
llama3.java
Practical Llama 3 inference in Java
Stars: 471
Llama3.java is a practical Llama 3 inference tool implemented in a single Java file. It serves as the successor of llama2.java and is designed for testing and tuning compiler optimizations and features on the JVM, especially for the Graal compiler. The tool features a GGUF format parser, Llama 3 tokenizer, Grouped-Query Attention inference, support for Q8_0 and Q4_0 quantizations, fast matrix-vector multiplication routines using Java's Vector API, and a simple CLI with 'chat' and 'instruct' modes. Users can download quantized .gguf files from huggingface.co for model usage and can also manually quantize to pure 'Q4_0'. The tool requires Java 21+ and supports running from source or building a JAR file for execution. Performance benchmarks show varying tokens/s rates for different models and implementations on different hardware setups.
README:
Practical Llama 3, 3.1 and 3.2 inference implemented in a single Java file.
This project is the successor of llama2.java based on llama2.c by Andrej Karpathy and his excellent educational videos.
Besides the educational value, this project will be used to test and tune compiler optimizations and features on the JVM, particularly for the Graal compiler.
- Single file, no dependencies
- GGUF format parser
- Llama 3 tokenizer based on minbpe
- Llama 3 inference with Grouped-Query Attention
- Support Llama 3.1 (ad-hoc RoPE scaling) and 3.2 (tie word embeddings)
- Support for Q8_0 and Q4_0 quantizations
- Fast matrix-vector multiplication routines for quantized tensors using Java's Vector API
- Simple CLI with
--chatand--instructmodes. - GraalVM's Native Image support (EA builds here)
- AOT model pre-loading for instant time-to-first-token
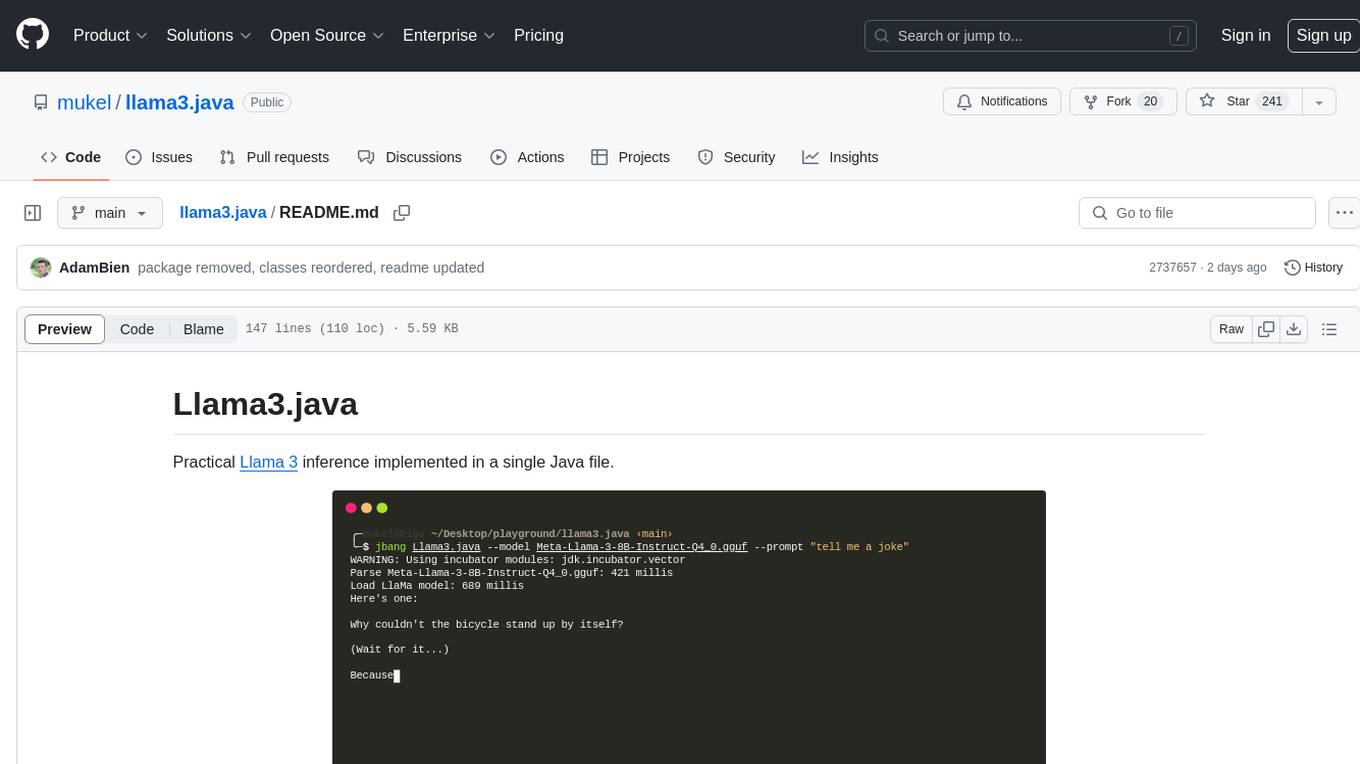
Interactive --chat mode in action:
Presented at Devoxx Belgium, 2024

Download pure Q4_0 and (optionally) Q8_0 quantized .gguf files from:
- https://huggingface.co/mukel/Llama-3.2-1B-Instruct-GGUF
- https://huggingface.co/mukel/Llama-3.2-3B-Instruct-GGUF
- https://huggingface.co/mukel/Meta-Llama-3.1-8B-Instruct-GGUF
- https://huggingface.co/mukel/Meta-Llama-3-8B-Instruct-GGUF
The pure Q4_0 quantized models are recommended, except for the very small models (1B), please be gentle with huggingface.co servers:
# Llama 3.2 (3B)
curl -L -O https://huggingface.co/mukel/Llama-3.2-3B-Instruct-GGUF/resolve/main/Llama-3.2-3B-Instruct-Q4_0.gguf
