
Here-Comes-the-AI-Worm
Here Comes the AI Worm: Preventing the Propagation of Adversarial Self-Replicating Prompts Within GenAI Ecosystems
Stars: 205
Large Language Models (LLMs) are now embedded in everyday tools like email assistants, chat apps, and productivity software. This project introduces DonkeyRail, a lightweight guardrail that detects and blocks malicious self-replicating prompts known as RAGworm within GenAI-powered applications. The guardrail is fast, accurate, and practical for real-world GenAI systems, preventing activities like spam, phishing campaigns, and data leaks.
README:
Here Comes the AI Worm: Preventing the Propagation of Adversarial Self-Replicating Prompts Within GenAI Ecosystems
Stav Cohen ,
Ron Bitton ,
Ben Nassi
Technion - Israel Institute of Technology
,Cornell Tech, Tel Aviv University, Intuit
Website |
YouTube Video |
ArXiv Paper V1 |
ACM CCS 2025 Paper
![]()
Large Language Models (LLMs) are now embedded in everyday tools like email assistants, chat apps, and productivity software. Many of these systems use Retrieval-Augmented Generation (RAG) to pull in outside information and make responses more useful.
But this connectivity also creates new risks. In this project, we show how a malicious self-replicating prompt can act like a computer worm, spreading automatically across GenAI-powered applications. We call this attack RAGworm. Once inside, it can force apps to send spam, run phishing campaigns, or even leak private data — all without the user realizing it.
To stop this, we built DonkeyRail, a lightweight guardrail that detects and blocks these worms in real time. DonkeyRail is fast, accurate, and adds almost no delay, making it practical for real-world GenAI systems.
In this paper, we show that when the communication between GenAI-powered applications relies on RAG-based inference, an attacker can initiate a computer worm-like chain reaction that we call RAGworm.
This is done by crafting an adversarial self-replicating prompt that triggers a cascade of indirect prompt injections within the ecosystem and forces each affected application to perform malicious actions and compromise the RAG of additional applications.
We evaluate the performance of the worm in creating a chain of malicious activities intended to promote content, distribute propaganda, and extract confidential user data within a GenAI ecosystem of GenAI-powered email assistants.
We demonstrate that RAGworm can trigger the aforementioned malicious activities with a super-linear propagation rate, where each client compromises 20 new clients within the first 1–3 days (depending on the number of emails sent per day).
In addition, we analyze how the performance of RAGworm is affected by various factors.
Finally, we introduce DonkeyRail, a guardrail intended to detect and prevent the propagation of RAGworm with minimal latency, high accuracy, and a low false-positive rate. We evaluate the guardrail’s performance and show that it yields a true-positive rate of 1.0 with a false-positive rate of 0.017 while adding a negligible latency of 7.6–38.3 ms (depending on the number of documents retrieved).
We also show that the guardrail is robust against out-of-distribution worms, consisting of unseen jailbreaking prompts and various worm use cases.
-
Datasets: Contains the datasets used in our experiments for both the Worm and the Guardrail. These datasets are referenced in the code and described in detail in the paper.
-
Demos: Includes three README files:
- A demo showing the input and output of RAGworm with different payloads.
- A demo showing the number of retrieved documents from the RAG when using Copilot (work email assistant) and Gemini Workspace (work email assistant).
- A demo showing a full end-to-end demo of RAGworm running on Gemini Workspace.
-
Self_Replicating_Test - Contains code to test the self-replicating trait of prompts on various LLMs.
-
Worm_Evaluation - Contains code to evaluate the performance of RAGworm with respect to Retrieval rate and overall success rate.
-
DonkeyRail - Contains the implementation of the DonkeyRail guardrail, including the models, preprocessing steps, training data and evaluation scripts. At the end of the DonkeyRail.ipynb file you can find a pipline showing how to use the guardrail in a real-world scenario.
-
Legacy Arxiv Paper: - Contains the legacy arxiv code used for the Arxiv paper. The code is not maintained and is provided for reference only.
TBD with the ACM CCS 2025 paper
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Here-Comes-the-AI-Worm
Similar Open Source Tools
Here-Comes-the-AI-Worm
Large Language Models (LLMs) are now embedded in everyday tools like email assistants, chat apps, and productivity software. This project introduces DonkeyRail, a lightweight guardrail that detects and blocks malicious self-replicating prompts known as RAGworm within GenAI-powered applications. The guardrail is fast, accurate, and practical for real-world GenAI systems, preventing activities like spam, phishing campaigns, and data leaks.

