
mikupad
LLM Frontend in a single html file
Stars: 300

mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.
README:
mikupad is a user-friendly, browser-based interface for interacting with language models. It's built with ReactJS and supports various text generation backends, all within a single HTML file.
- Multiple Backends: Supports llama.cpp, koboldcpp, AI Horde, and any OpenAI Compatible API.
- Session Persistence: Your prompt is automatically saved and restored, allowing you to continue seamlessly across multiple sessions. Import and export sessions for sharing or maintaining backups.
- Optional Server: Can be hosted on a local Node.js server, enabling database access remotely or across your local network.
-
Persistent Context:
- Memory: Seamlessly inject a text of your choice at the beginning of the context.
- Author's Note: Seamlessly inject a text of your choice at the end of the context, with adjustable depth.
- World Info: Dynamically include extra information in the context, triggered by specific keywords.
- Prediction Undo/Redo: Easily experiment and refine your generated text with the ability to undo and redo predictions.
-
Token Probability: Hover over any token to reveal the top 10 most probable tokens at that point. Click on a probability to regenerate the text from that specific token.
- If you're using oobabooga, make sure to use an _HF sampler for this feature to function properly.
- If you're using koboldcpp, token probabilities are only available with Token Streaming disabled.
- Logit Bias: Fine-tune the generation process by adjusting the likelihood bias of specific tokens on-the-fly.
-
Completion/Chat Modes:
- Completion: Have the language model directly continue your prompt.
- Chat: Mikupad simplifies using instruct models. It automatically adds the right delimiters when you start or stop generating, based on your selected template. This also structures your prompt into messages, making it compatible with the Chat Completions API (for OpenAI-compatible backends).
- Themes: Customize your environment by choosing from a variety of themes.
You can easily run mikupad by opening the mikupad.html file in your web browser. No additional installation is required. Choose your preferred backend and start generating text!
git clone https://github.com/lmg-anon/mikupad.git
cd mikupad
open mikupad.htmlTo use mikupad fully offline, run the provided compile script or download the pre-compiled mikupad_compiled.html file from Releases.
You can also try it on GitHub Pages.
Contributions from the open-source community are welcome. Whether it's fixing a bug, adding a feature, or improving the documentation, your contributions are greatly appreciated. To contribute to mikupad, follow these steps:
- Fork the repository.
- Create a new branch for your changes:
git checkout -b feature/your-feature-name - Make your changes and commit them:
git commit -m 'Add your feature' - Push your changes to your forked repository:
git push origin feature/your-feature-name - Open a pull request on the main repository, explaining your changes.
This project is released to the public domain under the CC0 License - see the LICENSE file for details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for mikupad
Similar Open Source Tools
mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.

AIOStreams
AIOStreams is a versatile tool that combines streams from various addons into one platform, offering extensive customization options. Users can change result formats, filter results by various criteria, remove duplicates, prioritize services, sort results, specify size limits, and more. The tool scrapes results from selected addons, applies user configurations, and presents the results in a unified manner. It simplifies the process of finding and accessing desired content from multiple sources, enhancing user experience and efficiency.

kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.

