
Awesome-LLM-RAG
Awesome-LLM-RAG: a curated list of advanced retrieval augmented generation (RAG) in Large Language Models
Stars: 733

This repository, Awesome-LLM-RAG, aims to record advanced papers on Retrieval Augmented Generation (RAG) in Large Language Models (LLMs). It serves as a resource hub for researchers interested in promoting their work related to LLM RAG by updating paper information through pull requests. The repository covers various topics such as workshops, tutorials, papers, surveys, benchmarks, retrieval-enhanced LLMs, RAG instruction tuning, RAG in-context learning, RAG embeddings, RAG simulators, RAG search, RAG long-text and memory, RAG evaluation, RAG optimization, and RAG applications.
README:
This repo aims to record advanced papers of Retrieval Agumented Generation (RAG) in LLMs.
We strongly encourage the researchers that want to promote their fantastic work to the LLM RAG to make pull request to update their paper's information!
Personalized Generative AI
Zheng Chen, Ziyan Jiang, Fan Yang, Zhankui He, Yupeng Hou, Eunah Cho, Julian McAuley, Aram Galstyan, Xiaohua Hu, Jie Yang
CIKM 23 – Oct 2023 [link]
First Workshop on Recommendation with Generative Models
Wenjie Wang, Yong Liu, Yang Zhang, Weiwen Liu, Fuli Feng, Xiangnan He, Aixin Sun
CIKM 23 – Oct 2023 [link]
First Workshop on Generative Information Retrieval
Gabriel Bénédict, Ruqing Zhang, Donald Metzler
SIGIR 23 – Jul 2023 [link]
Retrieval-based Language Models and Applications
Akari Asai, Sewon Min, Zexuan Zhong, Danqi Chen
ACL 23 – Jul 2023 [link]
Become a Generative AI Developer Richie Cotton, Olivier Mertens, Korey Stegared-Pace, James Briggs, Vincent Vankrunkelsven, Alara Dirik, Jacob Marquez, Priyanka Asnani DataCamp [link]
Benchmarking Large Language Models in Retrieval-Augmented Generation
Jiawei Chen, Hongyu Lin, Xianpei Han, Le Sun
arXiv 2023. [Paper][Github]
4 Sep 2023
Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models
Wenhao Yu, Hongming Zhang, Xiaoman Pan, Kaixin Ma, Hongwei Wang, Dong Yu
arxiv - Nov 2023 [Paper]
REST: Retrieval-Based Speculative Decoding
Zhenyu He, Zexuan Zhong, Tianle Cai, Jason D Lee, Di He
arXiv - Nov 2023 [Paper][Github]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Anonymous
ICLR 24 – Oct 2023 [paper]
Self-Knowledge Guided Retrieval Augmentation for Large Language Models
Yile Wang, Peng Li, Maosong Sun, Yang Liu
arXiv - Oct 2023 [Ppaer]
Retrieval meets Long Context Large Language Models
Peng Xu, Wei Ping, Xianchao Wu, Lawrence McAfee, Chen Zhu, Zihan Liu, Sandeep Subramanian, Evelina Bakhturina, Mohammad Shoeybi, Bryan Catanzaro
arxiv - Oct 2023 [Paper]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, Christopher Potts
arXiv – Oct 2023 [paper] [code]
Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts
Jian Xie, Kai Zhang, Jiangjie Chen, Renze Lou, Yu Su
ICLR 24 – May 2023 [paper] [code]
Active Retrieval Augmented Generation
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, Graham Neubig
arXiv – May 2023 [paper] [code]
REPLUG: Retrieval-Augmented Black-Box Language Models
Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Zettlemoyer, Wen-tau Yih
arXiv – Jan 2023 [paper]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela NeurIPS 2020 - May 2020 [Paper]
RA-DIT: Retrieval-Augmented Dual Instruction Tuning
Anonymous
ICLR 24 – Oct 23 [paper]
InstructRetro: Instruction Tuning post Retrieval-Augmented Pretraining
