Best AI tools for< Evaluate Systems >
20 - AI tool Sites
Fairo
Fairo is a platform that facilitates Responsible AI Governance, offering tools for reducing AI hallucinations, managing AI agents and assets, evaluating AI systems, and ensuring compliance with various regulations. It provides a comprehensive solution for organizations to align their AI systems ethically and strategically, automate governance processes, and mitigate risks. Fairo aims to make responsible AI transformation accessible to organizations of all sizes, enabling them to build technology that is profitable, ethical, and transformative.
Stanford HAI
Stanford HAI is a research institute at Stanford University dedicated to advancing AI research, education, and policy to improve the human condition. The institute brings together researchers from a variety of disciplines to work on a wide range of AI-related projects, including developing new AI algorithms, studying the ethical and societal implications of AI, and creating educational programs to train the next generation of AI leaders. Stanford HAI is committed to developing human-centered AI technologies and applications that benefit all of humanity.

Maxim
Maxim is an end-to-end AI evaluation and observability platform that empowers modern AI teams to ship products with quality, reliability, and speed. It offers a comprehensive suite of tools for experimentation, evaluation, observability, and data management. Maxim aims to bring the best practices of traditional software development into non-deterministic AI workflows, enabling rapid iteration and deployment of AI models. The platform caters to the needs of AI developers, data scientists, and machine learning engineers by providing a unified framework for evaluation, visual flows for workflow testing, and observability features for monitoring and optimizing AI systems in real-time.
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users confidently scale AI by providing a comprehensive solution for all production needs, from evaluation to experimentation to improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and innovative techniques to generate high-quality scores. UpTrain is built for developers, compliant to data governance needs, cost-efficient, remarkably reliable, and open-source. It provides precision metrics, task understanding, safeguard systems, and covers a wide range of language features and quality aspects. The platform is suitable for developers, product managers, and business leaders looking to enhance their LLM applications.
Compassionate AI
Compassionate AI is a cutting-edge AI-powered platform that empowers individuals and organizations to create and deploy AI solutions that are ethical, responsible, and aligned with human values. With Compassionate AI, users can access a comprehensive suite of tools and resources to design, develop, and implement AI systems that prioritize fairness, transparency, and accountability.
JobMojito
JobMojito is an AI Interview Platform that offers real-time avatar and voice interviews for job candidates. It provides interview coaching, job preparation, and support in English. The platform allows users to screen, evaluate, and select top talent using an AI Avatar that converses with candidates in real-time. JobMojito offers a comprehensive solution for managing the entire interview process, including preparation, conducting interviews with the avatar, providing instant feedback, and assessing candidates using AI technology. The platform is designed to attract new talent and streamline the recruitment process for organizations.
AutoScreen
AutoScreen is an AI-powered recruitment tool that revolutionizes the hiring process. It utilizes advanced algorithms and machine learning to streamline the recruitment process, saving time and resources for businesses. With AutoScreen, employers can efficiently screen and shortlist candidates based on predefined criteria, leading to faster and more accurate hiring decisions. The tool offers a user-friendly interface, customizable features, and seamless integration with existing HR systems, making it a valuable asset for modern recruitment practices.
LlamaIndex
LlamaIndex is a framework for building context-augmented Large Language Model (LLM) applications. It provides tools to ingest and process data, implement complex query workflows, and build applications like question-answering chatbots, document understanding systems, and autonomous agents. LlamaIndex enables context augmentation by combining LLMs with private or domain-specific data, offering tools for data connectors, data indexes, engines for natural language access, chat engines, agents, and observability/evaluation integrations. It caters to users of all levels, from beginners to advanced developers, and is available in Python and Typescript.
Workable
Workable is a leading recruiting software and hiring platform that offers a full Applicant Tracking System with built-in AI sourcing. It provides a configurable HRIS platform to securely manage employees, automate hiring tasks, and offer actionable insights and reporting. Workable helps companies streamline their recruitment process, from sourcing to employee onboarding and management, with features like sourcing and attracting candidates, evaluating and collaborating with hiring teams, automating hiring tasks, onboarding and managing employees, and tracking HR processes.
