
speech-to-speech
Speech To Speech: an effort for an open-sourced and modular GPT4-o
Stars: 3247
This repository implements a speech-to-speech cascaded pipeline with consecutive parts including Voice Activity Detection (VAD), Speech to Text (STT), Language Model (LM), and Text to Speech (TTS). It aims to provide a fully open and modular approach by leveraging models available on the Transformers library via the Hugging Face hub. The code is designed for easy modification, with each component implemented as a class. Users can run the pipeline either on a server/client approach or locally, with detailed setup and usage instructions provided in the readme.
README:
This repository implements a speech-to-speech cascaded pipeline consisting of the following parts:
- Voice Activity Detection (VAD)
- Speech to Text (STT)
- Language Model (LM)
- Text to Speech (TTS)
The pipeline provides a fully open and modular approach, with a focus on leveraging models available through the Transformers library on the Hugging Face hub. The code is designed for easy modification, and we already support device-specific and external library implementations:
VAD
STT
- Any Whisper model checkpoint on the Hugging Face Hub through Transformers 🤗, including whisper-large-v3 and distil-large-v3
- Lightning Whisper MLX
- Paraformer - FunASR
LLM
- Any instruction-following model on the Hugging Face Hub via Transformers 🤗
- mlx-lm
- OpenAI API
TTS
Clone the repository:
git clone https://github.com/huggingface/speech-to-speech.git
cd speech-to-speechInstall the required dependencies using uv:
uv pip install -r requirements.txtFor Mac users, use the requirements_mac.txt file instead:
uv pip install -r requirements_mac.txtIf you want to use Melo TTS, you also need to run:
python -m unidic downloadThe pipeline can be run in two ways:
- Server/Client approach: Models run on a server, and audio input/output are streamed from a client.
- Local approach: Runs locally.
-
Run the pipeline on the server:
python s2s_pipeline.py --recv_host 0.0.0.0 --send_host 0.0.0.0
-
Run the client locally to handle microphone input and receive generated audio:
python listen_and_play.py --host <IP address of your server>
- For optimal settings on Mac:
python s2s_pipeline.py --local_mac_optimal_settings
This setting:
- Adds
--device mpsto use MPS for all models.- Sets LightningWhisperMLX for STT
- Sets MLX LM for language model
- Sets MeloTTS for TTS
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
docker compose up
Leverage Torch Compile for Whisper and Parler-TTS. The usage of Parler-TTS allows for audio output streaming, futher reducing the overeall latency 🚀:
python s2s_pipeline.py \
--lm_model_name microsoft/Phi-3-mini-4k-instruct \
--stt_compile_mode reduce-overhead \
--tts_compile_mode default \
--recv_host 0.0.0.0 \
--send_host 0.0.0.0 For the moment, modes capturing CUDA Graphs are not compatible with streaming Parler-TTS (reduce-overhead, max-autotune).
The pipeline currently supports English, French, Spanish, Chinese, Japanese, and Korean.
Two use cases are considered:
-
Single-language conversation: Enforce the language setting using the
--languageflag, specifying the target language code (default is 'en'). -
Language switching: Set
--languageto 'auto'. In this case, Whisper detects the language for each spoken prompt, and the LLM is prompted with "Please reply to my message in ..." to ensure the response is in the detected language.
Please note that you must use STT and LLM checkpoints compatible with the target language(s). For the STT part, Parler-TTS is not yet multilingual (though that feature is coming soon! 🤗). In the meantime, you should use Melo (which supports English, French, Spanish, Chinese, Japanese, and Korean) or Chat-TTS.
For automatic language detection:
python s2s_pipeline.py \
--stt_model_name large-v3 \
--language auto \
