
LLMs-in-science
None
Stars: 103
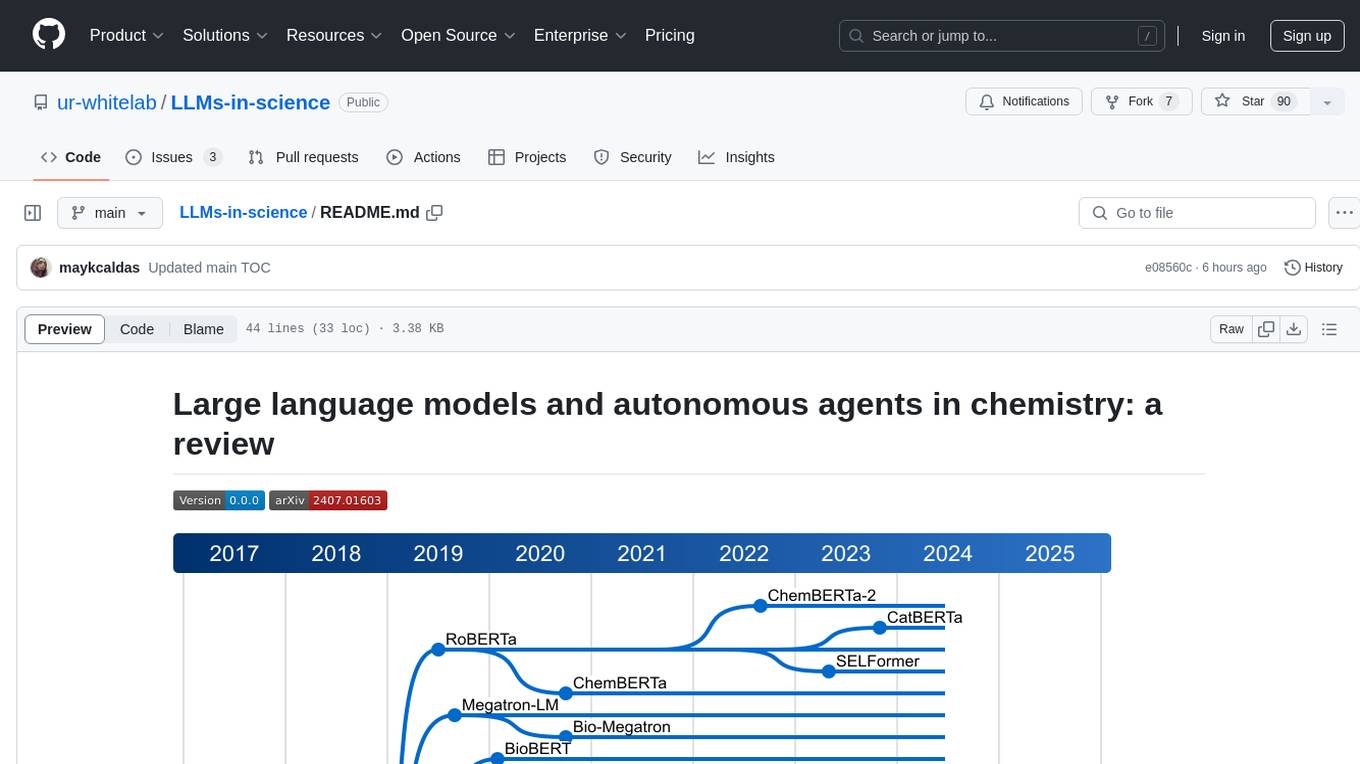
The 'LLMs-in-science' repository is a collaborative environment for organizing papers related to large language models (LLMs) and autonomous agents in the field of chemistry. The goal is to discuss trend topics, challenges, and the potential for supporting scientific discovery in the context of artificial intelligence. The repository aims to maintain a systematic structure of the field and welcomes contributions from the community to keep the content up-to-date and relevant.
README:

