
agent-contributions-library
This repository contains the AI Agents Contributions Library for the Virtual DAO ecosystem. It focuses on how contributions from AI agents, particularly datasets on voice and text data, are recorded, reviewed, and rewarded within the Virtual DAO framework.
Stars: 77
The AI Agents Contributions Library is a repository dedicated to managing datasets on voice and cognitive core data for AI agents within the Virtual DAO ecosystem. It provides a structured framework for recording, reviewing, and rewarding contributions from contributors. The repository includes folders for character cards, contribution datasets, fine-tuning resources, text datasets, and voice datasets. Contributors can submit datasets following specific guidelines and formats, and the Virtual DAO team reviews and integrates approved datasets to enhance AI agents' capabilities.
README:
This repository hosts the AI Agents Contributions Library for the Virtual DAO ecosystem. It focuses on how AI agents' contributions—particularly datasets on voice and cognitive core data—are recorded, reviewed, and rewarded within the Virtual DAO framework.
- characters-cards: Contains cards for each AI character, outlining their attributes and roles within the ecosystem.
- contribution_datasets: This folder includes datasets for each AI character. Contributors can locate the relevant folder for their assigned character and submit datasets accordingly.
- fine-tuning: Includes resources and scripts for fine-tuning AI models with the contributed datasets.
- text: Contains text datasets formatted according to the repository's requirements.
- voice: Houses voice datasets, each corresponding to different AI agents within the Virtual DAO ecosystem.
- README.md: Provides an overview of the repository, its purpose, and structure.
- Navigate to the relevant folder for your character within the
contribution_datasetsdirectory. - Submit your dataset by placing it in the appropriate folder.
- Ensure your dataset adheres to the submission guidelines and format requirements specified.
-
Fork the Repository:
- Go to the repository on GitHub and click the "Fork" button in the top-right corner.
-
Clone the Forked Repository:
git clone https://github.com/your-username/agent-contributions-library.git cd agent-contributions-library -
Add Your Dataset:
- Navigate to the
contribution_datasetsfolder and locate the designated folder for your character. - Add your dataset files to the appropriate folder.
- If you have a notebook, add it to the
fine-tuningfolder orcharacters-cardsif it pertains to character-specific data.
- Navigate to the
-
Commit Your Changes:
git add . git commit -m "Added dataset for [Character Name]"
-
Push Your Changes:
git push origin main
-
Create a Pull Request:
- Go to your forked repository on GitHub.
- Click on the "Compare & pull request" button.
- Provide a meaningful title and description for your pull request.
- Submit the pull request.
All contributions will be reviewed by the Virtual DAO team. Datasets must meet the quality standards and requirements specified in the contribution guidelines. Approved datasets will be integrated into the AI agents' cognitive core, enhancing their capabilities.
For any questions or assistance, please reach out to the repository maintainers.
© 2024 Virtual DAO. All rights reserved.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for agent-contributions-library
Similar Open Source Tools
agent-contributions-library
The AI Agents Contributions Library is a repository dedicated to managing datasets on voice and cognitive core data for AI agents within the Virtual DAO ecosystem. It provides a structured framework for recording, reviewing, and rewarding contributions from contributors. The repository includes folders for character cards, contribution datasets, fine-tuning resources, text datasets, and voice datasets. Contributors can submit datasets following specific guidelines and formats, and the Virtual DAO team reviews and integrates approved datasets to enhance AI agents' capabilities.

graphrag-local-ollama
GraphRAG Local Ollama is a repository that offers an adaptation of Microsoft's GraphRAG, customized to support local models downloaded using Ollama. It enables users to leverage local models with Ollama for large language models (LLMs) and embeddings, eliminating the need for costly OpenAPI models. The repository provides a simple setup process and allows users to perform question answering over private text corpora by building a graph-based text index and generating community summaries for closely-related entities. GraphRAG Local Ollama aims to improve the comprehensiveness and diversity of generated answers for global sensemaking questions over datasets.
Local-Multimodal-AI-Chat
Local Multimodal AI Chat is a multimodal chat application that integrates various AI models to manage audio, images, and PDFs seamlessly within a single interface. It offers local model processing with Ollama for data privacy, integration with OpenAI API for broader AI capabilities, audio chatting with Whisper AI for accurate voice interpretation, and PDF chatting with Chroma DB for efficient PDF interactions. The application is designed for AI enthusiasts and developers seeking a comprehensive solution for multimodal AI technologies.

mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.
DataEngineeringPilipinas
DataEngineeringPilipinas is a repository dedicated to data engineering resources in the Philippines. It serves as a platform for data engineering professionals to contribute and access high-quality content related to data engineering. The repository provides guidelines for contributing, including forking the repository, making changes, and submitting contributions. It emphasizes the importance of quality, relevance, and respect in the contributions made to the project. By following the guidelines and contributing to the repository, users can help build a valuable resource for the data engineering community in the Philippines and beyond.
AiTimeline
AiTimeline is a comprehensive timeline showcasing the evolution and advancements in artificial intelligence technologies from 2022 to 2024. It provides a detailed overview of key milestones, releases, and developments in the AI industry, organized chronologically by year. The timeline offers a responsive design for seamless viewing on various devices and includes brief descriptions for each event, making it a valuable resource for researchers, enthusiasts, and anyone interested in tracking the progress of AI technologies.
fridon-ai
FridonAI is an open-source project offering AI-powered tools for cryptocurrency analysis and blockchain operations. It includes modules like FridonAnalytics for price analysis, FridonSearch for technical indicators, FridonNotifier for custom alerts, FridonBlockchain for blockchain operations, and FridonChat as a unified chat interface. The platform empowers users to create custom AI chatbots, access crypto tools, and interact effortlessly through chat. The core functionality is modular, with plugins, tools, and utilities for easy extension and development. FridonAI implements a scoring system to assess user interactions and incentivize engagement. The application uses Redis extensively for communication and includes a Nest.js backend for system operations.
ai-workshop
The AI Workshop repository provides a comprehensive guide to utilizing OpenAI's APIs, including Chat Completion, Embedding, and Assistant APIs. It offers hands-on demonstrations and code examples to help users understand the capabilities of these APIs. The workshop covers topics such as creating interactive chatbots, performing semantic search using text embeddings, and building custom assistants with specific data and context. Users can enhance their understanding of AI applications in education, research, and other domains through practical examples and usage notes.
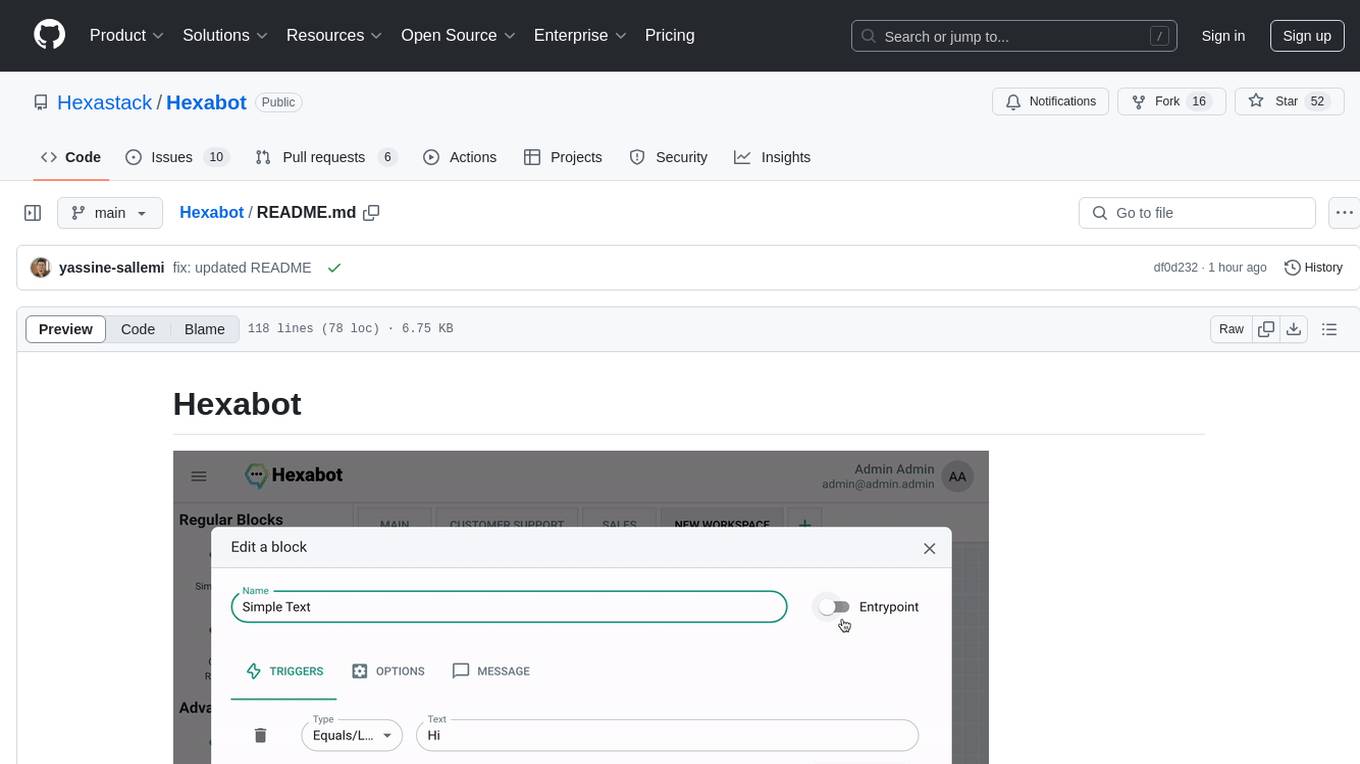
Hexabot
Hexabot Community Edition is an open-source chatbot solution designed for flexibility and customization, offering powerful text-to-action capabilities. It allows users to create and manage AI-powered, multi-channel, and multilingual chatbots with ease. The platform features an analytics dashboard, multi-channel support, visual editor, plugin system, NLP/NLU management, multi-lingual support, CMS integration, user roles & permissions, contextual data, subscribers & labels, and inbox & handover functionalities. The directory structure includes frontend, API, widget, NLU, and docker components. Prerequisites for running Hexabot include Docker and Node.js. The installation process involves cloning the repository, setting up the environment, and running the application. Users can access the UI admin panel and live chat widget for interaction. Various commands are available for managing the Docker services. Detailed documentation and contribution guidelines are provided for users interested in contributing to the project.

