
persian-license-plate-recognition
PLPR utilizes YOLOv5 and custom models for high-accuracy Persian license plate recognition, featuring real-time processing and an intuitive interface in an open-source framework.
Stars: 345
The Persian License Plate Recognition (PLPR) system is a state-of-the-art solution designed for detecting and recognizing Persian license plates in images and video streams. Leveraging advanced deep learning models and a user-friendly interface, it ensures reliable performance across different scenarios. The system offers advanced detection using YOLOv5 models, precise recognition of Persian characters, real-time processing capabilities, and a user-friendly GUI. It is well-suited for applications in traffic monitoring, automated vehicle identification, and similar fields. The system's architecture includes modules for resident management, entrance management, and a detailed flowchart explaining the process from system initialization to displaying results in the GUI. Hardware requirements include an Intel Core i5 processor, 8 GB RAM, a dedicated GPU with at least 4 GB VRAM, and an SSD with 20 GB of free space. The system can be installed by cloning the repository and installing required Python packages. Users can customize the video source for processing and run the application to upload and process images or video streams. The system's GUI allows for parameter adjustments to optimize performance, and the Wiki provides in-depth information on the system's architecture and model training.
README:
The Persian License Plate Recognition (PLPR) system is a state-of-the-art solution designed for detecting and recognizing Persian license plates in images and video streams. Leveraging advanced deep learning models and a user-friendly interface, it ensures reliable performance across different scenarios.
This system aims to tackle the unique challenges associated with Persian license plate detection and recognition, offering high accuracy and efficiency. It's well-suited for applications in traffic monitoring, automated vehicle identification, and similar fields.
- Advanced Detection: Utilizes YOLOv5 models for high-accuracy license plate detection.
- Persian Character Recognition: Custom-trained models ensure precise recognition of Persian characters.
- Real-Time Processing: Capable of processing live video feeds in real-time.
- User-Friendly GUI: Intuitive graphical user interface simplifies interactions with the system.

|
|

Focuses on maintaining and updating resident vehicle information, managing permissions for entry, and tracking resident vehicle movements within the premises. |

Handles the regulation of vehicles entering and exiting the premises, ensuring only authorized vehicles gain access, and maintaining a log of all vehicle movements for security and administrative purposes. |

|
|
To ensure optimal performance of the Persian License Plate Recognition System (PLPR), the following hardware specifications are recommended:
- Processor: Intel Core i5 (8th Gen) or equivalent/higher.
- Memory: 8 GB RAM or more.
- Graphics: Dedicated GPU (NVIDIA GTX 1060 or equivalent) with at least 4 GB VRAM for efficient real-time processing and deep learning model computations.
- Storage: SSD with at least 20 GB of free space for software, models, and datasets.
- Operating System: Compatible with Windows 10/11, Linux (Ubuntu 18.04 or later), and macOS (10.14 Mojave or later).
These specifications are designed to handle the computational demands of advanced deep learning models, real-time video processing, and high-volume data management integral to the PLPR system. Adjustments may be necessary based on specific deployment scenarios and performance expectations.
- Clone the repository and navigate to its directory:
git clone https://github.com/mtkarimi/smart-resident-guard.git cd smart-resident-guard - Install the required Python packages:
pip install -r requirements.txt