# Llama 3.2 (1B)
curl -L -O https://huggingface.co/mukel/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q8_0.gguf
# Llama 3.1 (8B)
curl -L -O https://huggingface.co/mukel/Meta-Llama-3.1-8B-Instruct-GGUF/resolve/main/Meta-Llama-3.1-8B-Instruct-Q4_0.gguf
# Llama 3 (8B)
curl -L -O https://huggingface.co/mukel/Meta-Llama-3-8B-Instruct-GGUF/resolve/main/Meta-Llama-3-8B-Instruct-Q4_0.gguf
# Optionally download the Q8_0 quantized models
# curl -L -O https://huggingface.co/mukel/Meta-Llama-3-8B-Instruct-GGUF/resolve/main/Meta-Llama-3-8B-Instruct-Q8_0.gguf
# curl -L -O https://huggingface.co/mukel/Meta-Llama-3.1-8B-Instruct-GGUF/resolve/main/Meta-Llama-3.1-8B-Instruct-Q8_0.gguf
In the wild, Q8_0 quantizations are fine, but Q4_0 quantizations are rarely pure e.g. the token_embd.weights/output.weights tensor are quantized with Q6_K, instead of Q4_0.
A pure Q4_0 quantization can be generated from a high precision (F32, F16, BFLOAT16) .gguf source
with the llama-quantize utility from llama.cpp as follows:
./llama-quantize --pure ./Meta-Llama-3-8B-Instruct-F32.gguf ./Meta-Llama-3-8B-Instruct-Q4_0.gguf Q4_0Java 21+ is required, in particular the MemorySegment mmap-ing feature.
jbang is a perfect fit for this use case, just:
jbang Llama3.java --help
Or execute directly, also via jbang:
chmod +x Llama3.java
./Llama3.java --helpjava --enable-preview --source 21 --add-modules jdk.incubator.vector LLama3.java -i --model Meta-Llama-3-8B-Instruct-Q4_0.ggufA simple Makefile is provided, run make to produce llama3.jar or manually:
javac -g --enable-preview -source 21 --add-modules jdk.incubator.vector -d target/classes Llama3.java
jar -cvfe llama3.jar com.llama4j.Llama3 LICENSE -C target/classes .Run the resulting llama3.jar as follows:
java --enable-preview --add-modules jdk.incubator.vector -jar llama3.jar --helpCompile to native via make (recommended):
make nativeOr directly:
native-image -H:+UnlockExperimentalVMOptions -H:+VectorAPISupport -H:+ForeignAPISupport -O3 -march=native --enable-preview --add-modules jdk.incubator.vector --initialize-at-build-time=com.llama4j.FloatTensor -Djdk.incubator.vector.VECTOR_ACCESS_OOB_CHECK=0 -jar llama3.jar -o llama3Run as Native Image:
./llama3 --model Llama-3.2-1B-Instruct-Q8_0 --chatLlama3.java supports AOT model preloading, enabling 0-overhead, instant inference, with minimal TTFT (time-to-first-token).