--mlx_lm_model_name mlx-community/Meta-Llama-3.1-8B-Instruct \Or for one language in particular, chinese in this example
python s2s_pipeline.py \
--stt_model_name large-v3 \
--language zh \
--mlx_lm_model_name mlx-community/Meta-Llama-3.1-8B-Instruct \For automatic language detection:
python s2s_pipeline.py \
--local_mac_optimal_settings \
--device mps \
--stt_model_name large-v3 \
--language auto \
--mlx_lm_model_name mlx-community/Meta-Llama-3.1-8B-Instruct-4bit \Or for one language in particular, chinese in this example
python s2s_pipeline.py \
--local_mac_optimal_settings \
--device mps \
--stt_model_name large-v3 \
--language zh \
--mlx_lm_model_name mlx-community/Meta-Llama-3.1-8B-Instruct-4bit \NOTE: References for all the CLI arguments can be found directly in the arguments classes or by running
python s2s_pipeline.py -h.
See ModuleArguments class. Allows to set:
- a common
--device(if one wants each part to run on the same device) -
--modelocalorserver - chosen STT implementation
- chosen LM implementation
- chose TTS implementation
- logging level
See VADHandlerArguments class. Notably:
-
--thresh: Threshold value to trigger voice activity detection. -
--min_speech_ms: Minimum duration of detected voice activity to be considered speech. -
--min_silence_ms: Minimum length of silence intervals for segmenting speech, balancing sentence cutting and latency reduction.
model_name, torch_dtype, and device are exposed for each implementation of the Speech to Text, Language Model, and Text to Speech. Specify the targeted pipeline part with the corresponding prefix (e.g. stt, lm or tts, check the implementations' arguments classes for more details).
For example:
--lm_model_name google/gemma-2b-itOther generation parameters of the model's generate method can be set using the part's prefix + _gen_, e.g., --stt_gen_max_new_tokens 128. These parameters can be added to the pipeline part's arguments class if not already exposed.
@misc{Silero VAD,
author = {Silero Team},
title = {Silero VAD: pre-trained enterprise-grade Voice Activity Detector (VAD), Number Detector and Language Classifier},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/snakers4/silero-vad}},
commit = {insert_some_commit_here},
email = {hello@silero.ai}
}@misc{gandhi2023distilwhisper,
title={Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling},
author={Sanchit Gandhi and Patrick von Platen and Alexander M. Rush},
year={2023},
eprint={2311.00430},
archivePrefix={arXiv},
primaryClass={cs.CL}
}@misc{lacombe-etal-2024-parler-tts,
author = {Yoach Lacombe and Vaibhav Srivastav and Sanchit Gandhi},
title = {Parler-TTS},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/huggingface/parler-tts}}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for speech-to-speech
Similar Open Source Tools
speech-to-speech
This repository implements a speech-to-speech cascaded pipeline with consecutive parts including Voice Activity Detection (VAD), Speech to Text (STT), Language Model (LM), and Text to Speech (TTS). It aims to provide a fully open and modular approach by leveraging models available on the Transformers library via the Hugging Face hub. The code is designed for easy modification, with each component implemented as a class. Users can run the pipeline either on a server/client approach or locally, with detailed setup and usage instructions provided in the readme.
openai-edge-tts
This project provides a local, OpenAI-compatible text-to-speech (TTS) API using `edge-tts`. It emulates the OpenAI TTS endpoint (`/v1/audio/speech`), enabling users to generate speech from text with various voice options and playback speeds, just like the OpenAI API. `edge-tts` uses Microsoft Edge's online text-to-speech service, making it completely free. The project supports multiple audio formats, adjustable playback speed, and voice selection options, providing a flexible and customizable TTS solution for users.

