
llama.vim
Vim plugin for LLM-assisted code/text completion
Stars: 1271

llama.vim is a plugin that provides local LLM-assisted text completion for Vim users. It offers features such as auto-suggest on cursor movement, manual suggestion toggling, suggestion acceptance with Tab and Shift+Tab, control over text generation time, context configuration, ring context with chunks from open and edited files, and performance stats display. The plugin requires a llama.cpp server instance to be running and supports FIM-compatible models. It aims to be simple, lightweight, and provide high-quality and performant local FIM completions even on consumer-grade hardware.
README:
Local LLM-assisted text completion.
- Auto-suggest on cursor movement in
Insertmode - Toggle the suggestion manually by pressing
Ctrl+F - Accept a suggestion with
Tab - Accept the first line of a suggestion with
Shift+Tab - Control max text generation time
- Configure scope of context around the cursor
- Ring context with chunks from open and edited files and yanked text
- Supports very large contexts even on low-end hardware via smart context reuse
- Speculative FIM support
- Speculative Decoding support
- Display performance stats
-
vim-plug
Plug 'ggml-org/llama.vim' -
Vundle
cd ~/.vim/bundle git clone https://github.com/ggml-org/llama.vim
Then add
Plugin 'llama.vim'to your .vimrc in thevundle#begin()section. -
lazy.nvim
{ 'ggml-org/llama.vim', }
You can customize llama.vim by setting the g:llama_config variable.
Examples:
-
Disable the inline info:
" put before llama.vim loads let g:llama_config = { 'show_info': 0 }
-
Same thing but setting directly
let g:llama_config.show_info = v:false
-
Disable auto FIM (Fill-In-the-Middle) completion with lazy.nvim
{ 'ggml-org/llama.vim', init = function() vim.g.llama_config = { auto_fim = false, } end, } -
Changing accept line keymap
let g:llama_config.keymap_accept_full = "<C-S>"
Please refer to :help llama_config or the source
for the full list of options.
The plugin requires a llama.cpp server instance to be running at g:llama_config.endpoint.
brew install llama.cppEither build from source or use the latest binaries: https://github.com/ggml-org/llama.cpp/releases
Here are recommended settings, depending on the amount of VRAM that you have:
-
More than 16GB VRAM:
llama-server --fim-qwen-7b-default
-
Less than 16GB VRAM:
llama-server --fim-qwen-3b-default
-
Less than 8GB VRAM:
llama-server --fim-qwen-1.5b-default
Use :help llama for more details.
The plugin requires FIM-compatible models: HF collection
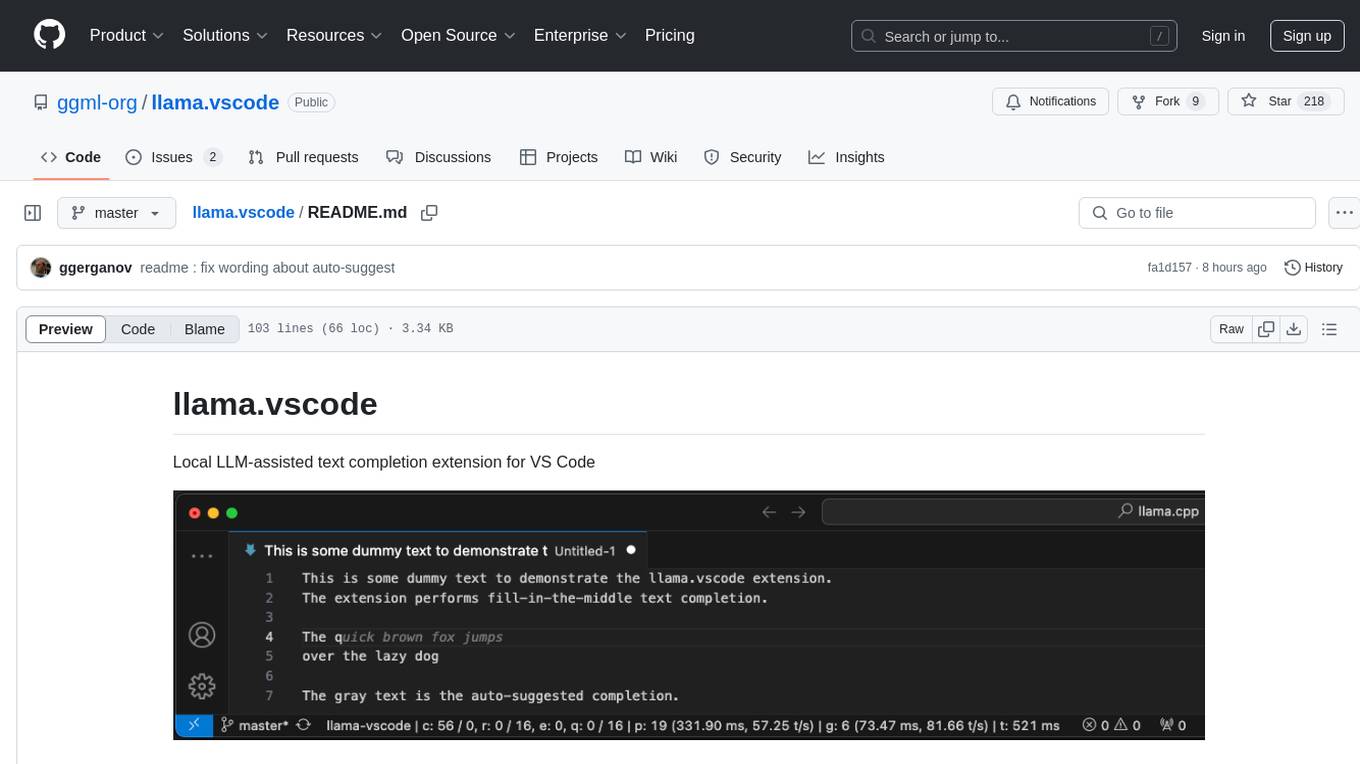
The orange text is the generated suggestion. The green text contains performance stats for the FIM request: the currently used context is 15186 tokens and the maximum is 32768. There are 30 chunks in the ring buffer with extra context (out of 64). So far, 1 chunk has been evicted in the current session and there are 0 chunks in queue. The newly computed prompt tokens for this request were 260 and the generated tokens were 24. It took 1245 ms to generate this suggestion after entering the letter c on the current line.
https://github.com/user-attachments/assets/1f1eb408-8ac2-4bd2-b2cf-6ab7d6816754
Demonstrates that the global context is accumulated and maintained across different files and showcases the overall latency when working in a large codebase.
The plugin aims to be very simple and lightweight and at the same time to provide high-quality and performant local FIM completions, even on consumer-grade hardware. Read more on how this is achieved in the following links:
- Initial implementation and techincal description: https://github.com/ggml-org/llama.cpp/pull/9787
- Classic Vim support: https://github.com/ggml-org/llama.cpp/pull/9995
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llama.vim
Similar Open Source Tools
llama.vim
