
llama.vscode
VS Code extension for LLM-assisted code/text completion
Stars: 966
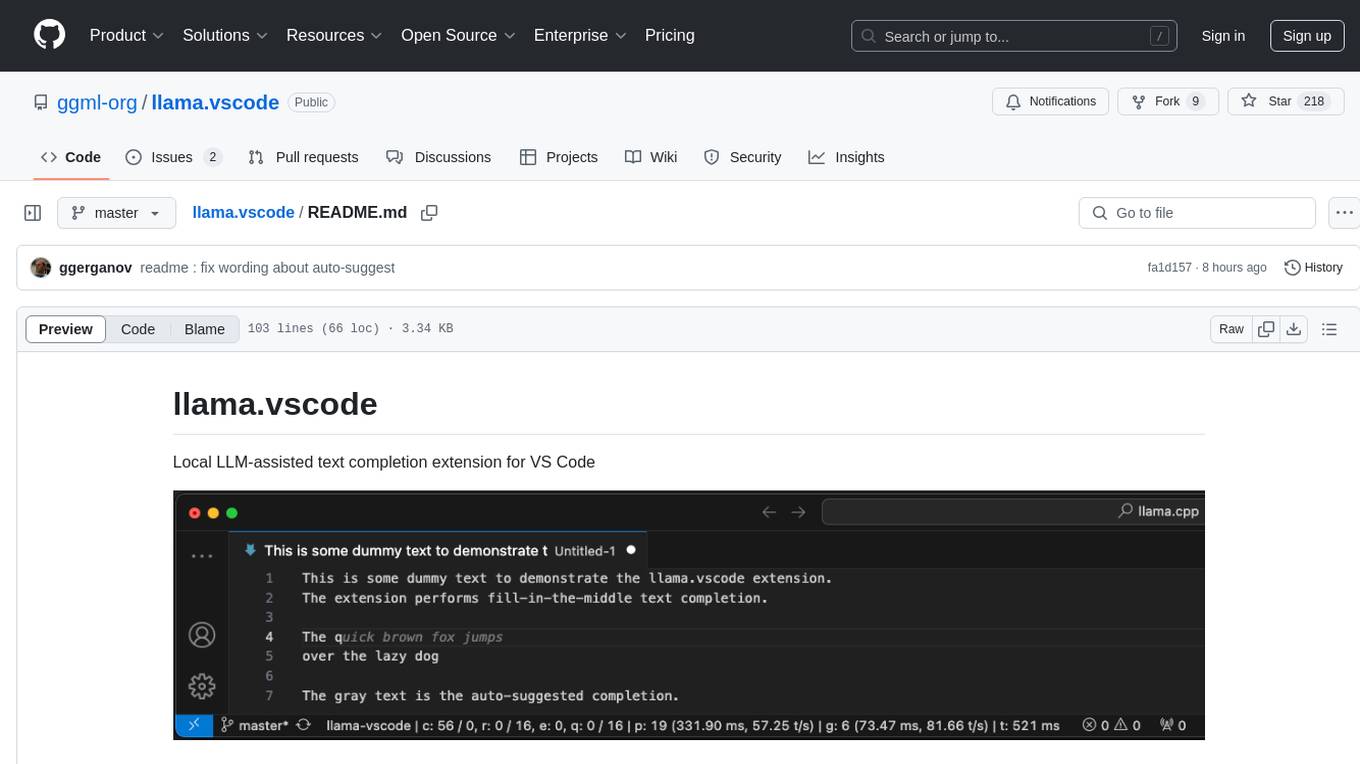
llama.vscode is a local LLM-assisted text completion extension for Visual Studio Code. It provides auto-suggestions on input, allows accepting suggestions with shortcuts, and offers various features to enhance text completion. The extension is designed to be lightweight and efficient, enabling high-quality completions even on low-end hardware. Users can configure the scope of context around the cursor and control text generation time. It supports very large contexts and displays performance statistics for better user experience.
README:
Local LLM-assisted text completion, chat with AI and agentic coding extension for VS Code
- Auto-suggest on input
- Accept a suggestion with
Tab - Accept the first line of a suggestion with
Shift + Tab - Accept the next word with
Ctrl/Cmd + Right - Toggle the suggestion manually by pressing
Ctrl + L - Control max text generation time
- Configure scope of context around the cursor
- Ring context with chunks from open and edited files and yanked text
- Supports very large contexts even on low-end hardware via smart context reuse
- Display performance stats
- Llama Agent for agentic coding
- Add/remove/export/import for models - completion, chat, embeddings and tools
- Model selection - for completion, chat, embeddings and tools
- Env (group of models) concept introduced. Selecting/Deselecting env selects/deselects all the models in it
- Add/remove/export/import for env
- Predefined models (including OpenAI gpt-oss 20B added as a local one)
- Predefined envs for different use cases - only completion, chat + completion, chat + agent, loccal full package (with gpt-oss 20B), etc.
- MCP tools selection for the agent (from VS Code installed MCP Servers)
- Search and download models from Huggingface directly from llama-vscode
Install the llama-vscode extension from the VS Code extension marketplace:
Note: also available at Open VSX
Show llama-vscode menu by clicking on llama-vscode in the status bar or Ctrl+Shift+M and select "Install/Upgrade llama.cpp". This will install llama.cpp automatically for Mac and Windows. For Linux get the latest binaries and add the bin folder to the path.
Once you have llama.cpp installed, you can select env for your needs from llama-vscode menu "Select/start env..."
Below are some details how to install llama.cpp manually (if you prefer it).
brew install llama.cppwinget install llama.cppEither use the latest binaries or build llama.cpp from source. For more information how to run the llama.cpp server, please refer to the Wiki.
Here are recommended settings, depending on the amount of VRAM that you have:
-
More than 16GB VRAM:
llama-server --fim-qwen-7b-default
-
Less than 16GB VRAM:
llama-server --fim-qwen-3b-default
-
Less than 8GB VRAM:
llama-server --fim-qwen-1.5b-default
CPU-only configs
These are llama-server settings for CPU-only hardware. Note that the quality will be significantly lower:
llama-server \
-hf ggml-org/Qwen2.5-Coder-1.5B-Q8_0-GGUF \
