
Awesome-CVPR2024-ECCV2024-AIGC
A Collection of Papers and Codes for CVPR2024/ECCV2024 AIGC
Stars: 427
A Collection of Papers and Codes for CVPR 2024 AIGC. This repository compiles and organizes research papers and code related to CVPR 2024 and ECCV 2024 AIGC (Artificial Intelligence and Graphics Computing). It serves as a valuable resource for individuals interested in the latest advancements in the field of computer vision and artificial intelligence. Users can find a curated list of papers and accompanying code repositories for further exploration and research. The repository encourages collaboration and contributions from the community through stars, forks, and pull requests.
README:
A Collection of Papers and Codes for CVPR2024 AIGC
整理汇总了下2024年CVPR和2024年ECCV AIGC相关的论文和代码,具体如下。
欢迎star,fork和PR~
Please feel free to star, fork or PR if helpful~
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-CVPR2024-ECCV2024-AIGC
Similar Open Source Tools
Awesome-CVPR2024-ECCV2024-AIGC
A Collection of Papers and Codes for CVPR 2024 AIGC. This repository compiles and organizes research papers and code related to CVPR 2024 and ECCV 2024 AIGC (Artificial Intelligence and Graphics Computing). It serves as a valuable resource for individuals interested in the latest advancements in the field of computer vision and artificial intelligence. Users can find a curated list of papers and accompanying code repositories for further exploration and research. The repository encourages collaboration and contributions from the community through stars, forks, and pull requests.
Awesome-AI-Data-GitHub-Repos
Awesome AI & Data GitHub-Repos is a curated list of essential GitHub repositories covering the AI & ML landscape. It includes resources for Natural Language Processing, Large Language Models, Computer Vision, Data Science, Machine Learning, MLOps, Data Engineering, SQL & Database, and Statistics. The repository aims to provide a comprehensive collection of projects and resources for individuals studying or working in the field of AI and data science.

MONAI
MONAI is a PyTorch-based, open-source framework for deep learning in healthcare imaging. It provides a comprehensive set of tools for medical image analysis, including data preprocessing, model training, and evaluation. MONAI is designed to be flexible and easy to use, making it a valuable resource for researchers and developers in the field of medical imaging.
blinko
Blinko is an innovative open-source project designed for individuals who want to quickly capture and organize their fleeting thoughts. It allows users to seamlessly jot down ideas the moment they strike, ensuring that no spark of creativity is lost. With advanced AI-powered note retrieval, data ownership, efficient and fast capturing, lightweight architecture, and open collaboration, Blinko offers a comprehensive solution for managing and accessing notes.

lobe-chat
Lobe Chat is an open-source, modern-design ChatGPT/LLMs UI/Framework. Supports speech-synthesis, multi-modal, and extensible ([function call][docs-functionc-call]) plugin system. One-click **FREE** deployment of your private OpenAI ChatGPT/Claude/Gemini/Groq/Ollama chat application.

cherry-studio
Cherry Studio is a desktop client that supports multiple LLM providers on Windows, Mac, and Linux. It offers diverse LLM provider support, AI assistants & conversations, document & data processing, practical tools integration, and enhanced user experience. The tool includes features like support for major LLM cloud services, AI web service integration, local model support, pre-configured AI assistants, document processing for text, images, and more, global search functionality, topic management system, AI-powered translation, and cross-platform support with ready-to-use features and themes for a better user experience.
Awesome-RoadMaps-and-Interviews
Awesome RoadMaps and Interviews is a comprehensive repository that aims to provide guidance for technical interviews and career development in the ITCS field. It covers a wide range of topics including interview strategies, technical knowledge, and practical insights gained from years of interviewing experience. The repository emphasizes the importance of combining theoretical knowledge with practical application, and encourages users to expand their interview preparation beyond just algorithms. It also offers resources for enhancing knowledge breadth, depth, and programming skills through curated roadmaps, mind maps, cheat sheets, and coding snippets. The content is structured to help individuals navigate various technical roles and technologies, fostering continuous learning and professional growth.
intro_pharma_ai
This repository serves as an educational resource for pharmaceutical and chemistry students to learn the basics of Deep Learning through a collection of Jupyter Notebooks. The content covers various topics such as Introduction to Jupyter, Python, Cheminformatics & RDKit, Linear Regression, Data Science, Linear Algebra, Neural Networks, PyTorch, Convolutional Neural Networks, Transfer Learning, Recurrent Neural Networks, Autoencoders, Graph Neural Networks, and Summary. The notebooks aim to provide theoretical concepts to understand neural networks through code completion, but instructors are encouraged to supplement with their own lectures. The work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
kornia
Kornia is a differentiable computer vision library for PyTorch. It consists of a set of routines and differentiable modules to solve generic computer vision problems. At its core, the package uses PyTorch as its main backend both for efficiency and to take advantage of the reverse-mode auto-differentiation to define and compute the gradient of complex functions.
AI-Engineering.academy
AI Engineering Academy aims to provide a structured learning path for individuals looking to learn Applied AI effectively. The platform offers multiple roadmaps covering topics like Retrieval Augmented Generation, Fine-tuning, and Deployment. Each roadmap equips learners with the knowledge and skills needed to excel in applied GenAI. Additionally, the platform will feature Hands-on End-to-End AI projects in the future.
SkyRL
SkyRL is a full-stack RL library that provides components such as 'skyagent' for training long-horizon, real-world agents, 'skyrl-train' for modular RL training, and 'skyrl-gym' for a variety of tool-use tasks. It offers a library of math, coding, search, and SQL environments implemented in the Gymnasium API, optimized for multi-turn tool use LLMs on long-horizon, real-environment tasks.
Play-with-LLMs
This repository provides a comprehensive guide to training, evaluating, and building applications with Large Language Models (LLMs). It covers various aspects of LLMs, including pretraining, fine-tuning, reinforcement learning from human feedback (RLHF), and more. The repository also includes practical examples and code snippets to help users get started with LLMs quickly and easily.