To AOT pre-load a GGUF model:
PRELOAD_GGUF=/path/to/model.gguf make nativeA specialized, larger binary will be generated, with no parsing overhead for that particular model. It can still run other models, although incurring the usual parsing overhead.
GraalVM now supports more Vector API operations. To give it a try, you need GraalVM for JDK 24 – get the EA builds from oracle-graalvm-ea-builds or sdkman: sdk install java 24.ea.15-graal.
Vanilla llama.cpp built with make.
./llama-cli --version 130 ↵
version: 3862 (3f1ae2e3)
built with cc (GCC) 14.2.1 20240805 for x86_64-pc-linux-gnuExecuted as follows:
./llama-bench -m Llama-3.2-1B-Instruct-Q4_0.gguf -p 0 -n 128taskset -c 0-15 ./llama3 \
--model ./Llama-3-1B-Instruct-Q4_0.gguf \
--max-tokens 128 \
--seed 42 \
--stream false \
--prompt "Why is the sky blue?"Hardware specs: 2019 AMD Ryzen 3950X 16C/32T 64GB (3800) Linux 6.6.47.
**Notes
Running on a single CCD e.g. taskset -c 0-15 ./llama3 ... since inference is constrained by memory bandwidth.
MIT
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llama3.java
Similar Open Source Tools
llama3.java
Llama3.java is a practical Llama 3 inference tool implemented in a single Java file. It serves as the successor of llama2.java and is designed for testing and tuning compiler optimizations and features on the JVM, especially for the Graal compiler. The tool features a GGUF format parser, Llama 3 tokenizer, Grouped-Query Attention inference, support for Q8_0 and Q4_0 quantizations, fast matrix-vector multiplication routines using Java's Vector API, and a simple CLI with 'chat' and 'instruct' modes. Users can download quantized .gguf files from huggingface.co for model usage and can also manually quantize to pure 'Q4_0'. The tool requires Java 21+ and supports running from source or building a JAR file for execution. Performance benchmarks show varying tokens/s rates for different models and implementations on different hardware setups.

llama.vim
llama.vim is a plugin that provides local LLM-assisted text completion for Vim users. It offers features such as auto-suggest on cursor movement, manual suggestion toggling, suggestion acceptance with Tab and Shift+Tab, control over text generation time, context configuration, ring context with chunks from open and edited files, and performance stats display. The plugin requires a llama.cpp server instance to be running and supports FIM-compatible models. It aims to be simple, lightweight, and provide high-quality and performant local FIM completions even on consumer-grade hardware.
speech-to-speech
This repository implements a speech-to-speech cascaded pipeline with consecutive parts including Voice Activity Detection (VAD), Speech to Text (STT), Language Model (LM), and Text to Speech (TTS). It aims to provide a fully open and modular approach by leveraging models available on the Transformers library via the Hugging Face hub. The code is designed for easy modification, with each component implemented as a class. Users can run the pipeline either on a server/client approach or locally, with detailed setup and usage instructions provided in the readme.
ahnlich
Ahnlich is a tool that provides multiple components for storing and searching similar vectors using linear or non-linear similarity algorithms. It includes 'ahnlich-db' for in-memory vector key value store, 'ahnlich-ai' for AI proxy communication, 'ahnlich-client-rs' for Rust client, and 'ahnlich-client-py' for Python client. The tool is not production-ready yet and is still in testing phase, allowing AI/ML engineers to issue queries using raw input such as images/text and features off-the-shelf models for indexing and querying.