--port 8012 -ub 512 -b 512 --ctx-size 0 --cache-reuse 256llama-server \
-hf ggml-org/Qwen2.5-Coder-0.5B-Q8_0-GGUF \
--port 8012 -ub 1024 -b 1024 --ctx-size 0 --cache-reuse 256You can use any other FIM-compatible model that your system can handle. By default, the models downloaded with the -hf flag are stored in:
- Mac OS:
~/Library/Caches/llama.cpp/ - Linux:
~/.cache/llama.cpp - Windows:
LOCALAPPDATA
The plugin requires FIM-compatible models: HF collection
The extension includes Llama Agent
- Llama Agent UI in Explorer view
- Works with local models - gpt-oss 20B is the best choice for now
- Could work with external models (for example from OpenRouter)
- MCP Support - could use the tools from the MCP Servers, which are installed and started in VS Code
- 9 internal tools available for use
- custom_tool - returns the content of a file or a web page
- custom_eval_tool - write your own tool in javascript (function with input and return value string)
- Attach the selection to the context
- Configure maximum loops for Llama Agent
- Open Llama Agent with Ctrl+Shift+A or from llama-vscode menu "Show Llama Agent"
- Select Env with an agent if you haven't done it before.
- Write a query and attach files with the @ button if needed
More details(https://github.com/ggml-org/llama.vscode/wiki)
Speculative FIMs running locally on a M2 Studio:
https://github.com/user-attachments/assets/cab99b93-4712-40b4-9c8d-cf86e98d4482
The extension aims to be very simple and lightweight and at the same time to provide high-quality and performant local FIM completions, even on consumer-grade hardware.
- The initial implementation was done by Ivaylo Gardev @igardev using the llama.vim plugin as a reference
- Techincal description: https://github.com/ggerganov/llama.cpp/pull/9787
- Vim/Neovim: https://github.com/ggml-org/llama.vim
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llama.vscode
Similar Open Source Tools
llama.vscode
llama.vscode is a local LLM-assisted text completion extension for Visual Studio Code. It provides auto-suggestions on input, allows accepting suggestions with shortcuts, and offers various features to enhance text completion. The extension is designed to be lightweight and efficient, enabling high-quality completions even on low-end hardware. Users can configure the scope of context around the cursor and control text generation time. It supports very large contexts and displays performance statistics for better user experience.
ModelGenerator
AIDO.ModelGenerator is a software stack designed for developing AI-driven Digital Organisms. It enables researchers to adapt pretrained models and generate finetuned models for various tasks. The framework supports rapid prototyping with experiments like applying pre-trained models to new data, developing finetuning tasks, benchmarking models, and testing new architectures. Built on PyTorch, HuggingFace, and Lightning, it facilitates seamless integration with these ecosystems. The tool caters to cross-disciplinary teams in ML & Bio, offering installation, usage, tutorials, and API reference in its documentation.