Our review paper has, by no means, the goal of discussing the entire LLM/autonomous agents literature. Instead, we propose a general discussion of these studies' trend topics, challenges, and potential for supporting scientific discovery.
Because artificial intelligence is a hot topic at the moment, and the daily number of new papers is just astonishing, any published review is fated to be outdated after a few months. Therefore, we must maintain a systematic structure of the field with collaboration. With this in mind, we aim to create this repository as a broad, open-source, collaborative environment for organizing the large number of papers published daily.
Please check our CONTRIBUTING.md file to know how to contribute.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLMs-in-science
Similar Open Source Tools
LLMs-in-science
The 'LLMs-in-science' repository is a collaborative environment for organizing papers related to large language models (LLMs) and autonomous agents in the field of chemistry. The goal is to discuss trend topics, challenges, and the potential for supporting scientific discovery in the context of artificial intelligence. The repository aims to maintain a systematic structure of the field and welcomes contributions from the community to keep the content up-to-date and relevant.

data-to-paper
Data-to-paper is an AI-driven framework designed to guide users through the process of conducting end-to-end scientific research, starting from raw data to the creation of comprehensive and human-verifiable research papers. The framework leverages a combination of LLM and rule-based agents to assist in tasks such as hypothesis generation, literature search, data analysis, result interpretation, and paper writing. It aims to accelerate research while maintaining key scientific values like transparency, traceability, and verifiability. The framework is field-agnostic, supports both open-goal and fixed-goal research, creates data-chained manuscripts, involves human-in-the-loop interaction, and allows for transparent replay of the research process.
matchem-llm
A public repository collecting links to state-of-the-art training sets, QA, benchmarks and other evaluations for various ML and LLM applications in materials science and chemistry. It includes datasets related to chemistry, materials, multimodal data, and knowledge graphs in the field. The repository aims to provide resources for training and evaluating machine learning models in the materials science and chemistry domains.
MathPile
MathPile is a generative AI tool designed for math, offering a diverse and high-quality math-centric corpus comprising about 9.5 billion tokens. It draws from various sources such as textbooks, arXiv, Wikipedia, ProofWiki, StackExchange, and web pages, catering to different educational levels and math competitions. The corpus is meticulously processed to ensure data quality, with extensive documentation and data contamination detection. MathPile aims to enhance mathematical reasoning abilities of language models.

Awesome-LLM-in-Social-Science
This repository compiles a list of academic papers that evaluate, align, simulate, and provide surveys or perspectives on the use of Large Language Models (LLMs) in the field of Social Science. The papers cover various aspects of LLM research, including assessing their alignment with human values, evaluating their capabilities in tasks such as opinion formation and moral reasoning, and exploring their potential for simulating social interactions and addressing issues in diverse fields of Social Science. The repository aims to provide a comprehensive resource for researchers and practitioners interested in the intersection of LLMs and Social Science.

kaapana
Kaapana is an open-source toolkit for state-of-the-art platform provisioning in the field of medical data analysis. The applications comprise AI-based workflows and federated learning scenarios with a focus on radiological and radiotherapeutic imaging. Obtaining large amounts of medical data necessary for developing and training modern machine learning methods is an extremely challenging effort that often fails in a multi-center setting, e.g. due to technical, organizational and legal hurdles. A federated approach where the data remains under the authority of the individual institutions and is only processed on-site is, in contrast, a promising approach ideally suited to overcome these difficulties. Following this federated concept, the goal of Kaapana is to provide a framework and a set of tools for sharing data processing algorithms, for standardized workflow design and execution as well as for performing distributed method development. This will facilitate data analysis in a compliant way enabling researchers and clinicians to perform large-scale multi-center studies. By adhering to established standards and by adopting widely used open technologies for private cloud development and containerized data processing, Kaapana integrates seamlessly with the existing clinical IT infrastructure, such as the Picture Archiving and Communication System (PACS), and ensures modularity and easy extensibility.
mlforpublicpolicylab
The Machine Learning for Public Policy Lab is a project-based course focused on solving real-world problems using machine learning in the context of public policy and social good. Students will gain hands-on experience building end-to-end machine learning systems, developing skills in problem formulation, working with messy data, communicating with non-technical stakeholders, model interpretability, and understanding algorithmic bias & disparities. The course covers topics such as project scoping, data acquisition, feature engineering, model evaluation, bias and fairness, and model interpretability. Students will work in small groups on policy projects, with graded components including project proposals, presentations, and final reports.