nanobrowser
Nanobrowser is an open-source AI web automation tool that runs in your browser. It is a free alternative to OpenAI Operator with flexible LLM options and a multi-agent system. Nanobrowser offers premium web automation capabilities while keeping users in complete control, with features like a multi-agent system, interactive side panel, task automation, follow-up questions, and multiple LLM support. Users can easily download and install Nanobrowser as a Chrome extension, configure agent models, and accomplish tasks such as news summary, GitHub research, and shopping research with just a sentence. The tool uses a specialized multi-agent system powered by large language models to understand and execute complex web tasks. Nanobrowser is actively developed with plans to expand LLM support, implement security measures, optimize memory usage, enable session replay, and develop specialized agents for domain-specific tasks. Contributions from the community are welcome to improve Nanobrowser and build the future of web automation.
Local-Multimodal-AI-Chat
Local Multimodal AI Chat is a multimodal chat application that integrates various AI models to manage audio, images, and PDFs seamlessly within a single interface. It offers local model processing with Ollama for data privacy, integration with OpenAI API for broader AI capabilities, audio chatting with Whisper AI for accurate voice interpretation, and PDF chatting with Chroma DB for efficient PDF interactions. The application is designed for AI enthusiasts and developers seeking a comprehensive solution for multimodal AI technologies.
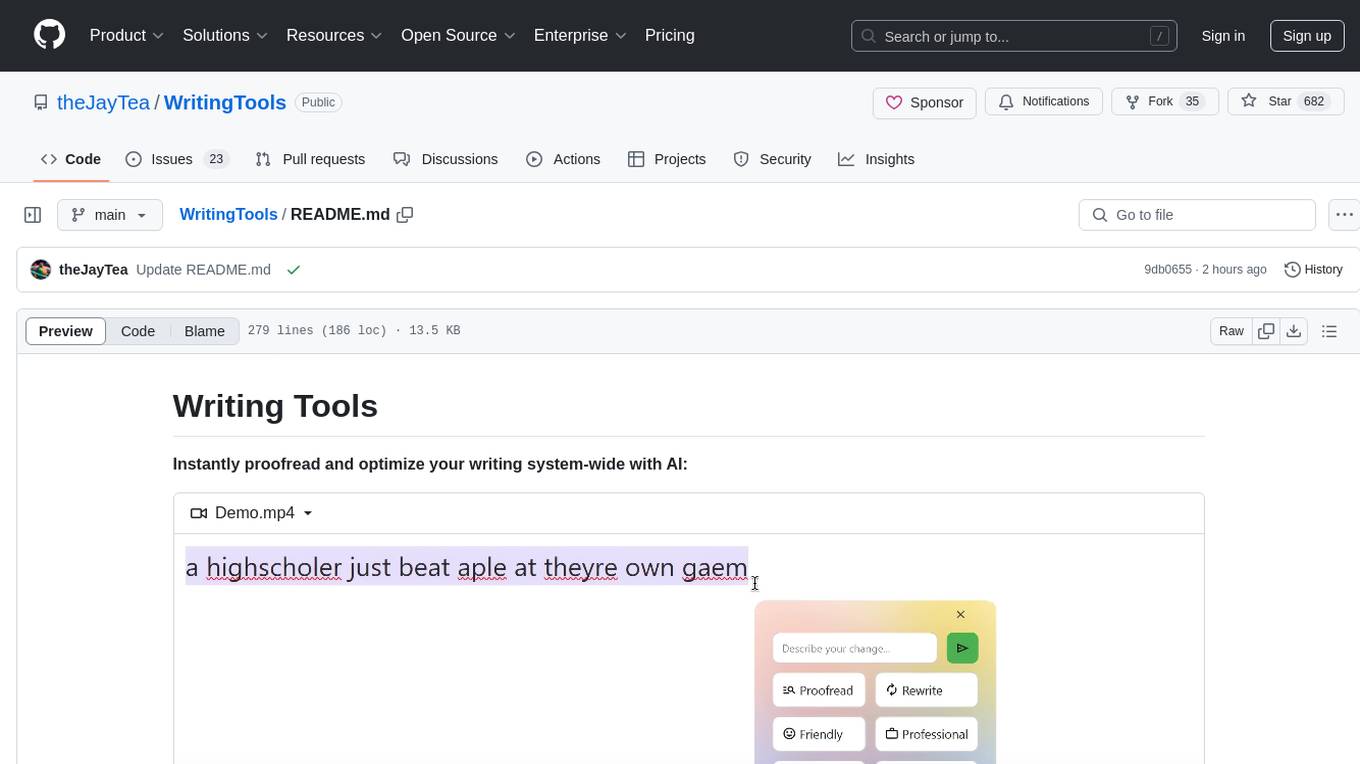
WritingTools
Writing Tools is an Apple Intelligence-inspired application for Windows, Linux, and macOS that supercharges your writing with an AI LLM. It allows users to instantly proofread, optimize text, and summarize content from webpages, YouTube videos, documents, etc. The tool is privacy-focused, open-source, and supports multiple languages. It offers powerful features like grammar correction, content summarization, and LLM chat mode, making it a versatile writing assistant for various tasks.
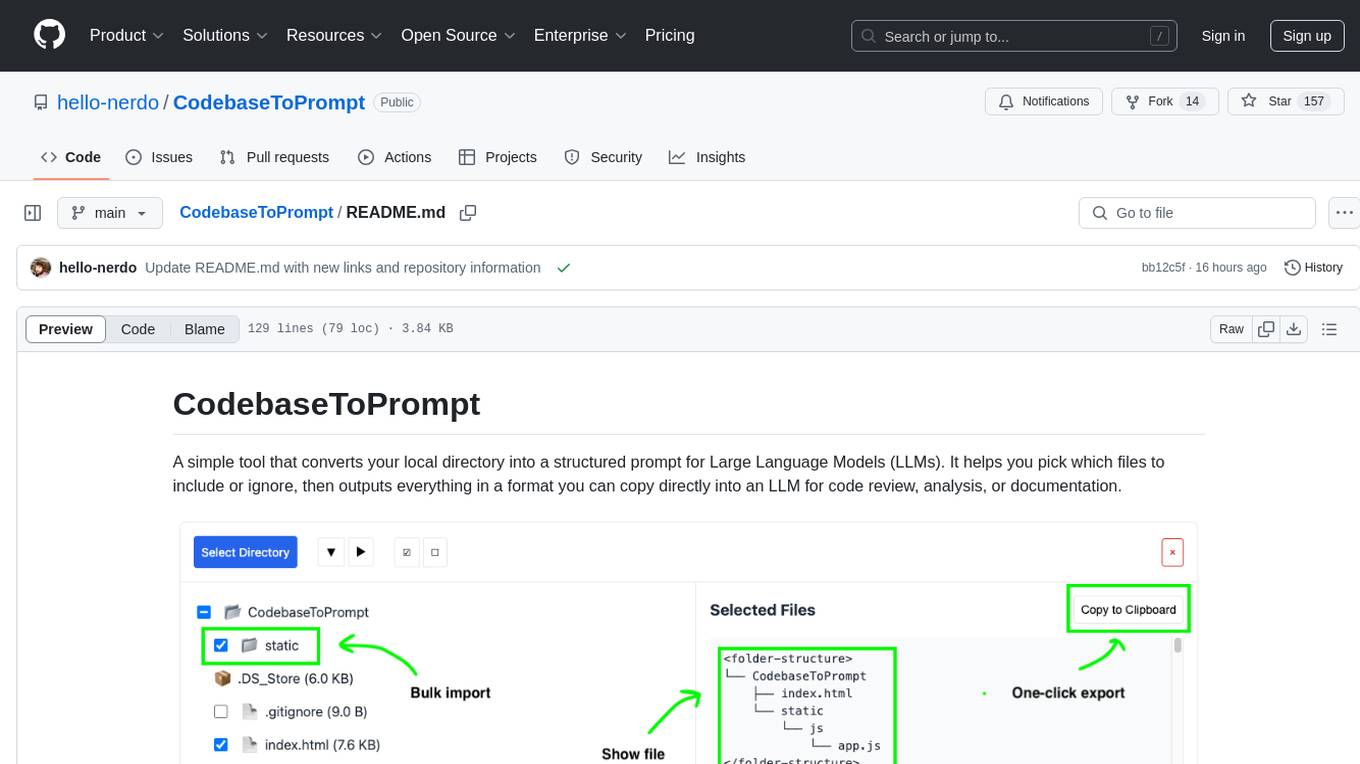
CodebaseToPrompt
CodebaseToPrompt is a tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in an interactive interface. The tool generates a formatted output that can be directly used with LLMs, estimates token count, and supports flexible text selection. Users can deploy the tool using Docker for self-contained usage and can contribute to the project by opening issues or submitting pull requests.
nextjs-ollama-llm-ui