binglish
binglish is a desktop English learning tool that automatically changes the Bing daily wallpaper while helping users learn new words through AI-generated images, example sentences, and translations. Users can enjoy beautiful scenery, acquire knowledge, and build vocabulary towers. The tool excludes bad words and offers words ranging from CET-4 to GRE difficulty levels. It refreshes every 3 hours and is designed for Windows 10 and above with a resolution of 1920x1080. The AI-generated content may not be completely accurate.
hound
Hound is a security audit automation pipeline for AI-assisted code review that mirrors how expert auditors think, learn, and collaborate. It features graph-driven analysis, sessionized audits, provider-agnostic models, belief system and hypotheses, precise code grounding, and adaptive planning. The system employs a senior/junior auditor pattern where the Scout actively navigates the codebase and annotates knowledge graphs while the Strategist handles high-level planning and vulnerability analysis. Hound is optimized for small-to-medium sized projects like smart contract applications and is language-agnostic.
green-bit-llm
Green-Bit-LLM is a Python toolkit designed for fine-tuning, inferencing, and evaluating GreenBitAI's low-bit Language Models (LLMs). It utilizes the Bitorch Engine for efficient operations on low-bit LLMs, enabling high-performance inference on various GPUs and supporting full-parameter fine-tuning using quantized LLMs. The toolkit also provides evaluation tools to validate model performance on benchmark datasets. Green-Bit-LLM is compatible with AutoGPTQ series of 4-bit quantization and compression models.
backend.ai
Backend.AI is a streamlined, container-based computing cluster platform that hosts popular computing/ML frameworks and diverse programming languages, with pluggable heterogeneous accelerator support including CUDA GPU, ROCm GPU, TPU, IPU and other NPUs. It allocates and isolates the underlying computing resources for multi-tenant computation sessions on-demand or in batches with customizable job schedulers with its own orchestrator. All its functions are exposed as REST/GraphQL/WebSocket APIs.

pebblo
Pebblo enables developers to safely load data and promote their Gen AI app to deployment without worrying about the organization’s compliance and security requirements. The project identifies semantic topics and entities found in the loaded data and summarizes them on the UI or a PDF report.
litserve
LitServe is a high-throughput serving engine for deploying AI models at scale. It generates an API endpoint for a model, handles batching, streaming, autoscaling across CPU/GPUs, and more. Built for enterprise scale, it supports every framework like PyTorch, JAX, Tensorflow, and more. LitServe is designed to let users focus on model performance, not the serving boilerplate. It is like PyTorch Lightning for model serving but with broader framework support and scalability.

can-ai-code
Can AI Code is a self-evaluating interview tool for AI coding models. It includes interview questions written by humans and tests taken by AI, inference scripts for common API providers and CUDA-enabled quantization runtimes, a Docker-based sandbox environment for validating untrusted Python and NodeJS code, and the ability to evaluate the impact of prompting techniques and sampling parameters on large language model (LLM) coding performance. Users can also assess LLM coding performance degradation due to quantization. The tool provides test suites for evaluating LLM coding performance, a webapp for exploring results, and comparison scripts for evaluations. It supports multiple interviewers for API and CUDA runtimes, with detailed instructions on running the tool in different environments. The repository structure includes folders for interviews, prompts, parameters, evaluation scripts, comparison scripts, and more.
llm-detect-ai
This repository contains code and configurations for the LLM - Detect AI Generated Text competition. It includes setup instructions for hardware, software, dependencies, and datasets. The training section covers scripts and configurations for training LLM models, DeBERTa ranking models, and an embedding model. Text generation section details fine-tuning LLMs using the CLM objective on the PERSUADE corpus to generate student-like essays.
aicsimageio
AICSImageIO is a Python tool for Image Reading, Metadata Conversion, and Image Writing for Microscopy Images. It supports various file formats like OME-TIFF, TIFF, ND2, DV, CZI, LIF, PNG, GIF, and Bio-Formats. Users can read and write metadata and imaging data, work with different file systems like local paths, HTTP URLs, s3fs, and gcsfs. The tool provides functionalities for full image reading, delayed image reading, mosaic image reading, metadata reading, xarray coordinate plane attachment, cloud IO support, and saving to OME-TIFF. It also offers benchmarking and developer resources.
