
ParrotServe
[OSDI'24] Serving LLM-based Applications Efficiently with Semantic Variable
Stars: 89
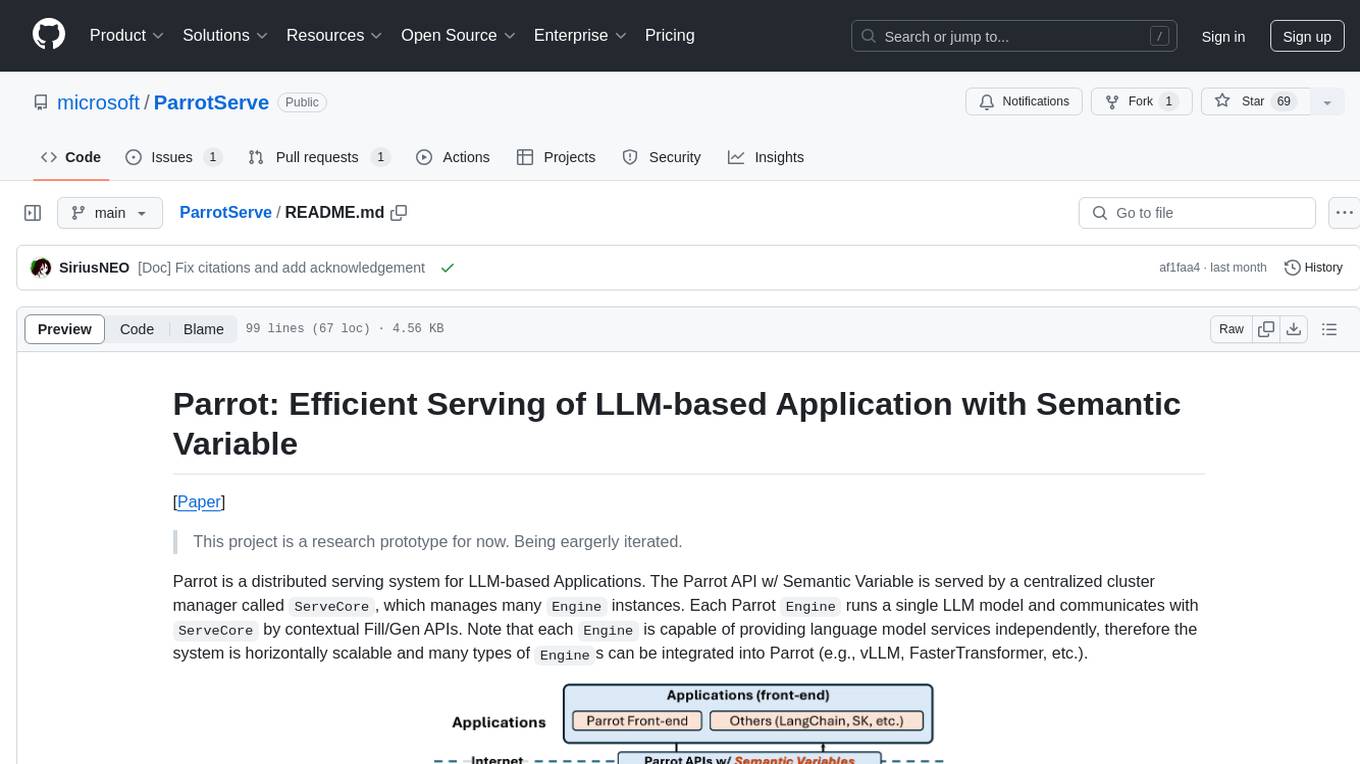
Parrot is a distributed serving system for LLM-based Applications, designed to efficiently serve LLM-based applications by adding Semantic Variable in the OpenAI-style API. It allows for horizontal scalability with multiple Engine instances running LLM models communicating with ServeCore. The system enables AI agents to interact with LLMs via natural language prompts for collaborative tasks.
README:
Paper | Documentation | Slides | Poster
This repo is current a research prototype and is not actively maintained. Please open issue or contact the authors when you need help.
Parrot is a distributed, multi-tenant serving system for LLM-based Applications. With the Semantic Variable abstraction, Parrot can easily grasp the app-level information like LLM computation graph (DAG) or the prompt structure, which enables many interesting features like:
- Automatically parallelize and batch LLM requests in complex LLM applications. Asynchronous communication between dependent requests.
- Performance objective deduction and DAG-aware scheduling.
- Sharing common prompt prefix between requests with optimized attention kernel, Context-aware scheduling.
The powerful language understanding capability of large language models (LLMs) has enabled a new application paradigm, where one or multiple application entities, known as AI agents or co-pilots, communicate with LLMs via natural language, known as “prompts”, to accomplish a task collaboratively.
Parrot is designed to serve these LLM-based applications efficiently by adding Semantic Variable in current OpenAI-style API, exposing richer application-level knowledge to backend systems and engines for better optimization.