VITA
VITA is an open-source interactive omni multimodal Large Language Model (LLM) capable of processing video, image, text, and audio inputs simultaneously. It stands out with features like Omni Multimodal Understanding, Non-awakening Interaction, and Audio Interrupt Interaction. VITA can respond to user queries without a wake-up word, track and filter external queries in real-time, and handle various query inputs effectively. The model utilizes state tokens and a duplex scheme to enhance the multimodal interactive experience.
effective_llm_alignment
This is a super customizable, concise, user-friendly, and efficient toolkit for training and aligning LLMs. It provides support for various methods such as SFT, Distillation, DPO, ORPO, CPO, SimPO, SMPO, Non-pair Reward Modeling, Special prompts basket format, Rejection Sampling, Scoring using RM, Effective FAISS Map-Reduce Deduplication, LLM scoring using RM, NER, CLIP, Classification, and STS. The toolkit offers key libraries like PyTorch, Transformers, TRL, Accelerate, FSDP, DeepSpeed, and tools for result logging with wandb or clearml. It allows mixing datasets, generation and logging in wandb/clearml, vLLM batched generation, and aligns models using the SMPO method.

LEANN
LEANN is an innovative vector database that democratizes personal AI, transforming your laptop into a powerful RAG system that can index and search through millions of documents using 97% less storage than traditional solutions without accuracy loss. It achieves this through graph-based selective recomputation and high-degree preserving pruning, computing embeddings on-demand instead of storing them all. LEANN allows semantic search of file system, emails, browser history, chat history, codebase, or external knowledge bases on your laptop with zero cloud costs and complete privacy. It is a drop-in semantic search MCP service fully compatible with Claude Code, enabling intelligent retrieval without changing your workflow.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.

lionagi
LionAGI is a robust framework for orchestrating multi-step AI operations with precise control. It allows users to bring together multiple models, advanced reasoning, tool integrations, and custom validations in a single coherent pipeline. The framework is structured, expandable, controlled, and transparent, offering features like real-time logging, message introspection, and tool usage tracking. LionAGI supports advanced multi-step reasoning with ReAct, integrates with Anthropic's Model Context Protocol, and provides observability and debugging tools. Users can seamlessly orchestrate multiple models, integrate with Claude Code CLI SDK, and leverage a fan-out fan-in pattern for orchestration. The framework also offers optional dependencies for additional functionalities like reader tools, local inference support, rich output formatting, database support, and graph visualization.
Shellsage
Shell Sage is an intelligent terminal companion and AI-powered terminal assistant that enhances the terminal experience with features like local and cloud AI support, context-aware error diagnosis, natural language to command translation, and safe command execution workflows. It offers interactive workflows, supports various API providers, and allows for custom model selection. Users can configure the tool for local or API mode, select specific models, and switch between modes easily. Currently in alpha development, Shell Sage has known limitations like limited Windows support and occasional false positives in error detection. The roadmap includes improvements like better context awareness, Windows PowerShell integration, Tmux integration, and CI/CD error pattern database.

plexe
Plexe is a tool that allows users to create machine learning models by describing them in plain language. Users can explain their requirements, provide a dataset, and the AI-powered system will build a fully functional model through an automated agentic approach. It supports multiple AI agents and model building frameworks like XGBoost, CatBoost, and Keras. Plexe also provides Docker images with pre-configured environments, YAML configuration for customization, and support for multiple LiteLLM providers. Users can visualize experiment results using the built-in Streamlit dashboard and extend Plexe's functionality through custom integrations.