ChainForge
ChainForge is a visual programming environment for battle-testing prompts to LLMs. It is geared towards early-stage, quick-and-dirty exploration of prompts, chat responses, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can: * Query multiple LLMs at once to test prompt ideas and variations quickly and effectively. * Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case. * Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings. * Hold multiple conversations at once across template parameters and chat models. Template not just prompts, but follow-up chat messages, and inspect and evaluate outputs at each turn of a chat conversation. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals. This is an open beta of Chainforge. We support model providers OpenAI, HuggingFace, Anthropic, Google PaLM2, Azure OpenAI endpoints, and Dalai-hosted models Alpaca and Llama. You can change the exact model and individual model settings. Visualization nodes support numeric and boolean evaluation metrics. ChainForge is built on ReactFlow and Flask.

AIlice
AIlice is a fully autonomous, general-purpose AI agent that aims to create a standalone artificial intelligence assistant, similar to JARVIS, based on the open-source LLM. AIlice achieves this goal by building a "text computer" that uses a Large Language Model (LLM) as its core processor. Currently, AIlice demonstrates proficiency in a range of tasks, including thematic research, coding, system management, literature reviews, and complex hybrid tasks that go beyond these basic capabilities. AIlice has reached near-perfect performance in everyday tasks using GPT-4 and is making strides towards practical application with the latest open-source models. We will ultimately achieve self-evolution of AI agents. That is, AI agents will autonomously build their own feature expansions and new types of agents, unleashing LLM's knowledge and reasoning capabilities into the real world seamlessly.

llmops-promptflow-template
LLMOps with Prompt flow is a template and guidance for building LLM-infused apps using Prompt flow. It provides centralized code hosting, lifecycle management, variant and hyperparameter experimentation, A/B deployment, many-to-many dataset/flow relationships, multiple deployment targets, comprehensive reporting, BYOF capabilities, configuration-based development, local prompt experimentation and evaluation, endpoint testing, and optional Human-in-loop validation. The tool is customizable to suit various application needs.
HybridAGI
HybridAGI is the first Programmable LLM-based Autonomous Agent that lets you program its behavior using a **graph-based prompt programming** approach. This state-of-the-art feature allows the AGI to efficiently use any tool while controlling the long-term behavior of the agent. Become the _first Prompt Programmers in history_ ; be a part of the AI revolution one node at a time! **Disclaimer: We are currently in the process of upgrading the codebase to integrate DSPy**
foundationallm
FoundationaLLM is a platform designed for deploying, scaling, securing, and governing generative AI in enterprises. It allows users to create AI agents grounded in enterprise data, integrate REST APIs, experiment with various large language models, centrally manage AI agents and their assets, deploy scalable vectorization data pipelines, enable non-developer users to create their own AI agents, control access with role-based access controls, and harness capabilities from Azure AI and Azure OpenAI. The platform simplifies integration with enterprise data sources, provides fine-grain security controls, scalability, extensibility, and addresses the challenges of delivering enterprise copilots or AI agents.
foundationallm
FoundationaLLM is a platform designed for deploying, scaling, securing, and governing generative AI in enterprises. It allows users to create AI agents grounded in enterprise data, integrate REST APIs, experiment with large language models, centrally manage AI agents and assets, deploy scalable vectorization data pipelines, enable non-developer users to create their own AI agents, control access with role-based access controls, and harness capabilities from Azure AI and Azure OpenAI. The platform simplifies integration with enterprise data sources, provides fine-grain security controls, load balances across multiple endpoints, and is extensible to new data sources and orchestrators. FoundationaLLM addresses the need for customized copilots or AI agents that are secure, licensed, flexible, and suitable for enterprise-scale production.
Electronic-Component-Sorter
The Electronic Component Classifier is a project that uses machine learning and artificial intelligence to automate the identification and classification of electrical and electronic components. It features component classification into seven classes, user-friendly design, and integration with Flask for a user-friendly interface. The project aims to reduce human error in component identification, make the process safer and more reliable, and potentially help visually impaired individuals in identifying electronic components.
ask-astro
Ask Astro is an open-source reference implementation of Andreessen Horowitz's LLM Application Architecture built by Astronomer. It provides an end-to-end example of a Q&A LLM application used to answer questions about Apache Airflow® and Astronomer. Ask Astro includes Airflow DAGs for data ingestion, an API for business logic, a Slack bot, a public UI, and DAGs for processing user feedback. The tool is divided into data retrieval & embedding, prompt orchestration, and feedback loops.