DataDreamer
DataDreamer is a powerful open-source Python library designed for prompting, synthetic data generation, and training workflows. It is simple, efficient, and research-grade, allowing users to create prompting workflows, generate synthetic datasets, and train models with ease. The library is built for researchers, by researchers, focusing on correctness, best practices, and reproducibility. It offers features like aggressive caching, resumability, support for bleeding-edge techniques, and easy sharing of datasets and models. DataDreamer enables users to run multi-step prompting workflows, generate synthetic datasets for various tasks, and train models by aligning, fine-tuning, instruction-tuning, and distilling them using existing or synthetic data.

sealos
Sealos is a cloud operating system distribution based on the Kubernetes kernel, designed for a seamless development lifecycle. It allows users to spin up full-stack environments in seconds, effortlessly push releases, and scale production seamlessly. With core features like easy application management, quick database creation, and cloud universality, Sealos offers efficient and economical cloud management with high universality and ease of use. The platform also emphasizes agility and security through its multi-tenancy sharing model. Sealos is supported by a community offering full documentation, Discord support, and active development roadmap.
xpert
Xpert is a powerful tool for data analysis and visualization. It provides a user-friendly interface to explore and manipulate datasets, perform statistical analysis, and create insightful visualizations. With Xpert, users can easily import data from various sources, clean and preprocess data, analyze trends and patterns, and generate interactive charts and graphs. Whether you are a data scientist, analyst, researcher, or student, Xpert simplifies the process of data analysis and visualization, making it accessible to users with varying levels of expertise.
MaxKB
MaxKB is a knowledge base Q&A system based on the LLM large language model. MaxKB = Max Knowledge Base, which aims to become the most powerful brain of the enterprise.
For similar tasks

Awesome-LLM-RAG
This repository, Awesome-LLM-RAG, aims to record advanced papers on Retrieval Augmented Generation (RAG) in Large Language Models (LLMs). It serves as a resource hub for researchers interested in promoting their work related to LLM RAG by updating paper information through pull requests. The repository covers various topics such as workshops, tutorials, papers, surveys, benchmarks, retrieval-enhanced LLMs, RAG instruction tuning, RAG in-context learning, RAG embeddings, RAG simulators, RAG search, RAG long-text and memory, RAG evaluation, RAG optimization, and RAG applications.

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.