llama.vim is a plugin that provides local LLM-assisted text completion for Vim users. It offers features such as auto-suggest on cursor movement, manual suggestion toggling, suggestion acceptance with Tab and Shift+Tab, control over text generation time, context configuration, ring context with chunks from open and edited files, and performance stats display. The plugin requires a llama.cpp server instance to be running and supports FIM-compatible models. It aims to be simple, lightweight, and provide high-quality and performant local FIM completions even on consumer-grade hardware.
llama3.java
Llama3.java is a practical Llama 3 inference tool implemented in a single Java file. It serves as the successor of llama2.java and is designed for testing and tuning compiler optimizations and features on the JVM, especially for the Graal compiler. The tool features a GGUF format parser, Llama 3 tokenizer, Grouped-Query Attention inference, support for Q8_0 and Q4_0 quantizations, fast matrix-vector multiplication routines using Java's Vector API, and a simple CLI with 'chat' and 'instruct' modes. Users can download quantized .gguf files from huggingface.co for model usage and can also manually quantize to pure 'Q4_0'. The tool requires Java 21+ and supports running from source or building a JAR file for execution. Performance benchmarks show varying tokens/s rates for different models and implementations on different hardware setups.
speech-to-speech
This repository implements a speech-to-speech cascaded pipeline with consecutive parts including Voice Activity Detection (VAD), Speech to Text (STT), Language Model (LM), and Text to Speech (TTS). It aims to provide a fully open and modular approach by leveraging models available on the Transformers library via the Hugging Face hub. The code is designed for easy modification, with each component implemented as a class. Users can run the pipeline either on a server/client approach or locally, with detailed setup and usage instructions provided in the readme.
hound
Hound is a security audit automation pipeline for AI-assisted code review that mirrors how expert auditors think, learn, and collaborate. It features graph-driven analysis, sessionized audits, provider-agnostic models, belief system and hypotheses, precise code grounding, and adaptive planning. The system employs a senior/junior auditor pattern where the Scout actively navigates the codebase and annotates knowledge graphs while the Strategist handles high-level planning and vulnerability analysis. Hound is optimized for small-to-medium sized projects like smart contract applications and is language-agnostic.
aidermacs
Aidermacs is an AI pair programming tool for Emacs that integrates Aider, a powerful open-source AI pair programming tool. It provides top performance on the SWE Bench, support for multi-file edits, real-time file synchronization, and broad language support. Aidermacs delivers an Emacs-centric experience with features like intelligent model selection, flexible terminal backend support, smarter syntax highlighting, enhanced file management, and streamlined transient menus. It thrives on community involvement, encouraging contributions, issue reporting, idea sharing, and documentation improvement.
detoxify
Detoxify is a library that provides trained models and code to predict toxic comments on 3 Jigsaw challenges: Toxic comment classification, Unintended Bias in Toxic comments, Multilingual toxic comment classification. It includes models like 'original', 'unbiased', and 'multilingual' trained on different datasets to detect toxicity and minimize bias. The library aims to help in stopping harmful content online by interpreting visual content in context. Users can fine-tune the models on carefully constructed datasets for research purposes or to aid content moderators in flagging out harmful content quicker. The library is built to be user-friendly and straightforward to use.