PowerInfer
PowerInfer is a high-speed Large Language Model (LLM) inference engine designed for local deployment on consumer-grade hardware, leveraging activation locality to optimize efficiency. It features a locality-centric design, hybrid CPU/GPU utilization, easy integration with popular ReLU-sparse models, and support for various platforms. PowerInfer achieves high speed with lower resource demands and is flexible for easy deployment and compatibility with existing models like Falcon-40B, Llama2 family, ProSparse Llama2 family, and Bamboo-7B.
DALM
The DALM (Domain Adapted Language Modeling) toolkit is designed to unify general LLMs with vector stores to ground AI systems in efficient, factual domains. It provides developers with tools to build on top of Arcee's open source Domain Pretrained LLMs, enabling organizations to deeply tailor AI according to their unique intellectual property and worldview. The toolkit contains code for fine-tuning a fully differential Retrieval Augmented Generation (RAG-end2end) architecture, incorporating in-batch negative concept alongside RAG's marginalization for efficiency. It includes training scripts for both retriever and generator models, evaluation scripts, data processing codes, and synthetic data generation code.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.

Easy-Translate
Easy-Translate is a script designed for translating large text files with a single command. It supports various models like M2M100, NLLB200, SeamlessM4T, LLaMA, and Bloom. The tool is beginner-friendly and offers seamless and customizable features for advanced users. It allows acceleration on CPU, multi-CPU, GPU, multi-GPU, and TPU, with support for different precisions and decoding strategies. Easy-Translate also provides an evaluation script for translations. Built on HuggingFace's Transformers and Accelerate library, it supports prompt usage and loading huge models efficiently.
ComfyUI-BlenderAI-node
ComfyUI-BlenderAI-node is an addon for Blender that allows users to convert ComfyUI nodes into Blender nodes seamlessly. It offers features such as converting nodes, editing launch arguments, drawing masks with Grease pencil, and more. Users can queue batch processing, use node tree presets, and model preview images. The addon enables users to input or replace 3D models in Blender and output controlnet images using composite. It provides a workflow showcase with presets for camera input, AI-generated mesh import, composite depth channel, character bone editing, and more.
open-computer-use
Open Computer Use is a secure cloud Linux computer powered by E2B Desktop Sandbox and controlled by open-source LLMs. It allows users to operate the computer via keyboard, mouse, and shell commands, live stream the display of the sandbox on the client computer, and pause or prompt the agent at any time. The tool is designed to work with any operating system and supports integration with various LLMs and providers following the OpenAI API specification.

