
merlin
Merlin: Empowering Multimodal LLMs with Foresight Minds
Stars: 74

Merlin is a groundbreaking model capable of generating natural language responses intricately linked with object trajectories of multiple images. It excels in predicting and reasoning about future events based on initial observations, showcasing unprecedented capability in future prediction and reasoning. Merlin achieves state-of-the-art performance on the Future Reasoning Benchmark and multiple existing multimodal language models benchmarks, demonstrating powerful multi-modal general ability and foresight minds.
README:
![]()
En Yu, Liang Zhao, Yana Wei, Jinrong Yang, Dongming Wu, Lingyu Kong, Haoran Wei, Tiancai Wang, Zheng Ge, Xiangyu Zhang, and Wenbing Tao
Merlin is a groundbreaking model capable of generating natural language responses that are intricately linked with object trajectories of multiple images. Merlin excels in predicting and reasoning about future events based on initial observations, showcasing an unprecedented capability in future prediction and reasoning. Merlin achieves SOTA performance on the established Future Reasoning Benchmark and mulitiple existing MLLM benchmark (MMbench and MMVet), which shows powerful multi-modal general ability and forsight minds.

Code, model weights, and demo will be released soon.
- [2024/07/01] 🔥🔥🔥Merlin is accepted by ECCV2024! We will open our Merlin-chat SFT data soon!
- [2024/05/06] 🔥🔥🔥We release the source code and weights of Merlin, including training and eval codes.
- Clone this repository and navigate to the project folder
git clone https://github.com/Ahnsun/merlin.git
cd /path/to/merlin- Install Package
conda create -n merlin python=3.10 -y
conda activate merlin
pip install e .- Install Flash-Attention
pip install ninja
pip install flash-attn --no-build-isolation
Please download the raw image or video data following the Merlin paper. To define new dataset information, refer to the merlin/mmgpt/utils/constants.py. We currently support two types of data reading:
- Using JSON to store annotations, where JSON files and images are stored locally or on S3.
- Using Tarfiles to simultaneously store images and annotation information, where the tarfile is stored locally or on S3.
Considering the inefficiency of reading large-scale and complex data from JSON files, and aiming to enhance data supply performance, we sincerely recommend using only the first type of data for supervised fine-tuning and the second type of data for pretraining. We are gradually eliminating the usage of JSON data during the pretraining process until all JSON data is exclusively used for supervised fine-tuning.
On top of these two types of data feeds, we support various types of data for online training:
-
Conversation Data: We've retained the [Vicuna]/[Llava]-style construction process for conversations, where each round of dialogue is tokenized and concatenated online. Additionally, we provide support for additional boxed data. You need to ensure that each sample includes bounding box coordinates in the "boxes" key, following the format [[x1, y1, h1, w1], ..., [xn, yn, hn, wn]] for all the boxes in the image. We highly recommend using this type of data for training only during the SFT (Supervised Fine-Tuning) process.
-
Image-Text Pair Data: This is our primary pretraining data type. All the data is preprocessed into tarfiles and streamed using the webdataset library. Since the LLM typically encounters the data only once during pretraining, we perform a weak shuffle of the data (reading 1000 samples as a local batch randomly from a tarfile each time). Furthermore, to ensure minimal data duplication, we use the InfiniteShardList to read all the tarfiles in a chain. We have default support for sequence merge logic: Each "getitem" operation directly extracts N image-text pairs and concatenates them into a sequence with an EOS token as a separator, without separating the attention mask. This approach maximizes the utilization of LLM's large context length and minimizes data bubbles during training. After extracting N image-text pair samples, we sequentially tokenize each pair online. We also pre-determine if the current pair would cause a context length overflow. If it does, we discard all subsequent samples. To support multi-task data training, we allow setting a task prompt for each pair of data and mask the task prompt token during training. This enables us to support single-turn QA conversation data in a similar format for pretraining. For handling more complex multi-turn QA conversations, we have pre-tokenized and organized 22 QA datasets, and we provide support for reading this pre-tokenized data as well.
-
Interpair Data: We've gone the extra mile to support data types where multiple images correspond to a single text in video/tracking tasks. We call this type of data "interleaved pair" (or simply interpair). And yes, this data also supports task prompts (which, in fact, are essential for multi-task training).
-
Interleave Data: To cater to the needs of interactive image-text data with multiple images and segments of text (such as MMC4, OBLISC, News, and more), we've implemented a one-to-many data organization using Run-Webdataset. This means that a text list corresponds to all the images in the text. We've diligently and comprehensively packaged various types of open-source and in-house interleave data into tarfiles. Interleave data tends to be longer, so we don't provide concatenation for this type of data. However, in the future, we'll explore more scientific and efficient approaches to data concatenation.
- Download the Merlin weights here.
- Download the Merlin-Chat weights here.
- Download the CLIP-VIT-L here.
Merlin is build based on MMGPT. MMGPT is to be an open-source MultiModal Generative Pretrained Transformers library based on PyTorch and Transformers.
Major features
-
Module Design
We decompose the MMGPT framework into different components and one can easily construct a customized MMGPT framework by combining different modules.
-
Support of various high-performance MMGPTs
The library directly includes multiple general understanding frameworks such as LLava, ChatSpot, Merlin.
-
One-click construction of deep and comprehensive benchmark evaluation
From mmbench to mmvet, from vqav2 to docvqa, whatever you want!
-
High-performance data provisioning mechanism
We have truly broken free from the shackles of ugly and complex low-performance data provisioning tied to JSON. Now, we offer high-performance and high-quality data assurance for a wide range of tasks such as image-text pairs, interleave, VQA (Visual Question Answering), and task prompted QA, spanning from 1,000 to 10,000,000,000 scale.
sh playground/merlin/clip-large+conv+vicuna-v15-7b/pretrain.sh
sh playground/merlin/clip-large+conv+vicuna-v15-7b/sft.shsh playground/merlin/clip-large+conv+vicuna-v15-7b/eval.shIf you have any questions related to the code or the paper, feel free to email En Yu ([email protected]).
Our model and weights are licensed for both researchers and commercial entities, upholding the principles of openness. The license is drafted by modification of the license of LLaMA.
See the LICENSE, as well as our accompanying Acceptable Use Policy.
If you find our work useful in your research, please consider citing Merlin:
@article{yuen2023merlin,
author = {Yu, En and Zhao, Liang and Wei, Yana and Yang, Jinrong and Wu, Dongming and Kong, Lingyu and Wei, Haoran and Wang, Tiancai and Ge, Zheng and Zhang, Xiangyu and Tao, Wenbing},
title = {Merlin: Empowering Multimodal LLMs with Foresight Minds},
journal = {arXiv preprint arXiv:2312.00589},
year = {2023},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for merlin
Similar Open Source Tools
merlin
Merlin is a groundbreaking model capable of generating natural language responses intricately linked with object trajectories of multiple images. It excels in predicting and reasoning about future events based on initial observations, showcasing unprecedented capability in future prediction and reasoning. Merlin achieves state-of-the-art performance on the Future Reasoning Benchmark and multiple existing multimodal language models benchmarks, demonstrating powerful multi-modal general ability and foresight minds.