For more background knowledge and our motivation, please refer our OSDI'24 paper Parrot: Efficient Serving of LLM-based Applications with Semantic Variable.
- [2024/08] A Post about Parrot is published in the WeChat account of MSRA (Microsoft Research Asia)!
- [2024/07] Parrot is published and presented in OSDI'24. Please find the paper and presentation Here if you are interested!
- [2024/06] Blogs about the technical details behind Parrot: Blog (Chinese) or Blog Zhihu (Chinese).
- [2024/04] Release Parrot as a Microsoft open source project.
- [2024/03] Parrot has been accepted to OSDI'24!
See INSTALL for installation instructions.
- Get Started: In this chapter, you will learn how to install Parrot and run your first application using Parrot.
-
Documentation for Users: User documentation of Parrot. It contains the API specification of Parrot's OpenAI-like API, and the grammar of Parrot's frontend
pfunc. - Parrot System Design: If you want to hack/modify Parrot, it's what you need. This chapter offers an overview of Parrot's system architecture and provides detailed explanation of Parrot's internal code organization and implementation.
- Version Drafts: Learn about the refactor history and some of our brainstorm ideas when developing Parrot from these drafts.
We learned a lot from the following projects when developing Parrot.
If you find Parrot useful or relevant to your research, please cite our paper as below:
@inproceedings{lin2024parrot,
author = {Chaofan Lin and Zhenhua Han and Chengruidong Zhang and Yuqing Yang and Fan Yang and Chen Chen and Lili Qiu},
title = {Parrot: Efficient Serving of LLM-based Applications with Semantic Variable},
booktitle = {18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24)},
year = {2024},
address = {Santa Clara, CA},
publisher = {USENIX Association},
url = {https://www.usenix.org/conference/osdi24/presentation/lin-chaofan},
month = jul
}
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ParrotServe
Similar Open Source Tools
ParrotServe
Parrot is a distributed serving system for LLM-based Applications, designed to efficiently serve LLM-based applications by adding Semantic Variable in the OpenAI-style API. It allows for horizontal scalability with multiple Engine instances running LLM models communicating with ServeCore. The system enables AI agents to interact with LLMs via natural language prompts for collaborative tasks.

graphrag
The GraphRAG project is a data pipeline and transformation suite designed to extract meaningful, structured data from unstructured text using LLMs. It enhances LLMs' ability to reason about private data. The repository provides guidance on using knowledge graph memory structures to enhance LLM outputs, with a warning about the potential costs of GraphRAG indexing. It offers contribution guidelines, development resources, and encourages prompt tuning for optimal results. The Responsible AI FAQ addresses GraphRAG's capabilities, intended uses, evaluation metrics, limitations, and operational factors for effective and responsible use.

morphik-core
Morphik is an AI-native toolset designed to help developers integrate context into their AI applications by providing tools to store, represent, and search unstructured data. It offers features such as multimodal search, fast metadata extraction, and integrations with existing tools. Morphik aims to address the challenges of traditional AI approaches that struggle with visually rich documents and provide a more comprehensive solution for understanding and processing complex data.

Robyn
Robyn is an experimental, semi-automated and open-sourced Marketing Mix Modeling (MMM) package from Meta Marketing Science. It uses various machine learning techniques to define media channel efficiency and effectivity, explore adstock rates and saturation curves. Built for granular datasets with many independent variables, especially suitable for digital and direct response advertisers with rich data sources. Aiming to democratize MMM, make it accessible for advertisers of all sizes, and contribute to the measurement landscape.

serena
Serena is a powerful coding agent that integrates with existing LLMs to provide essential semantic code retrieval and editing tools. It is free to use and does not require API keys or subscriptions. Serena can be used for coding tasks such as analyzing, planning, and editing code directly on your codebase. It supports various programming languages and offers semantic code analysis capabilities through language servers. Serena can be integrated with different LLMs using the model context protocol (MCP) or Agno framework. The tool provides a range of functionalities for code retrieval, editing, and execution, making it a versatile coding assistant for developers.

aiid
The Artificial Intelligence Incident Database (AIID) is a collection of incidents involving the development and use of artificial intelligence (AI). The database is designed to help researchers, policymakers, and the public understand the potential risks and benefits of AI, and to inform the development of policies and practices to mitigate the risks and promote the benefits of AI. The AIID is a collaborative project involving researchers from the University of California, Berkeley, the University of Washington, and the University of Toronto.
dstoolkit-text2sql-and-imageprocessing
This repository provides sample code for improving RAG applications with rich data sources including SQL Warehouses and documents analysed with Azure Document Intelligence. It includes components for Text2SQL generation and querying, linking Azure Document Intelligence with AI Search for processing complex documents, and deploying AI search indexes. The plugins and skills aim to enhance response quality in RAG applications by accessing and pulling data from SQL tables, drawing insights from complex charts and images, and intelligently grouping similar sentences.