LLM-Tool-Survey
This repository contains a collection of papers related to tool learning with large language models (LLMs). The papers are organized according to the survey paper 'Tool Learning with Large Language Models: A Survey'. The survey focuses on the benefits and implementation of tool learning with LLMs, covering aspects such as task planning, tool selection, tool calling, response generation, benchmarks, evaluation, challenges, and future directions in the field. It aims to provide a comprehensive understanding of tool learning with LLMs and inspire further exploration in this emerging area.
Awesome-CVPR2024-ECCV2024-AIGC
A Collection of Papers and Codes for CVPR 2024 AIGC. This repository compiles and organizes research papers and code related to CVPR 2024 and ECCV 2024 AIGC (Artificial Intelligence and Graphics Computing). It serves as a valuable resource for individuals interested in the latest advancements in the field of computer vision and artificial intelligence. Users can find a curated list of papers and accompanying code repositories for further exploration and research. The repository encourages collaboration and contributions from the community through stars, forks, and pull requests.
LLMs-in-science
The 'LLMs-in-science' repository is a collaborative environment for organizing papers related to large language models (LLMs) and autonomous agents in the field of chemistry. The goal is to discuss trend topics, challenges, and the potential for supporting scientific discovery in the context of artificial intelligence. The repository aims to maintain a systematic structure of the field and welcomes contributions from the community to keep the content up-to-date and relevant.
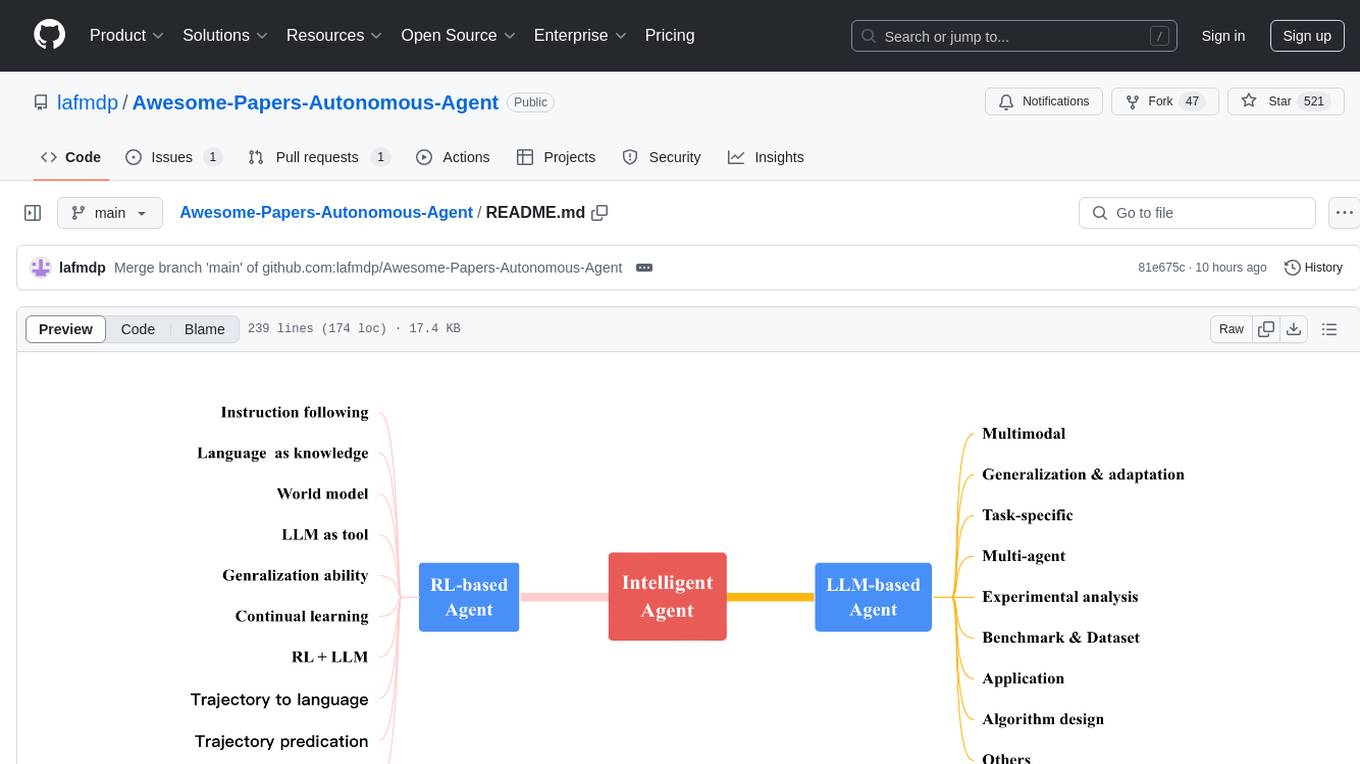
Awesome-Papers-Autonomous-Agent
Awesome-Papers-Autonomous-Agent is a curated collection of recent papers focusing on autonomous agents, specifically interested in RL-based agents and LLM-based agents. The repository aims to provide a comprehensive resource for researchers and practitioners interested in intelligent agents that can achieve goals, acquire knowledge, and continually improve. The collection includes papers on various topics such as instruction following, building agents based on world models, using language as knowledge, leveraging LLMs as a tool, generalization across tasks, continual learning, combining RL and LLM, transformer-based policies, trajectory to language, trajectory prediction, multimodal agents, training LLMs for generalization and adaptation, task-specific designing, multi-agent systems, experimental analysis, benchmarking, applications, algorithm design, and combining with RL.
awesome-lifelong-llm-agent
This repository is a collection of papers and resources related to Lifelong Learning of Large Language Model (LLM) based Agents. It focuses on continual learning and incremental learning of LLM agents, identifying key modules such as Perception, Memory, and Action. The repository serves as a roadmap for understanding lifelong learning in LLM agents and provides a comprehensive overview of related research and surveys.

LLM-Agent-Survey
LLM-Agent-Survey is a comprehensive repository that provides a curated list of papers related to Large Language Model (LLM) agents. The repository categorizes papers based on LLM-Profiled Roles and includes high-quality publications from prestigious conferences and journals. It aims to offer a systematic understanding of LLM-based agents, covering topics such as tool use, planning, and feedback learning. The repository also includes unpublished papers with insightful analysis and novelty, marked for future updates. Users can explore a wide range of surveys, tool use cases, planning workflows, and benchmarks related to LLM agents.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.