Boxin Wang, Wei Ping, Lawrence McAfee, Peng Xu, Bo Li, Mohammad Shoeybi, Bryan Catanzaro
arXiv - Oct 23 [paper]
In-Context Retrieval-Augmented Language Models
Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, Yoav Shoham
AI21 Labs – Jan 2023 [paper] [code]
RegaVAE: A Retrieval-Augmented Gaussian Mixture Variational Auto-Encoder for Language Modeling
Jingcheng Deng, Liang Pang, Huawei Shen, Xueqi Cheng
EMNLP 2023 - Oct 2023 [Paper][Github]
Text Embeddings Reveal (Almost) As Much As Text
John X. Morris, Volodymyr Kuleshov, Vitaly Shmatikov, Alexander M. Rush
EMNLP 2023 - Oct 2023 [Paper][Github]
Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents
Michael Günther, Jackmin Ong, Isabelle Mohr, Alaeddine Abdessalem, Tanguy Abel, Mohammad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, Maximilian Werk, Nan Wang, Han Xiao
arXiv - Oct 2023. [Paper][Model]
KAUCUS: Knowledge Augmented User Simulators for Training Language Model Assistants
Kaustubh D. Dhole
Simulation of Conversational Intelligence in Chat, EACL 2024 [Paper]
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, Yu Su
arXiv - May 2024 [paper] [GitHub]
Understanding Retrieval Augmentation for Long-Form Question Answering
Hung-Ting Chen, Fangyuan Xu, Shane A. Arora, Eunsol Choi
arXiv - Oct 2023 [Paper]
ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems
Jon Saad-Falcon, Omar Khattab, Christopher Potts, Matei Zaharia
arXiv - Nov 2023. [Paper] [Github]
Learning to Filter Context for Retrieval-Augmented Generation
Zhiruo Wang, Jun Araki, Zhengbao Jiang, Md Rizwan Parvez, Graham Neubig
arxiv- Nov 2023 [Paper][Github]
Large Language Models Can Be Easily Distracted by Irrelevant Context
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed Chi, Nathanael Schärli, Denny Zhou
ICML 2023 - Jan 2023 [Paper][Github]
Evidentiality-guided Generation for Knowledge-Intensive NLP Tasks
Akari Asai, Matt Gardner, Hannaneh Hajishirzi
NAACL 2022 - Dec 2021 [Paper][Github]
When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, Hannaneh Hajishirzi
ACL 2023 - Dec 2022 [Paper][Github]
Deficiency of Large Language Models in Finance: An Empirical Examination of Hallucination
Haoqiang Kang, Xiao-Yang Liu
arXiv - Nov 2023 [Paper]
Clinfo.ai: An Open-Source Retrieval-Augmented Large Language Model System for Answering Medical Questions using Scientific Literature
Alejandro Lozano, Scott L Fleming, Chia-Chun Chiang, Nigam Shah
arXiv - Oct 2023. [Paper]
PEARL: Personalizing Large Language Model Writing Assistants with Generation-Calibrated Retrievers
Sheshera Mysore, Zhuoran Lu, Mengting Wan, Longqi Yang, Steve Menezes, Tina Baghaee, Emmanuel Barajas Gonzalez, Jennifer Neville, Tara Safavi
arXiv - Nov 2023. [Paper]
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-LLM-RAG
Similar Open Source Tools
Awesome-LLM-RAG
This repository, Awesome-LLM-RAG, aims to record advanced papers on Retrieval Augmented Generation (RAG) in Large Language Models (LLMs). It serves as a resource hub for researchers interested in promoting their work related to LLM RAG by updating paper information through pull requests. The repository covers various topics such as workshops, tutorials, papers, surveys, benchmarks, retrieval-enhanced LLMs, RAG instruction tuning, RAG in-context learning, RAG embeddings, RAG simulators, RAG search, RAG long-text and memory, RAG evaluation, RAG optimization, and RAG applications.