Me-LLaMA
Me LLaMA introduces a suite of open-source medical Large Language Models (LLMs), including Me LLaMA 13B/70B and their chat-enhanced versions. Developed through innovative continual pre-training and instruction tuning, these models leverage a vast medical corpus comprising PubMed papers, medical guidelines, and general domain data. Me LLaMA sets new benchmarks on medical reasoning tasks, making it a significant asset for medical NLP applications and research. The models are intended for computational linguistics and medical research, not for clinical decision-making without validation and regulatory approval.

awesome-RLAIF
Reinforcement Learning from AI Feedback (RLAIF) is a concept that describes a type of machine learning approach where **an AI agent learns by receiving feedback or guidance from another AI system**. This concept is closely related to the field of Reinforcement Learning (RL), which is a type of machine learning where an agent learns to make a sequence of decisions in an environment to maximize a cumulative reward. In traditional RL, an agent interacts with an environment and receives feedback in the form of rewards or penalties based on the actions it takes. It learns to improve its decision-making over time to achieve its goals. In the context of Reinforcement Learning from AI Feedback, the AI agent still aims to learn optimal behavior through interactions, but **the feedback comes from another AI system rather than from the environment or human evaluators**. This can be **particularly useful in situations where it may be challenging to define clear reward functions or when it is more efficient to use another AI system to provide guidance**. The feedback from the AI system can take various forms, such as: - **Demonstrations** : The AI system provides demonstrations of desired behavior, and the learning agent tries to imitate these demonstrations. - **Comparison Data** : The AI system ranks or compares different actions taken by the learning agent, helping it to understand which actions are better or worse. - **Reward Shaping** : The AI system provides additional reward signals to guide the learning agent's behavior, supplementing the rewards from the environment. This approach is often used in scenarios where the RL agent needs to learn from **limited human or expert feedback or when the reward signal from the environment is sparse or unclear**. It can also be used to **accelerate the learning process and make RL more sample-efficient**. Reinforcement Learning from AI Feedback is an area of ongoing research and has applications in various domains, including robotics, autonomous vehicles, and game playing, among others.
oreilly-llm-rl-alignment
This repository contains Jupyter notebooks for the courses 'Aligning Large Language Models' and 'Reinforcement Learning with Large Language Models' by Sinan Ozdemir. It covers effective best practices and industry case studies in using Large Language Models (LLMs). The courses provide in-depth exploration of alignment techniques, evaluation methods, ethical considerations, and reinforcement learning concepts with practical applications. Participants will gain theoretical insights and hands-on experience in working with LLMs, including fine-tuning models and understanding advanced concepts like RLHF, RLAIF, and Constitutional AI.

Taiyi-LLM
Taiyi (太一) is a bilingual large language model fine-tuned for diverse biomedical tasks. It aims to facilitate communication between healthcare professionals and patients, provide medical information, and assist in diagnosis, biomedical knowledge discovery, drug development, and personalized healthcare solutions. The model is based on the Qwen-7B-base model and has been fine-tuned using rich bilingual instruction data. It covers tasks such as question answering, biomedical dialogue, medical report generation, biomedical information extraction, machine translation, title generation, text classification, and text semantic similarity. The project also provides standardized data formats, model training details, model inference guidelines, and overall performance metrics across various BioNLP tasks.
agentUniverse
agentUniverse is a multi-agent framework based on large language models, providing flexible capabilities for building individual agents. It focuses on multi-agent collaborative patterns, integrating domain experience to help agents solve problems in various fields. The framework includes pattern components like PEER and DOE for event interpretation, industry analysis, and financial report generation. It offers features for agent construction, multi-agent collaboration, and domain expertise integration, aiming to create intelligent applications with professional know-how.

