
kaapana
Kaapana is an open source toolkit for state of the art platform provisioning in the field of medical data analysis. The applications comprise AI-based workflows and federated learning scenarios with a focus on radiological and radiotherapeutic imaging. The name Kaapana comes from the Hawaiian word kaʻāpana, meaning "distributor" or "part".
Stars: 176

Kaapana is an open-source toolkit for state-of-the-art platform provisioning in the field of medical data analysis. The applications comprise AI-based workflows and federated learning scenarios with a focus on radiological and radiotherapeutic imaging. Obtaining large amounts of medical data necessary for developing and training modern machine learning methods is an extremely challenging effort that often fails in a multi-center setting, e.g. due to technical, organizational and legal hurdles. A federated approach where the data remains under the authority of the individual institutions and is only processed on-site is, in contrast, a promising approach ideally suited to overcome these difficulties. Following this federated concept, the goal of Kaapana is to provide a framework and a set of tools for sharing data processing algorithms, for standardized workflow design and execution as well as for performing distributed method development. This will facilitate data analysis in a compliant way enabling researchers and clinicians to perform large-scale multi-center studies. By adhering to established standards and by adopting widely used open technologies for private cloud development and containerized data processing, Kaapana integrates seamlessly with the existing clinical IT infrastructure, such as the Picture Archiving and Communication System (PACS), and ensures modularity and easy extensibility.
README:
Kaapana is an open-source toolkit for state-of-the-art platform provisioning in the field of medical data analysis. The applications comprise AI-based workflows and federated learning scenarios with a focus on radiological and radiotherapeutic imaging. The name Kaapana comes from the Hawaiian word kaʻāpana, meaning "distributor" or "part".
Obtaining large amounts of medical data necessary for developing and training modern machine learning methods is an extremely challenging effort that often fails in a multi-center setting, e.g. due to technical, organizational and legal hurdles. A federated approach where the data remains under the authority of the individual institutions and is only processed on-site is, in contrast, a promising approach ideally suited to overcome these difficulties.