awesome-generative-information-retrieval
This repository contains a curated list of resources on generative information retrieval, including research papers, datasets, tools, and applications. Generative information retrieval is a subfield of information retrieval that uses generative models to generate new documents or passages of text that are relevant to a given query. This can be useful for a variety of tasks, such as question answering, summarization, and document generation. The resources in this repository are intended to help researchers and practitioners stay up-to-date on the latest advances in generative information retrieval.
awesome-open-ended
A curated list of open-ended learning AI resources focusing on algorithms that invent new and complex tasks endlessly, inspired by human advancements. The repository includes papers, safety considerations, surveys, perspectives, and blog posts related to open-ended AI research.
LLM4DB
LLM4DB is a repository focused on the intersection of Large Language Models (LLMs) and Database technologies. It covers various aspects such as data processing, data analysis, database optimization, and data management for LLMs. The repository includes research papers, tools, and techniques related to leveraging LLMs for tasks like data cleaning, entity matching, schema matching, data discovery, NL2SQL, data exploration, data visualization, knob tuning, query optimization, and database diagnosis.

LLM4DB
LLM4DB is a repository focused on the intersection of Large Language Models (LLM) and Database technologies. It covers various aspects such as data processing, data analysis, database optimization, and data management for LLM. The repository includes works on data cleaning, entity matching, schema matching, data discovery, NL2SQL, data exploration, data visualization, configuration tuning, query optimization, and anomaly diagnosis using LLMs. It aims to provide insights and advancements in leveraging LLMs for improving data processing, analysis, and database management tasks.

llm-self-correction-papers
This repository contains a curated list of papers focusing on the self-correction of large language models (LLMs) during inference. It covers various frameworks for self-correction, including intrinsic self-correction, self-correction with external tools, self-correction with information retrieval, and self-correction with training designed specifically for self-correction. The list includes survey papers, negative results, and frameworks utilizing reinforcement learning and OpenAI o1-like approaches. Contributions are welcome through pull requests following a specific format.
Prompt4ReasoningPapers
Prompt4ReasoningPapers is a repository dedicated to reasoning with language model prompting. It provides a comprehensive survey of cutting-edge research on reasoning abilities with language models. The repository includes papers, methods, analysis, resources, and tools related to reasoning tasks. It aims to support various real-world applications such as medical diagnosis, negotiation, etc.
Awesome-LLM-Reasoning-Openai-o1-Survey
The repository 'Awesome LLM Reasoning Openai-o1 Survey' provides a collection of survey papers and related works on OpenAI o1, focusing on topics such as LLM reasoning, self-play reinforcement learning, complex logic reasoning, and scaling law. It includes papers from various institutions and researchers, showcasing advancements in reasoning bootstrapping, reasoning scaling law, self-play learning, step-wise and process-based optimization, and applications beyond math. The repository serves as a valuable resource for researchers interested in exploring the intersection of language models and reasoning techniques.

Awesome-LLM-Preference-Learning
The repository 'Awesome-LLM-Preference-Learning' is the official repository of a survey paper titled 'Towards a Unified View of Preference Learning for Large Language Models: A Survey'. It contains a curated list of papers related to preference learning for Large Language Models (LLMs). The repository covers various aspects of preference learning, including on-policy and off-policy methods, feedback mechanisms, reward models, algorithms, evaluation techniques, and more. The papers included in the repository explore different approaches to aligning LLMs with human preferences, improving mathematical reasoning in LLMs, enhancing code generation, and optimizing language model performance.

Awesome-LLM-Reasoning
**Curated collection of papers and resources on how to unlock the reasoning ability of LLMs and MLLMs.** **Description in less than 400 words, no line breaks and quotation marks.** Large Language Models (LLMs) have revolutionized the NLP landscape, showing improved performance and sample efficiency over smaller models. However, increasing model size alone has not proved sufficient for high performance on challenging reasoning tasks, such as solving arithmetic or commonsense problems. This curated collection of papers and resources presents the latest advancements in unlocking the reasoning abilities of LLMs and Multimodal LLMs (MLLMs). It covers various techniques, benchmarks, and applications, providing a comprehensive overview of the field. **5 jobs suitable for this tool, in lowercase letters.** - content writer - researcher - data analyst - software engineer - product manager **Keywords of the tool, in lowercase letters.** - llm - reasoning - multimodal - chain-of-thought - prompt engineering **5 specific tasks user can use this tool to do, in less than 3 words, Verb + noun form, in daily spoken language.** - write a story - answer a question - translate a language - generate code - summarize a document
awesome-llm-role-playing-with-persona
Awesome-llm-role-playing-with-persona is a curated list of resources for large language models for role-playing with assigned personas. It includes papers and resources related to persona-based dialogue systems, personalized response generation, psychology of LLMs, biases in LLMs, and more. The repository aims to provide a comprehensive collection of research papers and tools for exploring role-playing abilities of large language models in various contexts.
ai4math-papers
The 'ai4math-papers' repository contains a collection of research papers related to AI applications in mathematics, including automated theorem proving, synthetic theorem generation, autoformalization, proof refactoring, premise selection, benchmarks, human-in-the-loop interactions, and constructing examples/counterexamples. The papers cover various topics such as neural theorem proving, reinforcement learning for theorem proving, generative language modeling, formal mathematics statement curriculum learning, and more. The repository serves as a valuable resource for researchers and practitioners interested in the intersection of AI and mathematics.