agentUniverse
agentUniverse is a framework for developing applications powered by multi-agent based on large language model. It provides essential components for building single agent and multi-agent collaboration mechanism for customizing collaboration patterns. Developers can easily construct multi-agent applications and share pattern practices from different fields. The framework includes pre-installed collaboration patterns like PEER and DOE for complex task breakdown and data-intensive tasks.

hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.

aitlas
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as a repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which allows benchmarking of various existing and novel AI methods tailored for EO data.
For similar tasks

Awesome-LLM-RAG
This repository, Awesome-LLM-RAG, aims to record advanced papers on Retrieval Augmented Generation (RAG) in Large Language Models (LLMs). It serves as a resource hub for researchers interested in promoting their work related to LLM RAG by updating paper information through pull requests. The repository covers various topics such as workshops, tutorials, papers, surveys, benchmarks, retrieval-enhanced LLMs, RAG instruction tuning, RAG in-context learning, RAG embeddings, RAG simulators, RAG search, RAG long-text and memory, RAG evaluation, RAG optimization, and RAG applications.

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.

LLM-Tool-Survey
This repository contains a collection of papers related to tool learning with large language models (LLMs). The papers are organized according to the survey paper 'Tool Learning with Large Language Models: A Survey'. The survey focuses on the benefits and implementation of tool learning with LLMs, covering aspects such as task planning, tool selection, tool calling, response generation, benchmarks, evaluation, challenges, and future directions in the field. It aims to provide a comprehensive understanding of tool learning with LLMs and inspire further exploration in this emerging area.
Awesome-CVPR2024-ECCV2024-AIGC
A Collection of Papers and Codes for CVPR 2024 AIGC. This repository compiles and organizes research papers and code related to CVPR 2024 and ECCV 2024 AIGC (Artificial Intelligence and Graphics Computing). It serves as a valuable resource for individuals interested in the latest advancements in the field of computer vision and artificial intelligence. Users can find a curated list of papers and accompanying code repositories for further exploration and research. The repository encourages collaboration and contributions from the community through stars, forks, and pull requests.