skyeye
SkyEye is an AI-powered Ground Controlled Intercept (GCI) bot designed for the flight simulator Digital Combat Simulator (DCS). It serves as an advanced replacement for the in-game E-2, E-3, and A-50 AI aircraft, offering modern voice recognition, natural-sounding voices, real-world brevity and procedures, a wide range of commands, and intelligent battlespace monitoring. The tool uses Speech-To-Text and Text-To-Speech technology, can run locally or on a cloud server, and is production-ready software used by various DCS communities.
chatgpt-universe
ChatGPT is a large language model that can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in a conversational way. It is trained on a massive amount of text data, and it is able to understand and respond to a wide range of natural language prompts. Here are 5 jobs suitable for this tool, in lowercase letters: 1. content writer 2. chatbot assistant 3. language translator 4. creative writer 5. researcher

raft
RAFT (Retrieval-Augmented Fine-Tuning) is a method for creating conversational agents that realistically emulate specific human targets. It involves a dual-phase process of fine-tuning and retrieval-based augmentation to generate nuanced and personalized dialogue. The tool is designed to combine interview transcripts with memories from past writings to enhance language model responses. RAFT has the potential to advance the field of personalized, context-sensitive conversational agents.
Document-Knowledge-Mining-Solution-Accelerator
The Document Knowledge Mining Solution Accelerator leverages Azure OpenAI and Azure AI Document Intelligence to ingest, extract, and classify content from various assets, enabling chat-based insight discovery, analysis, and prompt guidance. It uses OCR and multi-modal LLM to extract information from documents like text, handwritten text, charts, graphs, tables, and form fields. Users can customize the technical architecture and data processing workflow. Key features include ingesting and extracting real-world entities, chat-based insights discovery, text and document data analysis, prompt suggestion guidance, and multi-modal information processing.
motleycrew
Motleycrew is an ultimate framework for building multi-agent AI systems, allowing users to mix and match AI agents and tools from popular frameworks, design advanced workflows, and leverage dynamic knowledge graphs with simplicity and elegance. It acts as a conductor orchestrating a symphony of AI agents and tools, providing building blocks for creating AI systems and enabling users to focus on high-level design while taking care of the rest. The framework offers integration with various tools, flexibility in providing agents with tools or other agents, advanced flow design capabilities, and built-in observability and caching features.
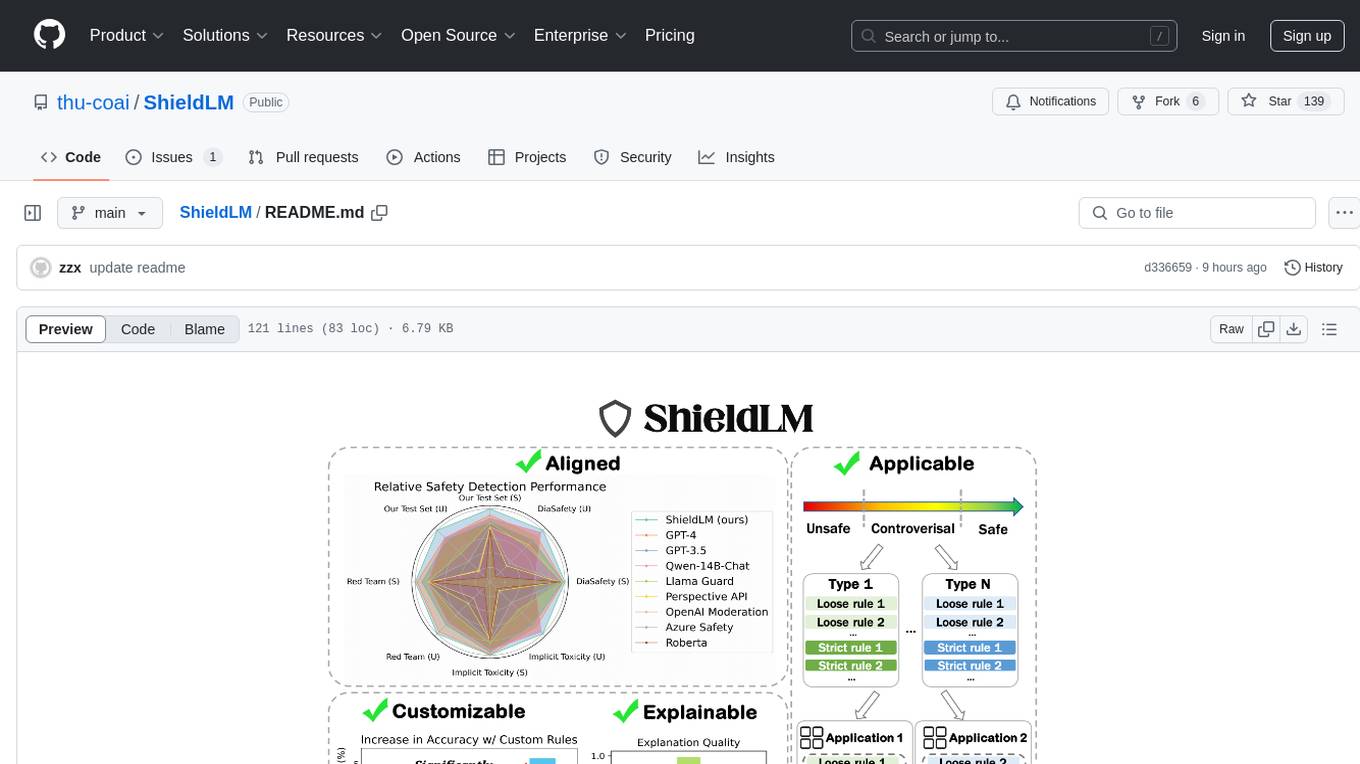
ShieldLM
ShieldLM is a bilingual safety detector designed to detect safety issues in LLMs' generations. It aligns with human safety standards, supports customizable detection rules, and provides explanations for decisions. Outperforming strong baselines, ShieldLM is impressive across 4 test sets.