Mangus
Mangus is an AI-powered learning platform that provides personalized learning paths for employees and students. It offers a wide range of courses and programs in various disciplines, including business, education, technology, and more. Mangus uses gamification and artificial intelligence to create an engaging and effective learning experience.

Flow AI
Flow AI is an advanced AI tool designed for evaluating and improving Large Language Model (LLM) applications. It offers a unique system for creating custom evaluators, deploying them with an API, and developing specialized LMs tailored to specific use cases. The tool aims to revolutionize AI evaluation and model development by providing transparent, cost-effective, and controllable solutions for AI teams across various domains.

PyjamaHR
PyjamaHR is a leading AI-powered Applicant Tracking System (ATS) and recruitment software designed to streamline the hiring process for businesses of all sizes. It offers advanced features such as source management, candidate evaluation, collaboration tools, and AI-powered candidate tests to enhance the efficiency and effectiveness of the recruitment process. With a user-friendly interface and robust security measures, PyjamaHR is a trusted solution for managing talent acquisition and improving hiring outcomes.
Recooty
Recooty is a modern applicant tracking system designed for growing companies to streamline their recruiting process. It offers features such as applicant tracking, job posting, candidate tracking, interview scheduling, talent pool management, employer branding, and HR tools. With Recooty, companies can attract, engage, and hire their next teammates with ease. The platform also provides resources like job descriptions, templates, interview questions, and AI tools to enhance the recruitment experience.
PolygrAI