Following this federated concept, the goal of Kaapana is to provide a framework and a set of tools for sharing data processing algorithms, for standardized workflow design and execution as well as for performing distributed method development. This will facilitate data analysis in a compliant way enabling researchers and clinicians to perform large-scale multi-center studies.
By adhering to established standards and by adopting widely used open technologies for private cloud development and containerized data processing, Kaapana integrates seamlessly with the existing clinical IT infrastructure, such as the Picture Archiving and Communication System (PACS), and ensures modularity and easy extensibility.
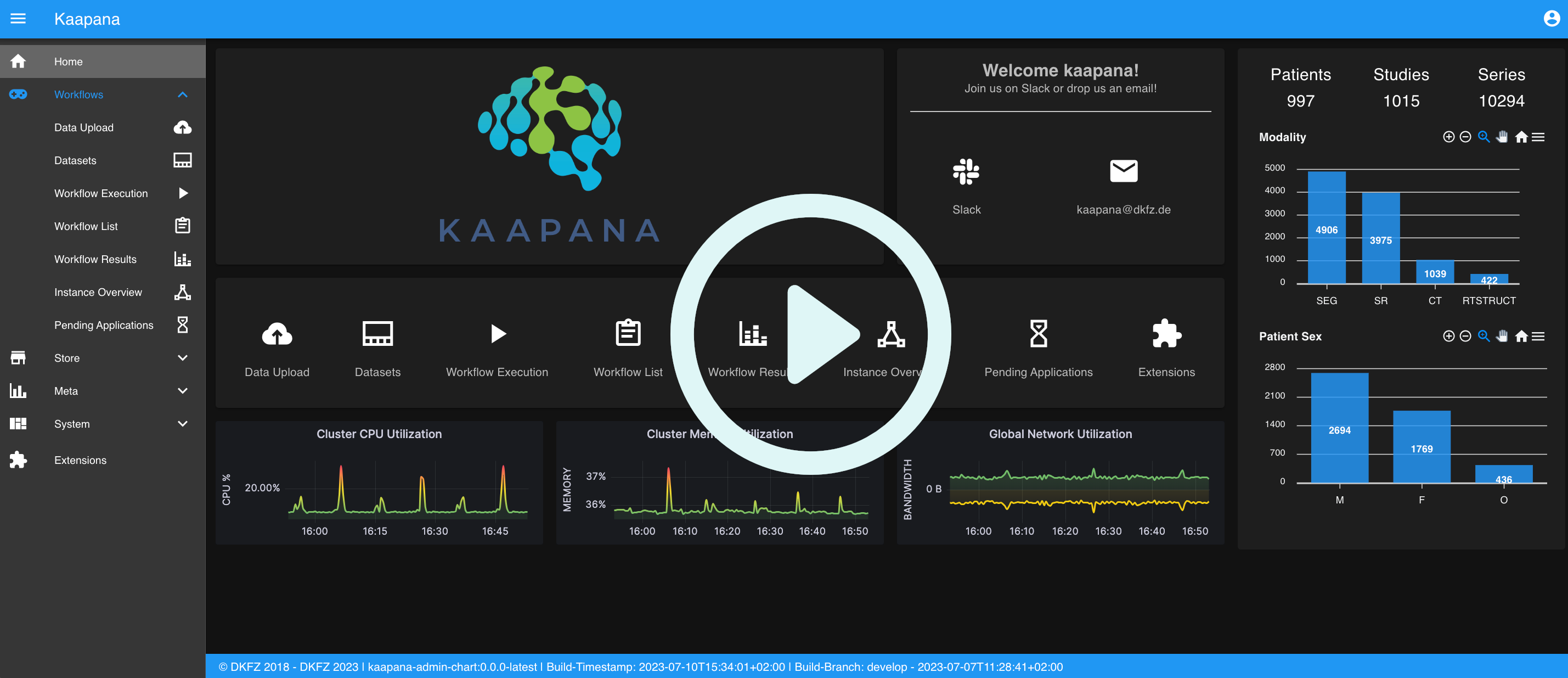
Core components of Kaapana:
- Workflow management: Large-scale image processing with SOTA deep learning algorithms, such as nnU-Net image segmentation and TotalSegmentator
- Datasets: Exploration, visualization and curation of medical images
- Extensions: Simple integration of new, customized algorithms and applications into the framework
- Storage: An integrated PACS system and Minio for other types of data
- System monitoring: Extensive resource and system monitoring for administrators
- User management Simple user management via Keycloak
Core technologies used in Kaapana:
- Kubernetes: Container orchestration system
- Helm: The package manager for Kubernetes
- Airflow: Workflow management system enabling complex and flexible data processing workflows
- OpenSearch: Search engine for DICOM metadata-based searches
- dcm4chee: Open source PACS system serving as a central DICOM data storage
- Prometheus: Collecting metrics for system monitoring
- Grafana: Visualization for monitoring metrics
- Keycloak: User authentication
- OHIF Viewers: Visualization of medical images
Currently, Kaapana is used in multiple projects in which a Kaapana-based platform is deployed at multiple clinical sites with the objective of distributed radiological image analysis and quantification. The projects include RACOON initiated by NUM with all 38 German university clinics participating, the Joint Imaging Platform (JIP) initiated by the German Cancer Consortium (DKTK) with 11 university clinics participating as well as DART initiated by the Cancer Core Europe with 7 cancer research centers participating.
For more information, please also take a look at our publication of the Kaapana-based Joint Imaging Platform in JCO Clinical Cancer Informatics.
Check out the documentation for further information about how Kaapana works, for instructions on how to build, deploy, use and further develop the platform.
- GitLab: The main Kaapana repository, mirrored on GitHub.
- Slack: Join the community for discussions and updates.
- YouTube: Tutorials, demos and more in-depth presentations.
- Website
As of Kaapana 0.2.0 we follow strict SemVer approach to versioning.