req_llm
ReqLLM is a Req-based library for LLM interactions, offering a unified interface to AI providers through a plugin-based architecture. It brings composability and middleware advantages to LLM interactions, with features like auto-synced providers/models, typed data structures, ergonomic helpers, streaming capabilities, usage & cost extraction, and a plugin-based provider system. Users can easily generate text, structured data, embeddings, and track usage costs. The tool supports various AI providers like Anthropic, OpenAI, Groq, Google, and xAI, and allows for easy addition of new providers. ReqLLM also provides API key management, detailed documentation, and a roadmap for future enhancements.
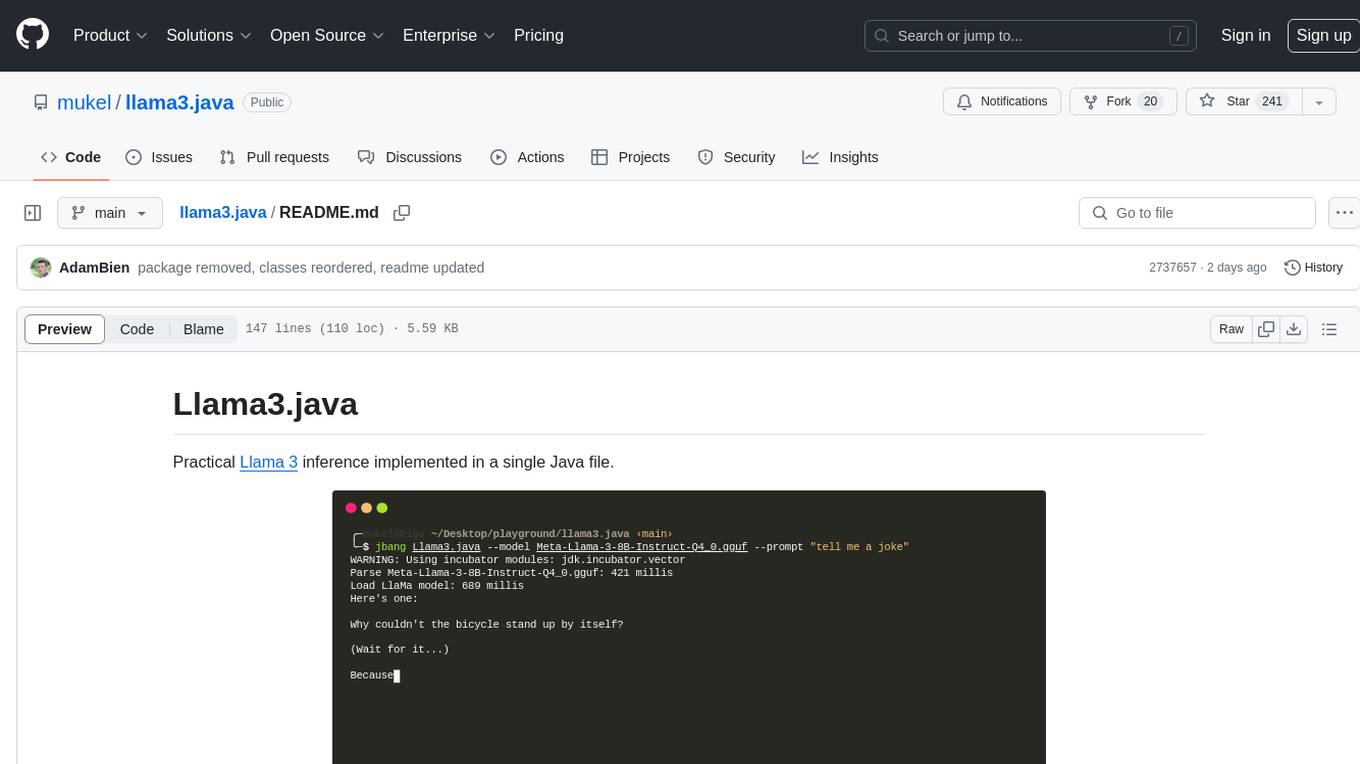
llama3.java
Llama3.java is a practical Llama 3 inference tool implemented in a single Java file. It serves as the successor of llama2.java and is designed for testing and tuning compiler optimizations and features on the JVM, especially for the Graal compiler. The tool features a GGUF format parser, Llama 3 tokenizer, Grouped-Query Attention inference, support for Q8_0 and Q4_0 quantizations, fast matrix-vector multiplication routines using Java's Vector API, and a simple CLI with 'chat' and 'instruct' modes. Users can download quantized .gguf files from huggingface.co for model usage and can also manually quantize to pure 'Q4_0'. The tool requires Java 21+ and supports running from source or building a JAR file for execution. Performance benchmarks show varying tokens/s rates for different models and implementations on different hardware setups.
uLoopMCP
uLoopMCP is a Unity integration tool designed to let AI drive your Unity project forward with minimal human intervention. It provides a 'self-hosted development loop' where an AI can compile, run tests, inspect logs, and fix issues using tools like compile, run-tests, get-logs, and clear-console. It also allows AI to operate the Unity Editor itself—creating objects, calling menu items, inspecting scenes, and refining UI layouts from screenshots via tools like execute-dynamic-code, execute-menu-item, and capture-window. The tool enables AI-driven development loops to run autonomously inside existing Unity projects.