This web interface provides a user-friendly and feature-rich platform for interacting with Ollama Large Language Models (LLMs). It offers a beautiful and intuitive UI inspired by ChatGPT, making it easy for users to get started with LLMs. The interface is fully local, storing chats in local storage for convenience, and fully responsive, allowing users to chat on their phones with the same ease as on a desktop. It features easy setup, code syntax highlighting, and the ability to easily copy codeblocks. Users can also download, pull, and delete models directly from the interface, and switch between models quickly. Chat history is saved and easily accessible, and users can choose between light and dark mode. To use the web interface, users must have Ollama downloaded and running, and Node.js (18+) and npm installed. Installation instructions are provided for running the interface locally. Upcoming features include the ability to send images in prompts, regenerate responses, import and export chats, and add voice input support.
your-source-to-prompt.html
Your Source to Prompt is a single HTML file tool that allows users to easily select code files and combine them into a single text output. It runs entirely in the browser, ensuring local and secure operation without any external dependencies. The tool offers features like preset management, efficient file selection, context size awareness, hierarchical structure preview, minification, and user-friendly UI with dark mode. It aims to simplify the process of preparing code for Large Language Models (LLMs) by providing a well-structured prompt context.
CodeGPT
CodeGPT is an extension for JetBrains IDEs that provides access to state-of-the-art large language models (LLMs) for coding assistance. It offers a range of features to enhance the coding experience, including code completions, a ChatGPT-like interface for instant coding advice, commit message generation, reference file support, name suggestions, and offline development support. CodeGPT is designed to keep privacy in mind, ensuring that user data remains secure and private.
AIOLists
AIOLists is a stateless open source list management addon for Stremio that allows users to import and manage lists from various sources in one place. It offers unified search, metadata customization, Trakt integration, MDBList integration, external lists import, list sorting, customization options, watchlist updates, RPDB support, genre filtering, discovery lists, and shareable configurations. The addon aims to enhance the list management experience for Stremio users by providing a comprehensive set of features and functionalities.
ai_automation_suggester
An integration for Home Assistant that leverages AI models to understand your unique home environment and propose intelligent automations. By analyzing your entities, devices, areas, and existing automations, the AI Automation Suggester helps you discover new, context-aware use cases you might not have considered, ultimately streamlining your home management and improving efficiency, comfort, and convenience. The tool acts as a personal automation consultant, providing actionable YAML-based automations that can save energy, improve security, enhance comfort, and reduce manual intervention. It turns the complexity of a large Home Assistant environment into actionable insights and tangible benefits.