Instrukt
Instrukt is a terminal-based AI integrated environment that allows users to create and instruct modular AI agents, generate document indexes for question-answering, and attach tools to any agent. It provides a platform for users to interact with AI agents in natural language and run them inside secure containers for performing tasks. The tool supports custom AI agents, chat with code and documents, tools customization, prompt console for quick interaction, LangChain ecosystem integration, secure containers for agent execution, and developer console for debugging and introspection. Instrukt aims to make AI accessible to everyone by providing tools that empower users without relying on external APIs and services.
ai_automation_suggester
An integration for Home Assistant that leverages AI models to understand your unique home environment and propose intelligent automations. By analyzing your entities, devices, areas, and existing automations, the AI Automation Suggester helps you discover new, context-aware use cases you might not have considered, ultimately streamlining your home management and improving efficiency, comfort, and convenience. The tool acts as a personal automation consultant, providing actionable YAML-based automations that can save energy, improve security, enhance comfort, and reduce manual intervention. It turns the complexity of a large Home Assistant environment into actionable insights and tangible benefits.
PyWxDump
PyWxDump is a powerful tool designed to help extract and manage WeChat data efficiently. It allows users to read local databases, view chat histories, and export data in various formats such as CSV and HTML. With features like multi-account support, version compatibility, data export, AI training, and automated responses, PyWxDump offers flexibility for training AI models and developing automated replies.
deer-flow
DeerFlow is a community-driven Deep Research framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It supports FaaS deployment and one-click deployment based on Volcengine. The framework includes core capabilities like LLM integration, search and retrieval, RAG integration, MCP seamless integration, human collaboration, report post-editing, and content creation. The architecture is based on a modular multi-agent system with components like Coordinator, Planner, Research Team, and Text-to-Speech integration. DeerFlow also supports interactive mode, human-in-the-loop mechanism, and command-line arguments for customization.
MemGPT
MemGPT is a system that intelligently manages different memory tiers in LLMs in order to effectively provide extended context within the LLM's limited context window. For example, MemGPT knows when to push critical information to a vector database and when to retrieve it later in the chat, enabling perpetual conversations. MemGPT can be used to create perpetual chatbots with self-editing memory, chat with your data by talking to your local files or SQL database, and more.