PolygrAI is a digital polygraph powered by AI technology that provides real-time risk assessment and sentiment analysis. The platform meticulously analyzes facial micro-expressions, body language, vocal attributes, and linguistic cues to detect behavioral fluctuations and signs of deception. By combining well-established psychology practices with advanced AI and computer vision detection, PolygrAI offers users actionable insights for decision-making processes across various applications.
Wizi AI
Wizi AI is a technical AI interviewer that helps employers evaluate hundreds of candidates with in-depth assessments. It goes beyond basic coding challenges and conducts an onsite interview experience for every candidate. Employers get actionable hiring signals with in-depth reports on system design, project implementation, domain expertise, and debugging skills. Wizi AI saves teams time by screening all candidates with AI and bringing only the best to onsites.
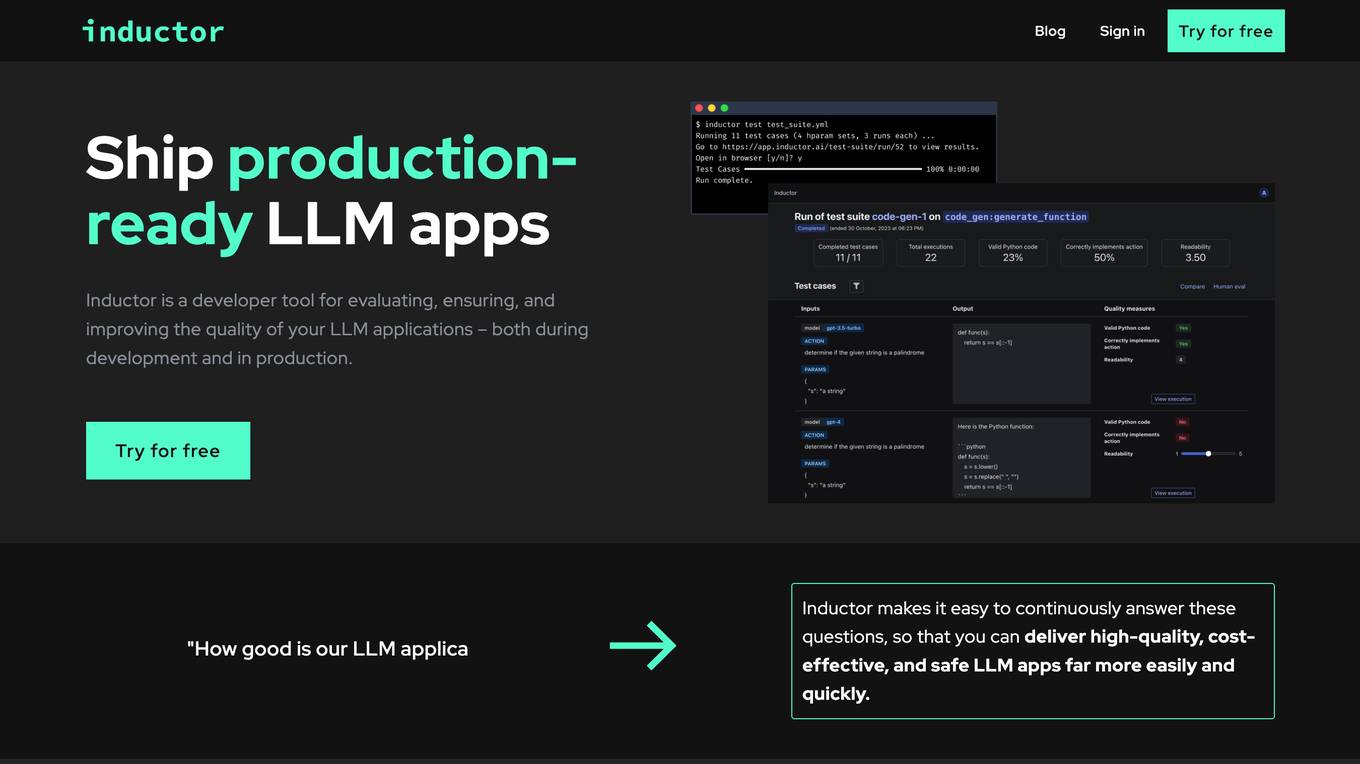
Inductor
Inductor is a developer tool for evaluating, ensuring, and improving the quality of your LLM applications – both during development and in production. It provides a fantastic workflow for continuous testing and evaluation as you develop, so that you always know your LLM app’s quality. Systematically improve quality and cost-effectiveness by actionably understanding your LLM app’s behavior and quickly testing different app variants. Rigorously assess your LLM app’s behavior before you deploy, in order to ensure quality and cost-effectiveness when you’re live. Easily monitor your live traffic: detect and resolve issues, analyze usage in order to improve, and seamlessly feed back into your development process. Inductor makes it easy for engineering and other roles to collaborate: get critical human feedback from non-engineering stakeholders (e.g., PM, UX, or subject matter experts) to ensure that your LLM app is user-ready.