lionagi
LionAGI is a powerful intelligent workflow automation framework that introduces advanced ML models into any existing workflows and data infrastructure. It can interact with almost any model, run interactions in parallel for most models, produce structured pydantic outputs with flexible usage, automate workflow via graph based agents, use advanced prompting techniques, and more. LionAGI aims to provide a centralized agent-managed framework for "ML-powered tools coordination" and to dramatically lower the barrier of entries for creating use-case/domain specific tools. It is designed to be asynchronous only and requires Python 3.10 or higher.
wikipedia-mcp
The Wikipedia MCP Server is a Model Context Protocol (MCP) server that provides real-time access to Wikipedia information for Large Language Models (LLMs). It allows AI assistants to retrieve accurate and up-to-date information from Wikipedia to enhance their responses. The server offers features such as searching Wikipedia, retrieving article content, getting article summaries, extracting specific sections, discovering links within articles, finding related topics, supporting multiple languages and country codes, optional caching for improved performance, and compatibility with Google ADK agents and other AI frameworks. Users can install the server using pipx, Smithery, PyPI, virtual environment, or from source. The server can be run with various options for transport protocol, language, country/locale, caching, access token, and more. It also supports Docker and Kubernetes deployment. The server provides MCP tools for interacting with Wikipedia, such as searching articles, getting article content, summaries, sections, links, coordinates, related topics, and extracting key facts. It also supports country/locale codes and language variants for languages like Chinese, Serbian, Kurdish, and Norwegian. The server includes example prompts for querying Wikipedia and provides MCP resources for interacting with Wikipedia through MCP endpoints. The project structure includes main packages, API implementation, core functionality, utility functions, and a comprehensive test suite for reliability and functionality testing.
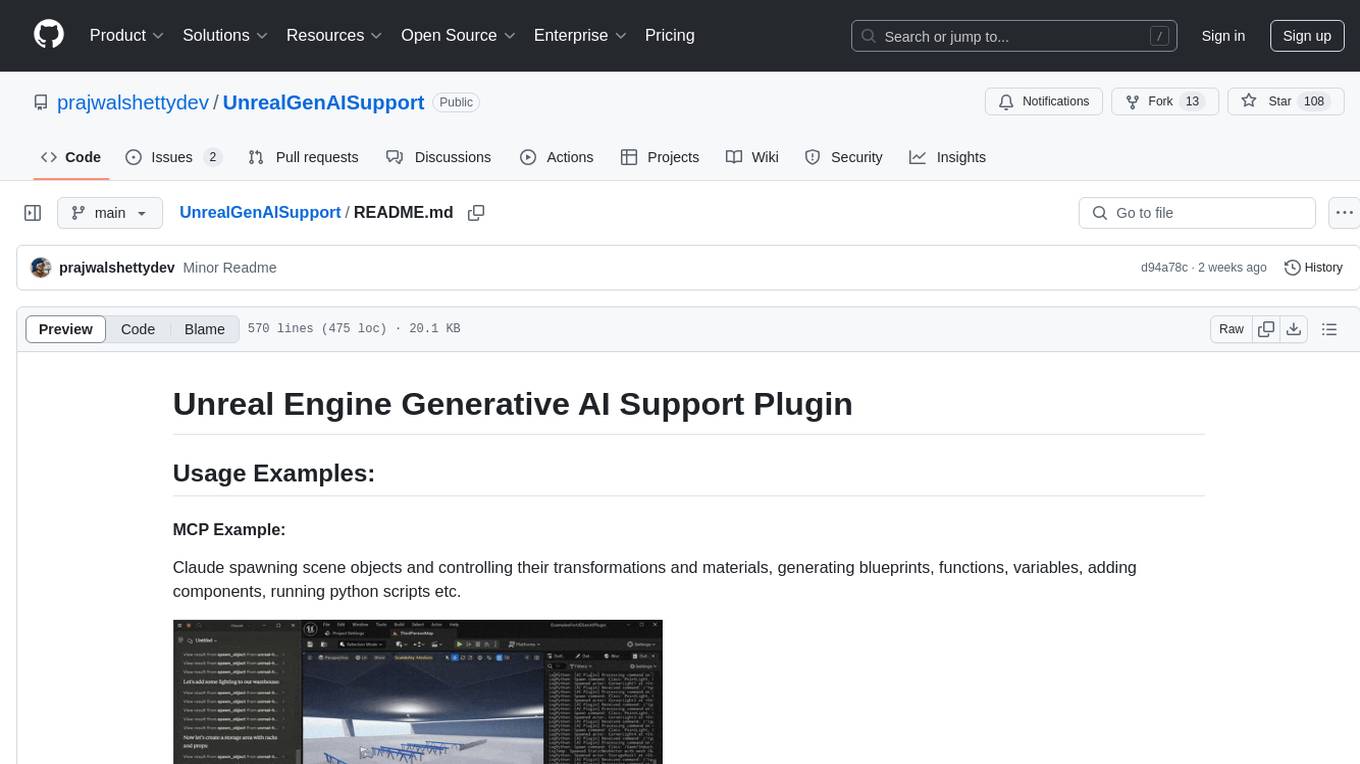
UnrealGenAISupport
The Unreal Engine Generative AI Support Plugin is a tool designed to integrate various cutting-edge LLM/GenAI models into Unreal Engine for game development. It aims to simplify the process of using AI models for game development tasks, such as controlling scene objects, generating blueprints, running Python scripts, and more. The plugin currently supports models from organizations like OpenAI, Anthropic, XAI, Google Gemini, Meta AI, Deepseek, and Baidu. It provides features like API support, model control, generative AI capabilities, UI generation, project file management, and more. The plugin is still under development but offers a promising solution for integrating AI models into game development workflows.