CodebaseToPrompt
CodebaseToPrompt is a simple tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in a browser-based interface. The tool generates a formatted output that can be directly used with AI tools, provides token count estimates, and supports local storage for saving selections. Users can easily copy the selected files in the desired format for further use.
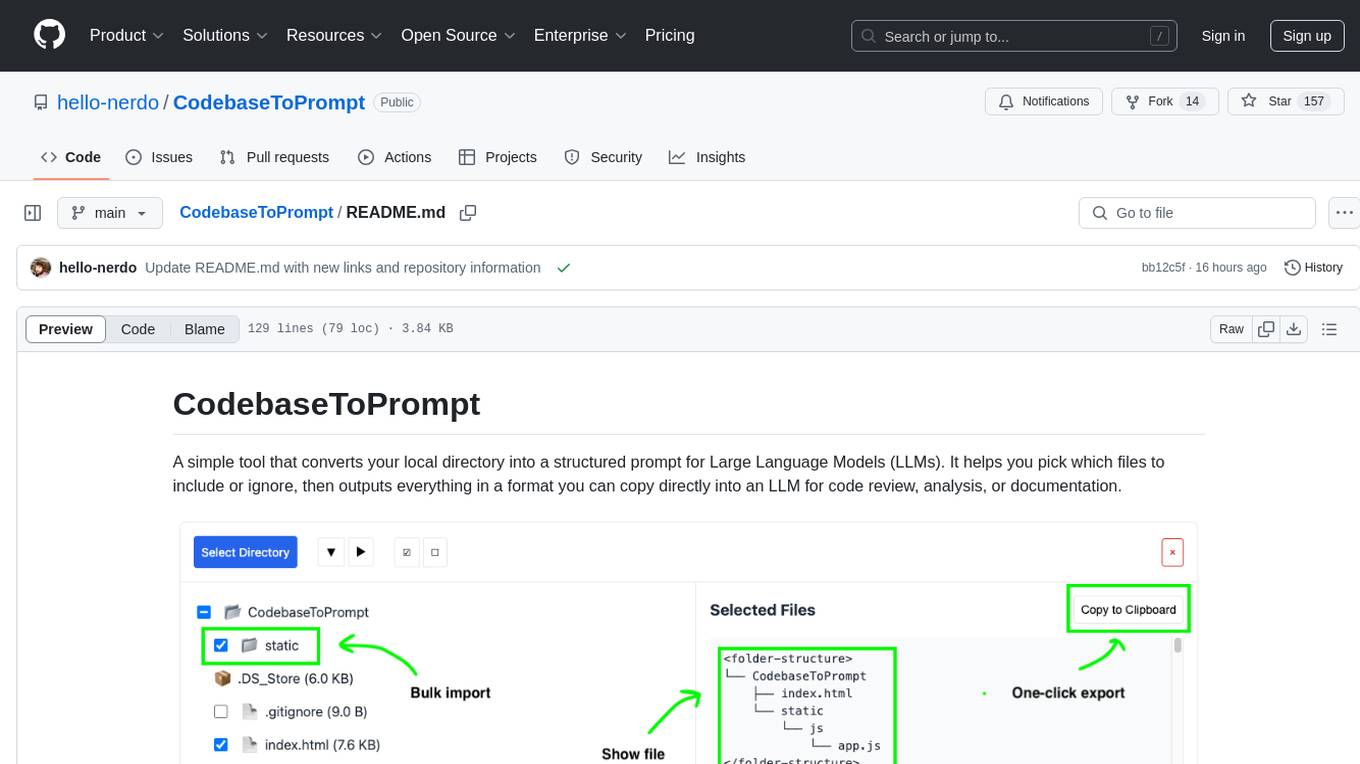
CodebaseToPrompt
CodebaseToPrompt is a tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in an interactive interface. The tool generates a formatted output that can be directly used with LLMs, estimates token count, and supports flexible text selection. Users can deploy the tool using Docker for self-contained usage and can contribute to the project by opening issues or submitting pull requests.
For similar tasks
agent-contributions-library
The AI Agents Contributions Library is a repository dedicated to managing datasets on voice and cognitive core data for AI agents within the Virtual DAO ecosystem. It provides a structured framework for recording, reviewing, and rewarding contributions from contributors. The repository includes folders for character cards, contribution datasets, fine-tuning resources, text datasets, and voice datasets. Contributors can submit datasets following specific guidelines and formats, and the Virtual DAO team reviews and integrates approved datasets to enhance AI agents' capabilities.