kairon
Kairon is an open-source conversational digital transformation platform that helps build LLM-based digital assistants at scale. It provides a no-coding web interface for adapting, training, testing, and maintaining AI assistants. Kairon focuses on pre-processing data for chatbots, including question augmentation, knowledge graph generation, and post-processing metrics. It offers end-to-end lifecycle management, low-code/no-code interface, secure script injection, telemetry monitoring, chat client designer, analytics module, and real-time struggle analytics. Kairon is suitable for teams and individuals looking for an easy interface to create, train, test, and deploy digital assistants.

CodebaseToPrompt
CodebaseToPrompt is a simple tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in a browser-based interface. The tool generates a formatted output that can be directly used with AI tools, provides token count estimates, and supports local storage for saving selections. Users can easily copy the selected files in the desired format for further use.

LLMstudio
LLMstudio by TensorOps is a platform that offers prompt engineering tools for accessing models from providers like OpenAI, VertexAI, and Bedrock. It provides features such as Python Client Gateway, Prompt Editing UI, History Management, and Context Limit Adaptability. Users can track past runs, log costs and latency, and export history to CSV. The tool also supports automatic switching to larger-context models when needed. Coming soon features include side-by-side comparison of LLMs, automated testing, API key administration, project organization, and resilience against rate limits. LLMstudio aims to streamline prompt engineering, provide execution history tracking, and enable effortless data export, offering an evolving environment for teams to experiment with advanced language models.

ProxyAI
ProxyAI is an open-source AI copilot for JetBrains, offering advanced code assistance features powered by top-tier language models. Users can customize their coding experience, receive AI-suggested code changes, autocomplete suggestions, and context-aware naming suggestions. The tool also allows users to chat with images, reference project files and folders, web docs, git history, and search the web. ProxyAI prioritizes user privacy by not collecting sensitive information and only gathering anonymous usage data with consent.
For similar tasks
mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.
mlx-ui
MLX Chat is a simple UI / Web / Frontend for MLX mlx-lm using Streamlit. It provides a user-friendly interface to interact with the MLX language model, allowing users to easily generate text, translate languages, write different kinds of creative content, and more. The tool is designed to be accessible to users of all levels, from beginners to experienced programmers.