magpie
This is the official repository for 'Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing'. Magpie is a tool designed to synthesize high-quality instruction data at scale by extracting it directly from an aligned Large Language Models (LLMs). It aims to democratize AI by generating large-scale alignment data and enhancing the transparency of model alignment processes. Magpie has been tested on various model families and can be used to fine-tune models for improved performance on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.

ChainForge
ChainForge is a visual programming environment for battle-testing prompts to LLMs. It is geared towards early-stage, quick-and-dirty exploration of prompts, chat responses, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can: * Query multiple LLMs at once to test prompt ideas and variations quickly and effectively. * Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case. * Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings. * Hold multiple conversations at once across template parameters and chat models. Template not just prompts, but follow-up chat messages, and inspect and evaluate outputs at each turn of a chat conversation. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals. This is an open beta of Chainforge. We support model providers OpenAI, HuggingFace, Anthropic, Google PaLM2, Azure OpenAI endpoints, and Dalai-hosted models Alpaca and Llama. You can change the exact model and individual model settings. Visualization nodes support numeric and boolean evaluation metrics. ChainForge is built on ReactFlow and Flask.

llm-course
The LLM course is divided into three parts: 1. 🧩 **LLM Fundamentals** covers essential knowledge about mathematics, Python, and neural networks. 2. 🧑🔬 **The LLM Scientist** focuses on building the best possible LLMs using the latest techniques. 3. 👷 **The LLM Engineer** focuses on creating LLM-based applications and deploying them. For an interactive version of this course, I created two **LLM assistants** that will answer questions and test your knowledge in a personalized way: * 🤗 **HuggingChat Assistant**: Free version using Mixtral-8x7B. * 🤖 **ChatGPT Assistant**: Requires a premium account. ## 📝 Notebooks A list of notebooks and articles related to large language models. ### Tools | Notebook | Description | Notebook | |----------|-------------|----------| | 🧐 LLM AutoEval | Automatically evaluate your LLMs using RunPod |  | | 🥱 LazyMergekit | Easily merge models using MergeKit in one click. |  | | 🦎 LazyAxolotl | Fine-tune models in the cloud using Axolotl in one click. |  | | ⚡ AutoQuant | Quantize LLMs in GGUF, GPTQ, EXL2, AWQ, and HQQ formats in one click. |  | | 🌳 Model Family Tree | Visualize the family tree of merged models. |  | | 🚀 ZeroSpace | Automatically create a Gradio chat interface using a free ZeroGPU. |  |