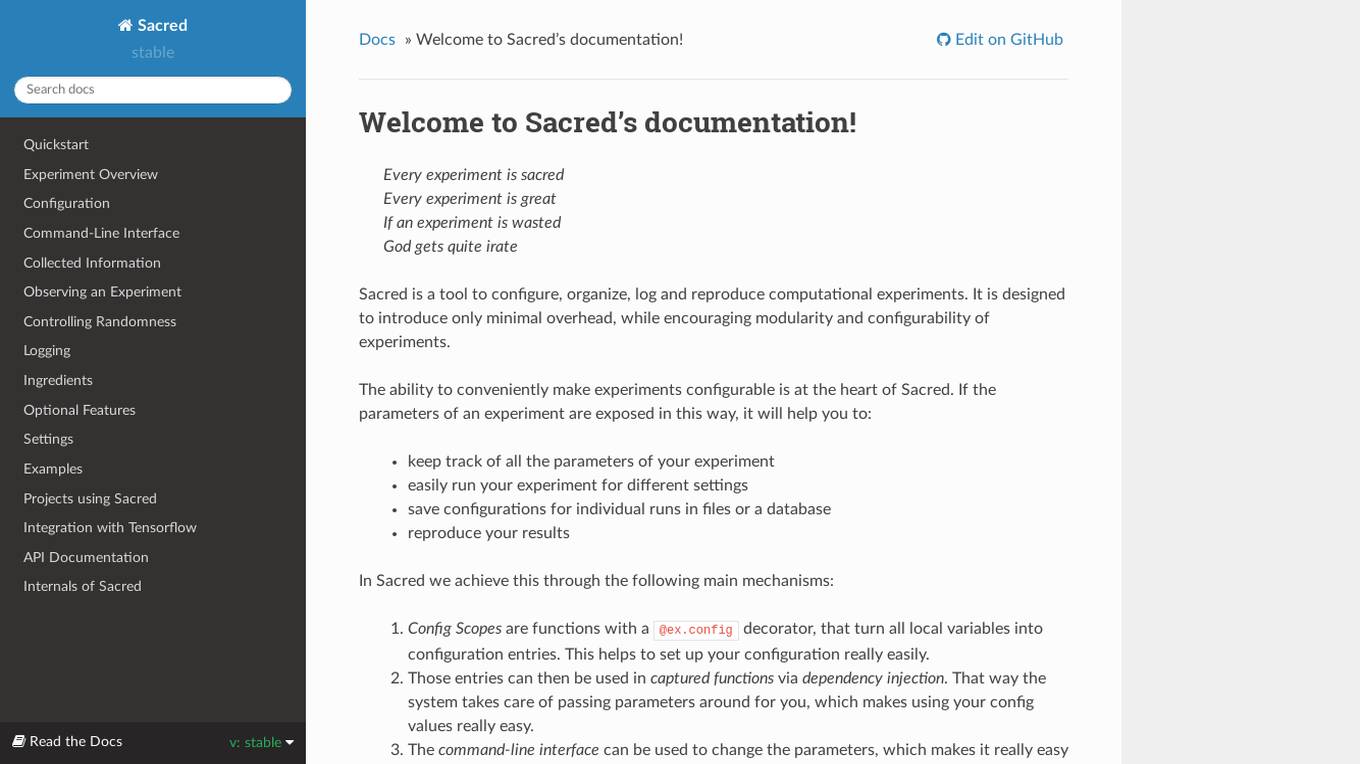
Sacred
Sacred is a tool to configure, organize, log and reproduce computational experiments. It is designed to introduce only minimal overhead, while encouraging modularity and configurability of experiments. The ability to conveniently make experiments configurable is at the heart of Sacred. If the parameters of an experiment are exposed in this way, it will help you to: keep track of all the parameters of your experiment easily run your experiment for different settings save configurations for individual runs in files or a database reproduce your results In Sacred we achieve this through the following main mechanisms: Config Scopes are functions with a @ex.config decorator, that turn all local variables into configuration entries. This helps to set up your configuration really easily. Those entries can then be used in captured functions via dependency injection. That way the system takes care of passing parameters around for you, which makes using your config values really easy. The command-line interface can be used to change the parameters, which makes it really easy to run your experiment with modified parameters. Observers log every information about your experiment and the configuration you used, and saves them for example to a Database. This helps to keep track of all your experiments. Automatic seeding helps controlling the randomness in your experiments, such that they stay reproducible.
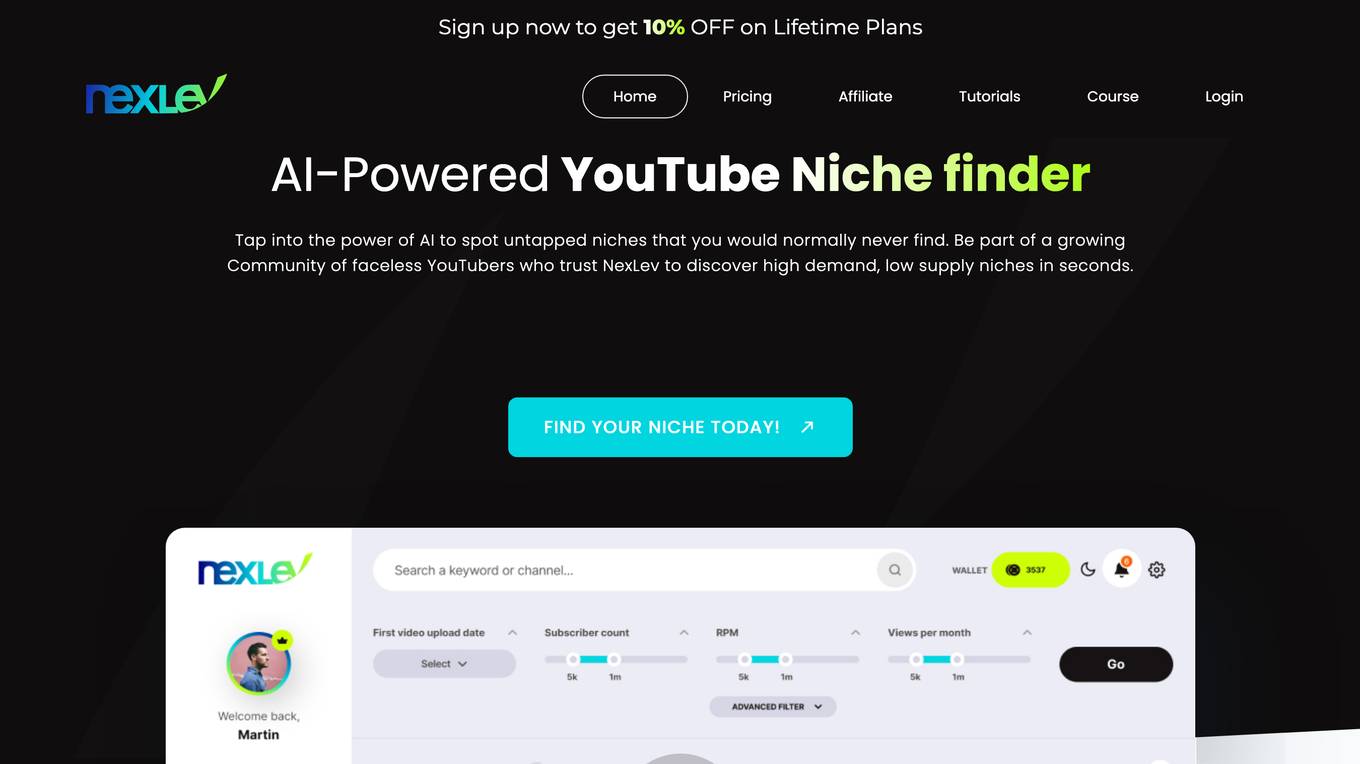
NexLev
NexLev is an AI-powered YouTube niche finder that helps users discover untapped, high-demand niches in seconds. It provides detailed YouTube channel analytics and an intuitive filtering system, making it easier for users to find lucrative niches for their next YouTube venture. NexLev also offers a variety of features such as a keyword analysis tool, competitor analysis, and a niche profitability calculator.