openedai-speech
OpenedAI Speech is a free, private text-to-speech server compatible with the OpenAI audio/speech API. It offers custom voice cloning and supports various models like tts-1 and tts-1-hd. Users can map their own piper voices and create custom cloned voices. The server provides multilingual support with XTTS voices and allows fixing incorrect sounds with regex. Recent changes include bug fixes, improved error handling, and updates for multilingual support. Installation can be done via Docker or manual setup, with usage instructions provided. Custom voices can be created using Piper or Coqui XTTS v2, with guidelines for preparing audio files. The tool is suitable for tasks like generating speech from text, creating custom voices, and multilingual text-to-speech applications.
podscript
Podscript is a tool designed to generate transcripts for podcasts and similar audio files using Language Model Models (LLMs) and Speech-to-Text (STT) APIs. It provides a command-line interface (CLI) for transcribing audio from various sources, including YouTube videos and audio files, using different speech-to-text services like Deepgram, Assembly AI, and Groq. Additionally, Podscript offers a web-based user interface for convenience. Users can configure keys for supported services, transcribe audio, and customize the transcription models. The tool aims to simplify the process of creating accurate transcripts for audio content.

can-ai-code
Can AI Code is a self-evaluating interview tool for AI coding models. It includes interview questions written by humans and tests taken by AI, inference scripts for common API providers and CUDA-enabled quantization runtimes, a Docker-based sandbox environment for validating untrusted Python and NodeJS code, and the ability to evaluate the impact of prompting techniques and sampling parameters on large language model (LLM) coding performance. Users can also assess LLM coding performance degradation due to quantization. The tool provides test suites for evaluating LLM coding performance, a webapp for exploring results, and comparison scripts for evaluations. It supports multiple interviewers for API and CUDA runtimes, with detailed instructions on running the tool in different environments. The repository structure includes folders for interviews, prompts, parameters, evaluation scripts, comparison scripts, and more.

react-native-fast-tflite
A high-performance TensorFlow Lite library for React Native that utilizes JSI for power, zero-copy ArrayBuffers for efficiency, and low-level C/C++ TensorFlow Lite core API for direct memory access. It supports swapping out TensorFlow Models at runtime and GPU-accelerated delegates like CoreML/Metal/OpenGL. Easy VisionCamera integration allows for seamless usage. Users can load TensorFlow Lite models, interpret input and output data, and utilize GPU Delegates for faster computation. The library is suitable for real-time object detection, image classification, and other machine learning tasks in React Native applications.
Pixel-Reasoner
Pixel Reasoner is a framework that introduces reasoning in the pixel-space for Vision-Language Models (VLMs), enabling them to directly inspect, interrogate, and infer from visual evidences. This enhances reasoning fidelity for visual tasks by equipping VLMs with visual reasoning operations like zoom-in and select-frame. The framework addresses challenges like model's imbalanced competence and reluctance to adopt pixel-space operations through a two-phase training approach involving instruction tuning and curiosity-driven reinforcement learning. With these visual operations, VLMs can interact with complex visual inputs such as images or videos to gather necessary information, leading to improved performance across visual reasoning benchmarks.
private-ml-sdk
Private ML SDK is a secure solution for running Large Language Models (LLMs) in Trusted Execution Environments (TEEs) using NVIDIA GPU TEE and Intel TDX technologies. It provides a tamper-proof data processing environment with secure execution, open-source builds, and nearly native speed performance. The system includes components like Secure Compute Environment, Remote Attestation, Secure Communication, and Key Management Service (KMS). Users can build TDX guest images, run Local KMS, and TDX guest images on TDX host machines with Nvidia GPUs. The SDK offers verifiable execution results and high performance for LLM workloads.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.
mem-kk-logic
This repository provides a PyTorch implementation of the paper 'On Memorization of Large Language Models in Logical Reasoning'. The work investigates memorization of Large Language Models (LLMs) in reasoning tasks, proposing a memorization metric and a logical reasoning benchmark based on Knights and Knaves puzzles. It shows that LLMs heavily rely on memorization to solve training puzzles but also improve generalization performance through fine-tuning. The repository includes code, data, and tools for evaluation, fine-tuning, probing model internals, and sample classification.
RA.Aid
RA.Aid is an AI software development agent powered by `aider` and advanced reasoning models like `o1`. It combines `aider`'s code editing capabilities with LangChain's agent-based task execution framework to provide an intelligent assistant for research, planning, and implementation of multi-step development tasks. It handles complex programming tasks by breaking them down into manageable steps, running shell commands automatically, and leveraging expert reasoning models like OpenAI's o1. RA.Aid is designed for everyday software development, offering features such as multi-step task planning, automated command execution, and the ability to handle complex programming tasks beyond single-shot code edits.
aicsimageio
AICSImageIO is a Python tool for Image Reading, Metadata Conversion, and Image Writing for Microscopy Images. It supports various file formats like OME-TIFF, TIFF, ND2, DV, CZI, LIF, PNG, GIF, and Bio-Formats. Users can read and write metadata and imaging data, work with different file systems like local paths, HTTP URLs, s3fs, and gcsfs. The tool provides functionalities for full image reading, delayed image reading, mosaic image reading, metadata reading, xarray coordinate plane attachment, cloud IO support, and saving to OME-TIFF. It also offers benchmarking and developer resources.
For similar tasks
llama.vim
llama.vim is a plugin that provides local LLM-assisted text completion for Vim users. It offers features such as auto-suggest on cursor movement, manual suggestion toggling, suggestion acceptance with Tab and Shift+Tab, control over text generation time, context configuration, ring context with chunks from open and edited files, and performance stats display. The plugin requires a llama.cpp server instance to be running and supports FIM-compatible models. It aims to be simple, lightweight, and provide high-quality and performant local FIM completions even on consumer-grade hardware.