To customize the video source for processing, modify the parameter in cv2.VideoCapture(0), where 0 denotes the default webcam input. For using a specific video file, change this parameter to params.video, which fetches the video path from config.ini. In config.ini, set the video parameter to your video file path, e.g., video = anpr_video.mp4, replacing anpr_video.mp4 with the path to your video file.
For streaming video sources, update the config.ini file with the stream address. Replace the existing video path with your stream address, for example, rtps = rtsp://172.17.0.1:8554/webCamStream. This adjustment allows the system to process video streams in real-time.
This flexibility in video source selection enables seamless integration and testing across various input methods, ensuring adaptability to different operational requirements.
Launch the application with the following command:
python home-yolo.pyThe system's GUI enables users to upload and process images or video streams, displaying detected license plates and recognized text. It also allows for parameter adjustments to optimize performance.
For a deep dive into the PLPR system's architecture, model training, and advanced usage, check out our Wiki. It's a comprehensive resource for users and developers alike.
Explore the pdf-research directory for research papers and articles on LPR technologies, offering insights into the techniques and algorithms behind the system.
Heartfelt thanks to the open-source projects and communities that have made this project possible. Special mentions include:
- YOLOv5 and PyTorch for the core detection and recognition models.
- PySide6 and OpenCV for the application interface and image processing capabilities.
- Pillow for enhanced image manipulation.
This project stands on the shoulders of giants within the AI and open-source communities. Their dedication to sharing knowledge and tools has been invaluable.
GPL-3.0. See the LICENSE file for details. It means you can:
- Share Source Code: If you distribute binaries or modified versions, you must make the source code available under GPL-3.
- License: Must keep and apply GPL-3 to the modified work.
- State Modifications: If modified, must disclose that it was changed.
The Persian License Plate Recognition (PLPR) system is a testament to the collaborative spirit of the open-source community. While the assembly and development of this system were carried out independently, the project is enriched through the insights and resources offered by various exceptional contributors and datasets within the community. This section is dedicated to acknowledging those invaluable learnings and resources.
🫂 Learning from Community Leaders:
- Immense gratitude is directed towards Mahdi Rahmani and Meftun AKARSU. Although not directly involved in this project, their repositories served as significant learning resources. The knowledge gleaned from their work helped in navigating the complexities of license plate recognition and contributed to the foundation upon which PLPR was built.
🧱 Acknowledging Vital Datasets:
-
The datasets that played a pivotal role in the development of the PLPR system deserve special mention. I am deeply thankful for access to:
These resources were crucial for training and refining the recognition capabilities of the system. My heartfelt thanks go out to the creators and contributors of these datasets for their openness and dedication to advancing the field.
Open for Dialogue:
- Acting in the spirit of the open-source community means valuing transparency and open communication. Should there be any questions about how I utilized these contributions, or if there are specific concerns to be addressed, I am more than willing to engage in discussions. This project is a reflection of what can be accomplished through shared knowledge and cooperation, and I am committed to learning from and contributing back to the community.
I extend my sincerest appreciation to everyone whose work has indirectly contributed to the Persian License Plate Recognition system. Your tireless efforts and willingness to share knowledge have not only made this project possible but also continue to inspire and propel the open-source movement forward.
🌟 A Heartfelt Note:
- 🍁 Continuing Forward: This repository has reached a milestone and I've decided to not update it going forward. It stands as a testament to what we've achieved together.
- 📚 Inspiration and Acknowledgment: Much of what you've read and discovered here, including the detailed Wiki, was crafted with the assistance of ChatGPT. This AI has been an invaluable tool in articulating ideas and descriptions.
- 🌈 Gratitude and Learning: I encourage you to explore the works of the contributors and datasets mentioned here. Their efforts not only enriched this project but also provide vast oceans of knowledge and inspiration for us all.
- 🧩 The Journey: If there's one thing I've learned, it's that creativity is about connecting ideas. My role was more of an assembler, piecing together the incredible innovations and knowledge shared by the community to create something meaningful.
💖 Thank you all for your support, curiosity, and for joining me on this journey. Here's to the endless potential of collaboration and open source! 🥂
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for persian-license-plate-recognition
Similar Open Source Tools
persian-license-plate-recognition
The Persian License Plate Recognition (PLPR) system is a state-of-the-art solution designed for detecting and recognizing Persian license plates in images and video streams. Leveraging advanced deep learning models and a user-friendly interface, it ensures reliable performance across different scenarios. The system offers advanced detection using YOLOv5 models, precise recognition of Persian characters, real-time processing capabilities, and a user-friendly GUI. It is well-suited for applications in traffic monitoring, automated vehicle identification, and similar fields. The system's architecture includes modules for resident management, entrance management, and a detailed flowchart explaining the process from system initialization to displaying results in the GUI. Hardware requirements include an Intel Core i5 processor, 8 GB RAM, a dedicated GPU with at least 4 GB VRAM, and an SSD with 20 GB of free space. The system can be installed by cloning the repository and installing required Python packages. Users can customize the video source for processing and run the application to upload and process images or video streams. The system's GUI allows for parameter adjustments to optimize performance, and the Wiki provides in-depth information on the system's architecture and model training.