evalchemy
Evalchemy is a unified and easy-to-use toolkit for evaluating language models, focusing on post-trained models. It integrates multiple existing benchmarks such as RepoBench, AlpacaEval, and ZeroEval. Key features include unified installation, parallel evaluation, simplified usage, and results management. Users can run various benchmarks with a consistent command-line interface and track results locally or integrate with a database for systematic tracking and leaderboard submission.
For similar tasks

open-llms
Open LLMs is a repository containing various Large Language Models licensed for commercial use. It includes models like T5, GPT-NeoX, UL2, Bloom, Cerebras-GPT, Pythia, Dolly, and more. These models are designed for tasks such as transfer learning, language understanding, chatbot development, code generation, and more. The repository provides information on release dates, checkpoints, papers/blogs, parameters, context length, and licenses for each model. Contributions to the repository are welcome, and it serves as a resource for exploring the capabilities of different language models.
speech-to-speech
This repository implements a speech-to-speech cascaded pipeline with consecutive parts including Voice Activity Detection (VAD), Speech to Text (STT), Language Model (LM), and Text to Speech (TTS). It aims to provide a fully open and modular approach by leveraging models available on the Transformers library via the Hugging Face hub. The code is designed for easy modification, with each component implemented as a class. Users can run the pipeline either on a server/client approach or locally, with detailed setup and usage instructions provided in the readme.

nexa-sdk
Nexa SDK is a comprehensive toolkit supporting ONNX and GGML models for text generation, image generation, vision-language models (VLM), and text-to-speech (TTS) capabilities. It offers an OpenAI-compatible API server with JSON schema mode and streaming support, along with a user-friendly Streamlit UI. Users can run Nexa SDK on any device with Python environment, with GPU acceleration supported. The toolkit provides model support, conversion engine, inference engine for various tasks, and differentiating features from other tools.
text2text
Text2Text is a comprehensive language modeling toolkit that offers a wide range of functionalities for text processing and generation. It provides tools for tokenization, embedding, TF-IDF calculations, BM25 scoring, indexing, translation, data augmentation, distance measurement, training/finetuning models, language identification, and serving models via a web server. The toolkit is designed to be user-friendly and efficient, offering a variety of features for natural language processing tasks.

VoiceStreamAI
VoiceStreamAI is a Python 3-based server and JavaScript client solution for near-realtime audio streaming and transcription using WebSocket. It employs Huggingface's Voice Activity Detection (VAD) and OpenAI's Whisper model for accurate speech recognition. The system features real-time audio streaming, modular design for easy integration of VAD and ASR technologies, customizable audio chunk processing strategies, support for multilingual transcription, and secure sockets support. It uses a factory and strategy pattern implementation for flexible component management and provides a unit testing framework for robust development.
RealtimeSTT_LLM_TTS
RealtimeSTT is an easy-to-use, low-latency speech-to-text library for realtime applications. It listens to the microphone and transcribes voice into text, making it ideal for voice assistants and applications requiring fast and precise speech-to-text conversion. The library utilizes Voice Activity Detection, Realtime Transcription, and Wake Word Activation features. It supports GPU-accelerated transcription using PyTorch with CUDA support. RealtimeSTT offers various customization options for different parameters to enhance user experience and performance. The library is designed to provide a seamless experience for developers integrating speech-to-text functionality into their applications.
echosharp
EchoSharp is an open-source library designed for near-real-time audio processing, orchestrating different AI models seamlessly for various audio analysis scopes. It focuses on flexibility and performance, allowing near-real-time Transcription and Translation by integrating components for Speech-to-Text and Voice Activity Detection. With interchangeable components, easy orchestration, and first-party components like Whisper.net, SileroVad, OpenAI Whisper, AzureAI SpeechServices, WebRtcVadSharp, Onnx.Whisper, and Onnx.Sherpa, EchoSharp provides efficient audio analysis solutions for developers.

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.