mindsdb
MindsDB is a platform for customizing AI from enterprise data. You can create, serve, and fine-tune models in real-time from your database, vector store, and application data. MindsDB "enhances" SQL syntax with AI capabilities to make it accessible for developers worldwide. With MindsDB’s nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely. Their AI systems will constantly improve themselves — using companies’ own data, in real-time.

training-operator
Kubeflow Training Operator is a Kubernetes-native project for fine-tuning and scalable distributed training of machine learning (ML) models created with various ML frameworks such as PyTorch, Tensorflow, XGBoost, MPI, Paddle and others. Training Operator allows you to use Kubernetes workloads to effectively train your large models via Kubernetes Custom Resources APIs or using Training Operator Python SDK. > Note: Before v1.2 release, Kubeflow Training Operator only supports TFJob on Kubernetes. * For a complete reference of the custom resource definitions, please refer to the API Definition. * TensorFlow API Definition * PyTorch API Definition * Apache MXNet API Definition * XGBoost API Definition * MPI API Definition * PaddlePaddle API Definition * For details of all-in-one operator design, please refer to the All-in-one Kubeflow Training Operator * For details on its observability, please refer to the monitoring design doc.

helix
HelixML is a private GenAI platform that allows users to deploy the best of open AI in their own data center or VPC while retaining complete data security and control. It includes support for fine-tuning models with drag-and-drop functionality. HelixML brings the best of open source AI to businesses in an ergonomic and scalable way, optimizing the tradeoff between GPU memory and latency.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.

petals
Petals is a tool that allows users to run large language models at home in a BitTorrent-style manner. It enables fine-tuning and inference up to 10x faster than offloading. Users can generate text with distributed models like Llama 2, Falcon, and BLOOM, and fine-tune them for specific tasks directly from their desktop computer or Google Colab. Petals is a community-run system that relies on people sharing their GPUs to increase its capacity and offer a distributed network for hosting model layers.

LLaVA-pp
This repository, LLaVA++, extends the visual capabilities of the LLaVA 1.5 model by incorporating the latest LLMs, Phi-3 Mini Instruct 3.8B, and LLaMA-3 Instruct 8B. It provides various models for instruction-following LMMS and academic-task-oriented datasets, along with training scripts for Phi-3-V and LLaMA-3-V. The repository also includes installation instructions and acknowledgments to related open-source contributions.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.
For similar jobs