graphrag-local-ollama
GraphRAG Local Ollama is a repository that offers an adaptation of Microsoft's GraphRAG, customized to support local models downloaded using Ollama. It enables users to leverage local models with Ollama for large language models (LLMs) and embeddings, eliminating the need for costly OpenAPI models. The repository provides a simple setup process and allows users to perform question answering over private text corpora by building a graph-based text index and generating community summaries for closely-related entities. GraphRAG Local Ollama aims to improve the comprehensiveness and diversity of generated answers for global sensemaking questions over datasets.

nixtla
Nixtla is a production-ready generative pretrained transformer for time series forecasting and anomaly detection. It can accurately predict various domains such as retail, electricity, finance, and IoT with just a few lines of code. TimeGPT introduces a paradigm shift with its standout performance, efficiency, and simplicity, making it accessible even to users with minimal coding experience. The model is based on self-attention and is independently trained on a vast time series dataset to minimize forecasting error. It offers features like zero-shot inference, fine-tuning, API access, adding exogenous variables, multiple series forecasting, custom loss function, cross-validation, prediction intervals, and handling irregular timestamps.

gepa
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.

Controllable-RAG-Agent
This repository contains a sophisticated deterministic graph-based solution for answering complex questions using a controllable autonomous agent. The solution is designed to ensure that answers are solely based on the provided data, avoiding hallucinations. It involves various steps such as PDF loading, text preprocessing, summarization, database creation, encoding, and utilizing large language models. The algorithm follows a detailed workflow involving planning, retrieval, answering, replanning, content distillation, and performance evaluation. Heuristics and techniques implemented focus on content encoding, anonymizing questions, task breakdown, content distillation, chain of thought answering, verification, and model performance evaluation.

Docs2KG
Docs2KG is a tool designed for constructing a unified knowledge graph from heterogeneous documents. It addresses the challenges of digitizing diverse unstructured documents and constructing a high-quality knowledge graph with less effort. The tool combines bottom-up and top-down approaches, utilizing a human-LLM collaborative interface to enhance the generated knowledge graph. It organizes the knowledge graph into MetaKG, LayoutKG, and SemanticKG, providing a comprehensive view of document content. Docs2KG aims to streamline the process of knowledge graph construction and offers metrics for evaluating the quality of automatic construction.
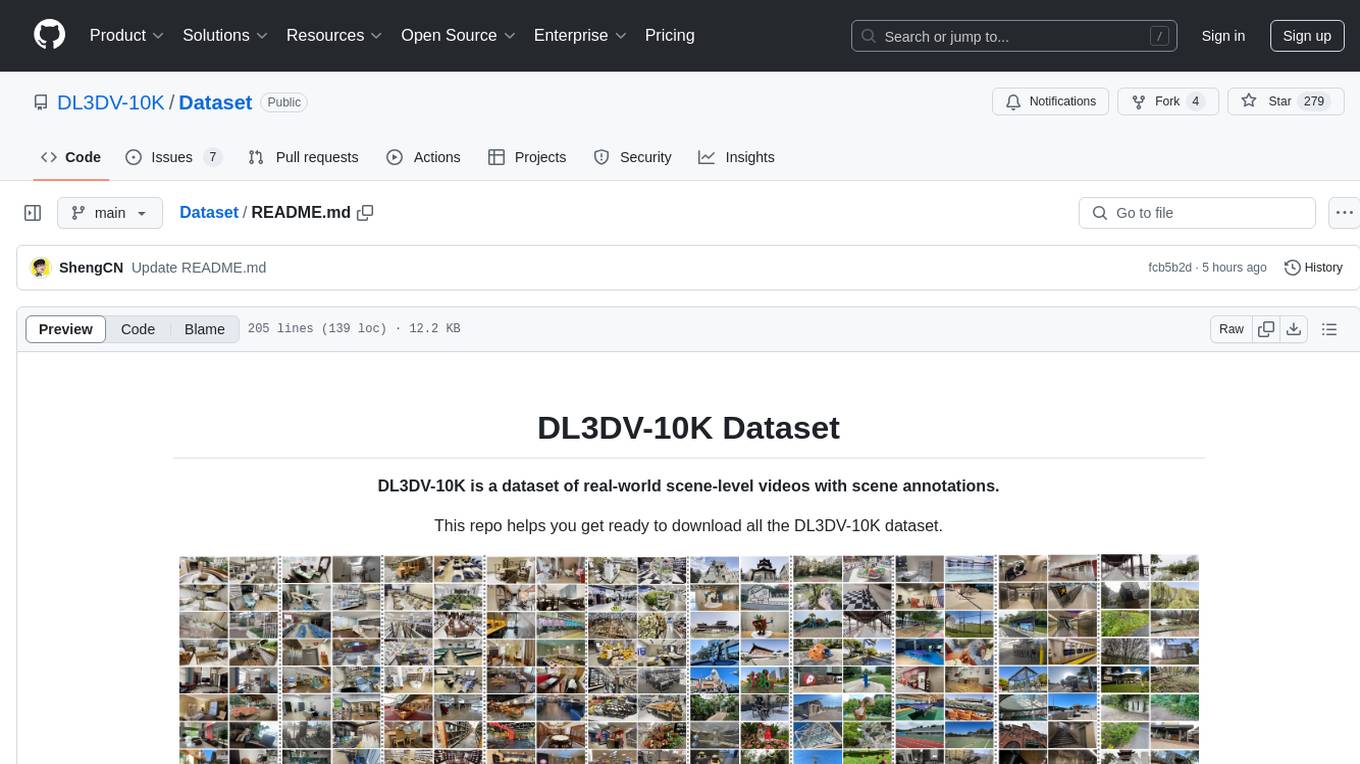
Dataset
DL3DV-10K is a large-scale dataset of real-world scene-level videos with annotations, covering diverse scenes with different levels of reflection, transparency, and lighting. It includes 10,510 multi-view scenes with 51.2 million frames at 4k resolution, and offers benchmark videos for novel view synthesis (NVS) methods. The dataset is designed to facilitate research in deep learning-based 3D vision and provides valuable insights for future research in NVS and 3D representation learning.