ProX
ProX is a lm-based data refinement framework that automates the process of cleaning and improving data used in pre-training large language models. It offers better performance, domain flexibility, efficiency, and cost-effectiveness compared to traditional methods. The framework has been shown to improve model performance by over 2% and boost accuracy by up to 20% in tasks like math. ProX is designed to refine data at scale without the need for manual adjustments, making it a valuable tool for data preprocessing in natural language processing tasks.
LafTools
LafTools is a privacy-first, self-hosted, fully open source toolbox designed for programmers. It offers a wide range of tools, including code generation, translation, encryption, compression, data analysis, and more. LafTools is highly integrated with a productive UI and supports full GPT-alike functionality. It is available as Docker images and portable edition, with desktop edition support planned for the future.
mac-studio-server
This repository provides configuration and scripts for running Ollama LLM server on Apple Silicon Macs in headless mode, optimized for performance and resource usage. It includes features like automatic startup, system resource optimization, external network access, proper logging setup, and SSH-based remote management. Users can customize the Ollama service configuration and enable optional GPU memory optimization and Docker autostart for container applications. The installation process disables unnecessary system services, configures power management, and optimizes for background operation while maintaining Screen Sharing capability for remote management. Performance considerations focus on reducing memory usage, disabling GUI-related services, minimizing background processes, preventing sleep/hibernation, and optimizing for headless operation.
docetl
DocETL is a tool for creating and executing data processing pipelines, especially suited for complex document processing tasks. It offers a low-code, declarative YAML interface to define LLM-powered operations on complex data. Ideal for maximizing correctness and output quality for semantic processing on a collection of data, representing complex tasks via map-reduce, maximizing LLM accuracy, handling long documents, and automating task retries based on validation criteria.
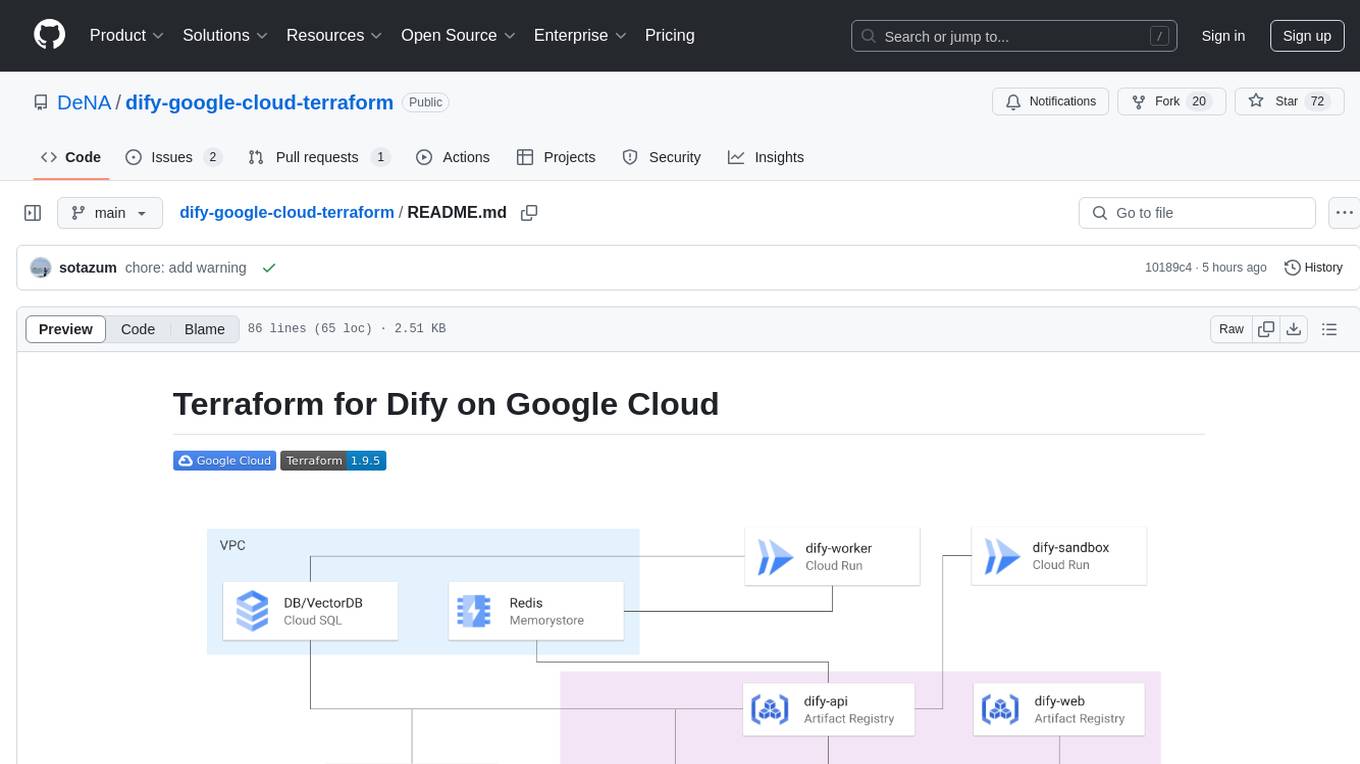
dify-google-cloud-terraform
This repository provides Terraform configurations to automatically set up Google Cloud resources and deploy Dify in a highly available configuration. It includes features such as serverless hosting, auto-scaling, and data persistence. Users need a Google Cloud account, Terraform, and gcloud CLI installed to use this tool. The configuration involves setting environment-specific values and creating a GCS bucket for managing Terraform state. The tool allows users to initialize Terraform, create Artifact Registry repository, build and push container images, plan and apply Terraform changes, and cleanup resources when needed.