SiMa.ai
SiMa.ai is an AI application that offers high-performance, power-efficient, and scalable edge machine learning solutions for various industries such as automotive, industrial, healthcare, drones, and government sectors. The platform provides MLSoC™ boards, DevKit 2.0, Palette Software 1.2, and Edgematic™ for developers to accelerate complete applications and deploy AI-enabled solutions. SiMa.ai's Machine Learning System on Chip (MLSoC) enables full-pipeline implementations of real-world ML solutions, making it a trusted platform for edge AI development.
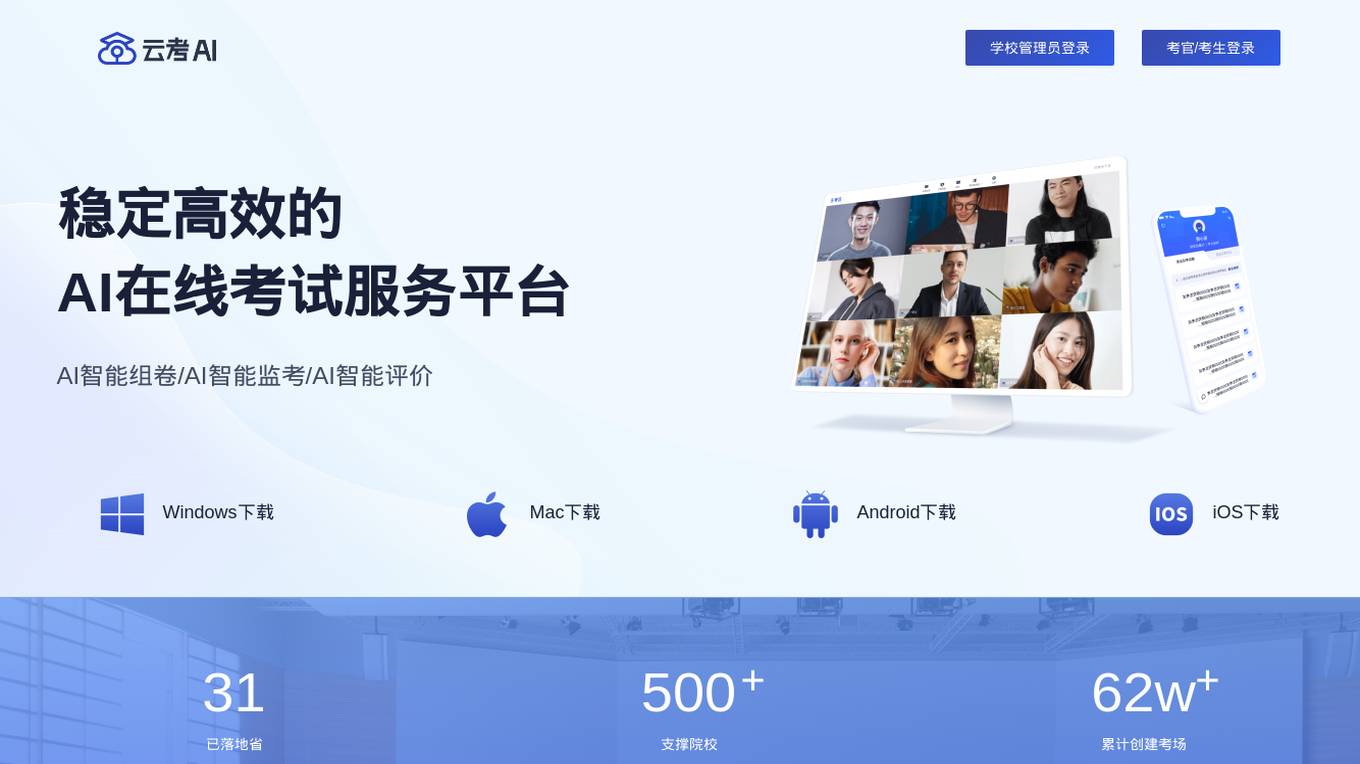
CloudExam AI
CloudExam AI is an online testing platform developed by Hanke Numerical Union Technology Co., Ltd. It provides stable and efficient AI online testing services, including intelligent grouping, intelligent monitoring, and intelligent evaluation. The platform ensures test fairness by implementing automatic monitoring level regulations and three random strategies. It prioritizes information security by combining software and hardware to secure data and identity. With global cloud deployment and flexible architecture, it supports hundreds of thousands of concurrent users. CloudExam AI offers features like queue interviews, interactive pen testing, data-driven cockpit, AI grouping, AI monitoring, AI evaluation, random question generation, dual-seat testing, facial recognition, real-time recording, abnormal behavior detection, test pledge book, student information verification, photo uploading for answers, inspection system, device detection, scoring template, ranking of results, SMS/email reminders, screen sharing, student fees, and collaboration with selected schools.