MMStar
MMStar is an elite vision-indispensable multi-modal benchmark comprising 1,500 challenge samples meticulously selected by humans. It addresses two key issues in current LLM evaluation: the unnecessary use of visual content in many samples and the existence of unintentional data leakage in LLM and LVLM training. MMStar evaluates 6 core capabilities across 18 detailed axes, ensuring a balanced distribution of samples across all dimensions.
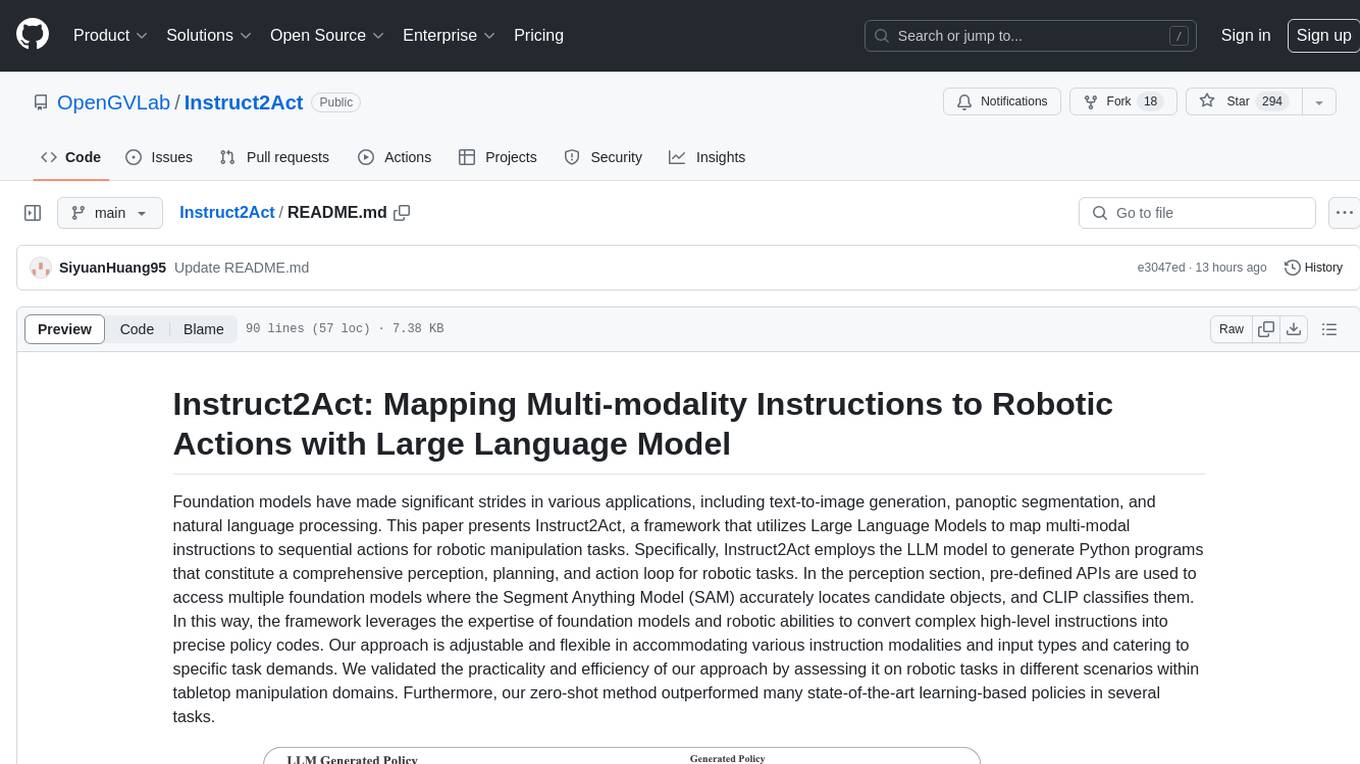
Instruct2Act
Instruct2Act is a framework that utilizes Large Language Models to map multi-modal instructions to sequential actions for robotic manipulation tasks. It generates Python programs using the LLM model for perception, planning, and action. The framework leverages foundation models like SAM and CLIP to convert high-level instructions into policy codes, accommodating various instruction modalities and task demands. Instruct2Act has been validated on robotic tasks in tabletop manipulation domains, outperforming learning-based policies in several tasks.
DataFrame
DataFrame is a C++ analytical library designed for data analysis similar to libraries in Python and R. It allows you to slice, join, merge, group-by, and perform various statistical, summarization, financial, and ML algorithms on your data. DataFrame also includes a large collection of analytical algorithms in form of visitors, ranging from basic stats to more involved analysis. You can easily add your own algorithms as well. DataFrame employs extensive multithreading in almost all its APIs, making it suitable for analyzing large datasets. Key principles followed in the library include supporting any type without needing new code, avoiding pointer chasing, having all column data in contiguous memory space, minimizing space usage, avoiding data copying, using multi-threading judiciously, and not protecting the user against garbage in, garbage out.