TokenFormer
TokenFormer is a fully attention-based neural network architecture that leverages tokenized model parameters to enhance architectural flexibility. It aims to maximize the flexibility of neural networks by unifying token-token and token-parameter interactions through the attention mechanism. The architecture allows for incremental model scaling and has shown promising results in language modeling and visual modeling tasks. The codebase is clean, concise, easily readable, state-of-the-art, and relies on minimal dependencies.
SiLLM
SiLLM is a toolkit that simplifies the process of training and running Large Language Models (LLMs) on Apple Silicon by leveraging the MLX framework. It provides features such as LLM loading, LoRA training, DPO training, a web app for a seamless chat experience, an API server with OpenAI compatible chat endpoints, and command-line interface (CLI) scripts for chat, server, LoRA fine-tuning, DPO fine-tuning, conversion, and quantization.

ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
For similar tasks

bce-qianfan-sdk
The Qianfan SDK provides best practices for large model toolchains, allowing AI workflows and AI-native applications to access the Qianfan large model platform elegantly and conveniently. The core capabilities of the SDK include three parts: large model reasoning, large model training, and general and extension: * `Large model reasoning`: Implements interface encapsulation for reasoning of Yuyan (ERNIE-Bot) series, open source large models, etc., supporting dialogue, completion, Embedding, etc. * `Large model training`: Based on platform capabilities, it supports end-to-end large model training process, including training data, fine-tuning/pre-training, and model services. * `General and extension`: General capabilities include common AI development tools such as Prompt/Debug/Client. The extension capability is based on the characteristics of Qianfan to adapt to common middleware frameworks.
freeGPT
freeGPT provides free access to text and image generation models. It supports various models, including gpt3, gpt4, alpaca_7b, falcon_40b, prodia, and pollinations. The tool offers both asynchronous and non-asynchronous interfaces for text completion and image generation. It also features an interactive Discord bot that provides access to all the models in the repository. The tool is easy to use and can be integrated into various applications.

languagemodels
Language Models is a Python package that provides building blocks to explore large language models with as little as 512MB of RAM. It simplifies the usage of large language models from Python, ensuring all inference is performed locally to keep data private. The package includes features such as text completions, chat capabilities, code completions, external text retrieval, semantic search, and more. It outperforms Hugging Face transformers for CPU inference and offers sensible default models with varying parameters based on memory constraints. The package is suitable for learners and educators exploring the intersection of large language models with modern software development.
RWKV-Runner
RWKV Runner is a project designed to simplify the usage of large language models by automating various processes. It provides a lightweight executable program and is compatible with the OpenAI API. Users can deploy the backend on a server and use the program as a client. The project offers features like model management, VRAM configurations, user-friendly chat interface, WebUI option, parameter configuration, model conversion tool, download management, LoRA Finetune, and multilingual localization. It can be used for various tasks such as chat, completion, composition, and model inspection.

warc-gpt
WARC-GPT is an experimental retrieval augmented generation pipeline for web archive collections. It allows users to interact with WARC files, extract text, generate text embeddings, visualize embeddings, and interact with a web UI and API. The tool is highly customizable, supporting various LLMs, providers, and embedding models. Users can configure the application using environment variables, ingest WARC files, start the server, and interact with the web UI and API to search for content and generate text completions. WARC-GPT is designed for exploration and experimentation in exploring web archives using AI.

llama.vim
llama.vim is a plugin that provides local LLM-assisted text completion for Vim users. It offers features such as auto-suggest on cursor movement, manual suggestion toggling, suggestion acceptance with Tab and Shift+Tab, control over text generation time, context configuration, ring context with chunks from open and edited files, and performance stats display. The plugin requires a llama.cpp server instance to be running and supports FIM-compatible models. It aims to be simple, lightweight, and provide high-quality and performant local FIM completions even on consumer-grade hardware.
llama.vscode
llama.vscode is a local LLM-assisted text completion extension for Visual Studio Code. It provides auto-suggestions on input, allows accepting suggestions with shortcuts, and offers various features to enhance text completion. The extension is designed to be lightweight and efficient, enabling high-quality completions even on low-end hardware. Users can configure the scope of context around the cursor and control text generation time. It supports very large contexts and displays performance statistics for better user experience.
illume
Illume is a scriptable command line program designed for interfacing with an OpenAI-compatible LLM API. It acts as a unix filter, sending standard input to the LLM and streaming its response to standard output. Users can interact with the LLM through text editors like Vim or Emacs, enabling seamless communication with the AI model for various tasks.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.