For similar tasks
Here-Comes-the-AI-Worm
Large Language Models (LLMs) are now embedded in everyday tools like email assistants, chat apps, and productivity software. This project introduces DonkeyRail, a lightweight guardrail that detects and blocks malicious self-replicating prompts known as RAGworm within GenAI-powered applications. The guardrail is fast, accurate, and practical for real-world GenAI systems, preventing activities like spam, phishing campaigns, and data leaks.
last_layer
last_layer is a security library designed to protect LLM applications from prompt injection attacks, jailbreaks, and exploits. It acts as a robust filtering layer to scrutinize prompts before they are processed by LLMs, ensuring that only safe and appropriate content is allowed through. The tool offers ultra-fast scanning with low latency, privacy-focused operation without tracking or network calls, compatibility with serverless platforms, advanced threat detection mechanisms, and regular updates to adapt to evolving security challenges. It significantly reduces the risk of prompt-based attacks and exploits but cannot guarantee complete protection against all possible threats.
Cyberion-Spark-X
Cyberion-Spark-X is a powerful open-source tool designed for cybersecurity professionals and data analysts. It provides advanced capabilities for analyzing and visualizing large datasets to detect security threats and anomalies. The tool integrates with popular data sources and supports various machine learning algorithms for predictive analytics and anomaly detection. Cyberion-Spark-X is user-friendly and highly customizable, making it suitable for both beginners and experienced professionals in the field of cybersecurity and data analysis.

sec-gemini
Sec-Gemini is an experimental cybersecurity-focused AI tool developed by Google. This repository contains SDKs and a CLI for Sec-Gemini, with SDKs available for Python and TypeScript. Additionally, there is a web component provided to facilitate integration on websites.
HydraDragonPlatform
Hydra Dragon Automatic Malware/Executable Analysis Platform offers dynamic and static analysis for Windows, including open-source XDR projects, ClamAV, YARA-X, machine learning AI, behavioral analysis, Unpacker, Deobfuscator, Decompiler, website signatures, Ghidra, Suricata, Sigma, Kernel based protection, and more. It is a Unified Executable Analysis & Detection Framework.

invariant
Invariant Analyzer is an open-source scanner designed for LLM-based AI agents to find bugs, vulnerabilities, and security threats. It scans agent execution traces to identify issues like looping behavior, data leaks, prompt injections, and unsafe code execution. The tool offers a library of built-in checkers, an expressive policy language, data flow analysis, real-time monitoring, and extensible architecture for custom checkers. It helps developers debug AI agents, scan for security violations, and prevent security issues and data breaches during runtime. The analyzer leverages deep contextual understanding and a purpose-built rule matching engine for security policy enforcement.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.