LLM-as-a-Judge
LLM-as-a-Judge is a repository that includes papers discussed in a survey paper titled 'A Survey on LLM-as-a-Judge'. The repository covers various aspects of using Large Language Models (LLMs) as judges for tasks such as evaluation, reasoning, and decision-making. It provides insights into evaluation pipelines, improvement strategies, and specific tasks related to LLMs. The papers included in the repository explore different methodologies, applications, and future research directions for leveraging LLMs as evaluators in various domains.
For similar tasks
Awesome-LLM-RAG
This repository, Awesome-LLM-RAG, aims to record advanced papers on Retrieval Augmented Generation (RAG) in Large Language Models (LLMs). It serves as a resource hub for researchers interested in promoting their work related to LLM RAG by updating paper information through pull requests. The repository covers various topics such as workshops, tutorials, papers, surveys, benchmarks, retrieval-enhanced LLMs, RAG instruction tuning, RAG in-context learning, RAG embeddings, RAG simulators, RAG search, RAG long-text and memory, RAG evaluation, RAG optimization, and RAG applications.

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.

LLM-Tool-Survey
This repository contains a collection of papers related to tool learning with large language models (LLMs). The papers are organized according to the survey paper 'Tool Learning with Large Language Models: A Survey'. The survey focuses on the benefits and implementation of tool learning with LLMs, covering aspects such as task planning, tool selection, tool calling, response generation, benchmarks, evaluation, challenges, and future directions in the field. It aims to provide a comprehensive understanding of tool learning with LLMs and inspire further exploration in this emerging area.
Awesome-CVPR2024-ECCV2024-AIGC
A Collection of Papers and Codes for CVPR 2024 AIGC. This repository compiles and organizes research papers and code related to CVPR 2024 and ECCV 2024 AIGC (Artificial Intelligence and Graphics Computing). It serves as a valuable resource for individuals interested in the latest advancements in the field of computer vision and artificial intelligence. Users can find a curated list of papers and accompanying code repositories for further exploration and research. The repository encourages collaboration and contributions from the community through stars, forks, and pull requests.
LLMs-in-science
