a rate limiter for asyncio using the Leaky bucket algorithm, providing precise control over the rate a code section can be entered. It allows for limiting the number of concurrent entries within a specified time window, ensuring that a section of code is executed a maximum number of times in that period.
bee
Bee is an easy and high efficiency ORM framework that simplifies database operations by providing a simple interface and eliminating the need to write separate DAO code. It supports various features such as automatic filtering of properties, partial field queries, native statement pagination, JSON format results, sharding, multiple database support, and more. Bee also offers powerful functionalities like dynamic query conditions, transactions, complex queries, MongoDB ORM, cache management, and additional tools for generating distributed primary keys, reading Excel files, and more. The newest versions introduce enhancements like placeholder precompilation, default date sharding, ElasticSearch ORM support, and improved query capabilities.
claude-api
claude-api is a web conversation library for ClaudeAI implemented in GoLang. It provides functionalities to interact with ClaudeAI for web-based conversations. Users can easily integrate this library into their Go projects to enable chatbot capabilities and handle conversations with ClaudeAI. The library includes features for sending messages, receiving responses, and managing chat sessions, making it a valuable tool for developers looking to incorporate AI-powered chatbots into their applications.
aide
Aide is a code-first API documentation and utility library for Rust, along with other related utility crates for web-servers. It provides tools for creating API documentation and handling JSON request validation. The repository contains multiple crates that offer drop-in replacements for existing libraries, ensuring compatibility with Aide. Contributions are welcome, and the code is dual licensed under MIT and Apache-2.0. If Aide does not meet your requirements, you can explore similar libraries like paperclip, utoipa, and okapi.
amadeus-java
Amadeus Java SDK provides a rich set of APIs for the travel industry, allowing developers to access various functionalities such as flight search, booking, airport information, and more. The SDK simplifies interaction with the Amadeus API by providing self-contained code examples and detailed documentation. Developers can easily make API calls, handle responses, and utilize features like pagination and logging. The SDK supports various endpoints for tasks like flight search, booking management, airport information retrieval, and travel analytics. It also offers functionalities for hotel search, booking, and sentiment analysis. Overall, the Amadeus Java SDK is a comprehensive tool for integrating Amadeus APIs into Java applications.
rig
Rig is a Rust library designed for building scalable, modular, and user-friendly applications powered by large language models (LLMs). It provides full support for LLM completion and embedding workflows, offers simple yet powerful abstractions for LLM providers like OpenAI and Cohere, as well as vector stores such as MongoDB and in-memory storage. With Rig, users can easily integrate LLMs into their applications with minimal boilerplate code.
celery-aio-pool
Celery AsyncIO Pool is a free software tool licensed under GNU Affero General Public License v3+. It provides an AsyncIO worker pool for Celery, enabling users to leverage the power of AsyncIO in their Celery applications. The tool allows for easy installation using Poetry, pip, or directly from GitHub. Users can configure Celery to use the AsyncIO pool provided by celery-aio-pool, or they can wait for the upcoming support for out-of-tree worker pools in Celery 5.3. The tool is actively maintained and welcomes contributions from the community.