Please cite the following paper when using Kaapana:
Jonas Scherer, Marco Nolden, Jens Kleesiek, Jasmin Metzger, Klaus Kades, Verena Schneider, Michael Bach, Oliver Sedlaczek, Andreas M. Bucher, Thomas J. Vogl, ...Klaus Maier-Hein. Joint Imaging Platform for Federated Clinical Data Analytics. JCO Clinical Cancer Informatics, 4:10271038, November 2020. doi: 10.1200/CCI.20.00045. URL https://ascopubs.org/doi/full/10.1200/CCI.20.00045.
When using Kapaana for federated learning please also cite the following paper:
Klaus Kades, Jonas Scherer, Maximilian Zenk, Marius Kempf, and Klaus MaierHein. Towards Real-World Federated Learning in Medical Image Analysis Using Kaapana. In Distributed, Collaborative, and Federated Learning, and Affordable AI and Healthcare for Resource Diverse Global Health, pages 130140, Cham, 2022b. Springer Nature Switzerland. ISBN 978-3-031-18523-6. doi: 10.1007/978-3-031-18523-6_13. URL https://doi.org/10.1007/978-3-031-18523-6_13.
This program is free software: you can redistribute it and/or modify it under the terms of the GNU Affero General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Affero General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program (see file LICENCE).
If not, see https://www.gnu.org/licenses/.
You can use Kaapana to build any product you like, including commercial closed-source ones since it is a highly modular system. Kaapana is licensed under the GNU Affero General Public License for now since we want to ensure that we can integrate all developments and contributions to its core system for maximum benefit to the community and give everything back. We consider switching to a more liberal license in the future. This decision will depend on how our project develops and what the feedback from the community is regarding the license.
Kaapana is built upon the great work of many other open-source projects, see the documentation for details. For now, we only release source code we created ourselves since providing pre-built docker containers and licensing for highly modular container-based systems is a complex task. We have done our very best to fulfill all requirements, and the choice of AGPL was motivated mainly to make sure we can improve and advance Kaapana in the best way for the whole community. If you have thoughts about this or if you disagree with our way of using a particular third-party toolkit or miss something please let us know and get in touch. We are open to any feedback and advice on this challenging topic.
If you want to contribute to Kaapana by submitting an issue or code please have a look at our contribution guide.
Building Data Rich Clinical Trials - CCE_DART: This project has received funding from the European Union’s Horizon 2020 research and innovation program under grant agreement No 965397. Website: https://cce-dart.com/
Capturing Tumor Heterogeneity in Hepatocellular Carcinoma - A Radiomics Approach Systematically Tested in Transgenic Mice This project is partially funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – 410981386. Website: https://gepris.dfg.de/gepris/projekt/410981386
Data Science Driven Surgical Oncology Project: This work was partially supported by the Data Science Driven Surgical Oncology Project (DSdSO), funded by the Surgical Oncology Program at the National Center for Tumor Diseases (NCT), Heidelberg, a partnership by DKFZ, UKHD, Heidelberg University. Website: https://www.nct-heidelberg.de/forschung/precision-local-therapy-and-image-guidance/surgical-oncology.html
Joint Imaging Platform: This work was partially supported by Joint Imaging Platform, funded by the German Cancer Consortium. Website: https://jip.dktk.dkfz.de/jiphomepage/
HiGHmed: This work was partially supported by the HiGHmed Consortium, funded by the German Federal Ministry of Education and Research (BMBF, funding code 01ZZ1802A). Website: https://highmed.org/
RACOON: This work was partially supported by RACOON, funded by the German Federal Ministry of Education and ResearchDieses in the Netzwerk Universitätsmedizin (NUM; funding code 01KX2021). Website: https://www.netzwerk-universitaetsmedizin.de/projekte/racoon
Trustworthy Federated Data Analysis - TFDA: This work is partially funded by the Helmholtz Association within the project "Trustworthy Federated Data Analytics” (TFDA) (funding number ZT-I-OO1 4). Website: https://tfda.hmsp.center/
Copyright (C) 2024 German Cancer Research Center (DKFZ)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for kaapana
Similar Open Source Tools
kaapana
Kaapana is an open-source toolkit for state-of-the-art platform provisioning in the field of medical data analysis. The applications comprise AI-based workflows and federated learning scenarios with a focus on radiological and radiotherapeutic imaging. Obtaining large amounts of medical data necessary for developing and training modern machine learning methods is an extremely challenging effort that often fails in a multi-center setting, e.g. due to technical, organizational and legal hurdles. A federated approach where the data remains under the authority of the individual institutions and is only processed on-site is, in contrast, a promising approach ideally suited to overcome these difficulties. Following this federated concept, the goal of Kaapana is to provide a framework and a set of tools for sharing data processing algorithms, for standardized workflow design and execution as well as for performing distributed method development. This will facilitate data analysis in a compliant way enabling researchers and clinicians to perform large-scale multi-center studies. By adhering to established standards and by adopting widely used open technologies for private cloud development and containerized data processing, Kaapana integrates seamlessly with the existing clinical IT infrastructure, such as the Picture Archiving and Communication System (PACS), and ensures modularity and easy extensibility.