responsible-ai-toolbox
Responsible AI Toolbox is a suite of tools providing model and data exploration and assessment interfaces and libraries for understanding AI systems. It empowers developers and stakeholders to develop and monitor AI responsibly, enabling better data-driven actions. The toolbox includes visualization widgets for model assessment, error analysis, interpretability, fairness assessment, and mitigations library. It also offers a JupyterLab extension for managing machine learning experiments and a library for measuring gender bias in NLP datasets.
LLMLingua
LLMLingua is a tool that utilizes a compact, well-trained language model to identify and remove non-essential tokens in prompts. This approach enables efficient inference with large language models, achieving up to 20x compression with minimal performance loss. The tool includes LLMLingua, LongLLMLingua, and LLMLingua-2, each offering different levels of prompt compression and performance improvements for tasks involving large language models.
llm-examples
Starter examples for building LLM apps with Streamlit. This repository showcases a growing collection of LLM minimum working examples, including a Chatbot, File Q&A, Chat with Internet search, LangChain Quickstart, LangChain PromptTemplate, and Chat with user feedback. Users can easily get their own OpenAI API key and set it as an environment variable in Streamlit apps to run the examples locally.

LMOps
LMOps is a research initiative focusing on fundamental research and technology for building AI products with foundation models, particularly enabling AI capabilities with Large Language Models (LLMs) and Generative AI models. The project explores various aspects such as prompt optimization, longer context handling, LLM alignment, acceleration of LLMs, LLM customization, and understanding in-context learning. It also includes tools like Promptist for automatic prompt optimization, Structured Prompting for efficient long-sequence prompts consumption, and X-Prompt for extensible prompts beyond natural language. Additionally, LLMA accelerators are developed to speed up LLM inference by referencing and copying text spans from documents. The project aims to advance technologies that facilitate prompting language models and enhance the performance of LLMs in various scenarios.

awesome-tool-llm
This repository focuses on exploring tools that enhance the performance of language models for various tasks. It provides a structured list of literature relevant to tool-augmented language models, covering topics such as tool basics, tool use paradigm, scenarios, advanced methods, and evaluation. The repository includes papers, preprints, and books that discuss the use of tools in conjunction with language models for tasks like reasoning, question answering, mathematical calculations, accessing knowledge, interacting with the world, and handling non-textual modalities.
gaianet-node
GaiaNet-node is a tool that allows users to run their own GaiaNet node, enabling them to interact with an AI agent. The tool provides functionalities to install the default node software stack, initialize the node with model files and vector database files, start the node, stop the node, and update configurations. Users can use pre-set configurations or pass a custom URL for initialization. The tool is designed to facilitate communication with the AI agent and access node information via a browser. GaiaNet-node requires sudo privilege for installation but can also be installed without sudo privileges with specific commands.

llmops-duke-aipi
LLMOps Duke AIPI is a course focused on operationalizing Large Language Models, teaching methodologies for developing applications using software development best practices with large language models. The course covers various topics such as generative AI concepts, setting up development environments, interacting with large language models, using local large language models, applied solutions with LLMs, extensibility using plugins and functions, retrieval augmented generation, introduction to Python web frameworks for APIs, DevOps principles, deploying machine learning APIs, LLM platforms, and final presentations. Students will learn to build, share, and present portfolios using Github, YouTube, and Linkedin, as well as develop non-linear life-long learning skills. Prerequisites include basic Linux and programming skills, with coursework available in Python or Rust. Additional resources and references are provided for further learning and exploration.
Awesome-AISourceHub
Awesome-AISourceHub is a repository that collects high-quality information sources in the field of AI technology. It serves as a synchronized source of information to avoid information gaps and information silos. The repository aims to provide valuable resources for individuals such as AI book authors, enterprise decision-makers, and tool developers who frequently use Twitter to share insights and updates related to AI advancements. The platform emphasizes the importance of accessing information closer to the source for better quality content. Users can contribute their own high-quality information sources to the repository by following specific steps outlined in the contribution guidelines. The repository covers various platforms such as Twitter, public accounts, knowledge planets, podcasts, blogs, websites, YouTube channels, and more, offering a comprehensive collection of AI-related resources for individuals interested in staying updated with the latest trends and developments in the AI field.