OpenDAN-Personal-AI-OS
OpenDAN is an open source Personal AI OS that consolidates various AI modules for personal use. It empowers users to create powerful AI agents like assistants, tutors, and companions. The OS allows agents to collaborate, integrate with services, and control smart devices. OpenDAN offers features like rapid installation, AI agent customization, connectivity via Telegram/Email, building a local knowledge base, distributed AI computing, and more. It aims to simplify life by putting AI in users' hands. The project is in early stages with ongoing development and future plans for user and kernel mode separation, home IoT device control, and an official OpenDAN SDK release.
deer-flow
DeerFlow is a community-driven Deep Research framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It supports FaaS deployment and one-click deployment based on Volcengine. The framework includes core capabilities like LLM integration, search and retrieval, RAG integration, MCP seamless integration, human collaboration, report post-editing, and content creation. The architecture is based on a modular multi-agent system with components like Coordinator, Planner, Research Team, and Text-to-Speech integration. DeerFlow also supports interactive mode, human-in-the-loop mechanism, and command-line arguments for customization.

nextpy
Nextpy is a cutting-edge software development framework optimized for AI-based code generation. It provides guardrails for defining AI system boundaries, structured outputs for prompt engineering, a powerful prompt engine for efficient processing, better AI generations with precise output control, modularity for multiplatform and extensible usage, developer-first approach for transferable knowledge, and containerized & scalable deployment options. It offers 4-10x faster performance compared to Streamlit apps, with a focus on cooperation within the open-source community and integration of key components from various projects.

neo
Neo.mjs is a revolutionary Application Engine for the web that offers true multithreading and context engineering, enabling desktop-class UI performance and AI-driven runtime mutation. It is not a framework but a complete runtime and toolchain for enterprise applications, excelling in single page apps and browser-based multi-window applications. With a pioneering Off-Main-Thread architecture, Neo.mjs ensures butter-smooth UI performance by keeping the main thread free for flawless user interactions. The latest version, v11, introduces AI-native capabilities, allowing developers to work with AI agents as first-class partners in the development process. The platform offers a suite of dedicated Model Context Protocol servers that give agents the context they need to understand, build, and reason about the code, enabling a new level of human-AI collaboration.

kairon
Kairon is an open-source conversational digital transformation platform that helps build LLM-based digital assistants at scale. It provides a no-coding web interface for adapting, training, testing, and maintaining AI assistants. Kairon focuses on pre-processing data for chatbots, including question augmentation, knowledge graph generation, and post-processing metrics. It offers end-to-end lifecycle management, low-code/no-code interface, secure script injection, telemetry monitoring, chat client designer, analytics module, and real-time struggle analytics. Kairon is suitable for teams and individuals looking for an easy interface to create, train, test, and deploy digital assistants.
local_multimodal_ai_chat
Local Multimodal AI Chat is a hands-on project that teaches you how to build a multimodal chat application. It integrates different AI models to handle audio, images, and PDFs in a single chat interface. This project is perfect for anyone interested in AI and software development who wants to gain practical experience with these technologies.