LLMs-in-science
The 'LLMs-in-science' repository is a collaborative environment for organizing papers related to large language models (LLMs) and autonomous agents in the field of chemistry. The goal is to discuss trend topics, challenges, and the potential for supporting scientific discovery in the context of artificial intelligence. The repository aims to maintain a systematic structure of the field and welcomes contributions from the community to keep the content up-to-date and relevant.
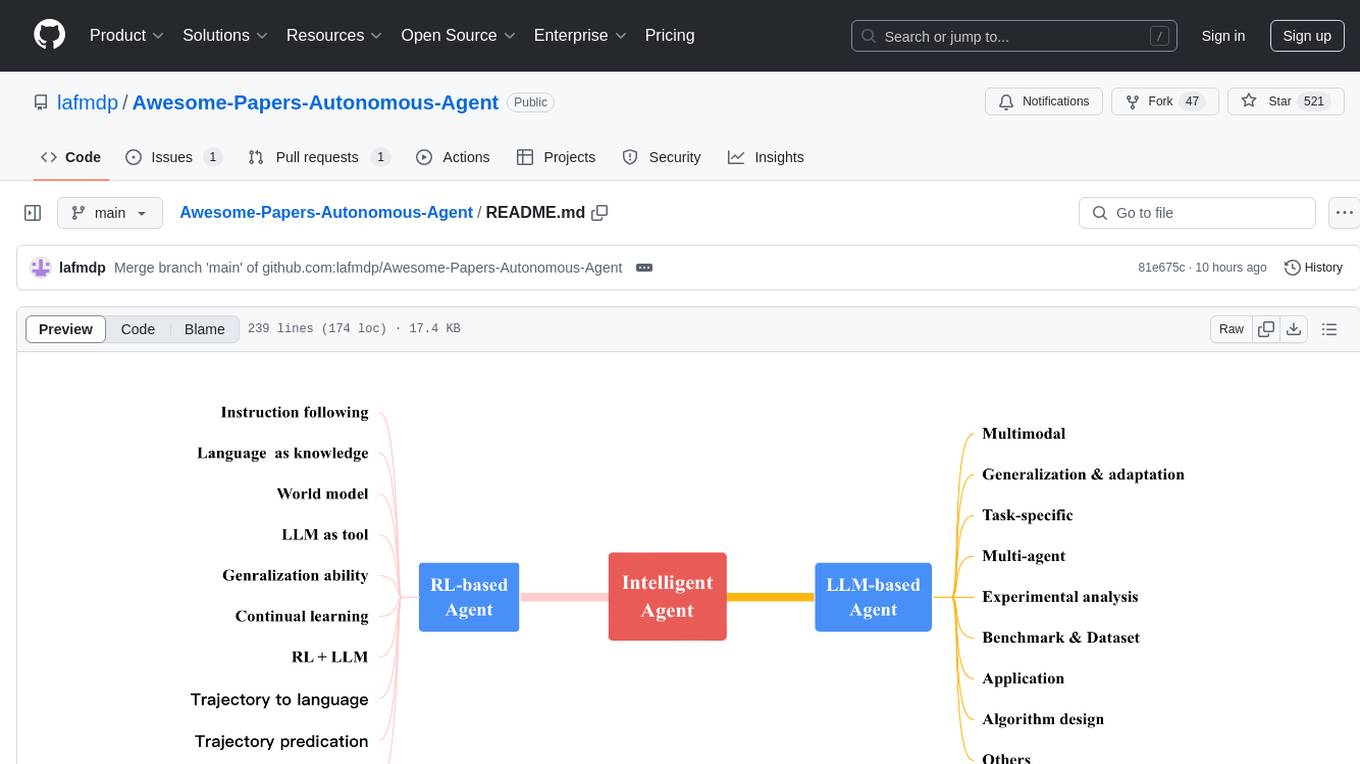
Awesome-Papers-Autonomous-Agent
Awesome-Papers-Autonomous-Agent is a curated collection of recent papers focusing on autonomous agents, specifically interested in RL-based agents and LLM-based agents. The repository aims to provide a comprehensive resource for researchers and practitioners interested in intelligent agents that can achieve goals, acquire knowledge, and continually improve. The collection includes papers on various topics such as instruction following, building agents based on world models, using language as knowledge, leveraging LLMs as a tool, generalization across tasks, continual learning, combining RL and LLM, transformer-based policies, trajectory to language, trajectory prediction, multimodal agents, training LLMs for generalization and adaptation, task-specific designing, multi-agent systems, experimental analysis, benchmarking, applications, algorithm design, and combining with RL.
awesome-lifelong-llm-agent
This repository is a collection of papers and resources related to Lifelong Learning of Large Language Model (LLM) based Agents. It focuses on continual learning and incremental learning of LLM agents, identifying key modules such as Perception, Memory, and Action. The repository serves as a roadmap for understanding lifelong learning in LLM agents and provides a comprehensive overview of related research and surveys.

LLM-Agent-Survey
LLM-Agent-Survey is a comprehensive repository that provides a curated list of papers related to Large Language Model (LLM) agents. The repository categorizes papers based on LLM-Profiled Roles and includes high-quality publications from prestigious conferences and journals. It aims to offer a systematic understanding of LLM-based agents, covering topics such as tool use, planning, and feedback learning. The repository also includes unpublished papers with insightful analysis and novelty, marked for future updates. Users can explore a wide range of surveys, tool use cases, planning workflows, and benchmarks related to LLM agents.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.