neural-speed
Neural Speed is an innovative library designed to support the efficient inference of large language models (LLMs) on Intel platforms through the state-of-the-art (SOTA) low-bit quantization powered by Intel Neural Compressor. The work is inspired by llama.cpp and further optimized for Intel platforms with our innovations in NeurIPS' 2023
QA-Pilot
QA-Pilot is an interactive chat project that leverages online/local LLM for rapid understanding and navigation of GitHub code repository. It allows users to chat with GitHub public repositories using a git clone approach, store chat history, configure settings easily, manage multiple chat sessions, and quickly locate sessions with a search function. The tool integrates with `codegraph` to view Python files and supports various LLM models such as ollama, openai, mistralai, and localai. The project is continuously updated with new features and improvements, such as converting from `flask` to `fastapi`, adding `localai` API support, and upgrading dependencies like `langchain` and `Streamlit` to enhance performance.
elysium
Elysium is an Emacs package that allows users to automatically apply AI-generated changes while coding. By calling `elysium-query`, users can request a set of changes that will be merged into the code buffer. The tool supports making queries on a specific region without leaving the code buffer. It uses the `gptel` backend and currently recommends using the Claude 3-5 Sonnet model for generating code. Users can customize the window size and style of the Elysium buffer. The tool also provides functions to keep or discard AI-suggested changes and navigate conflicting hunks with `smerge-mode`.
For similar tasks
llama3.java
Llama3.java is a practical Llama 3 inference tool implemented in a single Java file. It serves as the successor of llama2.java and is designed for testing and tuning compiler optimizations and features on the JVM, especially for the Graal compiler. The tool features a GGUF format parser, Llama 3 tokenizer, Grouped-Query Attention inference, support for Q8_0 and Q4_0 quantizations, fast matrix-vector multiplication routines using Java's Vector API, and a simple CLI with 'chat' and 'instruct' modes. Users can download quantized .gguf files from huggingface.co for model usage and can also manually quantize to pure 'Q4_0'. The tool requires Java 21+ and supports running from source or building a JAR file for execution. Performance benchmarks show varying tokens/s rates for different models and implementations on different hardware setups.

auto-round
AutoRound is an advanced weight-only quantization algorithm for low-bits LLM inference. It competes impressively against recent methods without introducing any additional inference overhead. The method adopts sign gradient descent to fine-tune rounding values and minmax values of weights in just 200 steps, often significantly outperforming SignRound with the cost of more tuning time for quantization. AutoRound is tailored for a wide range of models and consistently delivers noticeable improvements.
GPTQModel
GPTQModel is an easy-to-use LLM quantization and inference toolkit based on the GPTQ algorithm. It provides support for weight-only quantization and offers features such as dynamic per layer/module flexible quantization, sharding support, and auto-heal quantization errors. The toolkit aims to ensure inference compatibility with HF Transformers, vLLM, and SGLang. It offers various model supports, faster quant inference, better quality quants, and security features like hash check of model weights. GPTQModel also focuses on faster quantization, improved quant quality as measured by PPL, and backports bug fixes from AutoGPTQ.

Chinese-Mixtral-8x7B
Chinese-Mixtral-8x7B is an open-source project based on Mistral's Mixtral-8x7B model for incremental pre-training of Chinese vocabulary, aiming to advance research on MoE models in the Chinese natural language processing community. The expanded vocabulary significantly improves the model's encoding and decoding efficiency for Chinese, and the model is pre-trained incrementally on a large-scale open-source corpus, enabling it with powerful Chinese generation and comprehension capabilities. The project includes a large model with expanded Chinese vocabulary and incremental pre-training code.
LLM-Drop
LLM-Drop is an official implementation of the paper 'What Matters in Transformers? Not All Attention is Needed'. The tool investigates redundancy in transformer-based Large Language Models (LLMs) by analyzing the architecture of Blocks, Attention layers, and MLP layers. It reveals that dropping certain Attention layers can enhance computational and memory efficiency without compromising performance. The tool provides a pipeline for Block Drop and Layer Drop based on LLaMA-Factory, and implements quantization using AutoAWQ and AutoGPTQ.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

caikit
Caikit is an AI toolkit that enables users to manage models through a set of developer friendly APIs. It provides a consistent format for creating and using AI models against a wide variety of data domains and tasks.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.