graphrag-local-ollama
GraphRAG Local Ollama is a repository that offers an adaptation of Microsoft's GraphRAG, customized to support local models downloaded using Ollama. It enables users to leverage local models with Ollama for large language models (LLMs) and embeddings, eliminating the need for costly OpenAPI models. The repository provides a simple setup process and allows users to perform question answering over private text corpora by building a graph-based text index and generating community summaries for closely-related entities. GraphRAG Local Ollama aims to improve the comprehensiveness and diversity of generated answers for global sensemaking questions over datasets.
LLM-Minutes-of-Meeting
LLM-Minutes-of-Meeting is a project showcasing NLP & LLM's capability to summarize long meetings and automate the task of delegating Minutes of Meeting(MoM) emails. It converts audio/video files to text, generates editable MoM, and aims to develop a real-time python web-application for meeting automation. The tool features keyword highlighting, topic tagging, export in various formats, user-friendly interface, and uses Celery for asynchronous processing. It is designed for corporate meetings, educational institutions, legal and medical fields, accessibility, and event coverage.
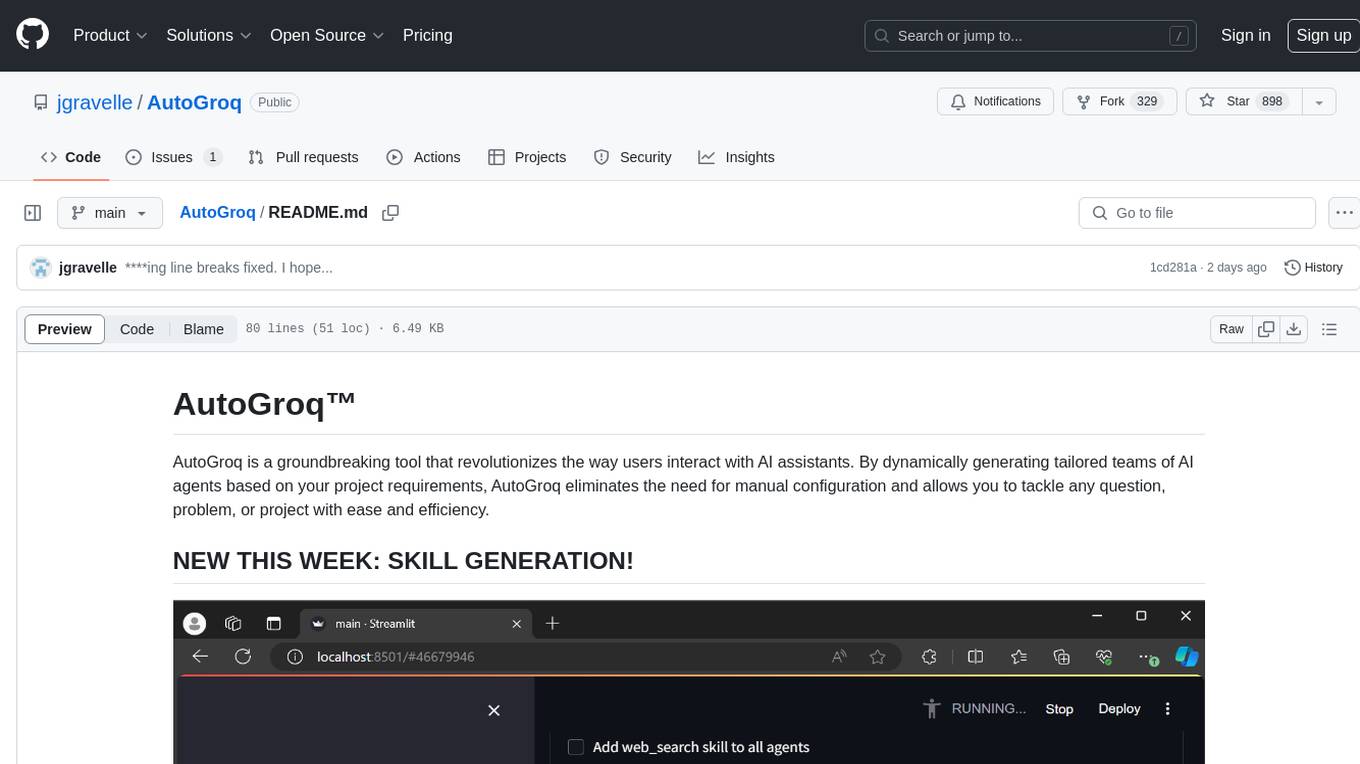
AutoGroq
AutoGroq is a revolutionary tool that dynamically generates tailored teams of AI agents based on project requirements, eliminating manual configuration. It enables users to effortlessly tackle questions, problems, and projects by creating expert agents, workflows, and skillsets with ease and efficiency. With features like natural conversation flow, code snippet extraction, and support for multiple language models, AutoGroq offers a seamless and intuitive AI assistant experience for developers and users.