Me-LLaMA
Me LLaMA introduces a suite of open-source medical Large Language Models (LLMs), including Me LLaMA 13B/70B and their chat-enhanced versions. Developed through innovative continual pre-training and instruction tuning, these models leverage a vast medical corpus comprising PubMed papers, medical guidelines, and general domain data. Me LLaMA sets new benchmarks on medical reasoning tasks, making it a significant asset for medical NLP applications and research. The models are intended for computational linguistics and medical research, not for clinical decision-making without validation and regulatory approval.
dioptra
Dioptra is a software test platform for assessing the trustworthy characteristics of artificial intelligence (AI). It supports the NIST AI Risk Management Framework by providing functionality to assess, analyze, and track identified AI risks. Dioptra provides a REST API and can be controlled via a web interface or Python client for designing, managing, executing, and tracking experiments. It aims to be reproducible, traceable, extensible, interoperable, modular, secure, interactive, shareable, and reusable.

RecAI
RecAI is a project that explores the integration of Large Language Models (LLMs) into recommender systems, addressing the challenges of interactivity, explainability, and controllability. It aims to bridge the gap between general-purpose LLMs and domain-specific recommender systems, providing a holistic perspective on the practical requirements of LLM4Rec. The project investigates various techniques, including Recommender AI agents, selective knowledge injection, fine-tuning language models, evaluation, and LLMs as model explainers, to create more sophisticated, interactive, and user-centric recommender systems.
jentic-public-apis
The Jentic Public APIs repository aims to collate all knowledge about the world's APIs into a detailed, comprehensive, structured documentation catalog designed for use by AI. It focuses on standardized OpenAPI specifications, Arazzo workflows, associated tooling, evaluations, and RFCs for extensions to open formats. The project is in ALPHA stage and welcomes contributions to accelerate the effort of building an open knowledge foundation for AI agents.

llmops-promptflow-template
LLMOps with Prompt flow is a template and guidance for building LLM-infused apps using Prompt flow. It provides centralized code hosting, lifecycle management, variant and hyperparameter experimentation, A/B deployment, many-to-many dataset/flow relationships, multiple deployment targets, comprehensive reporting, BYOF capabilities, configuration-based development, local prompt experimentation and evaluation, endpoint testing, and optional Human-in-loop validation. The tool is customizable to suit various application needs.
DevOpsGPT
DevOpsGPT is an AI-driven software development automation solution that combines Large Language Models (LLM) with DevOps tools to convert natural language requirements into working software. It improves development efficiency by eliminating the need for tedious requirement documentation, shortens development cycles, reduces communication costs, and ensures high-quality deliverables. The Enterprise Edition offers features like existing project analysis, professional model selection, and support for more DevOps platforms. The tool automates requirement development, generates interface documentation, provides pseudocode based on existing projects, facilitates code refinement, enables continuous integration, and supports software version release. Users can run DevOpsGPT with source code or Docker, and the tool comes with limitations in precise documentation generation and understanding existing project code. The product roadmap includes accurate requirement decomposition, rapid import of development requirements, and integration of more software engineering and professional tools for efficient software development tasks under AI planning and execution.