bce-qianfan-sdk
The Qianfan SDK provides best practices for large model toolchains, allowing AI workflows and AI-native applications to access the Qianfan large model platform elegantly and conveniently. The core capabilities of the SDK include three parts: large model reasoning, large model training, and general and extension: * `Large model reasoning`: Implements interface encapsulation for reasoning of Yuyan (ERNIE-Bot) series, open source large models, etc., supporting dialogue, completion, Embedding, etc. * `Large model training`: Based on platform capabilities, it supports end-to-end large model training process, including training data, fine-tuning/pre-training, and model services. * `General and extension`: General capabilities include common AI development tools such as Prompt/Debug/Client. The extension capability is based on the characteristics of Qianfan to adapt to common middleware frameworks.
freeGPT
freeGPT provides free access to text and image generation models. It supports various models, including gpt3, gpt4, alpaca_7b, falcon_40b, prodia, and pollinations. The tool offers both asynchronous and non-asynchronous interfaces for text completion and image generation. It also features an interactive Discord bot that provides access to all the models in the repository. The tool is easy to use and can be integrated into various applications.

languagemodels
Language Models is a Python package that provides building blocks to explore large language models with as little as 512MB of RAM. It simplifies the usage of large language models from Python, ensuring all inference is performed locally to keep data private. The package includes features such as text completions, chat capabilities, code completions, external text retrieval, semantic search, and more. It outperforms Hugging Face transformers for CPU inference and offers sensible default models with varying parameters based on memory constraints. The package is suitable for learners and educators exploring the intersection of large language models with modern software development.
RWKV-Runner
RWKV Runner is a project designed to simplify the usage of large language models by automating various processes. It provides a lightweight executable program and is compatible with the OpenAI API. Users can deploy the backend on a server and use the program as a client. The project offers features like model management, VRAM configurations, user-friendly chat interface, WebUI option, parameter configuration, model conversion tool, download management, LoRA Finetune, and multilingual localization. It can be used for various tasks such as chat, completion, composition, and model inspection.

warc-gpt
WARC-GPT is an experimental retrieval augmented generation pipeline for web archive collections. It allows users to interact with WARC files, extract text, generate text embeddings, visualize embeddings, and interact with a web UI and API. The tool is highly customizable, supporting various LLMs, providers, and embedding models. Users can configure the application using environment variables, ingest WARC files, start the server, and interact with the web UI and API to search for content and generate text completions. WARC-GPT is designed for exploration and experimentation in exploring web archives using AI.
llama.vscode
llama.vscode is a local LLM-assisted text completion extension for Visual Studio Code. It provides auto-suggestions on input, allows accepting suggestions with shortcuts, and offers various features to enhance text completion. The extension is designed to be lightweight and efficient, enabling high-quality completions even on low-end hardware. Users can configure the scope of context around the cursor and control text generation time. It supports very large contexts and displays performance statistics for better user experience.
illume
Illume is a scriptable command line program designed for interfacing with an OpenAI-compatible LLM API. It acts as a unix filter, sending standard input to the LLM and streaming its response to standard output. Users can interact with the LLM through text editors like Vim or Emacs, enabling seamless communication with the AI model for various tasks.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.