onnx
Open Neural Network Exchange (ONNX) is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. ONNX provides an open source format for AI models, both deep learning and traditional ML. It defines an extensible computation graph model, as well as definitions of built-in operators and standard data types. Currently, we focus on the capabilities needed for inferencing (scoring). ONNX is widely supported and can be found in many frameworks, tools, and hardware, enabling interoperability between different frameworks and streamlining the path from research to production to increase the speed of innovation in the AI community. Join us to further evolve ONNX.

llmops-duke-aipi
LLMOps Duke AIPI is a course focused on operationalizing Large Language Models, teaching methodologies for developing applications using software development best practices with large language models. The course covers various topics such as generative AI concepts, setting up development environments, interacting with large language models, using local large language models, applied solutions with LLMs, extensibility using plugins and functions, retrieval augmented generation, introduction to Python web frameworks for APIs, DevOps principles, deploying machine learning APIs, LLM platforms, and final presentations. Students will learn to build, share, and present portfolios using Github, YouTube, and Linkedin, as well as develop non-linear life-long learning skills. Prerequisites include basic Linux and programming skills, with coursework available in Python or Rust. Additional resources and references are provided for further learning and exploration.
intro-to-intelligent-apps
This repository introduces and helps organizations get started with building AI Apps and incorporating Large Language Models (LLMs) into them. The workshop covers topics such as prompt engineering, AI orchestration, and deploying AI apps. Participants will learn how to use Azure OpenAI, Langchain/ Semantic Kernel, Qdrant, and Azure AI Search to build intelligent applications.
aitour26-WRK541-real-world-code-migration-with-github-copilot-agent-mode
Microsoft AI Tour 2026 WRK541 is a workshop focused on real-world code migration using GitHub Copilot Agent Mode. The session is designed for technologists interested in applying AI pair-programming techniques to challenging tasks like migrating or translating code between different programming languages. Participants will learn advanced GitHub Copilot techniques, differences between Python and C#, JSON serialization and deserialization in C#, developing and validating endpoints, integrating Swagger/OpenAPI documentation, and writing unit tests with MSTest. The workshop aims to help users gain hands-on experience in using GitHub Copilot for real-world code migration scenarios.
ask-astro
Ask Astro is an open-source reference implementation of Andreessen Horowitz's LLM Application Architecture built by Astronomer. It provides an end-to-end example of a Q&A LLM application used to answer questions about Apache Airflow® and Astronomer. Ask Astro includes Airflow DAGs for data ingestion, an API for business logic, a Slack bot, a public UI, and DAGs for processing user feedback. The tool is divided into data retrieval & embedding, prompt orchestration, and feedback loops.
PythonDataScienceFullThrottle
PythonDataScienceFullThrottle is a comprehensive repository containing various Python scripts, libraries, and tools for data science enthusiasts. It includes a wide range of functionalities such as data preprocessing, visualization, machine learning algorithms, and statistical analysis. The repository aims to provide a one-stop solution for individuals looking to dive deep into the world of data science using Python.

ChainForge
ChainForge is a visual programming environment for battle-testing prompts to LLMs. It is geared towards early-stage, quick-and-dirty exploration of prompts, chat responses, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can: * Query multiple LLMs at once to test prompt ideas and variations quickly and effectively. * Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case. * Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings. * Hold multiple conversations at once across template parameters and chat models. Template not just prompts, but follow-up chat messages, and inspect and evaluate outputs at each turn of a chat conversation. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals. This is an open beta of Chainforge. We support model providers OpenAI, HuggingFace, Anthropic, Google PaLM2, Azure OpenAI endpoints, and Dalai-hosted models Alpaca and Llama. You can change the exact model and individual model settings. Visualization nodes support numeric and boolean evaluation metrics. ChainForge is built on ReactFlow and Flask.
langchain4j
LangChain for Java simplifies integrating Large Language Models (LLMs) into Java applications by offering unified APIs for various LLM providers and embedding stores. It provides a comprehensive toolbox with tools for prompt templating, chat memory management, function calling, and high-level patterns like Agents and RAG. The library supports 15+ popular LLM providers and 15+ embedding stores, offering numerous examples to help users quickly start building LLM-powered applications. LangChain4j is a fusion of ideas from various projects and actively incorporates new techniques and integrations to keep users up-to-date. The project is under active development, with core functionality already in place for users to start building LLM-powered apps.
HybridAGI
HybridAGI is the first Programmable LLM-based Autonomous Agent that lets you program its behavior using a **graph-based prompt programming** approach. This state-of-the-art feature allows the AGI to efficiently use any tool while controlling the long-term behavior of the agent. Become the _first Prompt Programmers in history_ ; be a part of the AI revolution one node at a time! **Disclaimer: We are currently in the process of upgrading the codebase to integrate DSPy**
For similar tasks
ParrotServe
Parrot is a distributed serving system for LLM-based Applications, designed to efficiently serve LLM-based applications by adding Semantic Variable in the OpenAI-style API. It allows for horizontal scalability with multiple Engine instances running LLM models communicating with ServeCore. The system enables AI agents to interact with LLMs via natural language prompts for collaborative tasks.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.