Document-Knowledge-Mining-Solution-Accelerator
The Document Knowledge Mining Solution Accelerator leverages Azure OpenAI and Azure AI Document Intelligence to ingest, extract, and classify content from various assets, enabling chat-based insight discovery, analysis, and prompt guidance. It uses OCR and multi-modal LLM to extract information from documents like text, handwritten text, charts, graphs, tables, and form fields. Users can customize the technical architecture and data processing workflow. Key features include ingesting and extracting real-world entities, chat-based insights discovery, text and document data analysis, prompt suggestion guidance, and multi-modal information processing.
oci-data-science-ai-samples
The Oracle Cloud Infrastructure Data Science and AI services Examples repository provides demos, tutorials, and code examples showcasing various features of the OCI Data Science service and AI services. It offers tools for data scientists to develop and deploy machine learning models efficiently, with features like Accelerated Data Science SDK, distributed training, batch processing, and machine learning pipelines. Whether you're a beginner or an experienced practitioner, OCI Data Science Services provide the resources needed to build, train, and deploy models easily.
Build-Modern-AI-Apps
This repository serves as a hub for Microsoft Official Build & Modernize AI Applications reference solutions and content. It provides access to projects demonstrating how to build Generative AI applications using Azure services like Azure OpenAI, Azure Container Apps, Azure Kubernetes, and Azure Cosmos DB. The solutions include Vector Search & AI Assistant, Real-Time Payment and Transaction Processing, and Medical Claims Processing. Additionally, there are workshops like the Intelligent App Workshop for Microsoft Copilot Stack, focusing on infusing intelligence into traditional software systems using foundation models and design thinking.
Multi-Agent-Custom-Automation-Engine-Solution-Accelerator
The Multi-Agent -Custom Automation Engine Solution Accelerator is an AI-driven orchestration system that manages a group of AI agents to accomplish tasks based on user input. It uses a FastAPI backend to handle HTTP requests, processes them through various specialized agents, and stores stateful information using Azure Cosmos DB. The system allows users to focus on what matters by coordinating activities across an organization, enabling GenAI to scale, and is applicable to most industries. It is intended for developing and deploying custom AI solutions for specific customers, providing a foundation to accelerate building out multi-agent systems.

agentUniverse
agentUniverse is a framework for developing applications powered by multi-agent based on large language model. It provides essential components for building single agent and multi-agent collaboration mechanism for customizing collaboration patterns. Developers can easily construct multi-agent applications and share pattern practices from different fields. The framework includes pre-installed collaboration patterns like PEER and DOE for complex task breakdown and data-intensive tasks.
AutoWebGLM
AutoWebGLM is a project focused on developing a language model-driven automated web navigation agent. It extends the capabilities of the ChatGLM3-6B model to navigate the web more efficiently and address real-world browsing challenges. The project includes features such as an HTML simplification algorithm, hybrid human-AI training, reinforcement learning, rejection sampling, and a bilingual web navigation benchmark for testing AI web navigation agents.

ianvs
Ianvs is a distributed synergy AI benchmarking project incubated in KubeEdge SIG AI. It aims to test the performance of distributed synergy AI solutions following recognized standards, providing end-to-end benchmark toolkits, test environment management tools, test case control tools, and benchmark presentation tools. It also collaborates with other organizations to establish comprehensive benchmarks and related applications. The architecture includes critical components like Test Environment Manager, Test Case Controller, Generation Assistant, Simulation Controller, and Story Manager. Ianvs documentation covers quick start, guides, dataset descriptions, algorithms, user interfaces, stories, and roadmap.

CodeFuse-muAgent
CodeFuse-muAgent is a Multi-Agent framework designed to streamline Standard Operating Procedure (SOP) orchestration for agents. It integrates toolkits, code libraries, knowledge bases, and sandbox environments for rapid construction of complex Multi-Agent interactive applications. The framework enables efficient execution and handling of multi-layered and multi-dimensional tasks.