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.

semlib
Semlib is a Python library for building data processing and data analysis pipelines that leverage the power of large language models (LLMs). It provides functional programming primitives like map, reduce, sort, and filter, programmed with natural language descriptions. Semlib handles complexities such as prompting, parsing, concurrency control, caching, and cost tracking. The library breaks down sophisticated data processing tasks into simpler steps to improve quality, feasibility, latency, cost, security, and flexibility of data processing tasks.

datasets
Datasets is a repository that provides a collection of various datasets for machine learning and data analysis projects. It includes datasets in different formats such as CSV, JSON, and Excel, covering a wide range of topics including finance, healthcare, marketing, and more. The repository aims to help data scientists, researchers, and students access high-quality datasets for training models, conducting experiments, and exploring data analysis techniques.
For similar tasks

Co-LLM-Agents
This repository contains code for building cooperative embodied agents modularly with large language models. The agents are trained to perform tasks in two different environments: ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH). TDW-MAT is a multi-agent environment where agents must transport objects to a goal position using containers. C-WAH is an extension of the Watch-And-Help challenge, which enables agents to send messages to each other. The code in this repository can be used to train agents to perform tasks in both of these environments.

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.

kan-gpt
The KAN-GPT repository is a PyTorch implementation of Generative Pre-trained Transformers (GPTs) using Kolmogorov-Arnold Networks (KANs) for language modeling. It provides a model for generating text based on prompts, with a focus on improving performance compared to traditional MLP-GPT models. The repository includes scripts for training the model, downloading datasets, and evaluating model performance. Development tasks include integrating with other libraries, testing, and documentation.

LLM-SFT
LLM-SFT is a Chinese large model fine-tuning tool that supports models such as ChatGLM, LlaMA, Bloom, Baichuan-7B, and frameworks like LoRA, QLoRA, DeepSpeed, UI, and TensorboardX. It facilitates tasks like fine-tuning, inference, evaluation, and API integration. The tool provides pre-trained weights for various models and datasets for Chinese language processing. It requires specific versions of libraries like transformers and torch for different functionalities.

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.