reductstore
ReductStore is a high-performance time series database designed for storing and managing large amounts of unstructured blob data. It offers features such as real-time querying, batching data, and HTTP(S) API for edge computing, computer vision, and IoT applications. The database ensures data integrity, implements retention policies, and provides efficient data access, making it a cost-effective solution for applications requiring unstructured data storage and access at specific time intervals.

ChainForge
ChainForge is a visual programming environment for battle-testing prompts to LLMs. It is geared towards early-stage, quick-and-dirty exploration of prompts, chat responses, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can: * Query multiple LLMs at once to test prompt ideas and variations quickly and effectively. * Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case. * Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings. * Hold multiple conversations at once across template parameters and chat models. Template not just prompts, but follow-up chat messages, and inspect and evaluate outputs at each turn of a chat conversation. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals. This is an open beta of Chainforge. We support model providers OpenAI, HuggingFace, Anthropic, Google PaLM2, Azure OpenAI endpoints, and Dalai-hosted models Alpaca and Llama. You can change the exact model and individual model settings. Visualization nodes support numeric and boolean evaluation metrics. ChainForge is built on ReactFlow and Flask.
AutoGPT
AutoGPT is a revolutionary tool that empowers everyone to harness the power of AI. With AutoGPT, you can effortlessly build, test, and delegate tasks to AI agents, unlocking a world of possibilities. Our mission is to provide the tools you need to focus on what truly matters: innovation and creativity.
aide
Aide is an Open Source AI-native code editor that combines the powerful features of VS Code with advanced AI capabilities. It provides a combined chat + edit flow, proactive agents for fixing errors, inline editing widget, intelligent code completion, and AST navigation. Aide is designed to be an intelligent coding companion, helping users write better code faster while maintaining control over the development process.

crewAI
CrewAI is a cutting-edge framework designed to orchestrate role-playing autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks. It enables AI agents to assume roles, share goals, and operate in a cohesive unit, much like a well-oiled crew. Whether you're building a smart assistant platform, an automated customer service ensemble, or a multi-agent research team, CrewAI provides the backbone for sophisticated multi-agent interactions. With features like role-based agent design, autonomous inter-agent delegation, flexible task management, and support for various LLMs, CrewAI offers a dynamic and adaptable solution for both development and production workflows.

kitops
KitOps is a packaging and versioning system for AI/ML projects that uses open standards so it works with the AI/ML, development, and DevOps tools you are already using. KitOps simplifies the handoffs between data scientists, application developers, and SREs working with LLMs and other AI/ML models. KitOps' ModelKits are a standards-based package for models, their dependencies, configurations, and codebases. ModelKits are portable, reproducible, and work with the tools you already use.
For similar tasks
persian-license-plate-recognition
The Persian License Plate Recognition (PLPR) system is a state-of-the-art solution designed for detecting and recognizing Persian license plates in images and video streams. Leveraging advanced deep learning models and a user-friendly interface, it ensures reliable performance across different scenarios. The system offers advanced detection using YOLOv5 models, precise recognition of Persian characters, real-time processing capabilities, and a user-friendly GUI. It is well-suited for applications in traffic monitoring, automated vehicle identification, and similar fields. The system's architecture includes modules for resident management, entrance management, and a detailed flowchart explaining the process from system initialization to displaying results in the GUI. Hardware requirements include an Intel Core i5 processor, 8 GB RAM, a dedicated GPU with at least 4 GB VRAM, and an SSD with 20 GB of free space. The system can be installed by cloning the repository and installing required Python packages. Users can customize the video source for processing and run the application to upload and process images or video streams. The system's GUI allows for parameter adjustments to optimize performance, and the Wiki provides in-depth information on the system's architecture and model training.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.