awesome-RLAIF
Reinforcement Learning from AI Feedback (RLAIF) is a concept that describes a type of machine learning approach where **an AI agent learns by receiving feedback or guidance from another AI system**. This concept is closely related to the field of Reinforcement Learning (RL), which is a type of machine learning where an agent learns to make a sequence of decisions in an environment to maximize a cumulative reward. In traditional RL, an agent interacts with an environment and receives feedback in the form of rewards or penalties based on the actions it takes. It learns to improve its decision-making over time to achieve its goals. In the context of Reinforcement Learning from AI Feedback, the AI agent still aims to learn optimal behavior through interactions, but **the feedback comes from another AI system rather than from the environment or human evaluators**. This can be **particularly useful in situations where it may be challenging to define clear reward functions or when it is more efficient to use another AI system to provide guidance**. The feedback from the AI system can take various forms, such as: - **Demonstrations** : The AI system provides demonstrations of desired behavior, and the learning agent tries to imitate these demonstrations. - **Comparison Data** : The AI system ranks or compares different actions taken by the learning agent, helping it to understand which actions are better or worse. - **Reward Shaping** : The AI system provides additional reward signals to guide the learning agent's behavior, supplementing the rewards from the environment. This approach is often used in scenarios where the RL agent needs to learn from **limited human or expert feedback or when the reward signal from the environment is sparse or unclear**. It can also be used to **accelerate the learning process and make RL more sample-efficient**. Reinforcement Learning from AI Feedback is an area of ongoing research and has applications in various domains, including robotics, autonomous vehicles, and game playing, among others.
For similar tasks

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.
djl-demo
The Deep Java Library (DJL) is a framework-agnostic Java API for deep learning. It provides a unified interface to popular deep learning frameworks such as TensorFlow, PyTorch, and MXNet. DJL makes it easy to develop deep learning applications in Java, and it can be used for a variety of tasks, including image classification, object detection, natural language processing, and speech recognition.
kaapana
Kaapana is an open-source toolkit for state-of-the-art platform provisioning in the field of medical data analysis. The applications comprise AI-based workflows and federated learning scenarios with a focus on radiological and radiotherapeutic imaging. Obtaining large amounts of medical data necessary for developing and training modern machine learning methods is an extremely challenging effort that often fails in a multi-center setting, e.g. due to technical, organizational and legal hurdles. A federated approach where the data remains under the authority of the individual institutions and is only processed on-site is, in contrast, a promising approach ideally suited to overcome these difficulties. Following this federated concept, the goal of Kaapana is to provide a framework and a set of tools for sharing data processing algorithms, for standardized workflow design and execution as well as for performing distributed method development. This will facilitate data analysis in a compliant way enabling researchers and clinicians to perform large-scale multi-center studies. By adhering to established standards and by adopting widely used open technologies for private cloud development and containerized data processing, Kaapana integrates seamlessly with the existing clinical IT infrastructure, such as the Picture Archiving and Communication System (PACS), and ensures modularity and easy extensibility.

MONAI
MONAI is a PyTorch-based, open-source framework for deep learning in healthcare imaging. It provides a comprehensive set of tools for medical image analysis, including data preprocessing, model training, and evaluation. MONAI is designed to be flexible and easy to use, making it a valuable resource for researchers and developers in the field of medical imaging.
nnstreamer
NNStreamer is a set of Gstreamer plugins that allow Gstreamer developers to adopt neural network models easily and efficiently and neural network developers to manage neural network pipelines and their filters easily and efficiently.
cortex
Nitro is a high-efficiency C++ inference engine for edge computing, powering Jan. It is lightweight and embeddable, ideal for product integration. The binary of nitro after zipped is only ~3mb in size with none to minimal dependencies (if you use a GPU need CUDA for example) make it desirable for any edge/server deployment.
PyTorch-Tutorial-2nd
The second edition of "PyTorch Practical Tutorial" was completed after 5 years, 4 years, and 2 years. On the basis of the essence of the first edition, rich and detailed deep learning application cases and reasoning deployment frameworks have been added, so that this book can more systematically cover the knowledge involved in deep learning engineers. As the development of artificial intelligence technology continues to emerge, the second edition of "PyTorch Practical Tutorial" is not the end, but the beginning, opening up new technologies, new fields, and new chapters. I hope to continue learning and making progress in artificial intelligence technology with you in the future.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.
VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.