The 'LLMs-in-science' repository is a collaborative environment for organizing papers related to large language models (LLMs) and autonomous agents in the field of chemistry. The goal is to discuss trend topics, challenges, and the potential for supporting scientific discovery in the context of artificial intelligence. The repository aims to maintain a systematic structure of the field and welcomes contributions from the community to keep the content up-to-date and relevant.
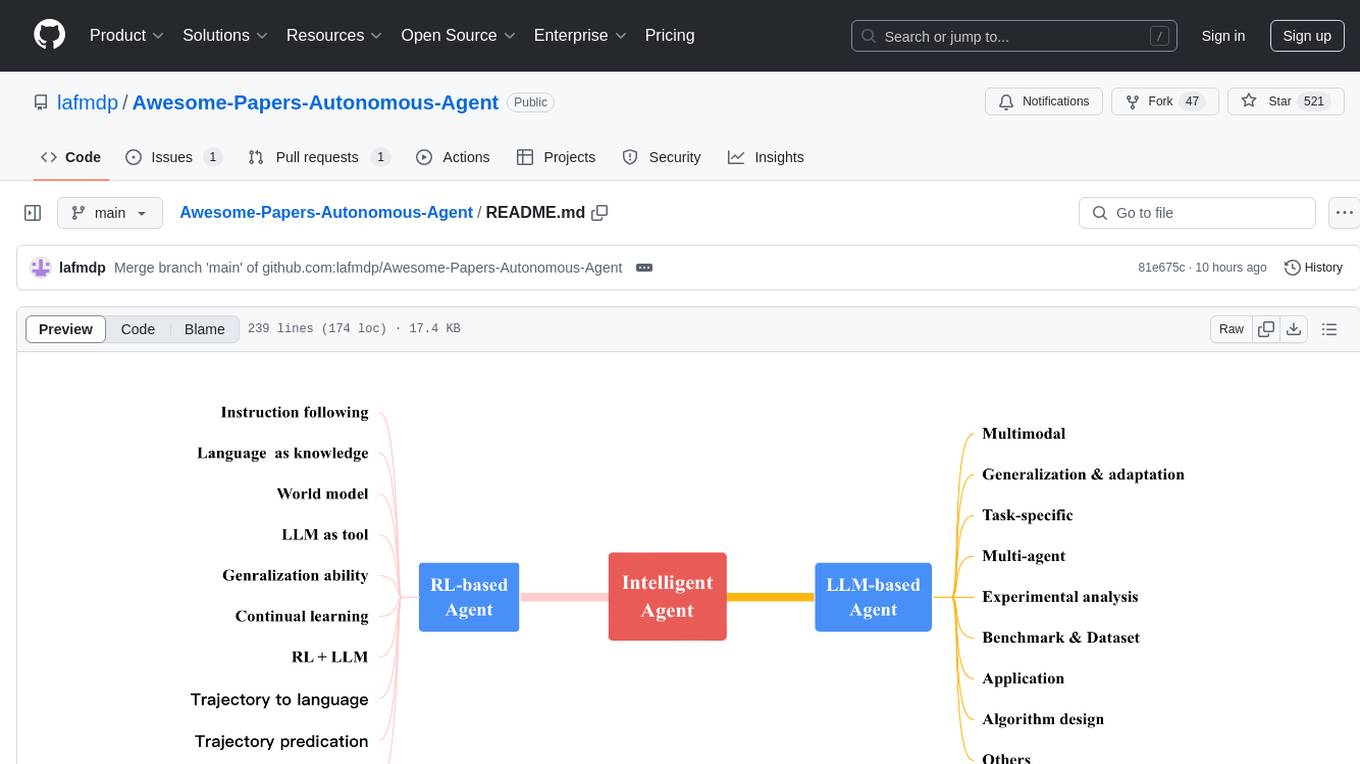
Awesome-Papers-Autonomous-Agent
Awesome-Papers-Autonomous-Agent is a curated collection of recent papers focusing on autonomous agents, specifically interested in RL-based agents and LLM-based agents. The repository aims to provide a comprehensive resource for researchers and practitioners interested in intelligent agents that can achieve goals, acquire knowledge, and continually improve. The collection includes papers on various topics such as instruction following, building agents based on world models, using language as knowledge, leveraging LLMs as a tool, generalization across tasks, continual learning, combining RL and LLM, transformer-based policies, trajectory to language, trajectory prediction, multimodal agents, training LLMs for generalization and adaptation, task-specific designing, multi-agent systems, experimental analysis, benchmarking, applications, algorithm design, and combining with RL.
awesome-lifelong-llm-agent
This repository is a collection of papers and resources related to Lifelong Learning of Large Language Model (LLM) based Agents. It focuses on continual learning and incremental learning of LLM agents, identifying key modules such as Perception, Memory, and Action. The repository serves as a roadmap for understanding lifelong learning in LLM agents and provides a comprehensive overview of related research and surveys.

LLM-Agent-Survey
LLM-Agent-Survey is a comprehensive repository that provides a curated list of papers related to Large Language Model (LLM) agents. The repository categorizes papers based on LLM-Profiled Roles and includes high-quality publications from prestigious conferences and journals. It aims to offer a systematic understanding of LLM-based agents, covering topics such as tool use, planning, and feedback learning. The repository also includes unpublished papers with insightful analysis and novelty, marked for future updates. Users can explore a wide range of surveys, tool use cases, planning workflows, and benchmarks related to LLM agents.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.