1 - Open Source AI Tools

Awesome-LLM-RAG
This repository, Awesome-LLM-RAG, aims to record advanced papers on Retrieval Augmented Generation (RAG) in Large Language Models (LLMs). It serves as a resource hub for researchers interested in promoting their work related to LLM RAG by updating paper information through pull requests. The repository covers various topics such as workshops, tutorials, papers, surveys, benchmarks, retrieval-enhanced LLMs, RAG instruction tuning, RAG in-context learning, RAG embeddings, RAG simulators, RAG search, RAG long-text and memory, RAG evaluation, RAG optimization, and RAG applications.
20 - OpenAI Gpts

Europe Ethos Guide for AI
Ethics-focused GPT builder assistant based on European AI guidelines, recommendations and regulations
Drug Delivery Systems Advisor
An expert in Drug Delivery Systems Industry, providing in-depth, accurate insights.
System Design Tutor
A System Architect Coach guiding you through system design principles and best practices. Explains CAP theorem like no one else

Transportation Engineering Advisor
Provides expert guidance in transportation engineering projects.
Environmental Engineering Advisor
Advises on sustainable engineering solutions to environmental challenges.
Edexcel A-Level Math Pure Assistant
Your Edexcel A level maths assistant. Ask for new questions. Help for the next step in your working out. Even send me a picture of a question and i can tell you what exam it is from.
Epidemic Global Insight System
Advanced epidemiology expert with AI-driven data integration and dynamic visualization tools.

Quality Assurance Advisor
Ensures product quality through systematic process monitoring and evaluation.
Luxury Authenticator
Expert in authenticating luxury items, providing detailed evaluations and ratings.

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model