chat-ui
A chat interface using open source models, eg OpenAssistant or Llama. It is a SvelteKit app and it powers the HuggingChat app on hf.co/chat.
Linly-Talker
Linly-Talker is an innovative digital human conversation system that integrates the latest artificial intelligence technologies, including Large Language Models (LLM) 🤖, Automatic Speech Recognition (ASR) 🎙️, Text-to-Speech (TTS) 🗣️, and voice cloning technology 🎤. This system offers an interactive web interface through the Gradio platform 🌐, allowing users to upload images 📷 and engage in personalized dialogues with AI 💬.
gemini-pro-bot
This Python Telegram bot utilizes Google's `gemini-pro` LLM API to generate creative text formats based on user input. It's designed to be an engaging and interactive way to explore the capabilities of large language models. Key features include generating various text formats like poems, code, scripts, and musical pieces. The bot supports real-time streaming of the generation process, allowing users to witness the text unfold. Additionally, it can respond to messages with Bard's creative output and handle image-based inputs for multimodal responses. User authentication is optional, and the bot can be easily integrated with Docker or installed via pipenv.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.
ChatterUI
ChatterUI is a mobile app that allows users to manage chat files and character cards, and to interact with Large Language Models (LLMs). It supports multiple backends, including local, koboldcpp, text-generation-webui, Generic Text Completions, AI Horde, Mancer, Open Router, and OpenAI. ChatterUI provides a mobile-friendly interface for interacting with LLMs, making it easy to use them for a variety of tasks, such as generating text, translating languages, writing code, and answering questions.
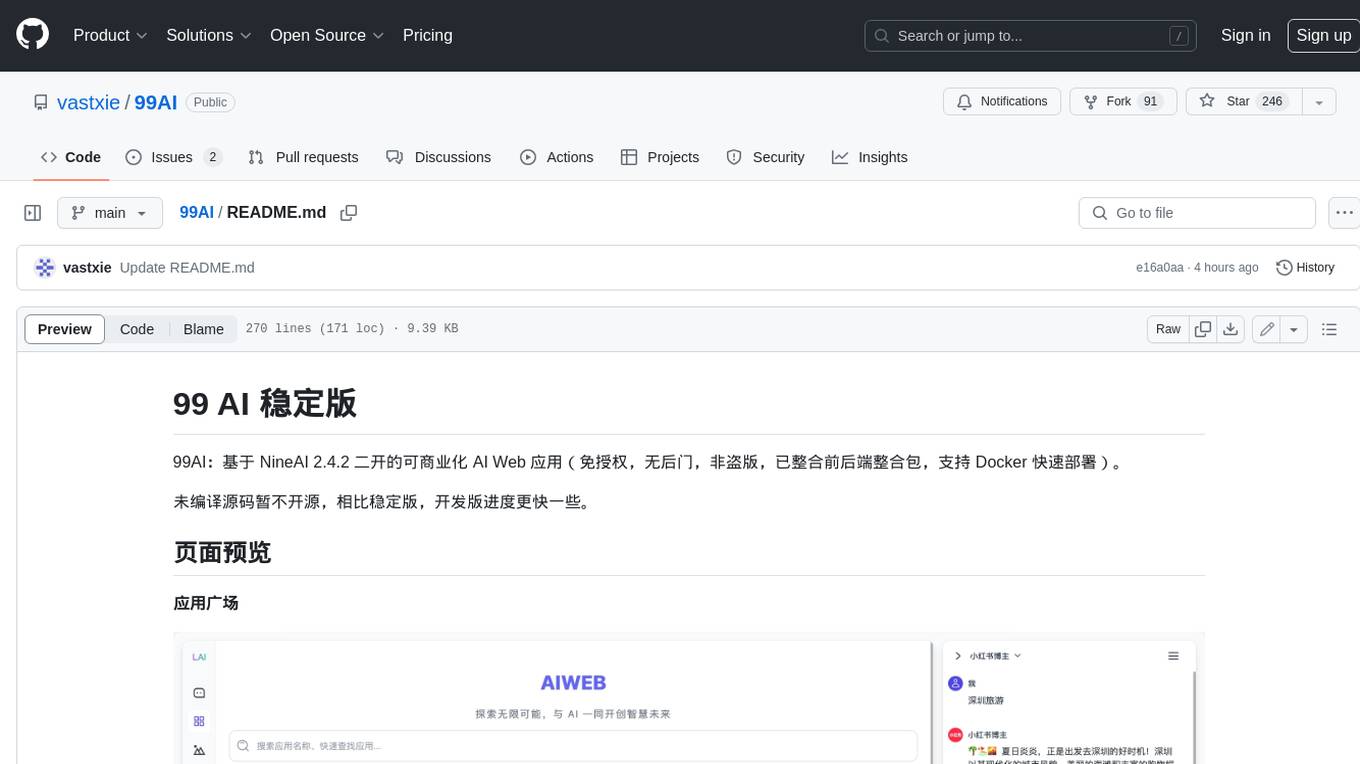
99AI
99AI is a commercializable AI web application based on NineAI 2.4.2 (no authorization, no backdoors, no piracy, integrated front-end and back-end integration packages, supports Docker rapid deployment). The uncompiled source code is temporarily closed. Compared with the stable version, the development version is faster.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.
mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.
onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.